Esercitazione: Eseguire il training di un modello di Machine Learning senza codice (deprecato)
È possibile arricchire i dati delle tabelle Spark con nuovi modelli di Machine Learning di cui si esegue il training con Machine Learning automatizzato. Nell'area di lavoro di Azure Synapse Analytics è possibile selezionare una tabella Spark da usare come set di dati di training per lo sviluppo di modelli di Machine Learning, in un'esperienza senza codice.
In questa esercitazione si apprenderà come eseguire il training il modelli di Machine Learning usando un'esperienza senza codice in Synapse Studio. Synapse Studio è una funzionalità di Azure Synapse Analytics.
Si userà Machine Learning automatizzato in Azure Machine Learning, invece di codificare l'esperienza manualmente. Il tipo di modello di cui si esegue il training dipende dal problema che si vuole provare a risolvere. Per questa esercitazione si userà un modello di regressione per stimare le tariffe dei taxi dal set di dati dei taxi di New York City.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Avviso
- A partire dal 29 settembre 2023, Azure Synapse interromperà il supporto ufficiale per i runtime di Spark 2.4. Dopo il 29 settembre 2023, non verranno affrontati ticket di supporto correlati a Spark 2.4. Non sarà disponibile alcuna pipeline di versione per correzioni di bug o di sicurezza per Spark 2.4. L'uso di Spark 2.4 dopo la data di scadenza del supporto viene intrapresa a proprio rischio. Sconsigliamo vivamente il suo uso continuo a causa di potenziali problemi di sicurezza e funzionalità.
- Come parte del processo di deprecazione per Apache Spark 2.4, si vuole segnalare che AutoML in Azure Synapse Analytics sarà deprecato. Sono incluse sia l'interfaccia a basso codice che le API usate per creare versioni di valutazione autoML tramite codice.
- Si noti che la funzionalità AutoML era disponibile esclusivamente tramite il runtime di Spark 2.4.
- Per i clienti che vogliono continuare a sfruttare le funzionalità autoML, è consigliabile salvare i dati nell'account Azure Data Lake Storage Gen2 (ADLSg2). Da qui è possibile accedere facilmente all'esperienza AutoML tramite Azure Machine Learning (AzureML). Altre informazioni su questa soluzione alternativa sono disponibili qui.
Prerequisiti
- Un'area di lavoro di Azure Synapse Analytics. Assicurarsi di avere un account di archiviazione di Azure Data Lake Storage Gen2 configurato come risorsa archiviazione predefinita. Assicurarsi di avere il ruolo di Collaboratore ai dati del BLOB di archiviazione per il file system di Data Lake Storage Gen2 usato.
- Un pool di Apache Spark (versione 2.4) nell'area di lavoro di Azure Synapse Analytics. Per dettagli, consultare Avvio rapido: Creare un pool di Apache Spark serverless con Synapse Studio.
- Un servizio collegato di Azure Machine Learning nell'area di lavoro di Azure Synapse Analytics. Per dettagli, consultare Avvio rapido: Creare un nuovo servizio collegato di Azure Machine Learning in Azure Synapse Analytics.
Accedere al portale di Azure
Accedere al portale di Azure.
Creare una tabella Spark per il set di dati di training
Per eseguire questa esercitazione è necessaria una tabella Spark. Il notebook seguente consente di crearne una:
Scaricare il notebook Create-Spark-Table-NYCTaxi- Data.ipynb.
Importare il notebook in Synapse Studio.
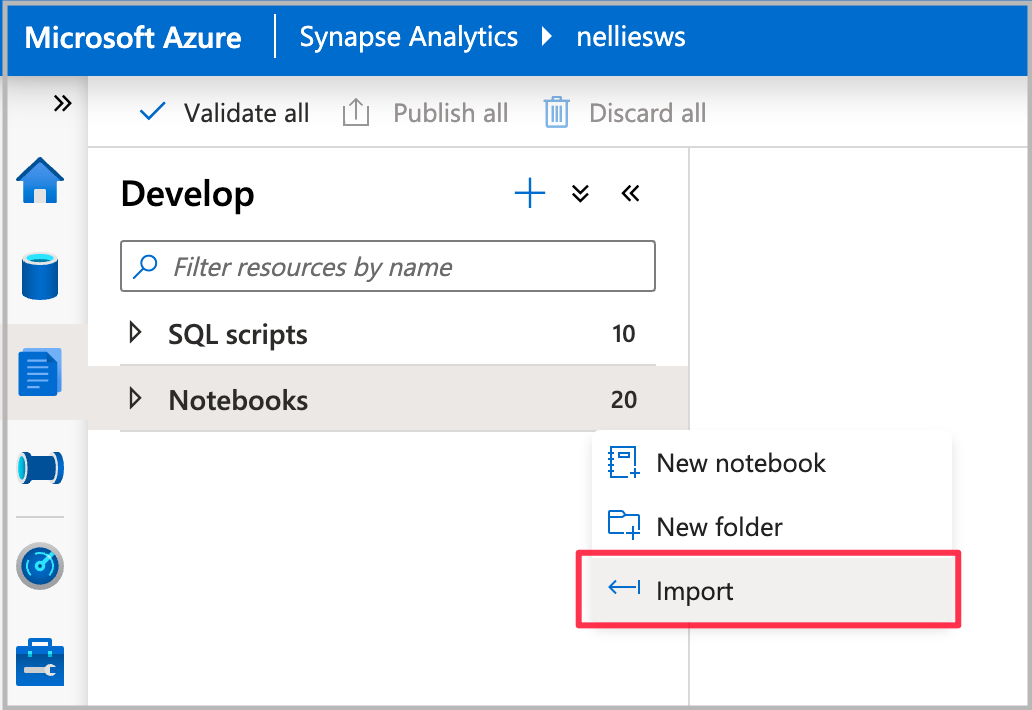
Selezionare il pool di Spark da usare e quindi selezionare Esegui tutti. Con questo passaggio si otterranno i dati dei taxi di New York dal set di dati aperto, che verranno salvati nel database Spark predefinito.

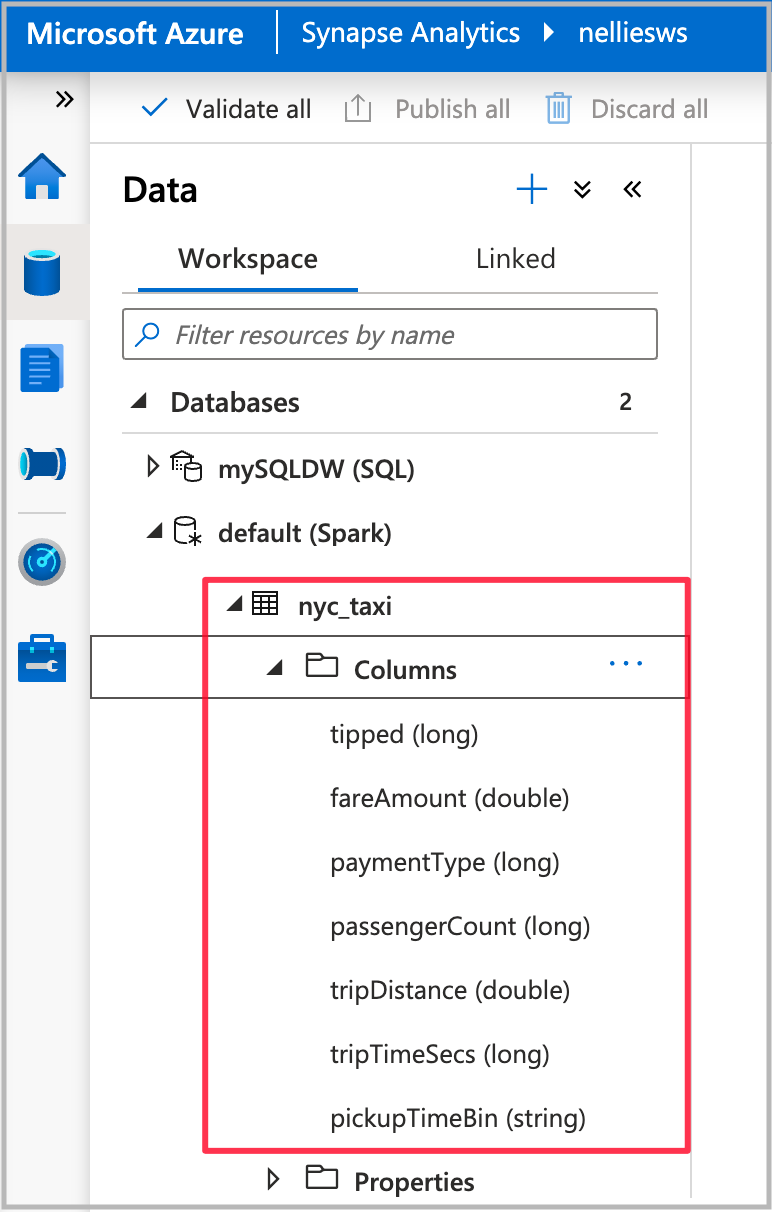
Una volta completata l'esecuzione del notebook, si vedrà una nuova tabella Spark nel database Spark predefinito. In Dati trovare la tabella denominata nyc_taxi.
Aprire la procedura guidata di Machine Learning automatizzato
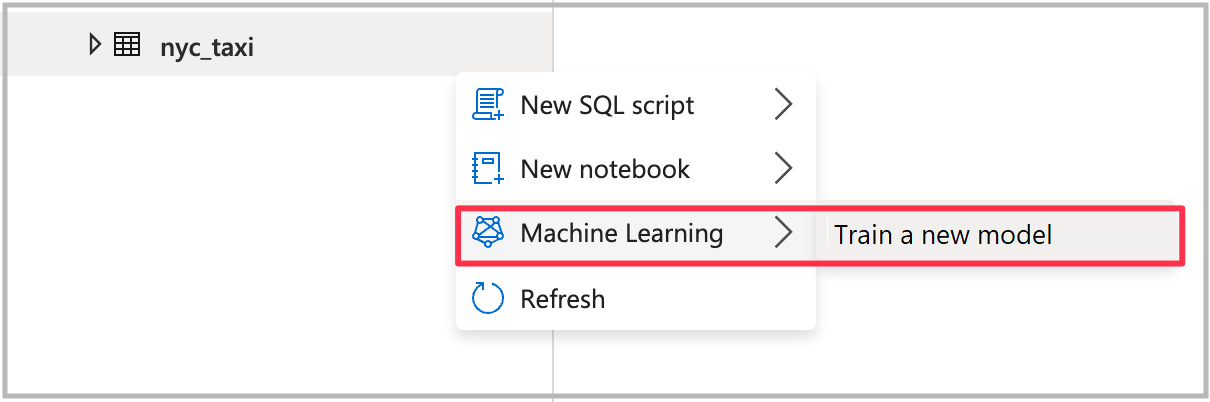
Per aprire la procedura guidata, fare clic con il pulsante destro del mouse sulla tabella Spark creata nel passaggio precedente. Selezionare quindi Machine Learning>Eseguire il training di un nuovo modello.
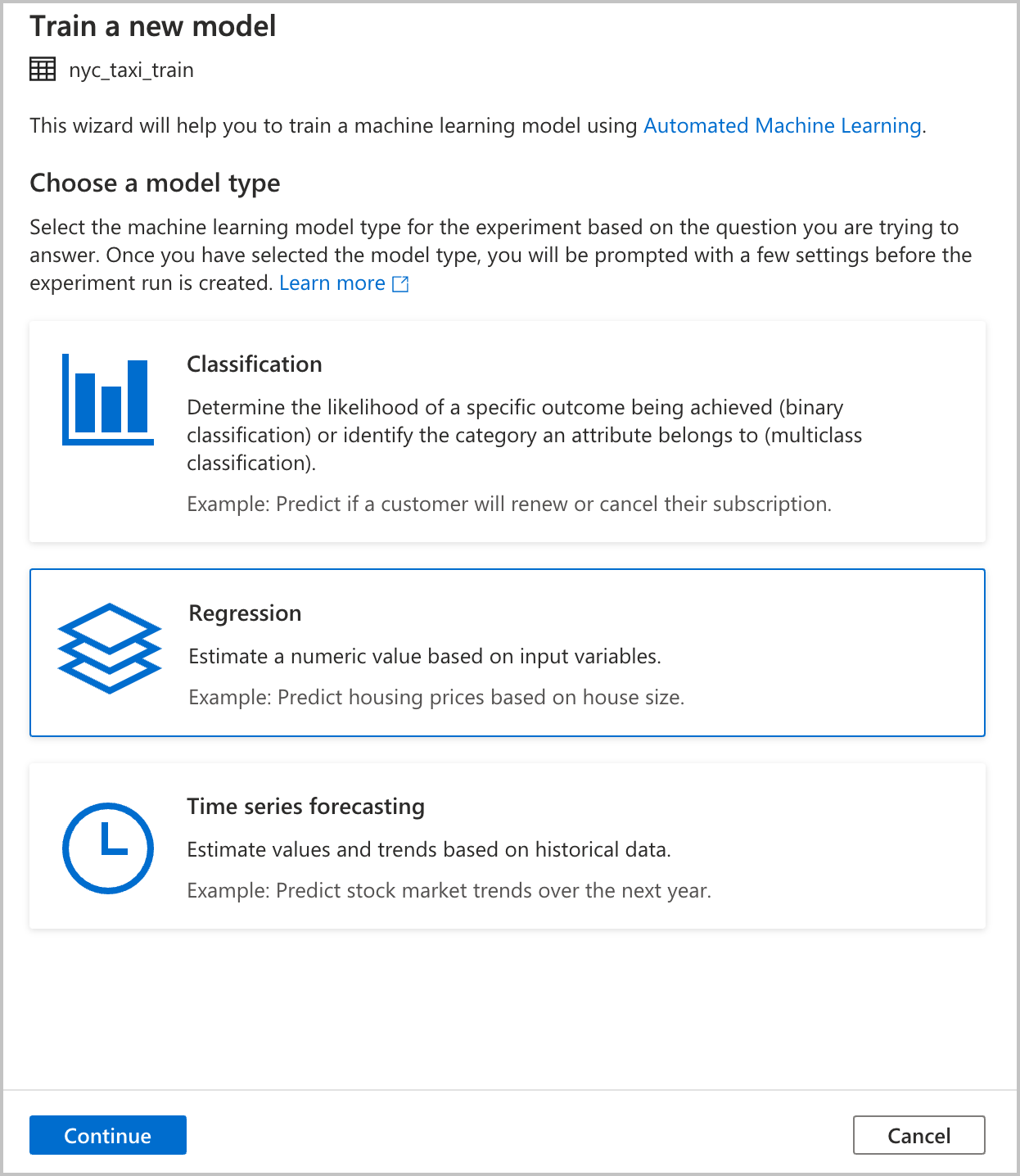
Scegliere un tipo di modello
Selezionare il tipo di modello di Machine Learning per l'esperimento in base alla domanda a cui si sta cercando di rispondere. Poiché il valore che si sta tentando di stimare è numerico (tariffe dei taxi), selezionare Regressione qui. Selezionare Continua.
Configurare l'esperimento
Specificare i dettagli di configurazione per creare un'esecuzione dell'esperimento di Machine Learning automatizzato in Azure Machine Learning. Questa esecuzione esegue il training di più modelli. Il modello migliore di un'esecuzione riuscita viene registrato nel registro modelli di Azure Machine Learning.
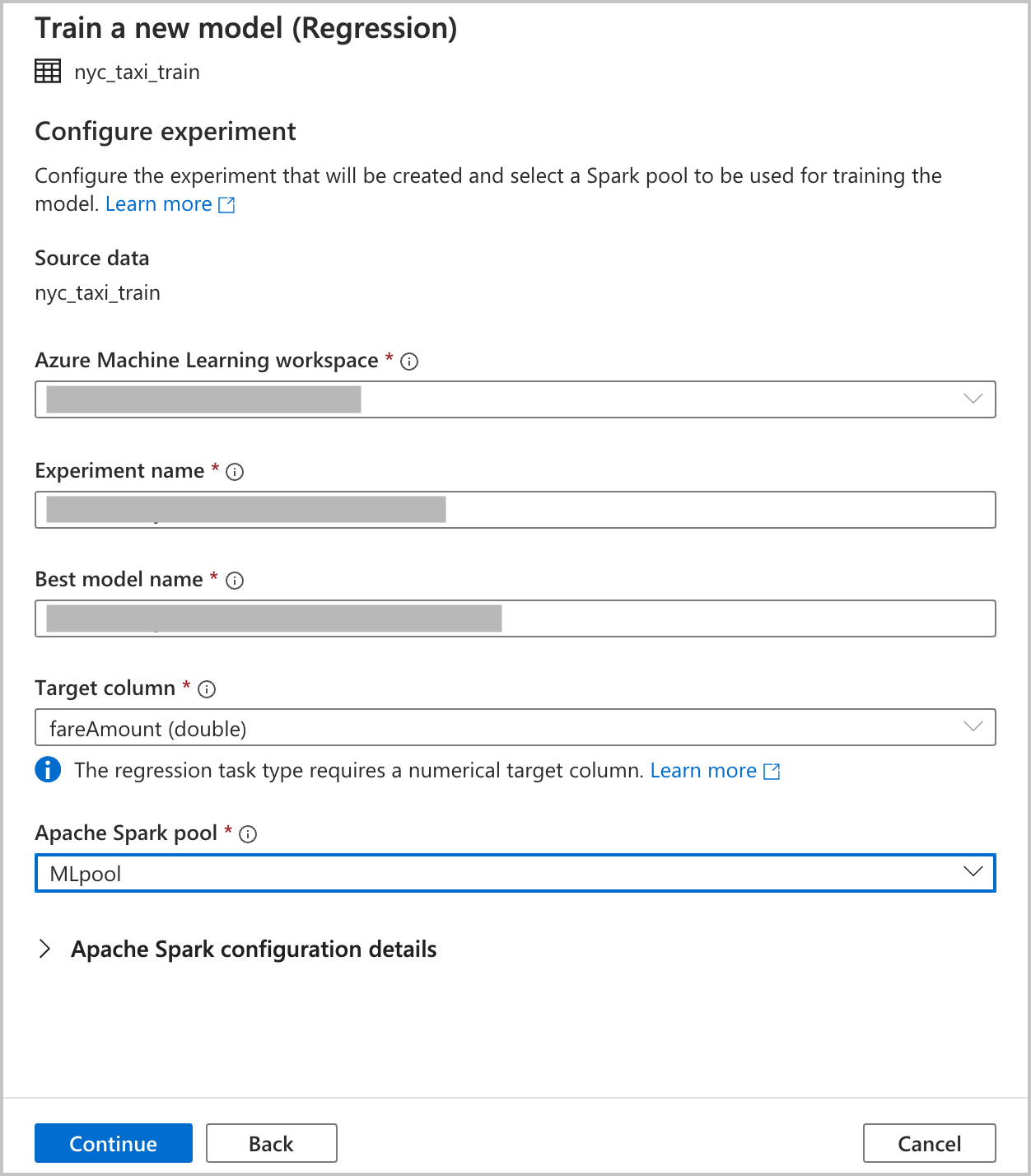
Area di lavoro di Azure Machine Learning: è necessaria un'area di lavoro di Azure Machine Learning per la creazione di un'esecuzione automatica dell'esperimento di Machine Learning. Occorre anche collegare l'area di lavoro di Azure Synapse Analytics all'area di lavoro di Azure Machine Learning usando un servizio collegato. Dopo aver soddisfatto tutti i prerequisiti, è possibile specificare l'area di lavoro di Azure Machine Learning da usare per questa esecuzione automatizzata.
Nome esperimento: specificare il nome dell'esperimento. Quando si invia un'esecuzione di Machine Learning automatizzato, si fornisce un nome dell'esperimento. Le informazioni per l'esecuzione vengono archiviate in tale esperimento nell'area di lavoro di Azure Machine Learning. Questa esperienza crea per impostazione predefinita un nuovo esperimento e genera un nome proposto, ma si può anche specificare il nome di un esperimento esistente.
Nome del modello migliore: specificare il nome del modello migliore generato dall'esecuzione di ML automatizzato. Questo nome viene assegnato al modello migliore e viene salvato automaticamente nel registro di modelli di Azure Machine Learning dopo l'esecuzione. Un'esecuzione di Machine Learning automatizzato crea diversi modelli di Machine Learning. In base alla metrica primaria che verrà selezionata in un passaggio successivo, è possibile confrontare questi modelli e selezionare quello migliore.
Colonna di destinazione: Training del modello su ciò che si vuole prevedere. Scegliere la colonna nel set di dati che contiene i dati da stimare. Per questa esercitazione viene selezionata la colonna numerica
fareAmountcome destinazione.Pool di Spark: specificare il pool di Spark da usare per l'esecuzione automatica dell'esperimento. I calcoli vengono eseguiti nel pool specificato.
Dettagli di configurazione di Spark: oltre all'opzione per il pool di Spark, è anche disponibile un'opzione per specificare i dettagli della configurazione della sessione.
Selezionare Continua.
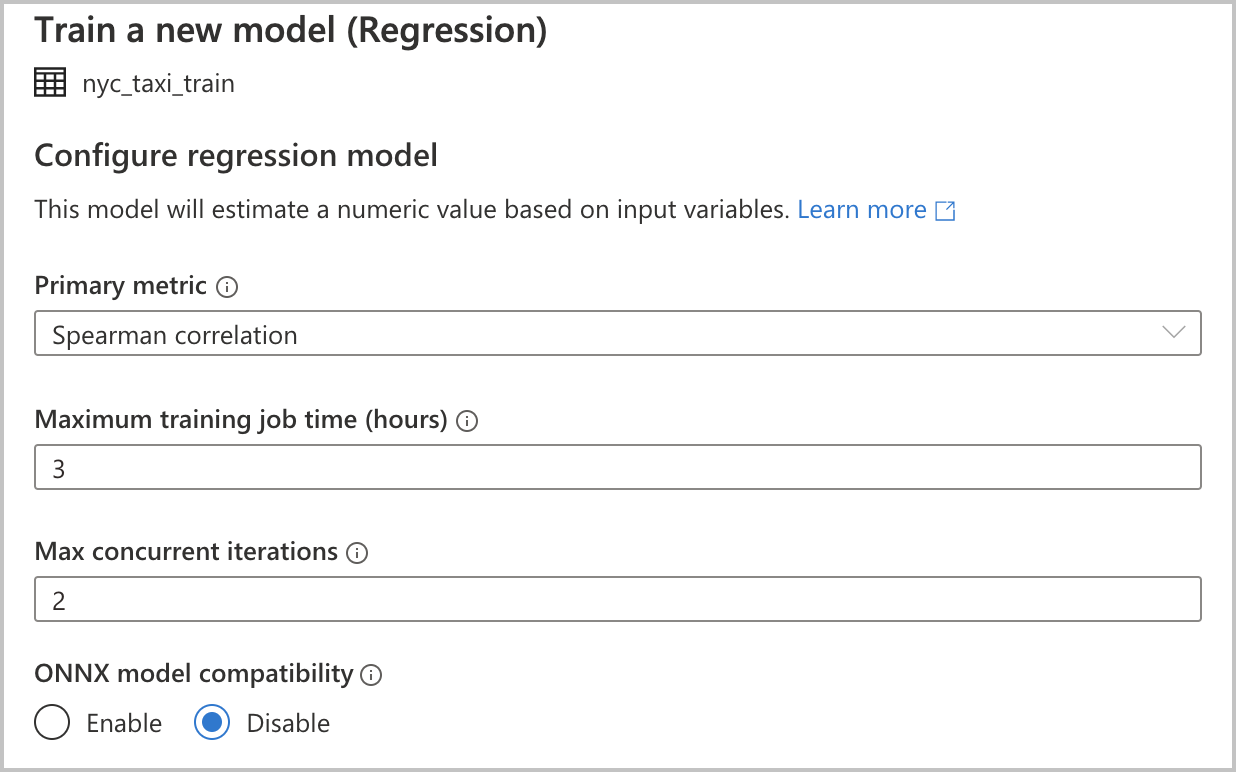
Configurare il modello
Poiché è stata selezionata Regressione come tipo di modello nella sezione precedente, sono disponibili le configurazioni seguenti (anche disponibili per il tipo di modello Classificazione):
Metrica primaria: immettere la metrica che misura il funzionamento del modello. Si tratta della metrica usata per confrontare i diversi modelli creati nell'esecuzione automatizzata e per determinare qual è il migliore.
Tempo del processo di training (ore): specificare la quantità massima di tempo, in ore, assegnata per l'esecuzione di un esperimento e il training dei modelli. Si noti che è anche possibile specificare valori minori di 1 (ad esempio 0.5).
Numero massimo di iterazioni simultanee: scegliere il numero massimo di iterazioni eseguite in parallelo.
Compatibilità del modello ONNX: se si abilita questa opzione, i modelli sottoposti a training mediante Machine Learning automatizzato vengono convertiti nel formato ONNX. Questa opzione è particolarmente utile se si vuole usare il modello per assegnare punteggi nei pool SQL di Azure Synapse Analytics.
Tutte queste impostazioni prevedono un valore predefinito che è possibile personalizzare.
Avviare un'esecuzione
Una volta completate tutte le configurazioni necessarie, è possibile avviare l'esecuzione automatizzata. È possibile scegliere di creare un'esecuzione direttamente selezionando Crea esecuzione. Verrà avviata l'esecuzione senza codice. In alternativa, se si preferisce il codice, è possibile selezionare Apri nel notebook. Verrà aperto un notebook contenente il codice che crea l'esecuzione in modo da poter visualizzare il codice e avviare l'esecuzione manualmente.

Nota
Se come tipo di modello si è selezionato Previsione di serie temporali nella sezione precedente, è necessario impostare altre configurazioni. La previsione, inoltre, non supporta la compatibilità con il modello ONNX.
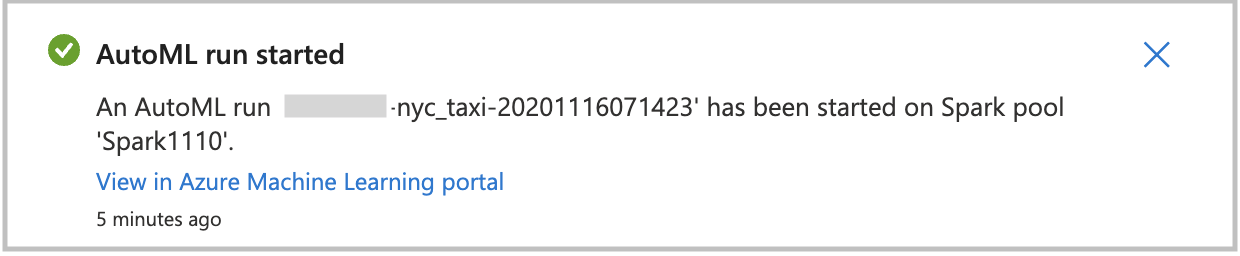
Creare direttamente un'esecuzione
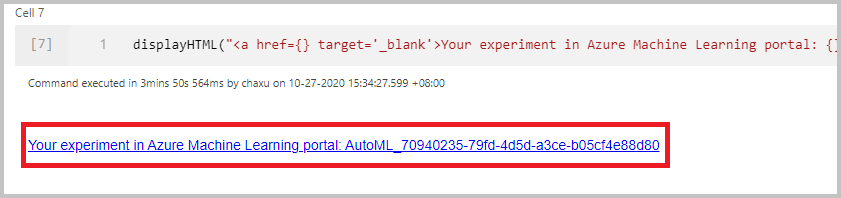
Per avviare l'esecuzione di Machine Learning automatizzato direttamente, selezionare Crea esecuzione. Viene visualizzata una notifica che indica che è in corso l'avvio dell'esecuzione. Alla fine viene visualizzata un'altra notifica che indica che l'esecuzione è riuscita. Si può anche controllare lo stato in Azure Machine Learning selezionando il collegamento nella notifica.
Creare un'esecuzione con un notebook
Selezionare Apri nel notebook per generare un notebook. In questo modo è possibile aggiungere impostazioni o modificare il codice per l'esecuzione di Machine Learning automatizzato. Quando si è pronti per eseguire il codice, selezionare Esegui tutto.

Monitorare l'esecuzione
Dopo avere inviato correttamente l'esecuzione, nell'output del notebook nell'area di lavoro di Azure Machine Learning sarà disponibile un collegamento all'esecuzione dell'esperimento. Selezionare il collegamento per monitorare l'esecuzione automatizzata in Azure Machine Learning.