Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Che cos'è lo strumento Map Data?
Lo strumento Map Data è un processo guidato che consente agli utenti di creare mapping ETL e mapping dei flussi di dati dai dati di origine alle tabelle di database synapse lake senza scrivere codice. Questo processo inizia con l'utente che sceglie le tabelle di destinazione nei database Synapse lake e quindi esegue il mapping dei dati di origine in queste tabelle.
Per altre informazioni sui database Synapse lake, vedere Panoramica dei modelli di database di Azure Synapse - Azure Synapse Analytics | Microsoft Docs
I dati mappa offrono un'esperienza guidata in cui l'utente può generare un flusso di dati di mapping senza dover iniziare con un'area di disegno vuota. È quindi possibile generare rapidamente un flusso di dati per mapping scalabile eseguibile nelle pipeline di Synapse.
Come iniziare
Lo strumento Dati di mapping viene avviato dall'esperienza del database Lake di Synapse. Da qui è possibile selezionare lo strumento Dati mappa per avviare il processo.
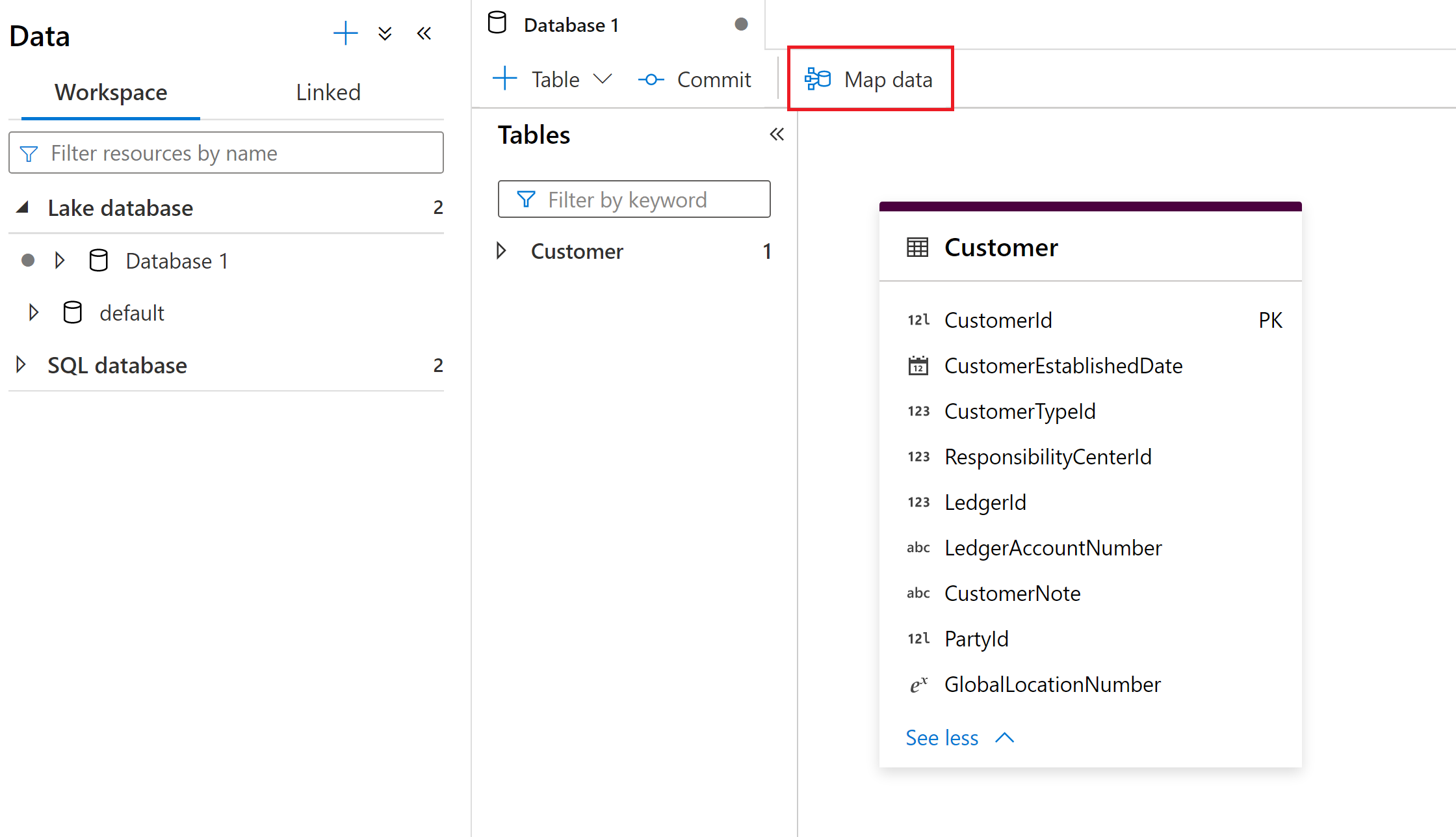
Le Map Data necessitano di risorse computazionali disponibili per assistere gli utenti nella visualizzazione in anteprima dei dati e nella lettura degli schemi dei loro file sorgente. Quando si usano i dati di mapping per la prima volta in una sessione, è necessario riscaldare un cluster.
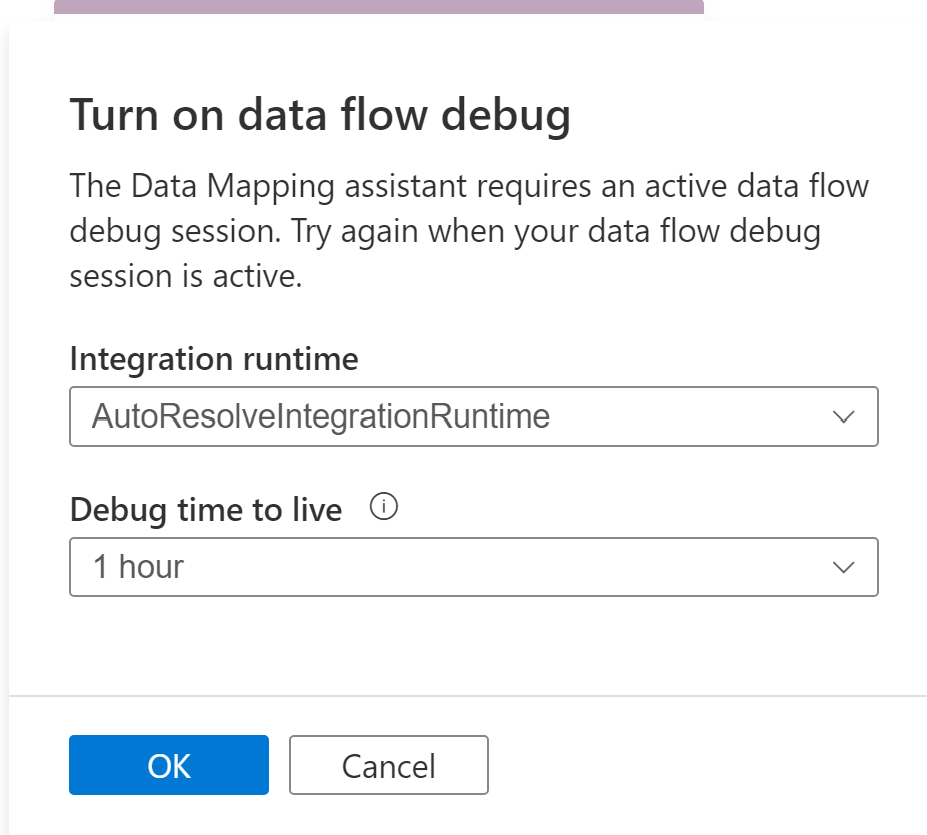
Per iniziare, scegliere l'origine dati di cui si vuole eseguire il mapping alle tabelle di database Lake. Le origini dati attualmente supportate sono database Azure Data Lake Storage Gen 2 e Synapse Lake.
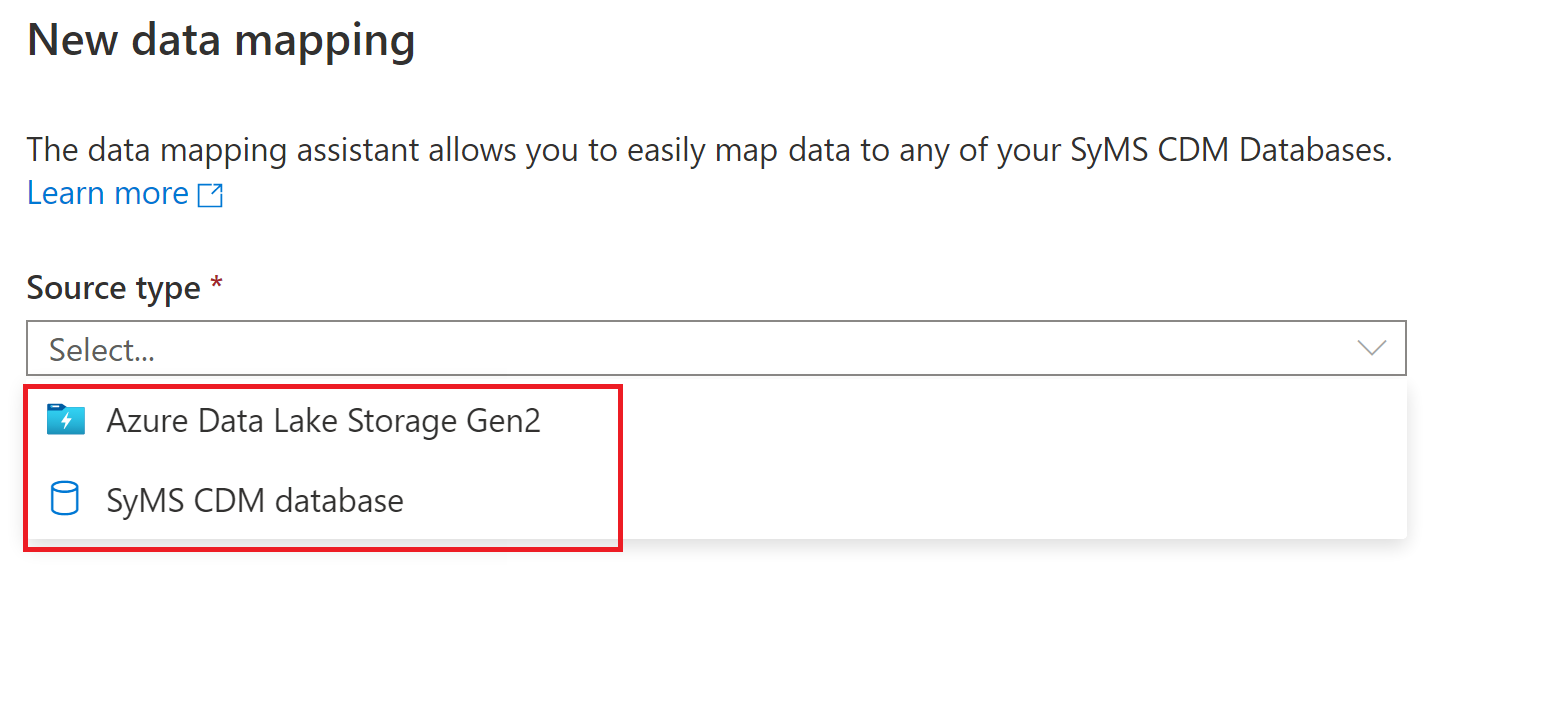
Opzioni del tipo di file
Quando si sceglie un archivio file, ad esempio Azure Data Lake Storage Gen 2, sono supportati i tipi di file seguenti:
- Modello Comune di Dati
- Testo delimitato
- Pavimento in parquet
Creare la mappatura dei dati
Configurare il mapping dei dati con il tipo di origine selezionato.
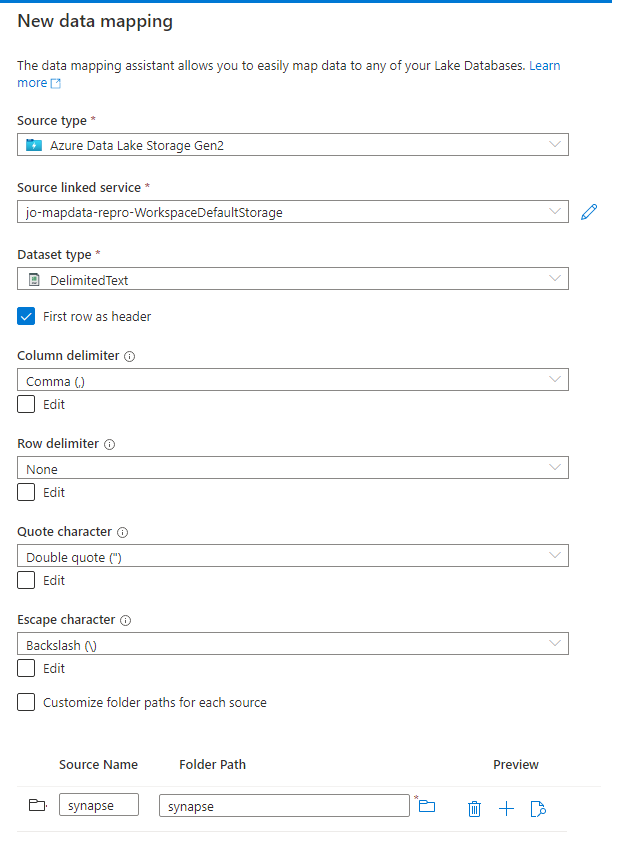
Annotazioni
È possibile scegliere una cartella o un singolo file. Se si sceglie una cartella, sarà possibile associare più file alle tabelle del database del lago. Dopo aver selezionato continua, se si sceglie una cartella, si può anche decidere di includere solo file specifici, se lo si desidera.
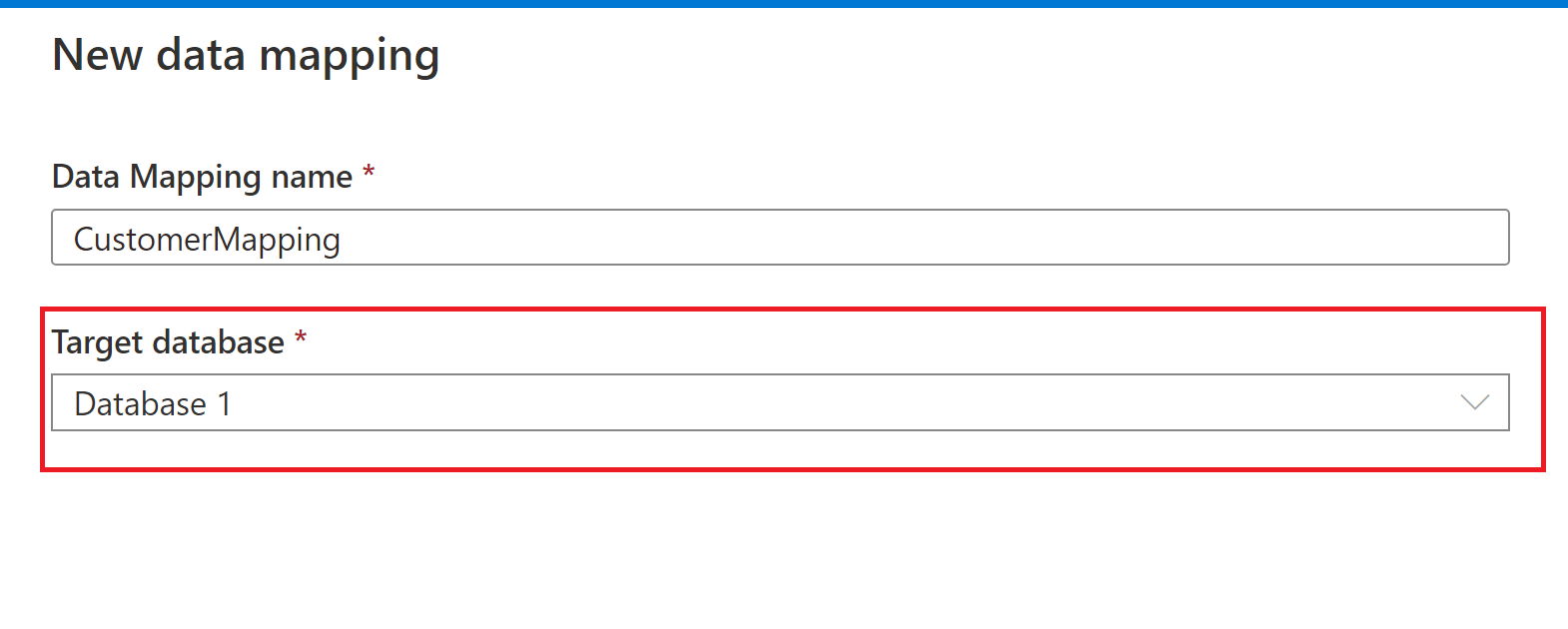
Assegnare un nome al mapping dei dati e selezionare la destinazione del database Lake di Azure Synapse.
Mapping da origine a destinazione
Scegliere una tabella di origine primaria per eseguire il mapping alla tabella di destinazione del database Synapse lake.
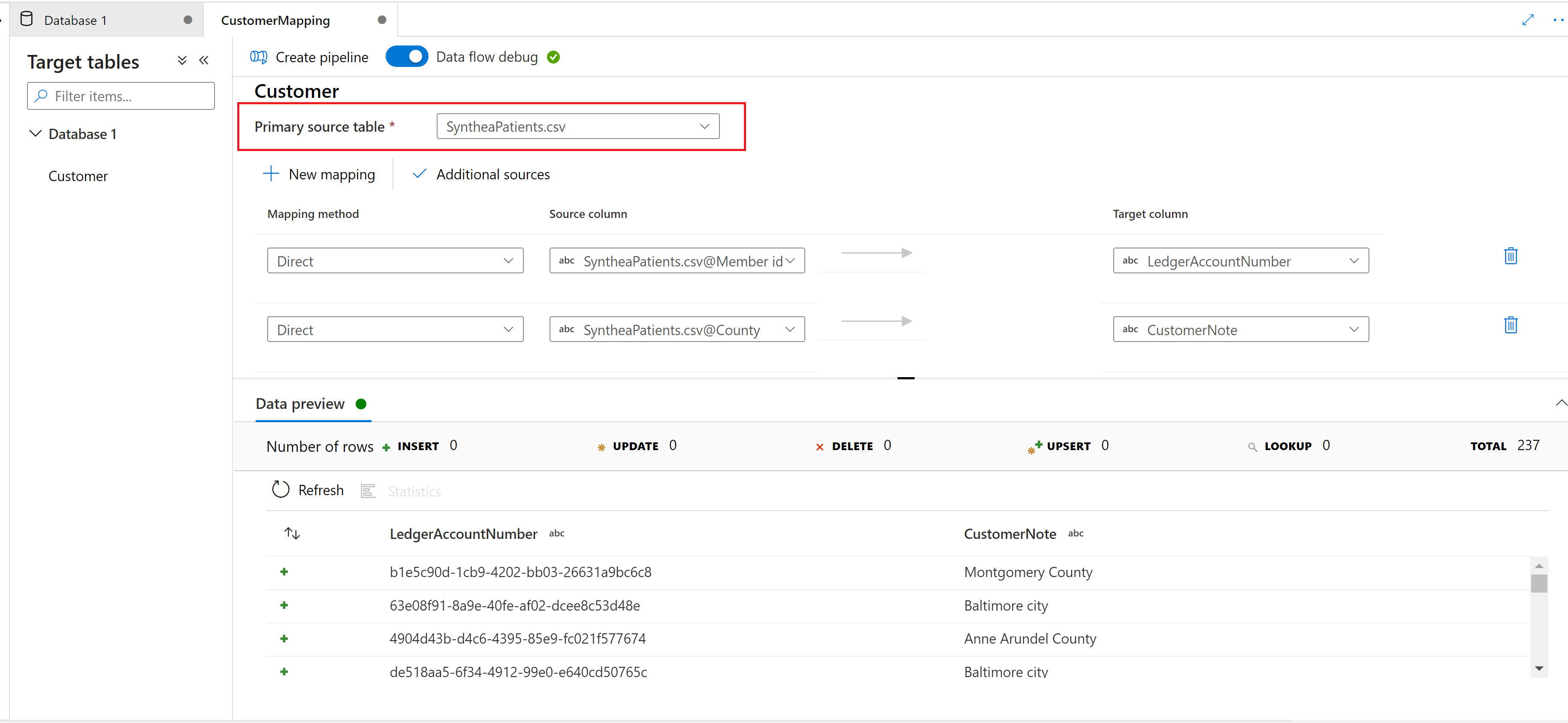
Nuova mappatura
Utilizzare il pulsante Nuova mappatura per aggiungere un metodo di mappatura e creare una mappatura o una trasformazione.
Origine aggiuntiva
Usare il pulsante Origine aggiuntiva per collegarsi e aggiungere un'altra origine alla mappatura.
Anteprima dati
La scheda Anteprima dati offre uno snapshot interattivo dei dati di ogni trasformazione. Per altre informazioni, vedere Anteprima dei dati in modalità di debug.
Metodi di mapping
Sono supportati i metodi di mapping seguenti:
- Diretta
- Chiave surrogata
- Ricerca
- UnPivot
- Aggregata
- Somma
- Requisiti minimi
- Massimo
- Primo
- Ultimo
- Deviazione standard
- Medio
- Media
- Colonna derivata
- Trim
- Upper (Superiori)
- Minore
- Avanzato
Creare una pipeline
Dopo aver completato le trasformazioni Map Data ,selezionare il pulsante Crea pipeline per generare un flusso di dati di mapping e una pipeline per eseguire il debug e l'esecuzione della trasformazione.