Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo è una guida dettagliata che illustra come spostare un'area di lavoro di Azure Synapse Analytics da un'area di Azure a un'altra.
Nota
I passaggi descritti in questo articolo non spostano effettivamente l'area di lavoro. I passaggi illustrano come creare una nuova area di lavoro in una nuova area usando i backup e gli artefatti dedicati del pool SQL ad Azure Synapse Analytics dall'area di origine.
Prerequisiti
- Integrare l'area di lavoro di Azure Synapse dell'area di origine con Azure DevOps o GitHub. Per altre informazioni, vedere Controllo del codice sorgente in Synapse Studio.
- Installare i moduli di Azure PowerShell e dell'interfaccia della riga di comando di Azure nel server in cui vengono eseguiti gli script.
- Assicurarsi che tutti i servizi dipendenti, ad esempio Azure Machine Learning, Archiviazione di Azure e l'hub di Collegamento privato di Azure vengano ricreati o spostati nell'area di destinazione se il servizio supporta lo spostamento di un'area.
- Spostare Archiviazione di Azure in un'area diversa. Per altre informazioni, vedere Spostare un account di Archiviazione di Azure in un'altra area.
- Verificare che il nome del pool SQL dedicato e il nome del pool di Apache Spark siano uguali nell'area di origine e nell'area di lavoro dell'area di destinazione.
Scenari per lo spostamento di un'area
- Nuovi requisiti di conformità: le organizzazioni richiedono che i dati e i servizi vengano inseriti nella stessa area come parte dei nuovi requisiti di conformità.
- Disponibilità di una nuova area di Azure: scenari in cui è disponibile una nuova area di Azure e sono previsti requisiti aziendali o di progetto per spostare l'area di lavoro e altre risorse di Azure nell'area di Azure appena disponibile.
- Area sbagliata selezionata: è stata selezionata l'area sbagliata al momento della creazione delle risorse di Azure.
Passaggi per spostare un'area di lavoro di Azure Synapse in un'altra area
Lo spostamento di un'area di lavoro di Azure Synapse da un'area a un'altra è un processo a più passaggi. Ecco i passaggi principali:
- Creare una nuova area di lavoro di Azure Synapse nell'area di destinazione insieme a un pool di Spark con le stesse configurazioni usate nell'area di lavoro dell'area di origine.
- Ripristinare il pool SQL dedicato nell'area di destinazione usando punti di ripristino o backup geografici.
- Ricreare tutti gli account di accesso necessari nella nuova istanza logica di SQL Server.
- Creare oggetti e database del pool SQL serverless e del pool Spark.
- Aggiungere un'entità servizio Di Azure DevOps al ruolo Controllo degli accessi in base al ruolo di Synapse Artifact Publisher di Azure Synapse se si usa una pipeline di versione di Azure DevOps per distribuire gli artefatti.
- Distribuire l'artefatto di codice (script SQL, notebook), servizi collegati, pipeline, set di dati, trigger di definizioni dei processi Spark e credenziali dalle pipeline di versione di Azure DevOps nell'area di destinazione dell'area di lavoro di Azure Synapse.
- Aggiungere utenti o gruppi di Microsoft Entra ai ruoli Controllo degli accessi in base al ruolo di Azure Synapse. Concessione dell'accesso Collaboratore BLOB di archiviazione all'identità gestita assegnata dal sistema in Archiviazione di Azure e Azure Key Vault se si esegue l'autenticazione usando l'identità gestita.
- Concedere i ruoli Collaboratore BLOB di archiviazione o Lettore BLOB di archiviazione a specifici utenti Microsoft Entra nell'archiviazione collegata predefinita o nell'account di archiviazione con dati di cui eseguire query usando un pool SQL serverless.
- Ricreare un runtime di integrazione self-hosted.
- Caricare manualmente tutte le librerie e i file JAR necessari nell'area di lavoro di Azure Synapse di destinazione.
- Creare tutti gli endpoint privati gestiti se l'area di lavoro viene distribuita in una rete virtuale gestita.
- Testare la nuova area di lavoro nell'area di destinazione e aggiornare tutte le voci DNS, che puntano all'area di lavoro dell'area di origine.
- Se è presente una connessione endpoint privato creata nell'area di lavoro di origine, crearne una nell'area di lavoro di destinazione.
- È possibile eliminare l'area di lavoro nell'area di origine dopo averla testata accuratamente e instradare tutte le connessioni all'area di lavoro dell'area di destinazione.
Preparazione
Passaggio 1: creare un'area di lavoro di Azure Synapse in un'area di destinazione
In questa sezione si creerà l'area di lavoro di Azure Synapse usando Azure PowerShell, l'interfaccia della riga di comando di Azure e il portale di Azure. Si creerà un gruppo di risorse assieme a un account Azure Data Lake Storage Gen2 che verrà usato come risorsa di archiviazione predefinita per l'area di lavoro come parte dello script di PowerShell e dello script dell'interfaccia della riga di comando. Per automatizzare il processo di distribuzione, richiamare questi script di PowerShell o dell'interfaccia della riga di comando dalla pipeline di versione di DevOps.
Azure portal
Per creare un'area di lavoro dal portale di Azure, seguire la procedura descritta in Avvio rapido: Creare un'area di lavoro Synapse.
Azure PowerShell
Lo script seguente crea il gruppo di risorse e l'area di lavoro di Azure Synapse usando i cmdlet New-AzResourceGroup e New-AzSynapseWorkspace.
Creare un gruppo di risorse
$storageAccountName= "<YourDefaultStorageAccountName>"
$resourceGroupName="<YourResourceGroupName>"
$regionName="<YourTargetRegionName>"
$containerName="<YourFileSystemName>" # This is the file system name
$workspaceName="<YourTargetRegionWorkspaceName>"
$sourceRegionWSName="<Your source region workspace name>"
$sourceRegionRGName="<YourSourceRegionResourceGroupName>"
$sqlUserName="<SQLUserName>"
$sqlPassword="<SQLStrongPassword>"
$sqlPoolName ="<YourTargetSQLPoolName>" #Both Source and target workspace SQL pool name will be same
$sparkPoolName ="<YourTargetWorkspaceSparkPoolName>"
$sparkVersion="2.4"
New-AzResourceGroup -Name $resourceGroupName -Location $regionName
Creare un account Data Lake Storage Gen2
#If the Storage account is already created, then you can skip this step.
New-AzStorageAccount -ResourceGroupName $resourceGroupName `
-Name $storageAccountName `
-Location $regionName `
-SkuName Standard_LRS `
-Kind StorageV2 `
-EnableHierarchicalNamespace $true
Crea un'area di lavoro di Azure Synapse
$password = ConvertTo-SecureString $sqlPassword -AsPlainText -Force
$creds = New-Object System.Management.Automation.PSCredential ($sqlUserName, $password)
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds
Per creare l'area di lavoro con una rete virtuale gestita, aggiungere il parametro aggiuntivo "ManagedVirtualNetwork" allo script. Per altre informazioni sulle opzioni disponibili, vedere Configurazione della rete virtuale gestita.
#Creating a managed virtual network configuration
$config = New-AzSynapseManagedVirtualNetworkConfig -PreventDataExfiltration -AllowedAadTenantIdsForLinking ContosoTenantId
#Creating an Azure Synapse workspace
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds `
-ManagedVirtualNetwork $config
Interfaccia della riga di comando di Azure
Questo script dell'interfaccia della riga di comando di Azure crea un gruppo di risorse, un account Data Lake Storage Gen2 e un file system. Crea quindi l'area di lavoro di Azure Synapse.
Creare un gruppo di risorse
az group create --name $resourceGroupName --location $regionName
Creare un account Data Lake Storage Gen2
Lo script seguente crea un account di archiviazione e un contenitore.
# Checking if name is not used only then creates it.
$StorageAccountNameAvailable=(az storage account check-name --name $storageAccountName --subscription $subscriptionId | ConvertFrom-Json).nameAvailable
if($StorageAccountNameAvailable)
{
Write-Host "Storage account Name is available to be used...creating storage account"
#Creating a Data Lake Storage Gen2 account
$storageAccountProvisionStatus=az storage account create `
--name $storageAccountName `
--resource-group $resourceGroupName `
--location $regionName `
--sku Standard_GRS `
--kind StorageV2 `
--enable-hierarchical-namespace $true
($storageAccountProvisionStatus| ConvertFrom-Json).provisioningState
}
else
{
Write-Host "Storage account Name is NOT available to be used...use another name -- exiting the script..."
EXIT
}
#Creating a container in a Data Lake Storage Gen2 account
$key=(az storage account keys list -g $resourceGroupName -n $storageAccountName|ConvertFrom-Json)[0].value
$fileShareStatus=(az storage share create --account-name $storageAccountName --name $containerName --account-key $key)
if(($fileShareStatus|ConvertFrom-Json).created -eq "True")
{
Write-Host f"Successfully created the fileshare - '$containerName'"
}
Crea un'area di lavoro di Azure Synapse
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $containerName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName
Per abilitare una rete virtuale gestita, includere il parametro --enable-managed-virtual-network nello script precedente. Per altre opzioni, vedere Rete virtuale gestita dell'area di lavoro.
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $FileShareName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName `
--enable-managed-virtual-network true `
--allowed-tenant-ids "Contoso"
Passaggio 2: creare una regola del firewall dell'area di lavoro di Azure Synapse
Dopo aver creato l'area di lavoro, aggiungere le regole del firewall per l'area di lavoro. Limitare gli indirizzi IP a un determinato intervallo. È possibile aggiungere un firewall dal portale di Azure o usando PowerShell o l'interfaccia della riga di comando.
Azure portal
Selezionare le opzioni del firewall e aggiungere l'intervallo di indirizzi IP, come illustrato nello screenshot seguente.
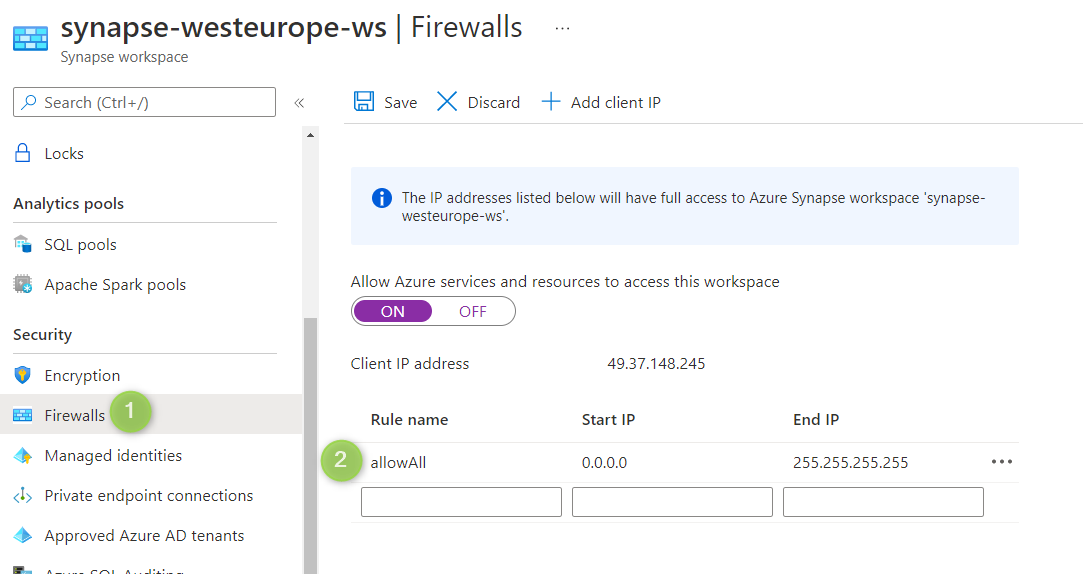
Azure PowerShell
Eseguire i comandi di PowerShell seguenti per aggiungere regole del firewall specificando gli indirizzi IP iniziale e finale. Aggiornare l'intervallo di indirizzi IP in base alle esigenze.
$WorkspaceWeb = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Web
$WorkspaceDev = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Dev
# Adding firewall rules
$FirewallParams = @{
WorkspaceName = $workspaceName
Name = 'Allow Client IP'
ResourceGroupName = $resourceGroup
StartIpAddress = "0.0.0.0"
EndIpAddress = "255.255.255.255"
}
New-AzSynapseFirewallRule @FirewallParams
Eseguire lo script seguente per aggiornare le impostazioni del controllo SQL dell'identità gestita dell'area di lavoro:
Set-AzSynapseManagedIdentitySqlControlSetting -WorkspaceName $workspaceName -Enabled $true
Interfaccia della riga di comando di Azure
az synapse workspace firewall-rule create --name allowAll --workspace-name $workspaceName `
--resource-group $resourceGroupName --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255
Eseguire lo script seguente per aggiornare le impostazioni del controllo SQL dell'identità gestita dell'area di lavoro:
az synapse workspace managed-identity grant-sql-access `
--workspace-name $workspaceName --resource-group $resourceGroupName
Passaggio 3: creare un pool di Apache Spark
Creare il pool di Spark con la stessa configurazione usata nell'area di lavoro dell'area di origine.
Azure portal
Per creare un pool di Spark dal portale di Azure, vedere Avvio rapido: Creare un nuovo pool di Apache Spark serverless usando il portale di Azure.
È anche possibile creare il pool di Spark da Synapse Studio seguendo la procedura descritta in Avvio rapido: Creare un pool di Apache Spark serverless usando Synapse Studio.
Azure PowerShell
Lo script seguente crea un pool di Spark con due ruoli di lavoro e un nodo driver e una piccola dimensione del cluster con 4 core e 32 GB di RAM. Aggiornare i valori in modo che corrispondano al pool di Spark dell'area di lavoro dell'area di origine.
#Creating a Spark pool with 3 nodes (2 worker + 1 driver) and a small cluster size with 4 cores and 32 GB RAM.
New-AzSynapseSparkPool `
-WorkspaceName $workspaceName `
-Name $sparkPoolName `
-NodeCount 3 `
-SparkVersion $sparkVersion `
-NodeSize Small
Interfaccia della riga di comando di Azure
az synapse spark pool create --name $sparkPoolName --workspace-name $workspaceName --resource-group $resourceGroupName `
--spark-version $sparkVersion --node-count 3 --node-size small
Sposta
Passaggio 4: ripristinare un pool SQL dedicato
Eseguire il ripristino da un backup con ridondanza geografica
Per ripristinare i pool SQL dedicati dal backup geografico usando il portale di Azure e PowerShell, vedere Ripristino geografico di un pool SQL dedicato in Azure Synapse Analytics.
Eseguire il ripristino usando i punti di ripristino dal pool SQL dedicato dell'area di lavoro dell'area di origine
Ripristinare il pool SQL dedicato nell'area di lavoro di destinazione usando il punto di ripristino del pool SQL dedicato dell'area di lavoro dell'area di origine. È possibile usare il portale di Azure, Synapse Studio o PowerShell per eseguire il ripristino da punti di ripristino. Se l'area di origine non è accessibile, non è possibile eseguire il ripristino usando questa opzione.
Synapse Studio
Da Synapse Studio è possibile ripristinare il pool SQL dedicato da qualsiasi area di lavoro nella sottoscrizione usando punti di ripristino. Durante la creazione del pool SQL dedicato, in Impostazioni aggiuntive selezionare Punto di ripristino e quindi selezionare l'area di lavoro come illustrato nello screenshot seguente. Se è stato creato un punto di ripristino definito dall'utente, usarlo per ripristinare il pool SQL. In caso contrario, è possibile selezionare il punto di ripristino automatico più recente.
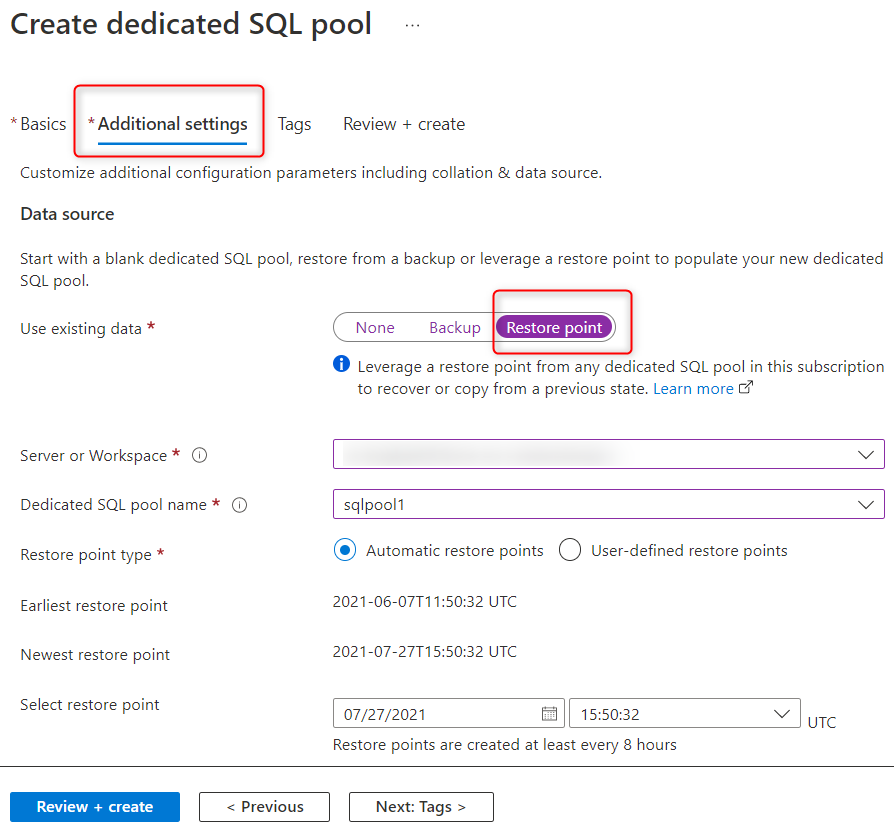
Azure PowerShell
Eseguire lo script di PowerShell seguente per ripristinare l'area di lavoro. Questo script usa il punto di ripristino più recente dal pool SQL dedicato dell'area di lavoro di origine per ripristinare il pool SQL nell'area di lavoro di destinazione. Prima di eseguire lo script, aggiornare il livello di prestazioni da DW100c al valore richiesto.
Importante
Il nome del pool SQL dedicato deve essere lo stesso in entrambe le aree di lavoro.
Ottenere i punti di ripristino:
$restorePoint=Get-AzSynapseSqlPoolRestorePoint -WorkspaceName $sourceRegionWSName -Name $sqlPoolName|Sort-Object -Property RestorePointCreationDate -Descending `
| SELECT RestorePointCreationDate -ExpandProperty RestorePointCreationDate -First 1
Trasformare l'ID risorsa del pool SQL di Azure Synapse in ID di Database SQL perché attualmente il comando accetta solo l'ID di Database SQL.
Ad esempio: /subscriptions/<SubscriptionId>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Sql/servers/<WorkspaceName>/databases/<DatabaseName>
$pool = Get-AzSynapseSqlPool -ResourceGroupName $sourceRegionRGName -WorkspaceName $sourceRegionWSName -Name $sqlPoolName
$databaseId = $pool.Id `
-replace "Microsoft.Synapse", "Microsoft.Sql" `
-replace "workspaces", "servers" `
-replace "sqlPools", "databases"
$restoredPool = Restore-AzSynapseSqlPool -FromRestorePoint `
-RestorePoint $restorePoint `
-TargetSqlPoolName $sqlPoolName `
-ResourceGroupName $resourceGroupName `
-WorkspaceName $workspaceName `
-ResourceId $databaseId `
-PerformanceLevel DW100c -AsJob
Di seguito viene tenuta traccia dello stato dell'operazione di ripristino:
Get-Job | Where-Object Command -In ("Restore-AzSynapseSqlPool") | `
Select-Object Id,Command,JobStateInfo,PSBeginTime,PSEndTime,PSJobTypeName,Error |Format-Table
Dopo il ripristino del pool SQL dedicato, creare tutti gli account di accesso SQL in Azure Synapse. Per creare tutti gli account di accesso, seguire la procedura descritta in Creare l'account di accesso.
Passaggio 5: creare un pool SQL serverless, un database del pool Spark e oggetti
Non è possibile eseguire il backup e il ripristino di database del pool SQL serverless e pool di Spark. Come possibile soluzione alternativa, è possibile:
- Creare notebook e script SQL, che hanno il codice per ricreare tutti i pool di Spark, i database del pool SQL serverless, le tabelle e i ruoli necessari, nonché gli utenti con tutte le assegnazioni di ruolo. Archiviare questi elementi in Azure DevOps o GitHub.
- Se il nome dell'account di archiviazione viene modificato, assicurarsi che gli artefatti del codice puntino al nome dell'account di archiviazione corretto.
- Creare pipeline che richiamano questi artefatti di codice in una sequenza specifica. Quando queste pipeline vengono eseguite nell'area di lavoro dell'area di destinazione, i database SQL Spark, i database del pool SQL serverless, le origini dati esterne, le viste, i ruoli e gli utenti e le autorizzazioni verranno creati nell'area di lavoro dell'area di destinazione.
- Integrando l'area di lavoro dell'area di origine con Azure DevOps, questi artefatti di codice faranno parte del repository. Successivamente, è possibile distribuire questi artefatti di codice nell'area di lavoro dell'area di destinazione usando la pipeline di versione DevOps come indicato nel passaggio 6.
- Nell'area di lavoro dell'area di destinazione attivare manualmente queste pipeline.
Passaggio 6: distribuire artefatti e pipeline usando CI/CD
Per informazioni su come integrare un'area di lavoro di Azure Synapse con Azure DevOps o GitHub e come distribuire gli artefatti in un'area di lavoro dell'area di destinazione, seguire i passaggi descritti in Integrazione continua e recapito continuo (CI/CD) per un'area di lavoro di Azure Synapse.
Dopo aver integrato l'area di lavoro con Azure DevOps, si noterà un ramo con il nome workspace_publish. Questo ramo contiene il modello di area di lavoro che include definizioni per gli artefatti, ad esempio Notebook, script SQL, set di dati, servizi collegati, pipeline, trigger e definizione di processo Spark.
Questo screenshot del repository Azure DevOps mostra i file del modello dell'area di lavoro per gli artefatti e altri componenti.
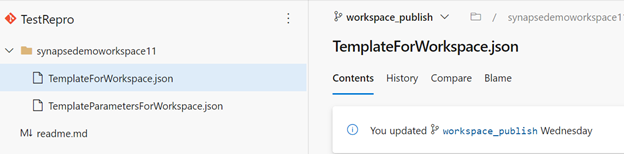
È possibile usare il modello di area di lavoro per distribuire artefatti e pipeline in un'area di lavoro usando la pipeline di versione di Azure DevOps.
Se l'area di lavoro non è integrata con GitHub o Azure DevOps, è necessario ricreare o scrivere manualmente script personalizzati di PowerShell o dell'interfaccia della riga di comando di Azure per distribuire tutti gli artefatti, le pipeline, i servizi collegati, le credenziali, i trigger e le definizioni di Spark nell'area di lavoro dell'area di destinazione.
Nota
Questo processo richiede di continuare ad aggiornare le pipeline e gli artefatti di codice per includere eventuali modifiche apportate a pool, oggetti e ruoli SQL serverless nelle aree di lavoro dell'area di origine.
Passaggio 7: creare un runtime di integrazione condiviso
Per creare un runtime di integrazione self-hosted, seguire i passaggi descritti in Creare e configurare un runtime di integrazione self-hosted.
Passaggio 8: assegnare un ruolo di Azure all'identità gestita
Assegnare a Storage Blob Contributor l'accesso all'identità gestita della nuova area di lavoro nell'account Data Lake Storage Gen2 collegato predefinito. Assegnare anche l'accesso ad altri account di archiviazione in cui viene usato SA-MI per l'autenticazione. Assegnare a Storage Blob Contributor o Storage Blob Reader l'accesso a utenti e gruppi di Microsoft Entra per tutti gli account di archiviazione necessari.
Azure portal
Seguire la procedura descritta in Concedere autorizzazioni all'identità gestita dell'area di lavoro per assegnare il ruolo di Collaboratore ai dati dei BLOB di archiviazione all'identità gestita dell'area di lavoro.
Azure PowerShell
Assegnare il ruolo di Collaboratore ai dati del BLOB di archiviazione all'identità gestita dell'area di lavoro.
Aggiunta di un Collaboratore ai dati dei BLOB di archiviazione all'identità gestita dell'area di lavoro nell'account di archiviazione. L'esecuzione di New-AzRoleAssignment genera un errore con il messaggio Exception of type 'Microsoft.Rest.Azure.CloudException' was thrown.; tuttavia, crea le autorizzazioni necessarie per l'account di archiviazione.
$workSpaceIdentityObjectID= (Get-AzSynapseWorkspace -ResourceGroupName $resourceGroupName -Name $workspaceName).Identity.PrincipalId
$scope = "/subscriptions/$($subscriptionId)/resourceGroups/$($resourceGroupName)/providers/Microsoft.Storage/storageAccounts/$($storageAccountName)"
$roleAssignedforManagedIdentity=New-AzRoleAssignment -ObjectId $workSpaceIdentityObjectID `
-RoleDefinitionName "Storage Blob Data Contributor" `
-Scope $scope -ErrorAction SilentlyContinue
Interfaccia della riga di comando di Azure
Ottenere il nome del ruolo, l'ID risorsa e l'ID entità per l'identità gestita dell'area di lavoro, quindi aggiungere il ruolo di Collaboratore ai dati del BLOB di archiviazione di Azure all'amministratore di sistema.
# Getting Role name
$roleName =az role definition list --query "[?contains(roleName, 'Storage Blob Data Contributor')].{roleName:roleName}" --output tsv
#Getting resource id for storage account
$scope= (az storage account show --name $storageAccountName|ConvertFrom-Json).id
#Getting principal ID for workspace managed identity
$workSpaceIdentityObjectID=(az synapse workspace show --name $workspaceName --resource-group $resourceGroupName|ConvertFrom-Json).Identity.PrincipalId
# Adding Storage Blob Data Contributor Azure role to SA-MI
az role assignment create --assignee $workSpaceIdentityObjectID `
--role $roleName `
--scope $scope
Passaggio 9: assegnare ruoli di Controllo degli accessi in base al ruolo di Azure Synapse
Aggiungere tutti gli utenti che devono accedere all'area di lavoro di destinazione con ruoli e autorizzazioni separati. Lo script di PowerShell e dell'interfaccia della riga di comando seguente aggiunge un utente di Microsoft Entra al ruolo di amministratore di Synapse nell'area di lavoro dell'area di destinazione.
Per ottenere tutti i nomi dei ruoli di Controllo degli accessi in base al ruolo di Azure Synapse, vedere Ruoli di Controllo degli accessi in base al ruolo di Azure Synapse.
Synapse Studio
Per aggiungere o eliminare assegnazioni di Controllo degli accessi in base al ruolo di Azure Synapse Studio da Synapse Studio, seguire la procedura descritta in Come gestire le assegnazioni di ruoli di Controllo degli accessi in base al ruolo di Azure Synapse Studio.
Azure PowerShell
Lo script di PowerShell seguente aggiunge l'assegnazione di ruolo di Amministratore di Synapse a un utente o a un gruppo di Microsoft Entra. È possibile usare -RoleDefinitionId anziché -RoleDefinitionName con il comando seguente per aggiungere gli utenti all'area di lavoro:
New-AzSynapseRoleAssignment `
-WorkspaceName $workspaceName `
-RoleDefinitionName "Synapse Administrator" `
-ObjectId aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb
Get-AzSynapseRoleAssignment -WorkspaceName $workspaceName
Per ottenere ObjectIds e RoleIds nell'area di lavoro dell'area di origine, eseguire il comando Get-AzSynapseRoleAssignment. Assegnare gli stessi ruoli di Controllo degli accessi in base al ruolo di Azure Synapse a utenti o gruppi di Microsoft Entra nell'area di lavoro di destinazione.
Anziché usare -ObjectId come parametro, è anche possibile usare -SignInName, dove si specifica l'indirizzo di posta elettronica o il nome dell'entità utente dell'utente. Per altre informazioni sulle opzioni disponibili, vedere Controllo degli accessi in base al ruolo di Azure Synapse - cmdlet PowerShell.
Interfaccia della riga di comando di Azure
Ottenere l'ID oggetto dell'utente e assegnare le autorizzazioni di Controllo degli accessi in base al ruolo di Azure Synapse necessarie all'utente di Microsoft Entra. È possibile specificare l'indirizzo di posta elettronica dell'utente (username@contoso.com) per il parametro --assignee.
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Administrator" --assignee adasdasdd42-0000-000-xxx-xxxxxxx
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Contributor" --assignee "user1@contoso.com"
Per altre informazioni sulle opzioni disponibili, vedere Controllo degli accessi in base al ruolo di Azure Synapse - Interfaccia della riga di comando.
Passaggio 10: caricare i pacchetti dell'area di lavoro
Caricare tutti i pacchetti dell'area di lavoro necessari nella nuova area di lavoro. Per automatizzare il processo di caricamento dei pacchetti dell'area di lavoro, vedere la libreria client di Microsoft Azure Synapse Analytics Artifacts.
Passaggio 11: autorizzazioni
Per configurare il controllo di accesso per l'area di lavoro di Azure Synapse di destinazione, seguire la procedura descritta in Come configurare il controllo di accesso per l'area di lavoro di Azure Synapse.
Passaggio 12: creare endpoint privati gestiti
Per ricreare gli endpoint privati gestiti dall'area di lavoro dell'area di origine nell'area di lavoro dell'area di destinazione, vedere Creare un endpoint privato gestito all'origine dati.
Discard
Per rimuovere l'area di lavoro dell'area di destinazione, eliminarla. A tale scopo, passare al gruppo di risorse dal dashboard nel portale e selezionare l'area di lavoro, quindi selezionare Elimina nella parte superiore della pagina Gruppo di risorse.
Eseguire la pulizia
Per eseguire il commit delle modifiche e completare lo spostamento dell'area di lavoro, eliminare l'area di lavoro dell'area di origine dopo aver testato l'area di lavoro nell'area di destinazione. A tale scopo, passare al gruppo di risorse con l'area di lavoro dell'area di origine dal dashboard nel portale e selezionare l'area di lavoro e selezionare Elimina nella parte superiore della pagina Gruppo di risorse.
Passaggi successivi
- Altre informazioni sulle reti virtuali gestite di Azure Synapse.
- Altre informazioni sugli endpoint privati gestiti di Azure Synapse.
- Altre informazioni su come connettersi alle risorse dell'area di lavoro da una rete con restrizioni.