Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La configurazione dell'ambiente è il primo passaggio per la creazione di una pipeline per i dati. Quando l'ambiente è pronto, l'esecuzione di un esempio è un'operazione rapida e semplice.
In questo articolo verranno eseguite queste operazioni per iniziare:
Creare una risorsa Servizi AI di Azure
Per usare Big Data in Foundry Tools, creare prima di tutto una risorsa dei servizi di intelligenza artificiale di Azure per il flusso di lavoro. Esistono due tipi principali di strumenti foundry: i servizi cloud ospitati in Azure e i servizi in contenitori gestiti dagli utenti. È consigliabile iniziare con gli strumenti Foundry basati sul cloud più semplici.
Servizi cloud
Gli strumenti Foundry basati sul cloud sono algoritmi intelligenti ospitati in Azure. Questi servizi sono pronti per l'uso senza training, ma è necessaria una connessione Internet. È possibile creare risorse per gli strumenti Foundry nel portale di Azure o con l'interfaccia della riga di comando di Azure.
Servizi in contenitori (facoltativo)
Se l'applicazione o il carico di lavoro usa set di dati di grandi dimensioni, richiede una rete privata o non può contattare il cloud, la comunicazione con i servizi cloud potrebbe risultare impossibile. In questo caso, gli strumenti Foundry in contenitori offrono questi vantaggi:
Connettività bassa: è possibile distribuire gli strumenti Foundry in contenitori in qualsiasi ambiente di elaborazione, sia nel cloud che in modalità off. Se l'applicazione non riesce a contattare il cloud, è consigliabile distribuire gli strumenti Foundry in contenitori nell'applicazione.
Bassa latenza: poiché i servizi in contenitori non richiedono la comunicazione roundtrip verso/dal cloud, le risposte vengono restituite con latenze molto inferiori.
Privacy e sicurezza dei dati: è possibile distribuire i servizi in contenitori in reti private, in modo che i dati sensibili non lascino la rete.
Elevata scalabilità: i servizi in contenitori non prevedono "limiti di velocità" e vengono eseguiti in computer gestiti dall'utente. È quindi possibile ridimensionare gli strumenti Foundry senza fine per gestire carichi di lavoro molto più grandi.
Seguire questa guida per creare uno strumento Microsoft Foundry in contenitori.
Creare un cluster Apache Spark
Apache Spark™ è un framework di elaborazione distribuito progettato per l'elaborazione di Big Data. Gli utenti possono usare Apache Spark in Azure con servizi come Azure Databricks, Azure Synapse Analytics, HDInsight e i servizi Azure Kubernetes. Per usare gli strumenti di Big Data Foundry, è prima necessario creare un cluster. Se è già disponibile un cluster Spark, provare a eseguire un esempio.
Azure Databricks
Azure Databricks è una piattaforma di analisi basata su Apache Spark configurabile con un clic, con flussi di lavoro semplificati e un'area di lavoro interattiva. Si usa spesso per la collaborazione tra scienziati dei dati, ingegneri e analisti aziendali. Per usare gli strumenti di Big Data Foundry in Azure Databricks, seguire questa procedura:
Installare la libreria open source SynapseML (o la libreria MMLSpark se si supporta un'applicazione legacy):
Creare una nuova libreria nell'area di lavoro di Databricks
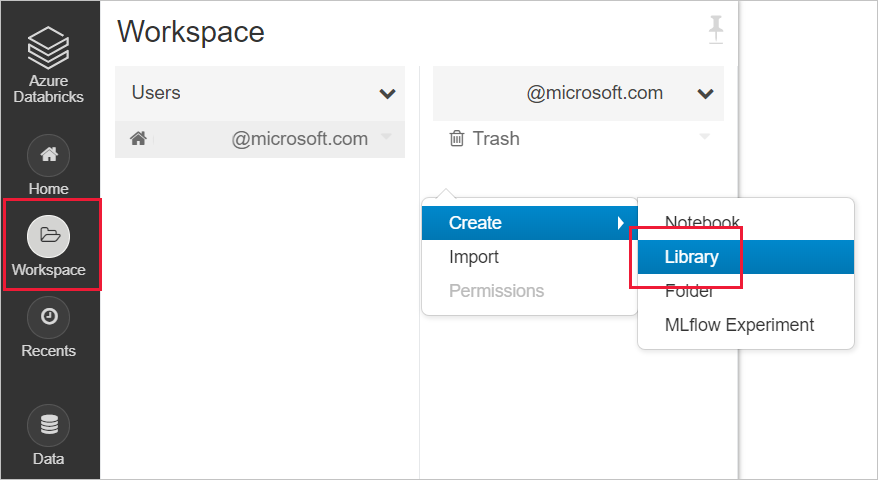
Per SynapseML: immettere le coordinate maven seguenti:
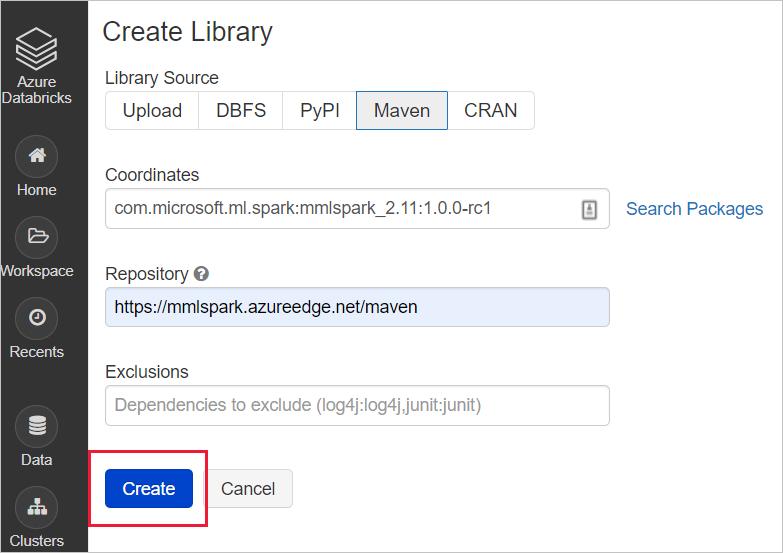
com.microsoft.azure:synapseml_2.12:0.10.0Repository: impostazione predefinitaPer MMLSpark (legacy): immettere le coordinate maven seguenti:
com.microsoft.ml.spark:mmlspark_2.11:1.0.0-rc3Repository:https://mmlspark.azureedge.net/maven
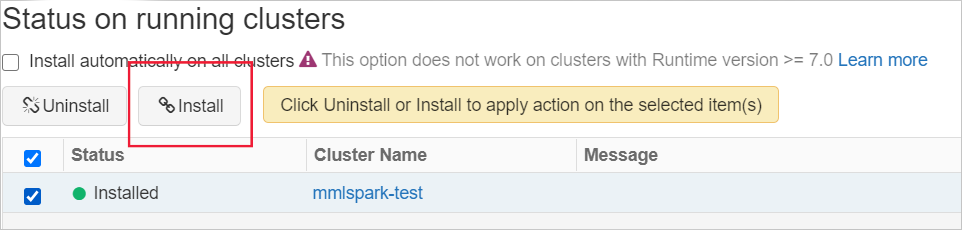
Installare la libreria su un cluster
Azure Synapse Analytics (facoltativo)
Facoltativamente, è possibile usare Synapse Analytics per creare un cluster Spark. Azure Synapse Analytics riunisce funzionalità aziendali di data warehousing e analisi di Big Data. Offre la libertà di eseguire query sui dati in base alle proprie esigenze, usando risorse serverless su richiesta o con provisioning, su scala. Per iniziare a usare Azure Synapse Analytics, seguire questa procedura:
In Azure Synapse Analytics i Big Data per gli strumenti Foundry vengono installati per impostazione predefinita.
Servizio Azure Kubernetes
Se si usano gli strumenti Foundry in contenitori, un'opzione comune per la distribuzione di Spark insieme ai contenitori è il servizio Azure Kubernetes.
Per iniziare a usare il servizio Azure Kubernetes, seguire questa procedura:
Distribuire un cluster del servizio Azure Kubernetes usando il portale di Azure
Installare un contenitore di Azure per intelligenza artificiale con Helm
Provare un esempio
Dopo aver configurato il cluster Spark e l'ambiente, è possibile eseguire un breve esempio. Questo esempio presuppone Azure Databricks e il pacchetto mmlspark.cognitive. Per un esempio di uso di synapseml.cognitive, vedere Aggiungere la ricerca ai dati arricchiti dall'intelligenza artificiale da Apache Spark usando SynapseML.
Creare prima di tutto un notebook in Azure Databricks. Per altri provider di cluster Spark, usare i loro notebook o Spark Submit.
Creare un nuovo notebook di Databricks scegliendo Nuovo notebook dal menu Azure Databricks.

Nella finestra di dialogo Crea Notebook immettere un nome, selezionare Python come linguaggio e selezionare il cluster Spark creato in precedenza.
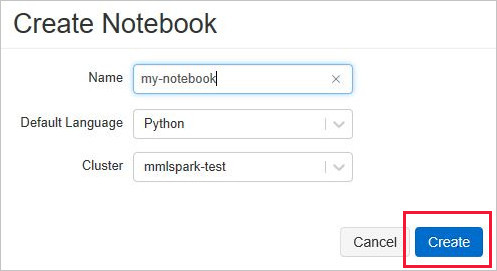
Seleziona Crea.
Incollare questo frammento di codice nel nuovo notebook.
from mmlspark.cognitive import * from pyspark.sql.functions import col # Add your region and subscription key from the Language service service_key = "ADD-SUBSCRIPTION-KEY-HERE" service_region = "ADD-SERVICE-REGION-HERE" df = spark.createDataFrame([ ("I am so happy today, its sunny!", "en-US"), ("I am frustrated by this rush hour traffic", "en-US"), ("The Foundry Tools on spark aint bad", "en-US"), ], ["text", "language"]) sentiment = (TextSentiment() .setTextCol("text") .setLocation(service_region) .setSubscriptionKey(service_key) .setOutputCol("sentiment") .setErrorCol("error") .setLanguageCol("language")) results = sentiment.transform(df) # Show the results in a table display(results.select("text", col("sentiment")[0].getItem("score").alias("sentiment")))Ottenere l'area e la chiave di sottoscrizione dal menu Chiavi ed endpoint dalla risorsa di lingua nel portale Azure.
Sostituire nel codice del notebook di Databricks i segnaposto per l'area e la chiave di sottoscrizione con i valori validi per la risorsa.
Selezionare il simbolo di riproduzione, o triangolo, nell'angolo in alto a destra della cella del notebook per eseguire l'esempio. Facoltativamente, selezionare Esegui tutti nella parte superiore del notebook per eseguire tutte le celle. Le risposte vengono visualizzate sotto la cella in una tabella.
Risultati previsti
| Testo | Sentiment |
|---|---|
| Sono così felice oggi, c'è il sole! | 0,978959 |
| Sono frustrato da questo traffico dell'ora di punta | 0,0237956 |
| Gli strumenti Foundry su Spark non sono male | 0,888896 |