Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo tutorial mostra come connettere il pool SQL serverless di Azure Synapse ai dati archiviati in un account di archiviazione di Azure per cui è abilitato Azure Data Lake Storage. Questa connessione consente di eseguire in modo nativo query e analisi SQL usando il linguaggio SQL nei dati in Archiviazione di Azure.
Questa esercitazione illustra come:
- Inserire dati in un account di archiviazione
- Creare un'area di lavoro Synapse Analytics (se non è già disponibile).
- Eseguire analisi sui dati nell'archivio BLOB
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Creare un account di archiviazione con uno spazio dei nomi gerarchico (Azure Data Lake Storage)
Vedere Creare un account di archiviazione da usare con Azure Data Lake Storage.
Verificare che all'account utente sia assegnato il ruolo di collaboratore ai dati del BLOB di archiviazione.
Importante
Assicurarsi di assegnare il ruolo nell'ambito dell'account di archiviazione. È possibile assegnare un ruolo al gruppo di risorse padre o alla sottoscrizione, ma si riceveranno errori relativi alle autorizzazioni fino a quando tali assegnazioni di ruolo non si propagheranno all'account di archiviazione.
Scaricare i dati relativi ai voli
In questa esercitazione vengono usati dati di volo provenienti da Bureau of Transportation Statistics. Per completare l'esercitazione, è necessario scaricare questi dati.
Scaricare il file On_Time_Reporting_Carrier_On_Time_Performance_1987_present_2016_1.zip. Questo file contiene i dati sui voli.
Decomprimere il contenuto del file compresso e prendere nota del nome e del percorso del file. Queste informazioni saranno necessarie in un passaggio successivo.
Copiare i dati di origine nell'account di archiviazione
Passare al nuovo account di archiviazione nel portale di Azure.
Selezionare Browser archiviazione->Contenitori BLOB->Aggiungi contenitore e creare un nuovo contenitore denominato dati.
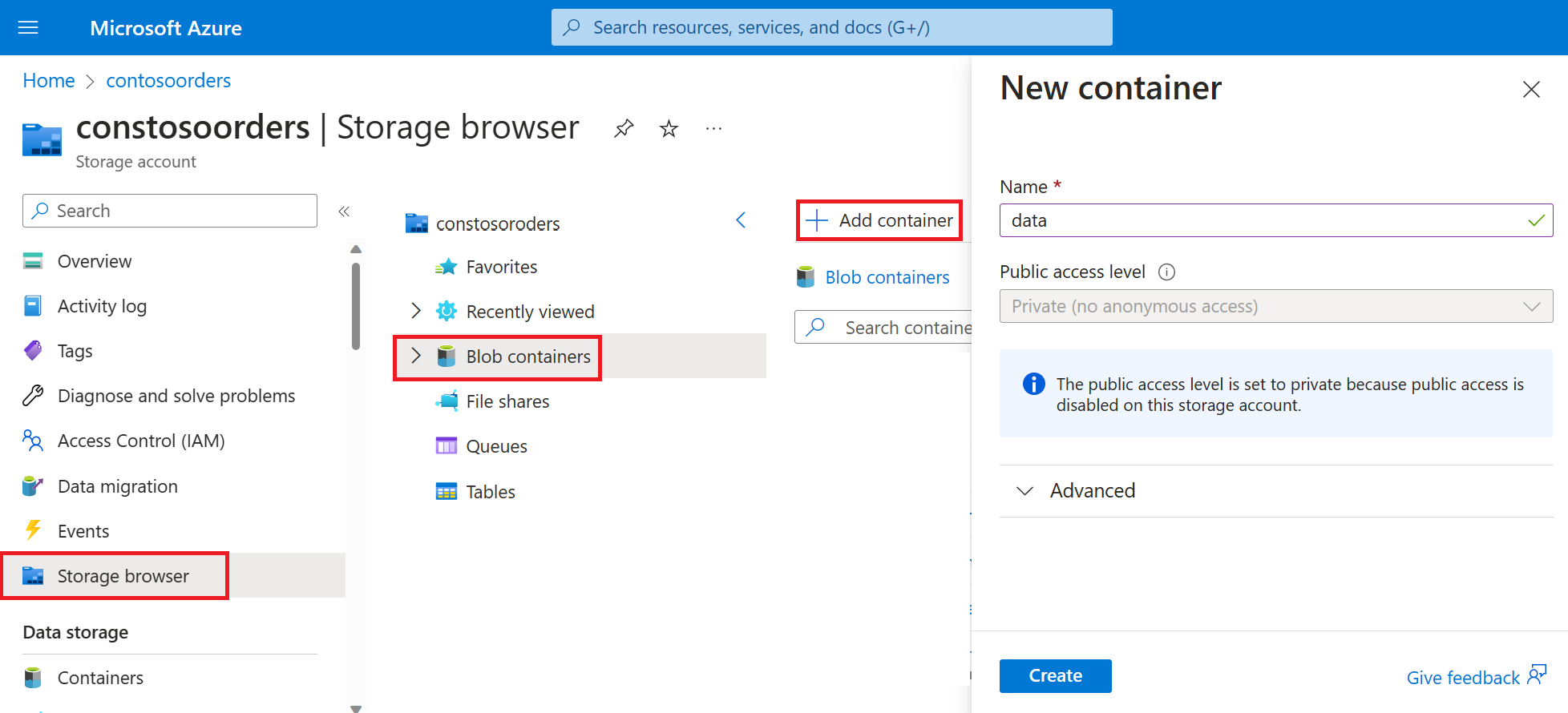
Nel browser archiviazione caricare il file
On_Time_Reporting_Carrier_On_Time_Performance_1987_present_2016_1.csvnella cartella dati.
Creare una Azure Synapse workspace
Creare un'area di lavoro Synapse nel portale di Azure. Quando si crea l'area di lavoro, usare questi valori:
- Sottoscrizione: selezionare la sottoscrizione di Azure associata all'account di archiviazione.
- Gruppo di risorse: selezionare il gruppo di risorse in cui è stato collocato l'account di archiviazione.
-
Area: selezionare l'area dell'account di archiviazione (ad esempio
Central US). - Nome: immettere un nome per l'area di lavoro Synapse.
- Accesso amministratore SQL: immettere il nome utente dell'amministratore di SQL Server.
- Password amministratore SQL: immettere la password dell'amministratore di SQL Server.
- Valori dei tag: accettare i valori predefiniti.
Trovare il nome dell'endpoint di Synapse SQL (facoltativo)
Il nome dell'endpoint SQL serverless consente di connettersi con qualsiasi strumento in grado di eseguire query T-SQL su SQL Server o sul database SQL di Azure (ad esempio: SQL Server Management Studio, l'estensione MSSQL in Visual Studio Code, o Power BI).
Per trovare il nome completo del server, procedere come segue:
- Selezionare l'area di lavoro a cui connettersi.
- Passare a Panoramica.
- Individuare il nome completo del server.
- Per un pool SQL dedicato, usare l'endpoint SQL.
- Per il pool SQL serverless, usare l'endpoint SQL su richiesta.
In questa esercitazione si usa Synapse Studio per eseguire query sui dati dal file CSV caricato nell'account di archiviazione.
Usare Synapse Studio per esplorare i dati
Aprire Synapse Studio. Vedere Aprire Synapse Studio
Creare uno script SQL ed eseguire questa query per visualizzare il contenuto del file:
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://<storage-account-name>.dfs.core.windows.net/<container-name>/folder1/On_Time.csv', FORMAT='CSV', PARSER_VERSION='2.0' ) AS [result]Per informazioni su come creare uno script SQL in Synapse Studio, vedere Script SQL di Synapse Studio in Azure Synapse Analytics
Pulire le risorse
Quando non sono più necessari, eliminare il gruppo di risorse e tutte le risorse correlate. A tal fine, selezionare il gruppo di risorse per l'account di archiviazione e l'area di lavoro, quindi fare clic su Elimina.