Playbook del modello di verifica di Synapse: analisi di Big Data con pool di Apache Spark in Azure Synapse Analytics
Questo articolo presenta una metodologia generale per la preparazione e l'esecuzione di un progetto di modello di verifica di Azure Synapse Analytics efficace per il pool di Apache Spark.
Nota
Questo articolo fa parte della serie di articoli Playbook del modello di verifica Azure Synapse. Per una panoramica della serie, vedere Playbook del modello di verifica Azure Synapse.
Prepararsi per il modello di verifica
Un progetto di modello di verifica consente di prendere una decisione aziendale informata sull'implementazione di un ambiente di analisi avanzata e Big Data in una piattaforma basata sul cloud che sfrutta un pool di Apache Spark in Azure Synapse.
Un progetto di modello di verifica identificherà gli obiettivi chiave e i driver aziendali che devono essere supportati da Big Data basati sul cloud e dalla piattaforma di analisi avanzata. Testerà le metriche chiave e proverà i comportamenti chiave fondamentali per il successo dell'ingegneria dei dati, la compilazione di modelli di Machine Learning e i requisiti di training. Un modello di verifica non è progettato per essere distribuito in un ambiente di produzione. Si tratta piuttosto di un progetto a breve termine incentrato sulle domande chiave e il suo risultato può essere ignorato.
Prima di iniziare a pianificare il progetto del modello di verifica Spark:
- Identificare eventuali restrizioni o linee guida dell'organizzazione in merito allo spostamento dei dati nel cloud.
- Identificare gli sponsor esecutivi o di business per un progetto di piattaforma di analisi avanzata e Big Data. Garantire il loro supporto per la migrazione al cloud.
- Identificare la disponibilità di esperti tecnici e utenti aziendali per supportare l'utente durante l'esecuzione del modello di verifica.
Prima di iniziare a preparare il progetto del modello di verifica, è consigliabile leggere la documentazione di Apache Spark.
Suggerimento
Se non si ha familiarità con i pool di Spark, è consigliabile usare il percorso di apprendimento Eseguire l'ingegneria dei dati con i pool di Apache Spark di Azure Synapse.
A questo punto si dovrebbe aver determinato che non ci sono blocchi immediati e quindi è possibile iniziare a prepararsi per il modello di verifica. Se non si ha familiarità con i pool di Apache Spark in Azure Synapse Analytics, è possibile fare riferimento a questa documentazione in cui è possibile ottenere una panoramica dell'architettura Spark e scoprire come funziona in Azure Synapse.
Sviluppare una conoscenza di questi concetti chiave:
- Apache Spark e l'architettura distribuita.
- Concetti di Spark come set di dati distribuiti resilienti (RDD) e partizioni (in memoria e fisiche).
- Area di lavoro di Azure Synapse, motori di calcolo, pipeline e monitoraggio diversi.
- Separazione di calcolo e archiviazione nel pool di Spark.
- Autenticazione e autorizzazione in Azure Synapse.
- Connettori nativi che si integrano con il pool SQL dedicato di Azure Synapse, Azure Cosmos DB e altri.
Azure Synapse separa le risorse di calcolo dall'archiviazione in modo da poter gestire meglio le esigenze di elaborazione dei dati e controllare i costi. L'architettura serverless del pool di Spark consente di aumentare e ridurre le dimensioni del cluster Spark, indipendentemente dall'archiviazione. È possibile sospendere completamente (o configurare la sospensione automatica) di un cluster Spark. In questo modo, si paga per il calcolo solo quando è in uso. Quando non è in uso, si paga solo per lo spazio di archiviazione. È possibile aumentare le prestazioni del cluster Spark per esigenze di elaborazione dei dati pesanti o carichi di grandi dimensioni e quindi ridurle in periodi di elaborazione meno intensi (o arrestare completamente il cluster). È possibile ridimensionare e sospendere in modo efficace un cluster per ridurre i costi. I test del modello di verifica Spark devono includere l'inserimento dati e l'elaborazione dei dati su diverse scale (piccole, medie e grandi) per confrontare prezzi e prestazioni su scala diversa. Per altre informazioni, vedere Ridimensionare automaticamente i pool di Apache Spark di Azure Synapse Analytics.
È importante comprendere la differenza tra i diversi set di API Spark in modo da poter decidere cosa funziona meglio per lo scenario in uso. È possibile scegliere quello che offre prestazioni migliori o facilità d'uso, sfruttando i set di competenze esistenti del team. Per altre informazioni, vedere il documento A Tale of Three Apache Spark APIs: RDDs, DataFrames and Datasets.
Il partizionamento dei dati e dei file funziona in modo leggermente diverso in Spark. Comprendere le differenze consente di ottimizzare le prestazioni. Per altre informazioni, vedere la documentazione di Apache Spark: Individuazione partizioni e Opzioni di configurazione della partizione.
Impostare gli obiettivi
Un progetto di modello di verifica successo richiede una pianificazione. Per iniziare, identificare il motivo per cui si sta creando un modello di verifica per comprendere appieno le motivazioni reali. Le motivazioni possono includere modernizzazione, risparmio dei costi, miglioramento delle prestazioni o esperienza integrata. Assicurarsi di documentare obiettivi chiari per il modello di verifica e i criteri che ne definiranno il successo. Chiediti:
- Cosa si desidera come output del modello di verifica?
- Cosa si farà con questi output?
- Chi userà gli output?
- Cosa definirà un modello di verifica di successo?
Tenere presente che un modello di verifica deve essere un'iniziativa breve e mirata per dimostrare rapidamente un set limitato di concetti e funzionalità. Questi concetti e funzionalità devono essere rappresentativi del carico di lavoro complessivo. Se si dispone di un lungo elenco di elementi da dimostrare, è consigliabile pianificare più di un modello di verifica. In tal caso, definire i controlli tra i modelli di verifica per determinare se sia necessario continuare con quello successivo. Considerati i diversi ruoli professionali che possono usare pool di Spark e notebook in Azure Synapse, è possibile scegliere di eseguire più modelli di verifica. Ad esempio, un modello di verifica può concentrarsi sui requisiti per il ruolo di ingegneria dei dati, ad esempio l'inserimento e l'elaborazione. Un altro modello di verifica potrebbe concentrarsi sullo sviluppo di modelli di Machine Learning (ML).
Quando si considerano gli obiettivi del modello di verifica, porre le domande seguenti per definirli:
- Si sta eseguendo la migrazione da una piattaforma di analisi avanzata e Big Data esistente (locale o cloud)?
- Si sta eseguendo la migrazione ma si vuole apportare il minor numero possibile di modifiche all'inserimento e all'elaborazione dei dati esistenti? Ad esempio, una migrazione da Spark a Spark o una migrazione da Hadoop/Hive a Spark.
- Si sta eseguendo la migrazione ma si vogliono apportare alcuni miglioramenti approfonditi nel corso del processo? Ad esempio, la riscrittura di processi MapReduce come processi Spark o la conversione di codice basato su RDD legacy in codice basato su dataframe/set di dati.
- Si sta creando una piattaforma di analisi avanzata e Big Data completamente nuova (progetto greenfield)?
- Quali sono le problematiche correnti? Ad esempio scalabilità, prestazioni o flessibilità.
- Quali nuovi requisiti aziendali è necessario supportare?
- Quali sono i contratti di servizio che è necessario soddisfare?
- Quali saranno i carichi di lavoro? Ad esempio ETL, elaborazione batch, elaborazione di flussi, training del modello di Machine Learning, analisi, query di creazione di report o query interattive?
- Quali sono le competenze degli utenti che possiedono il progetto (per capire se debba essere implementato il modello di verifica)? Ad esempio, le competenze di PySpark e Scala, l'esperienza notebook e IDE.
Ecco alcuni esempi di impostazioni di obiettivi del modello di verifica:
- Perché stiamo effettuando un modello di verifica?
- È necessario sapere che le prestazioni di inserimento ed elaborazione dei dati per il carico di lavoro dei Big Data soddisfino i nuovi contratti di servizio.
- È necessario sapere se l'elaborazione del flusso quasi in tempo reale è possibile e la quantità di velocità effettiva che può supportare. Supporterà i requisiti aziendali?
- È necessario sapere se i processi esistenti di inserimento e trasformazione dei dati sono adatti e dove devono essere apportati miglioramenti.
- È necessario sapere se sia possibile ridurre i tempi di esecuzione dell'integrazione dei dati e di quanto.
- È necessario sapere se i data scientist possono creare ed eseguire il training di modelli di Machine Learning e sfruttare le librerie di intelligenza artificiale/Machine Learning in base alle esigenze in un pool di Spark.
- Lo spostamento in Synapse Analytics basato sul cloud soddisfa gli obiettivi dei costi?
- Alla conclusione di questo modello di verifica:
- I dati saranno disponibili per determinare se i requisiti di prestazioni per l'elaborazione dei dati possono essere soddisfatti per lo streaming in batch e in tempo reale.
- Abbiamo testato l'inserimento e l'elaborazione di tutti i diversi tipi di dati (strutturati, semi e non strutturati) che supportano i nostri casi d'uso.
- Saranno testati alcuni dei processi di elaborazione dati complessi esistenti e sarà possibile identificare il lavoro che dovrà essere completato per eseguire la migrazione del portfolio di integrazione dei dati nel nuovo ambiente.
- L'inserimento e l'elaborazione dei dati saranno testati e saranno disponibili i punti dati per stimare lo sforzo necessario per la migrazione iniziale e il caricamento dei dati cronologici, nonché per stimare lo sforzo necessario a eseguire la migrazione dell'inserimento dati (Azure Data Factory (ADF), Distcp, Databox o altri).
- Verranno testati l'inserimento e l'elaborazione dei dati e sarà possibile determinare se sia possibile soddisfare i requisiti di elaborazione ETL/ELT.
- Verranno acquisite informazioni dettagliate per stimare meglio lo sforzo necessario per completare il progetto di implementazione.
- Saranno testate le opzioni di scalabilità e ridimensionamento e saranno disponibili i punti dati per configurare meglio la piattaforma e migliorare così le impostazioni relative al rapporto prezzi/prestazioni.
- Sarà disponibile un elenco di elementi che potrebbero richiedere più test.
Pianificare il progetto
Usare gli obiettivi per identificare test specifici e fornire gli output identificati. È importante assicurarsi di avere almeno un test per supportare ogni obiettivo e output previsto. Identificare anche l'inserimento dati specifico, l'elaborazione batch o di flusso e tutti gli altri processi che verranno eseguiti in modo da poter identificare un set di dati e una codebase molto specifici. Questo set di dati e la codebase specifici definiranno l'ambito del modello di verifica.
Di seguito è riportato un esempio del livello di specificità necessario nella pianificazione:
- Obiettivo A: è necessario sapere se i requisiti per l'inserimento e l'elaborazione dei dati batch possono essere soddisfatti nel contratto di servizio definito.
- Output A: saranno disponibili dati per determinare se l'inserimento e l'elaborazione dei dati batch possano soddisfare i requisiti di elaborazione dei dati e il contratto di servizio.
- Test A1: le query di elaborazione A, B e C vengono identificate come test delle prestazioni ottimali poiché vengono comunemente eseguite dal team di ingegneria dei dati. Rappresentano anche le esigenze generali di elaborazione dei dati.
- Test A2: le query di elaborazione X, Y e Z vengono identificate come test delle prestazioni ottimali perché contengono requisiti di elaborazione dei flussi quasi in tempo reale. Rappresentano anche le esigenze generali di elaborazione dei flussi basate su eventi.
- Test A3: confrontare le prestazioni di queste query su scala diversa del cluster Spark (numero variabile di nodi di lavoro, dimensioni dei nodi di lavoro, ad esempio piccole, medie e grandi dimensioni e numero di executor) con il benchmark ottenuto dal sistema esistente. Tenere presente la legge di riduzione dei rendimenti; l'aggiunta di più risorse (con aumento delle istanze) può contribuire a raggiungere il parallelismo, ma esiste un determinato limite univoco per ogni scenario in tal senso. Individuare la configurazione ottimale per ogni caso d'uso identificato nel test.
- Obiettivo B: è necessario sapere se i data scientist possono creare ed eseguire il training di modelli di Machine Learning su questa piattaforma.
- Output B: sono stati testati alcuni dei modelli di Machine Learning eseguendone il training sui dati in un pool di Spark o in un pool SQL, sfruttando diverse librerie di Machine Learning. Questi test consentiranno di determinare quali modelli di Machine Learning possono essere sottoposti a migrazione nel nuovo ambiente
- Test B1: verranno testati modelli di Machine Learning specifici.
- Test B2: testare le librerie di Machine Learning di base fornite con Spark (Spark MLLib) insieme a una libreria aggiuntiva che può essere installata in Spark (ad esempio scikit-learn) per soddisfare i requisiti.
- Obiettivo C: l'inserimento dei dati verrà testato e avrà i punti dati per:
- Stimare lo sforzo per la migrazione cronologica iniziale dei dati al data lake e/o al pool di Spark.
- Pianificare un approccio per eseguire la migrazione dei dati cronologici.
- Output C: sarà testata e determinata la velocità di inserimento dei dati ottenibile nell'ambiente e si potrà determinare se la velocità di inserimento dei dati è sufficiente per eseguire la migrazione dei dati cronologici durante l'intervallo di tempo disponibile.
- Test C1: testare diversi approcci di migrazione dei dati cronologici. Per altre informazioni, vedere Trasferire dati da e verso Azure.
- Test C2: identificare la larghezza di banda allocata di ExpressRoute e se è presente una limitazione da parte del team di infrastruttura. Per altre informazioni, vedere Che cos'è Azure ExpressRoute? (Opzioni di larghezza di banda).
- Test C3: test della velocità di trasferimento dei dati sia online che offline. Per altre informazioni, vedere la Guida alle prestazioni e alla scalabilità dell'attività Copy.
- Test C4: testare il trasferimento dei dati dal data lake al pool SQL usando ADF, Polybase o il comando COPY. Per altre informazioni, vedere Strategie di caricamento dei dati per pool SQL dedicati in Azure Synapse Analytics.
- Obiettivo D: sarà testata la velocità di inserimento dati del caricamento incrementale dei dati e saranno disponibili i punti dati per stimare l'inserimento dati e l'intervallo di tempo di elaborazione al data lake e/o al pool SQL dedicato.
- Output D: si testerà la frequenza di inserimento dei dati e si potrà determinare se i requisiti di inserimento e elaborazione dei dati possono essere soddisfatti con l'approccio identificato.
- Test D1: testare l'inserimento e l'elaborazione dei dati di aggiornamento giornalieri.
- Test D2: testare il carico dei dati elaborati nella tabella del pool SQL dedicato dal pool di Spark. Per altre informazioni, vedere Connettore del pool SQL dedicato di Azure Synapse per Apache Spark.
- Test D3: eseguire simultaneamente il processo di caricamento degli aggiornamenti giornalieri durante l'esecuzione di query dell'utente finale.
Assicurarsi di perfezionare i test aggiungendo più scenari di test. Azure Synapse semplifica il test di vari tipi di scalabilità (numero variabile di nodi di lavoro, dimensioni dei nodi di lavoro come piccoli, medi e grandi) per confrontare le prestazioni e il comportamento.
Ecco alcuni scenari di test:
- Test del pool di Spark A: verrà eseguita l'elaborazione dei dati tra più tipi di nodo (di piccole, medie e grandi dimensioni) e diversi numeri di nodi di lavoro.
- Test B del pool di Spark: verranno caricati/recuperati dati elaborati dal pool di Spark al pool SQL dedicato usando il connettore.
- Test del pool di Spark C: verranno caricati/recuperati dati elaborati dal pool di Spark ad Azure Cosmos DB tramite Collegamento ad Azure Synapse.
Valutare il set di dati del modello di verifica
Usando i test specifici identificati, selezionare un set di dati per supportare i test. Prendersi del tempo per esaminare questo set di dati. È necessario verificare che il set di dati rappresenti adeguatamente l'elaborazione futura in termini di contenuto, complessità e scalabilità. Non usare un set di dati troppo piccolo (inferiore a 1 TB) perché non offrirebbe prestazioni rappresentative. Al contrario, non usare un set di dati troppo grande perché il modello di verifica non deve diventare una migrazione completa dei dati. Assicurarsi di ottenere i benchmark appropriati dai sistemi esistenti in modo da poterli usare per i confronti delle prestazioni.
Importante
Assicurarsi di controllare con i proprietari dell'azienda eventuali blocchi prima di spostare i dati nel cloud. Identificare eventuali problemi di sicurezza o privacy o eventuali esigenze di offuscamento dei dati da eseguire prima di spostare i dati nel cloud.
Creare un'architettura generale
In base all'architettura generale dello stato proposta, identificare i componenti che faranno parte del modello di verifica. L'architettura di stato futura generale probabilmente contiene molte origini dati, numerosi consumer di dati, componenti Big Data e possibilmente consumer di dati di Machine Learning e intelligenza artificiale. L'architettura del modello di verifica deve identificare in modo specifico i componenti che faranno parte del modello di verifica. Cosa importante, deve identificare tutti i componenti che non fanno parte del test del modello di verifica.
Se si usa già Azure, identificare le risorse già disponibili (Microsoft Entra ID, ExpressRoute e altri) che è possibile usare durante il modello di verifica. Identificare anche le aree di Azure usate dall'organizzazione. Questo è un ottimo momento per identificare la velocità effettiva della connessione ExpressRoute e verificare con altri utenti aziendali che il modello di verifica possa usare una certa velocità effettiva senza influire negativamente sui sistemi di produzione.
Per altre informazioni, vedere Architetture di Big Data.
Identificare le risorse del modello di verifica
In particolare, identificare le risorse tecniche e gli impegni di tempo necessari per supportare il modello di verifica. Il modello di verifica avrà bisogno di:
- Un rappresentante aziendale per supervisionare i requisiti e i risultati.
- Un esperto di dati dell'applicazione, per estrarre i dati per il modello di verifica e fornire conoscenza di processi e logica esistenti.
- Un esperto di Apache Spark e pool di Spark.
- Un consulente esperto per ottimizzare i test del modello di verifica.
- Risorse che saranno necessarie per componenti specifici del progetto del modello di verifica, ma non necessariamente durante il modello stesso. Queste risorse possono includere amministratori di rete, amministratori di Azure, amministratori di Active Directory, amministratori del portale di Azure e altri.
- Assicurarsi che venga effettuato il provisioning di tutte le risorse dei servizi di Azure necessarie e che venga concesso il livello di accesso richiesto, incluso l'accesso agli account di archiviazione.
- Assicurarsi di disporre di un account con autorizzazioni di accesso ai dati necessarie per recuperare i dati da tutte le origini dati nell'ambito del modello di verifica.
Suggerimento
Consigliamo di coinvolgere un consulente esperto per assistere con il modello di verifica. La Community partner Microsoft ha una disponibilità globale di consulenti esperti che possono aiutare a valutare o implementare Azure Synapse.
Configurare la sequenza temporale
Esaminare i dettagli di pianificazione del modello di verifica e le esigenze aziendali per identificare un intervallo di tempo per il modello. Effettuare stime realistiche del tempo necessario per completare gli obiettivi del modello di verifica. Il tempo necessario per completare il modello di verifica dipenderà dalle dimensioni del suo set di dati, dal numero e dalla complessità dei test e dal numero di interfacce da testare. Se si stima che il modello di verifica verrà eseguito per più di quattro settimane, è consigliabile ridurre l'ambito del modello di verifica per concentrarsi sugli obiettivi con priorità più alta. Assicurarsi di ottenere l'approvazione e l'impegno da tutte le risorse lead e gli sponsor prima di continuare.
Mettere in pratica il modello di verifica
È consigliabile eseguire il progetto del modello di verifica con la disciplina e il rigore di qualsiasi progetto di produzione. Eseguire il progetto in base al piano e gestire un processo di richiesta di modifica per impedire la crescita non controllata dell'ambito del modello di verifica.
Ecco alcuni esempi di attività generali:
Creare un'area di lavoro Synapse, pool di Spark e pool SQL dedicati, account di archiviazione e tutte le risorse di Azure identificate nel piano del modello di verifica.
Caricare il set di dati del modello di verifica:
- Rendere disponibili i dati in Azure estraendo dall'origine o creando dati di esempio in Azure. Per altre informazioni, vedere:
- Testare il connettore dedicato per il pool di Spark e il pool SQL dedicato.
Eseguire la migrazione del codice esistente al pool di Spark:
- Se si esegue la migrazione da Spark, è probabile che il lavoro di migrazione sia semplice, dato che il pool di Spark sfrutta la distribuzione Spark open source. Tuttavia, se si usano funzionalità specifiche del fornitore oltre a quelle principali di Spark, è necessario eseguire correttamente il mapping di queste funzionalità a quelle del pool di Spark.
- Se si esegue la migrazione da un sistema non Spark, il lavoro di migrazione varia in base alla complessità interessata.
Eseguire i test:
- Molti test possono essere eseguiti in parallelo in più cluster del pool di Spark.
- Registrare i risultati in un formato di consumo e facilmente comprensibile.
Monitorare per la risoluzione dei problemi e le prestazioni. Per altre informazioni, vedi:
Monitorare l'asimmetria dei dati, l'asimmetria del tempo e la percentuale di utilizzo dell'executor aprendo la scheda Diagnostica del server di cronologia di Spark.
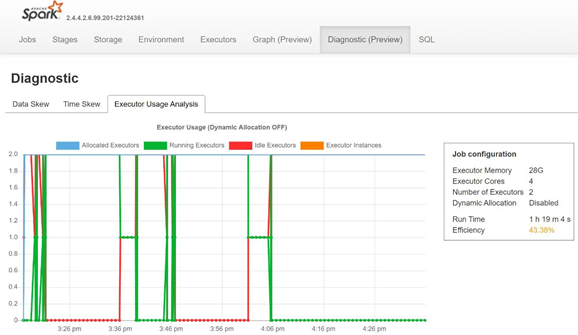
Interpretare i risultati del modello di verifica
Quando si completano tutti i test del modello di verifica, si valutano i risultati. Per iniziare, valutare se gli obiettivi del modello di verifica sono stati raggiunti e se gli output desiderati sono stati raccolti. Determinare se siano necessari altri test o se ci siano domande da affrontare.