Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'editor no-code semplifica lo sviluppo di un processo di Analisi di flusso per elaborare i dati di streaming in tempo reale. Usare la funzionalità di trascina e rilascia senza scrivere codice. L'esperienza offre un'area di disegno in cui è possibile connettersi alle origini di input per visualizzare rapidamente i dati di streaming. È quindi possibile trasformarlo prima di inviarlo alle destinazioni.
Usando l'editor senza codice, è possibile:
- Modificare gli schemi di input.
- Eseguire operazioni di preparazione dei dati come join e filtri.
- Gestire scenari avanzati come le aggregazioni di finestre temporali (finestre a cascata, salto e sessione) per le operazioni group-by.
Dopo aver creato ed eseguito i processi di analisi di flusso, è possibile rendere facilmente operativi i carichi di lavoro di produzione. Usare il set corretto di metriche predefinite per il monitoraggio e la risoluzione dei problemi. I processi di analisi di flusso vengono fatturati in base al modello tariffario quando vengono eseguiti.
Prerequisiti
Prima di sviluppare i processi di Analisi di flusso usando l'editor senza codice, assicurarsi di soddisfare questi requisiti:
- Le sorgenti di input di streaming e le risorse di destinazione per il processo di analisi di flusso devono essere accessibili pubblicamente e non possono trovarsi in una rete virtuale di Azure.
- È necessario disporre delle autorizzazioni necessarie per accedere alle sorgenti di input e output di streaming.
- È necessario mantenere le autorizzazioni per creare e modificare le risorse di Analisi di flusso di Azure.
Nota
L'editor no-code non è attualmente disponibile nell'area Cina.
Processo di Analisi di Flusso di Azure
Un processo di analisi di flusso si basa su tre componenti principali: input di streaming, trasformazionie output. È possibile includere tutti i componenti desiderati, ad esempio più input, rami paralleli con più trasformazioni e più output. Per altre informazioni, vedere Documentazione di Analisi di flusso di Azure.
Nota
Le funzionalità e i tipi di output seguenti non sono disponibili quando si usa l'editor no-code:
- Funzioni definite dall'utente.
- Modifica delle query nella pagina di query Analisi di flusso di Azure. Tuttavia, è possibile visualizzare la query generata dall'editor senza codice nella pagina di query.
- Aggiunta di input e output nelle pagine di input e output dell'analisi del flusso Azure. Tuttavia, è possibile visualizzare gli input e gli output generati dall'editor senza codice nella pagina di input e output.
- I tipi di output seguenti non sono disponibili: funzione Azure, Azure Data Lake Storage Gen1, database PostgreSQL, bus di servizio coda/argomento, archiviazione tabelle.
Per accedere all'editor senza codice per la creazione del lavoro di analisi flussi, utilizzare uno dei seguenti approcci:
Tramite il portale di Analisi di flusso di Azure (anteprima): creare un processo di analisi di flusso e quindi selezionare l'editor senza codice nella scheda Inizio nella pagina Panoramica, oppure selezionare Editor senza codice nel riquadro sinistro.

Tramite il portale di Hub eventi di Azure: aprire un'istanza di Hub eventi. Selezionare Elaborare dati, poi selezionare un qualunque modello predefinito.

I modelli predefiniti consentono di sviluppare ed eseguire un processo per risolvere vari scenari, tra cui:
- Acquisire dati da Hub eventi nel formato Delta Lake (anteprima)
- Filtrare e inserire in Azure Synapse SQL
- Acquisizione dei dati di Hub eventi nel formato Parquet in Azure Data Lake Storage Gen2
- Materializzazione dei dati in Azure Cosmos DB
- Filtrare e inserire in Azure Data Lake Storage Gen2
- Arricchire i dati e inserire nell’hub eventi
- Trasformare e archiviare i dati nel database SQL di Azure
- Filtrare e inserire in Esplora dati di Azure


Lo screenshot seguente mostra un processo di analisi di flusso completo. Evidenzia tutte le sezioni disponibili durante l'attività di creazione.

- Ribbon: sul ribbon, le sezioni seguono l'ordine di un classico processo di analisi: un hub eventi come input (noto anche come fonte dati), trasformazioni (operazioni di estrazione, trasformazione e caricamento in streaming), output, un pulsante per salvare i progressi e un pulsante per avviare il lavoro.
- Visualizzazione diagramma: questa visualizzazione è una rappresentazione grafica del processo di Analisi di flusso, dall'input alle operazioni agli output.
- Riquadro laterale: a seconda del componente selezionato nella visualizzazione diagramma, vengono visualizzate le impostazioni per modificare input, trasformazione o output.
- Schede per l'anteprima dei dati, errori di composizione, log di runtime e metriche: per ogni scheda, l'anteprima dei dati mostra i risultati per ciascun passaggio (in tempo reale per gli input; su richiesta per trasformazioni e output). Questa sezione riepiloga anche eventuali errori o avvisi di creazione che potrebbero verificarsi nel processo in fase di sviluppo. Selezionando ogni errore o avviso viene selezionata la trasformazione. Fornisce anche le metriche di processo per monitorare l'integrità del processo in esecuzione.
Input dei dati in streaming
L'editor senza codice supporta l’input dei dati in streaming da tre tipi di risorse:
- Hub eventi di Azure
- Hub IoT di Azure
- Azure Data Lake Storage Gen2
Per altre informazioni sugli input dei dati di flusso, vedere Trasmettere dati come input in Analisi di flusso.
Nota
L'editor senza codice nel portale di Hub eventi di Azure include solo Hub eventi come opzione di input.

Hub eventi di Azure come input di flusso
Hub eventi di Azure è una piattaforma di streaming di Big Data e un servizio di inserimento di eventi. È in grado di ricevere ed elaborare milioni di eventi al secondo. È possibile trasformare e archiviare i dati inviati a un hub eventi tramite qualsiasi provider di analisi in tempo reale o adattatore per batch e archiviazione.
Per configurare un hub eventi come input per il processo, selezionare l'icona dell'Hub eventi. Nella visualizzazione diagramma compare una piastrella, che comprende un riquadro laterale per la configurazione e la connessione.
Quando ci si connette all'hub eventi nell'editor senza codice, creare un nuovo gruppo di consumatori, che è l'opzione predefinita. Questo approccio consente di impedire all'hub eventi di raggiungere il limite di lettori simultanei. Per altre informazioni sui gruppi di consumer e sulla necessità di selezionare un gruppo di consumer esistente o crearne uno nuovo, vedere Gruppi di consumer.
Se l'hub eventi si trova nel piano Basic, è possibile usare solo il gruppo consumer $Default esistente. Se l'hub eventi si trova in un piano Standard o Premium, è possibile creare un nuovo gruppo di consumer.

Quando ci si connette all'hub eventi, se si seleziona Managed Identity come modalità di autenticazione, il ruolo di Data Owner per Hub eventi di Azure viene concesso all'identità gestita per il processo di Stream Analytics. Per altre informazioni sulle identità gestite per un hub eventi, vedere Usare le identità gestite per accedere a un hub eventi da un processo di Analisi di flusso di Azure.
Le identità gestite annullano le limitazioni dei metodi di autenticazione basati sull'utente. Queste limitazioni includono la necessità di ripetere l'autenticazione a causa delle modifiche apportate alla password o delle scadenze dei token utente che si verificano ogni 90 giorni.

Dopo aver configurato i dettagli dell'hub eventi e aver selezionato Connetti, è possibile aggiungere manualmente i campi usando + Aggiungi campo se si conoscono i nomi dei campi. Per rilevare automaticamente i campi e i tipi di dati in base a un campione dei messaggi in arrivo, selezionare Rilevare automativamente i campi. Se necessario, la selezione del simbolo dell'ingranaggio consente di modificare le credenziali.
Quando i processi di analisi di flusso rilevano i campi, questi vengono visualizzati nell'elenco. Viene visualizzata anche un'anteprima in tempo reale dei messaggi in ingresso nella tabella Anteprima dati nella visualizzazione diagramma.
Modificare i dati di input
È possibile modificare i nomi dei campi, rimuovere i campi, modificare il tipo di dati o modificare l'ora dell'evento (Contrassegna come ora evento: clausola TIMESTAMP BY se un campo di tipo datetime) selezionando il simbolo a tre punti accanto a ogni campo. È anche possibile espandere, selezionare e modificare i campi annidati dai messaggi in arrivo, come illustrato nell'immagine seguente.
Suggerimento
Questo processo si applica anche ai dati di input di hub IoT di Azure e Azure Data Lake Storage Gen2.

I tipi di dati disponibili sono:
- DateTime: campo data e ora in formato ISO.
- Float: numero decimale.
- Int: numero intero.
- Record: oggetto annidato con più record.
- Stringa: Testo.
Hub IoT di Azure come input per lo streaming
L'hub IoT di Azure è un servizio gestito, ospitato nel cloud, che funge da hub centrale di messaggi per le comunicazioni bidirezionali tra l'applicazione di IoT e i relativi dispositivi collegati. È possibile usare i dati del dispositivo IoT inviati all'hub IoT come input per un processo di Analisi di flusso.
Nota
È possibile usare hub IoT di Azure input nell'editor senza codice nel portale di Analisi di flusso di Azure.
Per aggiungere un hub IoT come input di flusso per il processo, selezionare l'hub IoT in Input dalla barra multifunzione. Immettere quindi le informazioni necessarie nel riquadro destro per connettere l'hub IoT alla tua attività. Per altre informazioni sui dettagli di ogni campo, vedere Trasmettere dati dall'Hub IoT al processo di Stream Analytics.

Azure Data Lake Storage Gen2 come ingresso per lo streaming
Azure Data Lake Storage Gen2 (ADLS Gen2) è una soluzione data lake aziendale basata sul cloud. È progettato per archiviare grandi quantità di dati in qualsiasi formato e facilitare carichi di lavoro analitici di Big Data. Analisi di flusso può elaborare i dati archiviati in ADLS Gen2 come flusso di dati. Per ulteriori informazioni su questo tipo di input, consultare Stream Analytics: Trasmissione dei dati da ADLS Gen2 al lavoro di Stream Analytics.
Nota
È possibile usare Azure Data Lake Storage Gen2 input nell'editor senza codice nel portale di Analisi di flusso di Azure.
Per aggiungere un ADLS Gen2 come input di flusso per il processo, selezionare ADLS Gen2 in Input dalla barra multifunzione. Compilare quindi le informazioni necessarie nel riquadro destro, per collegare ADLS Gen2 all'attività. Per ulteriori informazioni sui dettagli di ciascun campo, vedere Stream data da ADLS Gen2 a Stream Analytics Job.

Input dei dati di riferimento
I dati di riferimento sono statici o cambiano lentamente nel tempo. In genere, è possibile usarlo per arricchire i flussi in ingresso ed eseguire ricerche nel processo. Ad esempio, è possibile unire gli input del flusso dei dati ai dati di riferimento, proprio come si esegue un join SQL per cercare valori statici. Per maggiori informazioni sugli input dei dati di riferimento, vedere Uso dei dati di riferimento per le ricerche in Analisi di flusso.
L'editor senza codice supporta ora due sorgenti di dati di riferimento:
- Azure Data Lake Storage Gen2
- database SQL di Azure

Azure Data Lake Storage Gen2 come dati di riferimento
Modellare i dati di riferimento come sequenza di BLOB in ordine crescente della combinazione di data e ora specificata nel nome del BLOB. È possibile aggiungere blob alla fine della sequenza solo utilizzando una data e un'ora che siano maggiori rispetto a quella specificata dall'ultimo blob nella sequenza. Definire i BLOB nella configurazione di input.
Prima di tutto, nella sezione Input sulla barra multifunzione, selezionare Riferimento ADLS Gen2. Per informazioni dettagliate su ogni campo, vedere la sezione relativa all'archiviazione BLOB di Azure in Usare i dati di riferimento per le ricerche in Analisi di flusso.

Caricare quindi un file di matrice JSON. Il sistema rileva i campi. Usare questi dati di riferimento per eseguire la trasformazione con dati di input in streaming da Event Hubs.

Database SQL di Azure come dati di riferimento
È possibile usare il database SQL di Azure come dati di riferimento per il processo di analisi di flusso nell'editor senza codice. Per maggiori informazioni, vedere la sezione relativa al database SQL in Usare i dati di riferimento per le ricerche in Analisi di flusso.
Per configurare il database SQL come input di dati di riferimento, selezionare Database SQL di riferimento nella sezione Input della barra multifunzione. Immettere quindi le informazioni per connettere il database di riferimento e selezionare la tabella con le colonne necessarie. È anche possibile recuperare i dati di riferimento dalla tabella modificando manualmente la query SQL.

Trasformazioni
Le trasformazioni dei dati di streaming sono intrinsecamente diverse dalle trasformazioni dei dati batch. Quasi tutti i dati di streaming hanno un componente temporale, che influisce sulle attività di preparazione dei dati coinvolte.
Per aggiungere una trasformazione dati di flusso al processo, selezionare il simbolo della trasformazione nella sezioneOperazioni sulla barra multifunzione per quella trasformazione. Il rispettivo riquadro viene aggiunto alla visualizzazione diagramma. Dopo averla selezionata, viene visualizzato il riquadro laterale per la trasformazione per configurarla.

Filtro
Usare la trasformazione Filtro per filtrare gli eventi in base al valore di un campo nell'input. A seconda del tipo di dati (numero o testo), la trasformazione mantiene i valori corrispondenti alla condizione selezionata.

Nota
All'interno di ogni riquadro, vengono visualizzate informazioni su cos'altro è necessario affinché la trasformazione sia pronta. Ad esempio, quando si aggiunge un nuovo riquadro, viene visualizzato un messaggio Di installazione obbligatorio . Se manca un connettore del nodo, viene visualizzato un messaggio di errore o un messaggio di avviso .
Gestire i campi
La trasformazione Gestisci campi consente di aggiungere, rimuovere o rinominare campi provenienti da un input o da un'altra trasformazione. Le impostazioni nel riquadro laterale offrono la possibilità di aggiungere un nuovo campo selezionando Aggiungi campo o aggiungendo tutti i campi contemporaneamente.

È anche possibile aggiungere un nuovo campo usando le funzioni predefinite per aggregare i dati da upstream. Attualmente, le funzioni predefinite supportate sono alcune funzioni in Funzioni stringa, Funzioni di data e ora e Funzioni matematiche. Per altre informazioni sulle definizioni di queste funzioni, vedere Funzioni predefinite (Analisi di flusso di Azure).

Suggerimento
Dopo aver configurato un riquadro, la visualizzazione diagramma offre una panoramica delle impostazioni nel riquadro. Ad esempio, nell'area Gestisci campi dell'immagine precedente si vedono i primi tre campi gestiti con i rispettivi nuovi nomi assegnati. Ogni riquadro contiene informazioni pertinenti.
Aggregazione
È possibile usare la trasformazione Aggrega per calcolare un'aggregazione (Somma, Minimo, Massimo o Media) ogni volta che si verifica un nuovo evento in un periodo di tempo. Questa operazione consente inoltre di filtrare o suddividere l'aggregazione in base ad altre dimensioni nei dati. È possibile includere una o più aggregazioni nella stessa trasformazione.
Per aggiungere un'aggregazione, selezionare il simbolo di trasformazione. Connettere quindi un input, selezionare l'aggregazione, aggiungere eventuali dimensioni filtro o sezione e selezionare il periodo di tempo in cui viene calcolata l'aggregazione. In questo esempio, si calcola la somma del valore del pedaggio per stato di provenienza del veicolo negli ultimi 10 secondi.

Per aggiungere un'altra aggregazione alla stessa trasformazione, selezionare Aggiungi funzione di aggregazione. Il filtro o la sezione si applica a tutte le aggregazioni nella trasformazione.
Unisci.
Usare la trasformazione Join per combinare gli eventi di due input in base alle coppie di campi selezionate. Se non selezioni una coppia di campi, l'unione si basa sul tempo per impostazione predefinita. Il valore predefinito è ciò che rende questa trasformazione diversa da una batch.
Come per i normali join, sono disponibili opzioni per la logica di join:
- Inner join: includere solo i record di entrambe le tabelle in cui i valori della coppia corrispondono. In questo esempio, questa è la posizione in cui la targa corrisponde a entrambi gli input.
- Left outer join: includere tutti i record della tabella di sinistra (prima) e solo i record della seconda tabella che corrispondono alla coppia di campi. Se non esiste alcuna corrispondenza, i campi del secondo input sono vuoti.
Per selezionare il tipo di join, selezionare il simbolo per il tipo preferito nel riquadro laterale.
Infine, selezionare l'intervallo di tempo su cui si desidera calcolare il join. In questo esempio, il join esamina gli ultimi 10 secondi. Più lungo è il periodo, meno frequente è l'output e più risorse di elaborazione usate per la trasformazione.
Per impostazione predefinita, l'output include tutti i campi di entrambe le tabelle. I prefissi a sinistra (primo nodo) e a destra (secondo nodo) consentono di distinguere l'origine.

Raggruppa per
Usare la trasformazione Raggruppa per per calcolare le aggregazioni in tutti gli eventi in un determinato intervallo di tempo. Puoi raggruppare i valori di uno o più campi. È simile alla trasformazione Aggregazione, ma offre maggiori opzioni per le aggregazioni. Include anche opzioni più complesse per le finestre temporali. Come Aggregazione, è anche possibile aggiungere più aggregazioni per trasformazione.
Le aggregazioni disponibili nella trasformazione sono:
- Media
- Conteggio
- Massimo
- Minimo
- Percentile (continuo e discreto)
- Deviazione standard
- Sum
- Varianza
Per configurare la trasformazione:
- Selezionare l'aggregazione preferita.
- Selezionare il campo su cui si vuole aggregare.
- Selezionare un campo facoltativo di raggruppamento se si desidera ottenere il calcolo aggregato su un'altra dimensione o categoria. Ad esempio: Stato.
- Seleziona la funzione per le finestre temporali.
Per aggiungere un'altra aggregazione alla stessa trasformazione, selezionare Aggiungi funzione di aggregazione. Tenere presente che il campo Group by e la funzione windowing si applicano a tutte le aggregazioni nella trasformazione.

Un indicatore orario per la fine dell'intervallo di tempo viene visualizzato come parte dell'output della trasformazione per riferimento. Per maggiori informazioni sulle finestre temporali supportate dai processi di analisi di flusso, vedere Funzioni di windowing (Analisi di flusso di Azure).
Unione
Usare la trasformazione Unione per connettere due o più input. Aggiungere eventi con campi condivisi (con lo stesso nome e tipo di dati) in una tabella. L'output esclude i campi che non corrispondono.
Espandi matrice
Usare la trasformazione Espandi matrice per creare una nuova riga per ogni valore all'interno di una matrice.

Output di streaming
L'esperienza di trascinamento della selezione senza codice supporta al momento diversi sink di output per archiviare i dati in tempo reale elaborati.

Azure Data Lake Storage Gen2
Data Lake Storage Gen2 usa Archiviazione di Azure come base per la compilazione di Enterprise Data Lake (EDL) in Azure. Questo servizio è in grado di gestire diversi petabyte di informazioni supportando al tempo stesso centinaia di gigabit di velocità effettiva. Consente di gestire facilmente grandi quantità di dati. L'Archiviazione BLOB di Azure offre una soluzione conveniente e scalabile per archiviare grandi quantità di dati non strutturati nel cloud.
Nella sezione Output sulla barra multifunzione, selezionare ADLS Gen2 come output per il processo di analisi di flusso. Selezionare quindi il contenitore in cui si vuole inviare l'output del processo. Per maggiori informazioni sull'output di Azure Data Lake Gen2 per un processo di Stream Analytics, vedere Archiviazione Blob e output di Azure Data Lake Gen2 da Analisi di flusso di Azure.
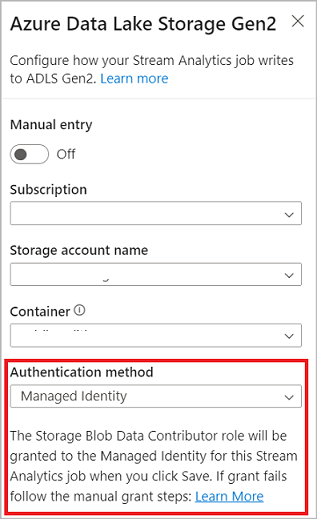
Quando ci si connette a Azure Data Lake Storage Gen2, se si seleziona Identità gestita come modalità di autenticazione, all'identità gestita viene concesso il ruolo Collaboratore ai dati del BLOB di archiviazione per il processo di Analisi di flusso. Per altre informazioni sulle identità gestite per Azure Data Lake Storage Gen2, vedere Usare le identità gestite per autenticare il processo di Analisi di flusso di Azure nell'Archiviazione BLOB di Azure.
Le identità gestite annullano le limitazioni dei metodi di autenticazione basati sull'utente. Queste limitazioni includono la necessità di ripetere l'autenticazione a causa delle modifiche apportate alla password o delle scadenze dei token utente che si verificano ogni 90 giorni.
Consegna exactly-once (anteprima) supportato in ADLS Gen2 come output dell'editor senza codice. È possibile abilitarlo nella sezione Modalità di scrittura nella configurazione di ADLS Gen2. Per altre informazioni su questa funzionalità, vedere Consegna exactly-once (anteprima) in Azure Data Lake Gen2.

La scrittura nella tabella Delta Lake (anteprima) è supportata in ADLS Gen2 come output dell'editor senza codice. È possibile accedere a questa opzione nella sezione Serializzazione nella configurazione di ADLS Gen2. Per maggiori informazioni su questa funzionalità, vedere Scrittura nella tabella Delta Lake.

Azure Synapse Analytics
I processi di Analisi di flusso di Azure possono inviare output a una tabella del pool SQL dedicata in Azure Synapse Analytics e possono elaborare a una velocità effettiva fino a 200 MB al secondo. Stream Analytics supporta le esigenze più impegnative di analisi in tempo reale e l'elaborazione dei dati in tempo reale per carichi di lavoro come la creazione di report e i dashboard.
Importante
La tabella del pool SQL dedicata deve esistere prima di poterla aggiungere come output per il processo di Analisi di flusso. Lo schema della tabella deve corrispondere ai campi e ai relativi tipi nell'output del processo.
Nella sezione Output sulla barra multifunzione, selezionare Synapse come output per il processo di analisi di flusso. Selezionare quindi la tabella del pool SQL in cui si vuole inviare l'output del processo. Per maggiori informazioni sull'output di Azure Synapse per un processo di Stream Analytics, vedere Output di Azure Synapse Analytics da Analisi di flusso di Azure.
Azure Cosmos DB
Azure Cosmos DB è un servizio di database distribuito a livello globale che offre scalabilità elastica illimitata in tutto il mondo. Offre anche query avanzate e indicizzazione automatica su modelli di dati indipendenti dallo schema.
Nella sezione Output sulla barra multifunzione, selezionare CosmosDB come output per il processo di analisi di flusso. Per maggiori informazioni sull'output di Azure Cosmos DB per un processo di analisi di flusso, vedere Output di Azure Cosmos DB da Analisi di flusso di Azure.
Quando ci si connette a Azure Cosmos DB, se si seleziona Managed Identity come modalità di autenticazione, il ruolo Collaboratore viene concesso all'identità gestita per il processo di Analisi di flusso. Per altremaggiori informazioni sulle identità gestite per Azure Cosmos DB, vedere Usare le identità gestite per accedere ad Azure Cosmos DB da un processo di Analisi di flusso di Azure (anteprima).
L'output Azure Cosmos DB nell'editor senza codice supporta anche il metodo di autenticazione delle identità gestite. Questo metodo offre gli stessi vantaggi offerti dall'output di ADLS Gen2.
database SQL di Azure
database SQL di Azure è un motore di database PaaS (Platform as a Service) completamente gestito che consente di creare un livello di archiviazione dati a disponibilità elevata e ad alte prestazioni per applicazioni e soluzioni in Azure. Usando l'editor senza codice, è possibile configurare i processi di Analisi di flusso di Azure per scrivere i dati elaborati in una tabella esistente nel database SQL.
Per configurare il database SQL di Azure come output, selezionare Database SQL nella sezione Output sulla barra multifunzione. Immettere quindi le informazioni necessarie per connettersi al database SQL e selezionare la tabella in cui scrivere i dati.
Importante
La tabella del database SQL di Azure deve esistere prima che sia possibile aggiungerla come output al processo di analisi di flusso. Lo schema della tabella deve corrispondere ai campi e ai relativi tipi nell'output del processo.
Per maggiori informazioni sull'output del database SQL di Azure per un processo di analisi di flusso, vedere Output del database SQL di Azure da Analisi di flusso di Azure.
Hub eventi
Con i dati in tempo reale provenienti da ASA, l'editor senza codice può trasformare e arricchire i dati e quindi restituire i dati in un altro hub eventi. È possibile scegliere l'output Hub eventi quando si configura il processo di Analisi di flusso di Azure.
Per configurare Hub eventi come output, selezionare Hub eventi nella sezione Output sulla barra multifunzione. Immettere quindi le informazioni necessarie per connettersi all'hub eventi in cui scrivere i dati.
Per ulteriori informazioni sull'output di Event Hubs per un job di Stream Analytics, vedere Event Hubs output da Analisi di flusso di Azure.
Esplora dati di Azure
Esplora dati di Azure è una piattaforma di analisi dei Big Data completamente gestita e ad alte prestazioni che semplifica l'analisi di grandi volumi di dati. È anche possibile usare Esplora dati di Azure come output per il processo Analisi di flusso di Azure usando l'editor senza codice.
Per configurare Esplora dati di Azure come output, selezionare Esplora dati di Azure nella sezione Outputs sulla barra multifunzione. Immettere quindi le informazioni necessarie per connettersi al database Esplora dati di Azure e specificare la tabella in cui scrivere i dati.
Importante
La tabella deve esistere nel database selezionato e lo schema della tabella deve corrispondere esattamente ai campi e ai relativi tipi nell'output del processo.
Per maggiori informazioni sull'output di Esplora dati di Azure per un processo di Stream Analytics, vedere Output di Analisi di flusso di Azure da Analisi di Flusso (anteprima).
Power BI
Power BI offre un'esperienza di visualizzazione completa per il risultato dell'analisi dei dati. Usando Power BI output in Analisi di flusso, i dati di streaming elaborati vengono scritti in un set di dati di streaming Power BI e quindi è possibile usarlo per creare il dashboard di Power BI quasi in tempo reale.
Per configurare Power BI come output, selezionare Power BI nella sezione Outputs sulla barra multifunzione. Immettere quindi le informazioni necessarie per connettersi all'area di lavoro Power BI e specificare i nomi per il set di dati di streaming e la tabella in cui scrivere i dati. Per maggiori informazioni sui dettagli di ogni campo, vedere Output di Power BI da Analisi di flusso di Azure.
Anteprima dei dati, errori di redazione, log di esecuzione e metriche
L'utilizzo senza codice offre strumenti che consentono di creare, eseguire il debug e valutare le prestazioni della tua pipeline di analisi per i dati di streaming.
Anteprima dei dati in tempo reale per gli input
Quando ci si connette a un'origine di input, ad esempio un hub eventi, e si seleziona il relativo riquadro nella visualizzazione diagramma (scheda Anteprima dati), viene visualizzata un'anteprima in tempo reale dei dati in ingresso se sono soddisfatte tutte le condizioni seguenti:
- Viene eseguito l'inoltro dei dati.
- L'input è configurato correttamente.
- Vengono aggiunti campi.
Come illustrato nello screenshot seguente, se si vuole visualizzare o eseguire il drill-down in un elemento specifico, è possibile sospendere l'anteprima (1). Oppure puoi riavviarlo se hai finito.
È anche possibile visualizzare i dettagli di un record specifico, una cella nella tabella, selezionandola e quindi selezionando Mostra/Nascondi dettagli (2). Lo screenshot mostra la visualizzazione dettagliata di un oggetto annidato in un record.

Anteprima statica per trasformazioni e output
Dopo aver aggiunto e configurato tutti i passaggi nella visualizzazione diagramma, è possibile testarne il comportamento selezionando Ottieni anteprima statica.

Quando si seleziona il pulsante, il processo di Analisi di flusso valuta tutte le trasformazioni e gli output per assicurarsi che siano configurati correttamente. Analisi di flusso visualizza quindi i risultati nell'anteprima dei dati statici, come illustrato nell'immagine seguente.

È possibile aggiornare l'anteprima selezionando Aggiorna anteprima statica (1). Quando si aggiorna l'anteprima, il processo di analisi di flusso accetta nuovi dati dall'input e valuta tutte le trasformazioni. In seguito, invia nuovamente l'output con tutti gli aggiornamenti che potrebbero essere stati eseguiti. L'opzione Mostra/Nascondi dettagli è disponibile anche (2).
Errori di redazione
Se sono presenti errori o avvisi di creazione, nella scheda Errori di creazione vengono elencati, come illustrato nello screenshot seguente. L'elenco include informazioni dettagliate sull'errore o l'avviso, il tipo di scheda (input, trasformazione o output), il livello di errore e una descrizione dell'errore o avviso.

Log di runtime
I log di runtime vengono visualizzati a livello di avviso, errore o informazioni quando un processo è in esecuzione. Questi log sono utili quando si vuole modificare la topologia o la configurazione del processo di analisi di flusso per la risoluzione dei problemi. Attivare i log di diagnostica e inviarli all'area di lavoro Log Analytics in Settings per ottenere altre informazioni dettagliate sui processi in esecuzione per il debug.

Nell'esempio di screenshot seguente l'utente configura l'output del database SQL con uno schema di tabella che non corrisponde ai campi dell'output del processo.

Metriche
Se il processo è in esecuzione, è possibile monitorare l'integrità del processo nella scheda Metriche. Le quattro metriche visualizzate per impostazione predefinita sono Ritardo della filigrana, Eventi di input, Eventi di input arretrati e Eventi di output. Usare queste metriche per comprendere se gli eventi fluiscono dentro e fuori dal processo senza alcun arretrato di input.

È possibile selezionare più metriche dall'elenco. Per comprendere in dettaglio tutte le metriche, vedere Metriche dei processi di Analisi di flusso di Azure.
Avviare un job di Stream Analytics
È possibile salvare il lavoro in qualsiasi momento mentre lo crei. Dopo aver configurato gli input, le trasformazioni e gli output di streaming per il processo, è possibile avviare il processo.
Nota
Anche se l'editor senza codice nel portale di Analisi di flusso di Azure è in anteprima, il servizio Analisi di flusso di Azure è disponibile a livello generale.

È possibile configurare queste opzioni:
-
Ora di inizio dell'output: quando si avvia un processo, selezionare un orario per avviare la creazione dell'output.
- Ora: questa opzione rende il punto iniziale del flusso di eventi di output uguale a quello dell'avvio del processo.
- Personalizzato: scegliere il punto iniziale dell'output.
- Ultimo arresto: questa opzione è disponibile quando il processo è stato avviato ma poi arrestato manualmente o non è riuscito. Quando si sceglie questa opzione, viene usata l'ora dell'ultimo output per riavviare il processo, quindi non vengono persi dati.
- Unità di streaming: le Unità di streaming (SU) rappresentano la quantità di calcolo e memoria assegnata al processo durante la sua esecuzione. Se non sei sicuro di quanti SUs scegliere, inizia con tre e regola in base alle esigenze.
- Gestione degli errori dei dati di output: i criteri per la gestione degli errori dei dati di output si applicano solo quando l'evento di output prodotto da un processo di analisi di flusso non è conforme allo schema del sink di destinazione. Configurare il criterio scegliendo Riprova o Rilascia. Per maggiori informazioni, vedere Criteri di gestione degli errori di output in Analisi di flusso di Azure.
- Avvio: questo pulsante avvia il processo di analisi di flusso.

Elenco dei job di Stream Analytics nel portale di Hub eventi di Azure
Per visualizzare un elenco di tutti i processi di analisi di flusso che hai creato usando l'esperienza di trascinamento senza codice nel portale di Hub eventi di Azure, selezionare Elabora dati>processi di analisi di flusso.

Ecco gli elementi della scheda Processi Stream Analytics:
- Filtro: Filtra l'elenco in base al nome dell'attività.
- Aggiorna: attualmente l'elenco non viene aggiornato automaticamente. Usare il pulsante Aggiorna per aggiornare l'elenco e visualizzare l’ultimo stato.
- Nome processo: il nome in questa area è quello che hai specificato nel primo passaggio della creazione del processo. Non è possibile modificarlo. Selezionare il nome del processo per aprire il processo nell'esperienza di trascinamento e rilascio senza codice, in cui è possibile fermare il processo, modificarlo e avviarlo di nuovo.
- Stato: quest'area mostra lo stato dell'attività. Selezionare Aggiornanella parte superiore dell'elenco per visualizzare l’ultimo stato.
- Unità di streaming: questa sezione mostra il numero di unità di streaming selezionate all'avvio del lavoro.
- Limite output: questa area fornisce un indicatore di attività per i dati che il processo produce. Tutti gli eventi prima dell’indicatore orario sono già calcolati.
- Monitoraggio dei processi: selezionare Apri metriche per visualizzare le metriche correlate a questo processo di Analisi di flusso. Per maggiori informazioni sulle metriche che è possibile usare per monitorare il processo di Analisi di flusso, vedere Metriche dei processi di Analisi di flusso di Azure.
- Operazioni: avviare, arrestare o eliminare il lavoro.
Passaggi successivi
Informazioni su come usare l'editor senza codice per gestire scenari comuni usando modelli predefiniti: