Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() Database SQL di Azure
Database SQL di Azure![]() Database SQL in Fabric
Database SQL in Fabric
Questo articolo descrive l'architettura di Azure SQL Database e di SQL Database in Fabric, che ottiene la disponibilità tramite ridondanza locale e alta disponibilità tramite ridondanza delle zone.
Overview
database SQL di Azure e database SQL in Fabric vengono entrambi eseguiti nella versione stabile più recente del motore di database DI SQL Server nel sistema operativo Windows con tutte le patch applicabili. Il database SQL gestisce automaticamente le attività di manutenzione critiche, quali l'applicazione di patch, i backup, gli aggiornamenti di Windows e SQL e gli eventi non pianificati come errori di hardware, software o rete sottostanti. Quando un database o un pool elastico nel database SQL viene patchato o sottoposto a failover, il tempo di inattività non influisce se si usa la logica di ripetizione dei tentativi nell'app. Il database SQL di Azure può effettuare rapidamente il recupero anche nei casi più critici, garantendo che i dati siano sempre disponibili. La maggior parte degli utenti non nota che gli aggiornamenti vengono eseguiti continuamente.
Per impostazione predefinita, il database SQL di Azure raggiunge la disponibilità tramite ridondanza locale, assicurandosi che il database gestisca le interruzioni, ad esempio:
- Operazioni di gestione avviate dal cliente che comportano un breve tempo di inattività
- Operazioni di manutenzione del servizio
- Problemi relativi a:
- rack in cui sono in esecuzione i computer che alimentano il servizio
- computer fisico che ospita il motore di database SQL
- Altri problemi relativi al motore di database SQL
- Altre potenziali interruzioni locali non pianificate
La soluzione di disponibilità predefinita è progettata per garantire che i dati di cui è stato eseguito il commit non vengano mai persi a causa di errori, che le operazioni di manutenzione abbiano un impatto minimo sul carico di lavoro e che il database non sia un singolo punto di errore nell'architettura software.
Tuttavia, per ridurre al minimo l'impatto sui dati in caso di interruzione di un'intera zona, è possibile ottenere una disponibilità elevata abilitando la ridondanza della zona. Senza ridondanza della zona, i failover vengono eseguiti localmente all'interno dello stesso data center, il che potrebbe causare l'indisponibilità del database fino a quando non viene risolta l'interruzione. L'unico modo per eseguire il ripristino è tramite una soluzione di ripristino di emergenza, ad esempio il failover geografico tramite la replica geografica attiva, i gruppi di failover o il ripristino geografico di un backup con ridondanza geografica. Per altre informazioni, vedere la panoramica della continuità aziendale.
Esistono tre modelli di architettura della disponibilità:
- Modello di archiviazione remota basato su una separazione tra calcolo e archiviazione. Il modello di archiviazione remota si basa sulla disponibilità e sull'affidabilità del livello di archiviazione remota. Questa architettura è destinata alle applicazioni aziendali orientate al budget che possono tollerare una riduzione del livello delle prestazioni durante le attività di manutenzione.
- Modello di archiviazione locale basato su un cluster di processi del motore di database. Il modello di archiviazione locale si basa sul fatto che esiste sempre un quorum di nodi del motore di database disponibili. Questa architettura è destinata alle applicazioni cruciali con prestazioni di I/O elevate, velocità di transazione elevata e garantisce un impatto minimo sulle prestazioni sul carico di lavoro durante le attività di manutenzione.
- Modello Hyperscale che usa un sistema distribuito di componenti a disponibilità elevata, ad esempio nodi di calcolo, server di pagine, servizio di log e archiviazione permanente. Ogni componente che supporta un database Hyperscale offre ridondanza e resilienza agli errori. I nodi di calcolo, i server di pagine e il servizio di log vengono eseguiti in Service Fabric di Azure, che controlla il funzionamento di ogni componente ed esegue i failover nei nodi integri disponibili in base alle esigenze. L'archiviazione persistente utilizza Azure Storage con le sue funzionalità native di alta disponibilità e ridondanza. Per altre informazioni, vedere Architettura hyperscale.
All'interno di ognuno dei tre modelli di disponibilità, il database SQL supporta le opzioni di ridondanza locale e ridondanza della zona. La ridondanza locale offre resilienza all'interno di un data center, mentre la ridondanza della zona migliora ulteriormente la resilienza proteggendo dalle interruzioni di una zona di disponibilità all'interno di un'area.
La tabella seguente illustra le opzioni di disponibilità in base ai livelli di servizio:
| Livello di servizio | Modello di disponibilità elevata | Disponibilità con ridondanza locale | Disponibilità a ridondanza di zona |
|---|---|---|---|
| Utilizzo generico (vCore) | Archiviazione remota | Yes | Yes |
| Business Critical (vCore) | Archiviazione locale | Yes | Yes |
| Hyperscale (vCore) | Hyperscale | Yes | Yes |
| Basico (DTU) | Archiviazione remota | Yes | No |
| Standard (DTU) | Archiviazione remota | Yes | No |
| Premium (DTU) | Archiviazione locale | Yes | Yes |
Per altre informazioni sui contratti di servizio specifici per diversi livelli di servizio, vedere Contratto di servizio per il database SQL di Azure.
Disponibilità tramite ridondanza locale
La disponibilità con ridondanza locale si basa sull'archiviazione del database nell'archiviazione con ridondanza locale che copia i dati tre volte all'interno di un singolo data center nell'area primaria e protegge i dati in caso di errore locale, ad esempio una rete su scala ridotta o un'interruzione dell'alimentazione. LRS è l'opzione di ridondanza più economica e offre una durabilità inferiore rispetto alle altre opzioni. Se si verifica un disastro su vasta scala, come un incendio o un'alluvione, all'interno di una regione, tutte le repliche di un account di archiviazione che utilizza l'archiviazione con ridondanza locale potrebbero essere perse o irrecuperabili. Di conseguenza, per proteggere ulteriormente i dati quando si usa l'opzione di disponibilità con ridondanza locale, è consigliabile usare un'opzione di archiviazione più resiliente per i backup del database. Ciò non si applica ai database Hyperscale, in cui viene usata la stessa risorsa di archiviazione sia per i file di dati che per i backup.
La disponibilità con ridondanza locale è disponibile per tutti i database in tutti i livelli di servizio e l'obiettivo del punto di ripristino (RPO), che indica che la quantità di perdita di dati, è zero.
Livelli di servizio Basic, Standard e Utilizzo generico
I livelli di servizio Basic e Standard del modello di acquisto basato su DTU e il livello di servizio per utilizzo generico del modello di acquisto basato su vCore usano il modello di disponibilità di archiviazione remota sia per il calcolo serverless che per quello con provisioning. Il diagramma seguente mostra i nodi con i livelli di calcolo e archiviazione separati.
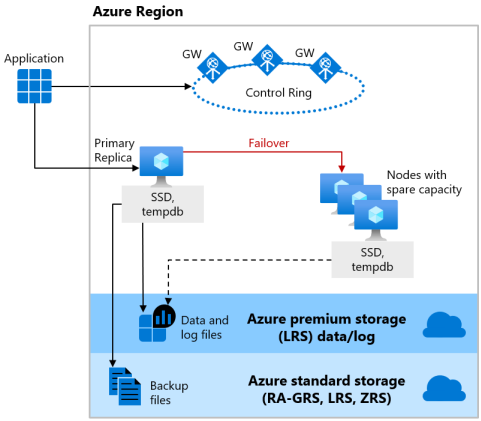
Il modello di disponibilità dell'archiviazione remota include due livelli:
Un strato di calcolo senza stato che esegue il processo del motore di database e contiene solo dati memorizzati temporaneamente in cache, come ad esempio i database
tempdbemodelnell'unità SSD collegata e la cache dei piani, il pool di buffer e il pool columnstore in memoria. Il nodo senza stato è gestito da Service Fabric di Azure che inizializza il motore di database, controlla il funzionamento del nodo e, se necessario, esegue il failover in un altro nodo.Un livello di dati con stato con i file di database (
.mdfand.ldf) archiviati in Archiviazione BLOB di Azure. L'Archiviazione BLOB di Azure include funzionalità predefinite di disponibilità e ridondanza dei dati. Garantisce che ogni record nel file di log o nella pagina del file di dati venga mantenuto anche se il processo del motore di database si arresta in modo anomalo.
Ogni volta che viene aggiornato il motore di database o il sistema operativo oppure viene rilevato un errore, Azure Service Fabric sposta il processo del motore di database senza stato in un altro nodo di calcolo senza stato con capacità libera sufficiente. I dati presenti in Archiviazione BLOB di Azure non vengono interessati dallo spostamento e i dati e i file di log vengono associati al processo di motore di database appena inizializzato. Questo processo garantisce la disponibilità elevata, ma un carico di lavoro elevato potrebbe riscontrare una riduzione delle prestazioni durante la transizione perché il nuovo processo del motore di database inizia con la cache a freddo.
Livelli di servizio Premium e Business Critical
Il livello di servizio Premium del modello di acquisto basato su DTU e il livello di servizio Business Critical del modello di acquisto basato su vCore usano il modello di disponibilità dell'archiviazione locale, che integra le risorse di calcolo (processo del motore di database) e l'archiviazione (unità SSD collegata localmente) in un singolo nodo. La disponibilità elevata viene ottenuta replicando sia il calcolo che l'archiviazione in nodi aggiuntivi.
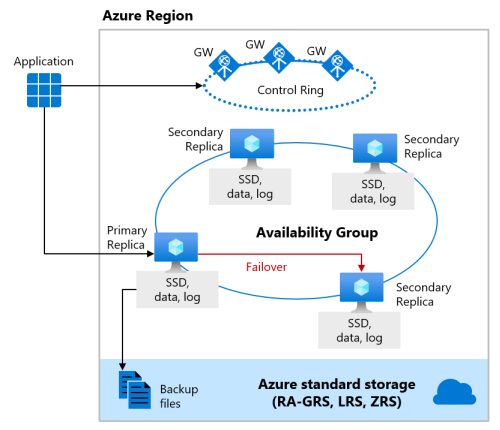
I file di database sottostanti (.mdf/.ldf) vengono inseriti nell'archiviazione SSD collegata per fornire operazioni di I/O a bassa latenza al carico di lavoro. La disponibilità elevata viene implementata usando una tecnologia simile ai gruppi di disponibilità AlwaysOn di SQL Server. Il cluster include una singola replica primaria accessibile per i carichi di lavoro dei clienti in lettura/scrittura e fino a tre repliche secondarie (calcolo e archiviazione) contenenti copie dei dati. La replica primaria trasmette costantemente le modifiche alle repliche secondarie in ordine e garantisce che i dati siano resi persistenti su un numero sufficiente di repliche secondarie prima di confermare ogni transazione. Questo processo garantisce che, se la replica primaria o la replica secondaria leggibile si arrestino in modo anomalo per qualsiasi motivo, esiste sempre una replica completamente sincronizzata in cui eseguire il failover. Il failover viene avviato da Service Fabric di Azure. Quando una replica secondaria diventa la nuova replica primaria, viene creata un'altra replica secondaria per garantire che il cluster disponga di un numero sufficiente di repliche per mantenere il quorum. Al termine di un failover, le connessioni SQL di Azure vengono reindirizzate automaticamente alla nuova replica primaria o alla replica secondaria leggibile.
Come vantaggio aggiuntivo, il modello di disponibilità dell'archiviazione locale include la possibilità di reindirizzare le connessioni SQL di Azure di sola lettura a una delle repliche secondarie. Questa funzionalità è denominata Scale-Out in lettura. Offre 100% capacità di calcolo aggiuntiva senza costi aggiuntivi per le operazioni di sola lettura, ad esempio i carichi di lavoro analitici, dalla replica primaria.
Livello di servizio Hyperscale
L'architettura del livello di servizio Hyperscale è descritta in Architettura delle funzioni distribuite, che include un diagramma dettagliato.
Il modello di disponibilità in Hyperscale include quattro livelli:
Un livello di elaborazione senza stato che esegue i processi del motore del database e contiene solo dati transitori e memorizzati nella cache, come la cache RBPEX non coprente, i database
tempdbemodel, ecc., sull'SSD collegato, e la cache dei piani, il pool di buffer e il pool columnstore in memoria. Questo livello senza stato include la replica di calcolo primaria e, facoltativamente, una serie di repliche di calcolo secondarie che possono fungere da destinazioni di failover.Livello di archiviazione senza stato formato da server di pagine. Questo livello è il motore di archiviazione distribuito per i processi del motore di database in esecuzione nelle repliche di calcolo. Ogni server di pagine contiene solo dati transitori e memorizzati nella cache, come la cache RBPEX presente nell'unità SSD collegata e le pagine di dati memorizzate nella cache della memoria. Ogni server di pagine dispone di un server di pagine associato in una configurazione attiva-attiva per garantire il bilanciamento del carico, la ridondanza e la disponibilità elevata.
Livello di archiviazione con stato dei log delle transazioni formato dal nodo di calcolo che esegue il processo di servizio di registro, dall'area di destinazione del registro delle transazioni e dall'archiviazione a lungo termine del registro delle transazioni. La zona di atterraggio e l'archiviazione a lungo termine usano Azure Storage, che offre disponibilità e ridondanza per il log delle transazioni, garantendo la durabilità dei dati per le transazioni di cui è stato eseguito il commit.
Strato di archiviazione dati con gestione dello stato, con i file di database (.mdf/.ndf) archiviati in Azure Storage e aggiornati dai server di pagine. Questo livello utilizza le funzionalità di Archiviazione di Azure per la disponibilità e la ridondanza dei dati. Garantisce che ogni pagina in un file di dati venga preservata anche se i processi in altri livelli dell'architettura Hyperscale si arrestano anormalmente, o se i nodi di calcolo falliscono.
I nodi di calcolo in tutti i livelli Hyperscale vengono eseguiti in Service Fabric di Azure, che controlla l'integrità di ogni nodo ed esegue i failover sui nodi integri disponibili, se necessario.
Per altre informazioni sulla disponibilità elevata in Hyperscale, vedere Disponibilità elevata del database in Hyperscale.
Disponibilità elevata tramite ridondanza zonale
Per le distribuzioni con ridondanza della zona, il database SQL di Azure usa il numero di zone di disponibilità di Azure in una determinata area, due o più comunemente tre. I componenti di calcolo e archiviazione si estendono su due o tre zone, come selezionato da Azure SQL per garantire resilienza ottimale, in posizioni fisiche separate con alimentazione, raffreddamento e rete indipendenti. Azure SQL seleziona automaticamente il numero di zone in base alla disponibilità e all'ottimizzazione del servizio a livello di area. La distribuzione non userà meno zone del necessario per garantire la resilienza.
La disponibilità di zone ridondanti è prevista per i database nei livelli di servizio Business Critical, Scopo generico e Hyperscale del modello di acquisto basato su vCore e solo il livello di servizio Premium del modello di acquisto basato su DTU, mentre i livelli di servizio Basic e Standard non supportano la ridondanza della zona.
Anche se ogni livello di servizio implementa la ridondanza zonale in modo diverso, tutte le implementazioni garantiscono un Recovery Point Objective (RPO) senza perdita di dati di cui è stato eseguito il commit in caso di failover, se una singola zona di disponibilità all'interno di una regione di Azure non è più disponibile.
Azure SQL ottimizza automaticamente il posizionamento della zona per la distribuzione. Tutte le configurazioni della zona di disponibilità, usando due o tre zone, offrono le stesse garanzie di disponibilità elevata e resilienza.
Livello di servizio a uso generico
La configurazione a ridondanza di zona per il livello di servizio Generale è disponibile sia per l'elaborazione serverless che per il calcolo con provisioning per i database nel modello di acquisto vCore. Questa configurazione usa le zone di disponibilità di Azure per replicare i database in più posizioni fisiche all'interno di un'area di Azure. Selezionando la ridondanza a livello di zona, è possibile rendere resilienti a una serie molto più ampia di errori i database singoli e i pool elastici, sia serverless che con provisioning per uso generico, incluse le interruzioni catastrofiche dei data center, senza alcuna modifica della logica dell'applicazione.
La configurazione con ridondanza della zona per un livello Utilizzo generico consiste in due livelli:
- Livello dati a stato gestito con i file di database (.mdf/.ldf) archiviati in storage ridondante a zona. Usando ZRS (Zone Redundant Storage), i file di log e dati vengono copiati in modo sincrono attraverso più zone di disponibilità di Azure nella regione primaria. Si tratta di due o tre zone, come selezionato da AZURE SQL per garantire una resilienza ottimale.
- Livello di calcolo senza stato che esegue il processo di sqlservr.exe e contiene solo dati temporanei e memorizzati nella cache, ad esempio i database
tempdbemodelnell'unità SSD collegata e la cache dei piani, il pool di buffer e il pool columnstore in memoria. Il nodo senza stato è gestito da Service Fabric di Azure che inizializza il processo sqlservr.exe, controlla l'integrità del nodo e, se necessario, esegue il failover in un altro nodo. Per i database serverless con ridondanza a livello di zona e con provisioning per utilizzo generico, i nodi con capacità di riserva sono facilmente disponibili in altre zone di disponibilità per il failover.
La versione zone-redundant dell'architettura ad alta disponibilità per il livello di servizio generale è illustrata nei diagrammi seguenti, in un'area a due zone o a tre zone.
| Regione a due zone | Area a tre zone |
|---|---|

|

|
Quando il calcolo viene distribuito tra due zone di disponibilità:
- Il backup e l'archiviazione sono ancora sincronizzati tra tre zone di disponibilità nell'area.
- L'archiviazione con ridondanza di zona, come sempre, viene sincronizzata tra tre zone di disponibilità.
Quando si approvvigionano le risorse di calcolo in tre zone di disponibilità:
- Il backup e l'archiviazione vengono sincronizzati tra tre zone di disponibilità nell'area.
Tutte le aree di Azure che hanno il supporto per la zona di disponibilità supportano i database generali con ridondanza di zona.
Per la disponibilità con ridondanza della zona, la scelta di una finestra di manutenzione diversa da quella predefinita è attualmente disponibile nelle aree selezionate. Per altre informazioni, vedere Disponibilità della finestra di manutenzione in base all'area per il database SQL di Azure.
La ridondanza di zona non è disponibile per i livelli di servizio Basic e Standard nel modello di acquisto DTU.
Livelli di servizio Business Critical/Premium
Quando è abilitata per il livello di servizio Premium o Business Critical, la Zona di Ridondanza colloca le repliche in zone di disponibilità diverse nella stessa regione. Per eliminare un singolo punto di guasto, l'anello di controllo viene anche duplicato in più zone come tre anelli gateway (GW). Il routing verso uno specifico anello del gateway è controllato da Azure Traffic Manager. Poiché la configurazione a ridondanza di zona nei livelli di servizio Premium o Business Critical utilizza le repliche esistenti per posizionarle in diverse zone di disponibilità, è possibile abilitarla senza costi aggiuntivi. Se si seleziona una configurazione con ridondanza della zona, è possibile rendere i database Premium o Business Critical e i pool elastici resilienti a una serie molto più ampia di errori, incluse le interruzioni irreversibili del data center, senza modifiche della logica dell'applicazione. È possibile convertire anche eventuali database Premium o Business Critical o pool elastici alla configurazione a ridondanza di zona.
La versione ridondante per zona dell'architettura ad alta disponibilità per il livello di servizio Business Critical è illustrata nei diagrammi seguenti, in una regione a due o tre zone.
| Regione a due zone | Area a tre zone |
|---|---|

|

|
Quando il provisioning delle risorse di calcolo viene effettuato tra due zone di disponibilità:
- Per i dati business critical, l'archiviazione con disponibilità a ridondanza locale per i file di dati e di log viene sincronizzata tra due zone di disponibilità.
- Per altri livelli, il backup e l'archiviazione vengono sincronizzati tra tre zone di disponibilità nell'area.
- L'archiviazione con ridondanza di zona, come sempre, viene sincronizzata tra tre zone di disponibilità.
Quando il provisioning delle risorse di calcolo è effettuato in tre zone di disponibilità:
- Per l'archiviazione Business Critical, l'archiviazione con ridondanza locale per i dati e i log viene sincronizzata tra tre zone di disponibilità.
- Per altri livelli, il backup e l'archiviazione vengono sincronizzati tra tre zone di disponibilità nell'area.
Quando configuri i tuoi database Premium o Business Critical con ridondanza zonale, tieni presente quanto segue:
- Tutte le aree di Azure che supportano la zona di disponibilità supportano i database Premium e Business Critical con ridondanza zonale.
- Per la disponibilità con ridondanza della zona, la scelta di una finestra di manutenzione diversa da quella predefinita è attualmente disponibile nelle aree selezionate. Per altre informazioni, vedere Disponibilità della finestra di manutenzione in base all'area per il database SQL di Azure.
Livello di servizio Hyperscale
È possibile configurare la ridondanza della zona per i database nel livello di servizio Hyperscale. Per ulteriori informazioni, consulta Creare un database Hyperscale con ridondanza zonale.
L'abilitazione di questa configurazione garantisce la resilienza a livello di zona tramite la replica tra zone di disponibilità per tutti i livelli Hyperscale. Selezionando la ridondanza della zona, è possibile rendere i database Hyperscale resilienti a una serie di errori molto più ampia, comprese le interruzioni irreversibili dei data center, senza alcuna modifica della logica dell'applicazione.
La disponibilità a ridondanza zonale è supportata sia nei database autonomi Hyperscale che nei pool elastici Hyperscale. Per altre informazioni, vedere Panoramica dei pool elastici Hyperscale nel database SQL di Azure.
I diagrammi seguenti illustrano l'architettura sottostante per i database Hyperscale con ridondanza della zona, in un'area a due o tre zone:
| Regione a due zone | Area a tre zone |
|---|---|

|

|
Quando le risorse di calcolo vengono distribuite tra due zone di disponibilità
- Il backup e l'archiviazione vengono sincronizzati tra tre zone di disponibilità nell'area.
- L'archiviazione a ridondanza di zona è sempre sincronizzata tra tre zone di disponibilità.
Quando viene effettuato il provisioning delle risorse di calcolo in tre zone di disponibilità:
- Il backup e l'archiviazione vengono sincronizzati tra tre zone di disponibilità nell'area.
Tenere presente le limitazioni seguenti:
Tutte le aree di Azure che supportano le zone di disponibilità supportano anche i database Hyperscale con ridondanza di zona.
- Per l'hardware delle serie Premium Hyperscale e Premium ottimizzate per la memoria, la ridondanza di zona è disponibile in determinate aree. Per altre informazioni, vedere Disponibilità della serie Premium Hyperscale per area per il database SQL di Azure.
La configurazione con ridondanza della zona può essere specificata solo durante la creazione del database. Questa impostazione non può essere modificata dopo il provisioning della risorsa. Usare copia del database, ripristino temporizzato o creare una replica geografica per aggiornare la configurazione con ridondanza della zona per un database Hyperscale esistente. Quando si usa una di queste opzioni di aggiornamento, se il database di destinazione si trova in un'area diversa rispetto all'origine o se la ridondanza dell'archiviazione del backup del database di destinazione è diversa da quella del database di origine, l'operazione di copia sarà basata sull'ampiezza dei dati.
Per la disponibilità con ridondanza della zona, la scelta di una finestra di manutenzione diversa da quella predefinita è attualmente disponibile nelle aree selezionate. Per altre informazioni, vedere Disponibilità della finestra di manutenzione in base all'area per il database SQL di Azure.
Attualmente non è possibile specificare la ridondanza della zona durante la migrazione di un database a Hyperscale usando il portale di Azure. È tuttavia possibile specificare la ridondanza della zona usando PowerShell di Azure, l'interfaccia della riga di comando di Azure o l'API REST durante la migrazione di un database esistente da un altro livello di servizio del database SQL di Azure a Hyperscale. Di seguito un esempio dell'interfaccia della riga di comando di Azure:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`Per abilitare la configurazione con ridondanza della zona per Hyperscale, è necessaria almeno una replica di calcolo a disponibilità elevata e l'uso dell'archiviazione di backup con ridondanza della zona o geografica.
Disponibilità con ridondanza della zona del database
Nel database SQL di Azure un server è un costrutto logico che funge da punto amministrativo centrale per una raccolta di database. A livello di server, è possibile amministrare account di accesso, metodo di autenticazione, regole del firewall, regole di controllo, criteri di rilevamento delle minacce e gruppi di failover. I dati correlati ad alcune di queste funzionalità, ad esempio gli account di accesso e le regole del firewall, vengono archiviati nel database master. Analogamente, anche i dati per alcune DMV, ad esempio sys.resource_stats, vengono archiviati nel master database.
Quando un database con una configurazione a ridondanza di zona viene creato su un server logico, anche il database master associato al server viene automaticamente reso a ridondanza di zona. Ciò garantisce che in un'interruzione della zona le applicazioni che usano il database rimangano invariate perché le funzionalità dipendenti dal master database, ad esempio gli account di accesso e le regole del firewall, sono ancora disponibili. Rendere ridondante la zona del database master è un processo asincrono e richiederà del tempo per essere completato in background.
Quando nessuno dei database su un server è a ridondanza di zona, o quando si crea un server vuoto, il master database associato al server non è a ridondanza di zona. Per eseguire la migrazione del database SQL di Azure per usare la ridondanza della zona, seguire la procedura descritta in Eseguire la migrazione del database SQL di Azure al supporto della zona di disponibilità.
Per controllare la ZoneRedundant proprietà del master database, usare Azure PowerShell o l'interfaccia della riga di comando di Azure o i passaggi dell'API REST in Convalidare lo stato della zona di disponibilità del database SQL di Azure.
Testare la resilienza degli errori dell'applicazione
La disponibilità elevata è una parte fondamentale della piattaforma del database SQL che funziona in modo trasparente per l'applicazione di database. Tuttavia, è plausibile voler testare il modo in cui le operazioni di failover automatico avviate durante gli eventi pianificati o non pianificati influirebbero su un'applicazione prima di distribuirla nella produzione. È possibile attivare manualmente un failover chiamando un'API speciale per riavviare un database o un pool elastico. Nel caso di un database o pool elastico serverless o con provisioning per utilizzo generico con ridondanza tra zone, la chiamata API comporterebbe il reindirizzamento delle connessioni del client al nuovo database primario in una zona di disponibilità diversa dalla zona di disponibilità del database primario precedente. Oltre a testare l'impatto del failover sulle sessioni di database esistenti, è anche possibile verificare se ciò modifica le prestazioni end-to-end a causa di modifiche alla latenza di rete. Poiché l'operazione di riavvio è intrusiva e un numero elevato di esse potrebbe comportare stress per la piattaforma, è consentita una sola chiamata di failover ogni 15 minuti per ogni database o pool elastico.
Per altre informazioni sulla disponibilità elevata e il ripristino di emergenza del database SQL di Azure, vedere l'elenco di controllo disponibilità elevata e ripristino di emergenza - Database SQL di Azure.
È possibile avviare un failover usando PowerShell, l'API REST o l'interfaccia della riga di comando di Azure:
| Tipo di distribuzione | PowerShell | REST API | Azure CLI | Portale (anteprima) |
|---|---|---|---|---|
| Database | Invoke-AzSqlDatabaseFailover | Failover del database | az rest può essere usato per richiamare una chiamata API REST dall'interfaccia della riga di comando di Azure | Impostazioni > Riavvio manutenzione > |
| Pool elastico | Invoke-AzSqlElasticPoolFailover | Failover del pool elastico | az rest può essere usato per richiamare una chiamata API REST dall'interfaccia della riga di comando di Azure | Impostazioni > Riavvio manutenzione > |
Important
Il comando Failover non è disponibile per le repliche secondarie leggibili dei database Hyperscale.
Conclusion
Il database SQL di Azure offre una soluzione a disponibilità elevata predefinita pienamente integrata con la piattaforma Azure. È fortemente dipendente da Service Fabric per il rilevamento degli errori e il ripristino, da Azure Blob Storage per la protezione dei dati e da Availability Zones per una tolleranza di errore più elevata. Inoltre, il database SQL usa la tecnologia dei Gruppi di disponibilità Always On di SQL Server per la sincronizzazione dei dati e il failover. La combinazione di queste tecnologie consente alle applicazioni di ottenere tutti i vantaggi di un modello di archiviazione mista e supporta i contratti di servizio più esigenti.