Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure Synapse Analytics offre vari motori di analisi che consentono di inserire, trasformare, modellare e analizzare i dati. Un pool SQL dedicato offre funzionalità di calcolo e archiviazione basate su T-SQL. Dopo aver creato un pool SQL dedicato nell'area di lavoro synapse, è possibile caricare, modellare, elaborare e recapitare i dati per ottenere informazioni analitiche più veloci.
Questo argomento di avvio rapido illustra come caricare i dati dal database SQL di Azure in Azure Synapse Analytics. È possibile seguire una procedura simile a quella usata per copiare dati da altri tipi di archivi dati. Questo flusso simile si applica anche alla copia di dati per altre origini e sink.
Prerequisiti
- Sottoscrizione di Azure: se non si ha una sottoscrizione di Azure, creare un account Azure gratuito prima di iniziare.
- Area di lavoro di Azure Synapse: creare un'area di lavoro Synapse usando il portale di Azure seguendo le istruzioni riportate in Avvio rapido: Creare un'area di lavoro synapse.
- Database SQL di Azure: questa esercitazione copia i dati da un database SQL di Azure con dati di esempio di Adventure Works LT. È possibile creare questo database di esempio in Database SQL seguendo le istruzioni fornite in Creare un database di esempio in Database SQL di Azure. In alternativa, è possibile usare altri archivi dati seguendo una procedura simile.
- Account di archiviazione di Azure: Archiviazione di Azure viene usato come area di staging nell'operazione di copia. Se non è disponibile un account di archiviazione di Azure, vedere le istruzioni fornite in Creare un account di archiviazione.
- Azure Synapse Analytics: si usa un pool SQL dedicato come archivio dati sink. Se non si ha un'istanza di Azure Synapse Analytics, vedere Creare un pool SQL dedicato per la procedura per crearne una.
Vai su Synapse Studio
Dopo aver creato l'area di lavoro di Synapse, è possibile aprire Synapse Studio in due modi:
- Aprire l'area di lavoro di Synapse nel portale di Azure. Selezionare Apri sulla scheda Open Synapse Studio sotto Guida introduttiva.
- Aprire Azure Synapse Analytics e accedere all'area di lavoro.
In questa guida rapida, usiamo l'area di lavoro denominata "adftest2020" come esempio. Verrà visualizzata automaticamente la home page di Synapse Studio.
Creare servizi collegati
In Azure Synapse Analytics, un servizio collegato è la posizione in cui si definiscono le informazioni di connessione ad altri servizi. In questa sezione verranno creati due tipi di servizi collegati seguenti: database SQL di Azure e servizi collegati di Azure Data Lake Storage Gen2 (ADLS Gen2).
Nella home page di Synapse Studio selezionare la scheda Gestisci nel riquadro di spostamento a sinistra.
In Connessioni esterne selezionare Servizi collegati.
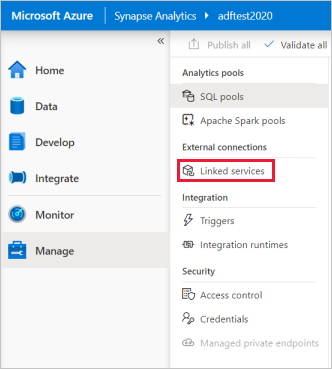
Per aggiungere un servizio collegato, selezionare Nuovo.
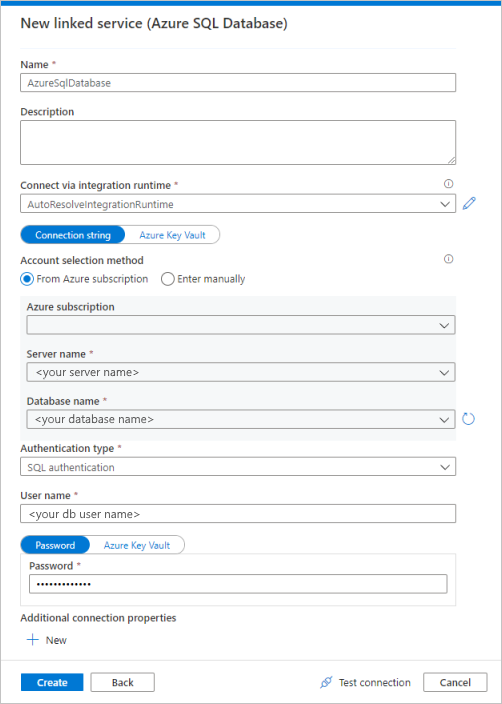
Selezionare Database SQL di Azure nella raccolta e quindi Continua. È possibile digitare "sql" nella casella di ricerca per filtrare i connettori.

Nella pagina Nuovo servizio collegato selezionare il nome del server e il nome del database dall'elenco a discesa e specificare il nome utente e la password. Fare clic su Test connessione per convalidare le impostazioni e quindi selezionare Crea.
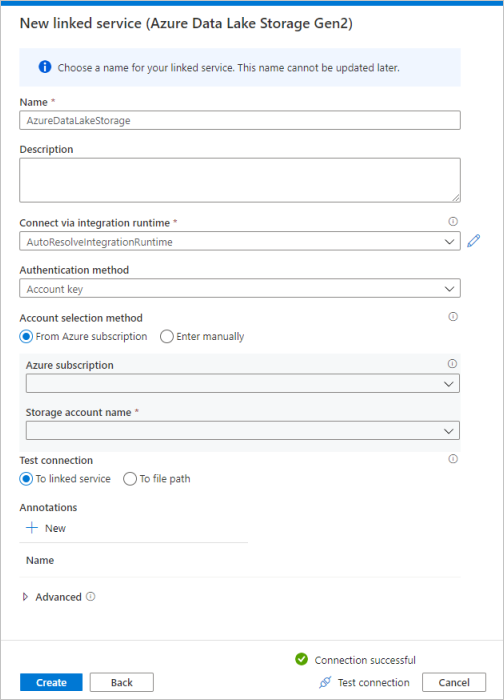
Ripetere i passaggi 3 e 4 selezionando però Azure Data Lake Storage Gen2 dalla raccolta. Nella pagina Nuovo servizio collegato selezionare il nome dell'account di archiviazione dall'elenco a discesa. Fare clic su Test connessione per convalidare le impostazioni e quindi selezionare Crea.
Creare una pipeline
Una pipeline contiene il flusso logico per un'esecuzione di un set di attività. In questa sezione si creerà una pipeline contenente un'attività di copia che inserisce i dati dal database SQL di Azure in un pool SQL dedicato.
Passare alla scheda Integrazione . Selezionare l'icona con il segno più accanto all'intestazione pipeline e selezionare Pipeline.
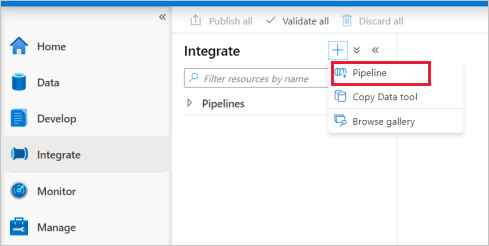
Nel riquadro Attività, sotto Sposta e trasforma, trascina Copia dati nell'area di disegno della pipeline.
Selezionare l'attività di copia e passare alla scheda Origine. Selezionare Nuovo per creare un nuovo set di dati di origine.
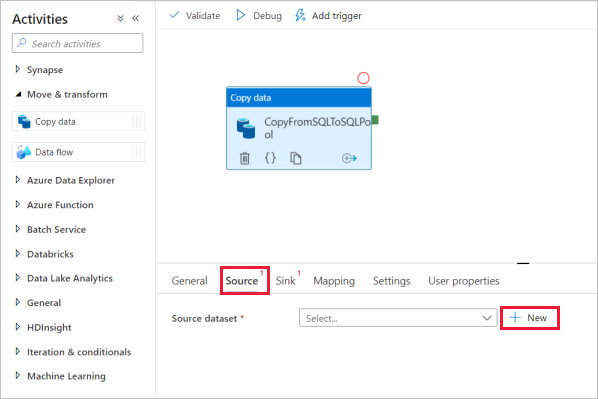
Selezionare Database SQL di Azure come archivio dati e selezionare Continua.
Nel riquadro Imposta proprietà selezionare il servizio collegato database SQL di Azure creato nel passaggio precedente.
In Nome tabella selezionare una tabella di esempio da usare nell'attività di copia seguente. In questo avvio rapido, utilizziamo la tabella "SalesLT.Customer" come esempio.
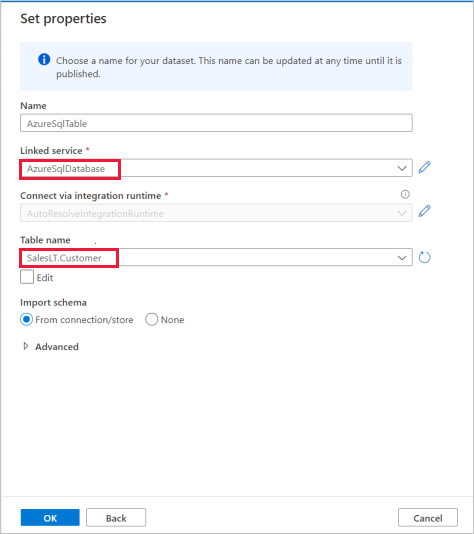
Al termine, selezionare OK.
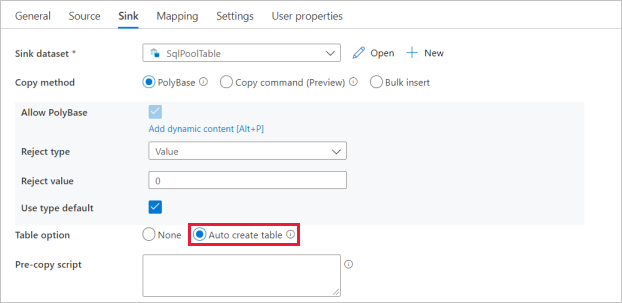
Selezionare l'attività di copia e passare alla scheda Sink. Selezionare Nuovo per creare un nuovo set di dati sink.
Selezionare Pool SQL dedicato di Azure Synapse come archivio dati e selezionare Continua.
Nel riquadro Imposta proprietà selezionare il pool di Analisi SQL creato nel passaggio precedente. Se stai scrivendo su una tabella esistente, nel campo Nome tabella, selezionala dall'elenco a discesa. In caso contrario, selezionare "Modifica" e immettere il nome della nuova tabella. Al termine, selezionare OK.
Per le impostazioni del set di dati sink, abilitare Creazione automatica tabella nel campo Opzioni Tabella.
Nella pagina Impostazioni selezionare la casella di controllo Abilita gestione temporanea. Questa opzione si applica se i dati di origine non sono compatibili con PolyBase. Nella sezione Impostazioni di staging, seleziona il servizio collegato di Azure Data Lake Storage Gen2 che hai creato in un passaggio precedente come archiviazione temporanea.
L'archivio viene usato per eseguire lo staging dei dati prima di caricarli in Azure Synapse Analytics tramite PolyBase. Al termine della copia, i dati provvisori in Azure Data Lake Storage Gen2 vengono puliti automaticamente.
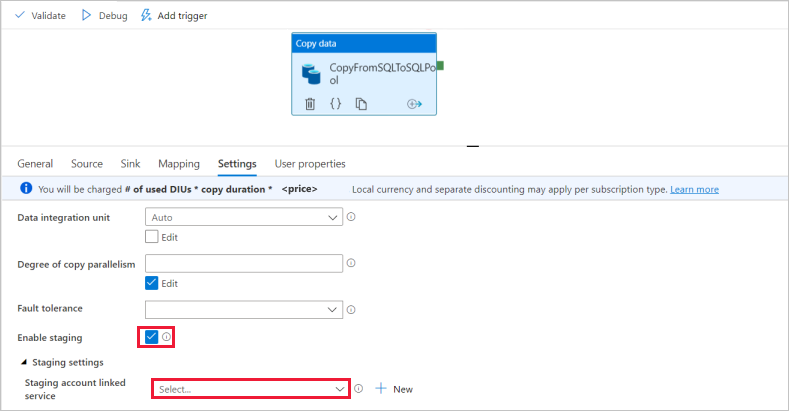
Per convalidare la pipeline, selezionare Convalida sulla barra degli strumenti. Il risultato dell'output di convalida della pipeline viene visualizzato sul lato destro della pagina.
Eseguire il debug della pipeline e pubblicarla
Dopo aver completato la configurazione della pipeline, è possibile eseguire un'esecuzione di debug prima di pubblicare gli artefatti per verificare che tutto sia corretto.
Per eseguire il debug della pipeline, selezionare Debug sulla barra degli strumenti. Lo stato dell'esecuzione della pipeline verrà visualizzato nella scheda Output nella parte inferiore della finestra.
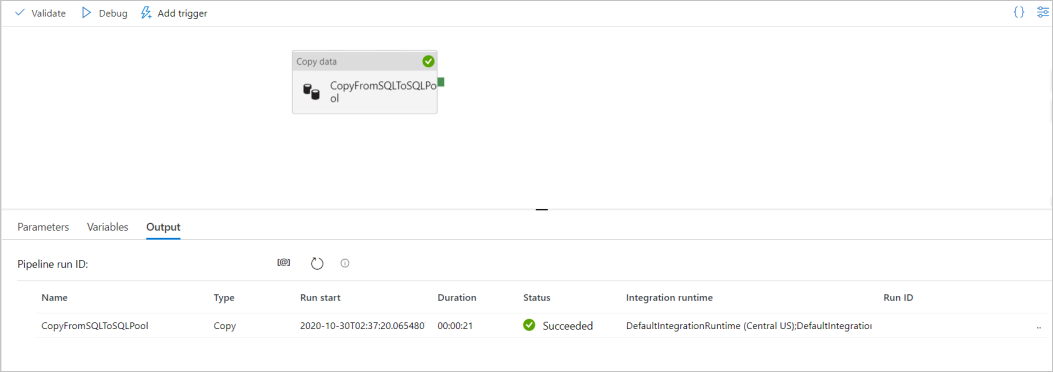
Al termine dell'esecuzione della pipeline, nella barra degli strumenti superiore selezionare Pubblica tutto. Questa azione pubblica le entità (set di dati e pipeline) create nel servizio Synapse Analytics.
Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita. Per visualizzare i messaggi di notifica, selezionare il pulsante a forma di campana in alto a destra.
Attivare e monitorare la pipeline
In questa sezione viene attivata manualmente la pipeline pubblicata nel passaggio precedente.
Selezionare Aggiungi trigger nella barra degli strumenti, quindi selezionare Attiva adesso. Nella pagina Esecuzione della pipeline selezionare OK.
Passare alla scheda Monitoraggio nella barra laterale sinistra. Viene visualizzata un'esecuzione della pipeline attivata da un trigger manuale.
Al termine dell'esecuzione della pipeline, selezionare il collegamento nella colonna Nome pipeline per visualizzare i dettagli dell'esecuzione dell'attività o per rieseguire la pipeline. In questo esempio è presente una sola attività, quindi nell'elenco viene visualizzata una sola voce.
Per informazioni dettagliate sull'operazione di copia, selezionare il collegamento Dettagli (icona a forma di occhiali) nella colonna Nome attività. È possibile monitorare dettagli come il volume dei dati copiati dall'origine al sink, la velocità effettiva dei dati, i passaggi di esecuzione con la durata corrispondente e le configurazioni usate.
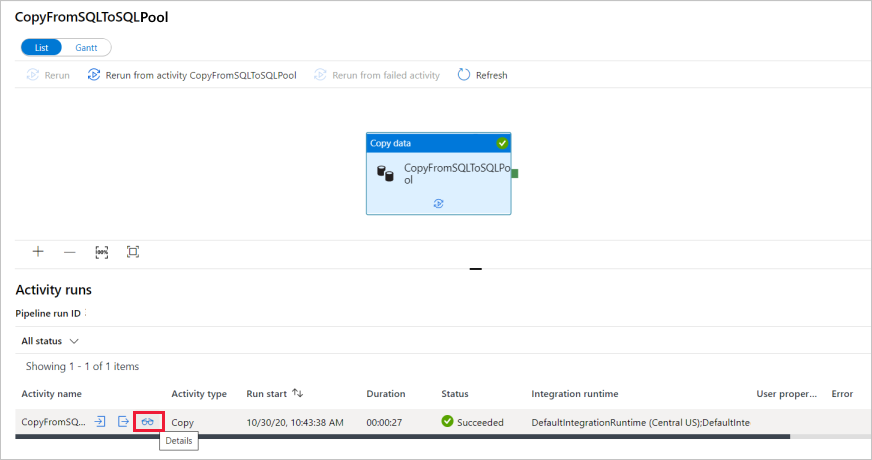
Per tornare alla visualizzazione delle esecuzioni di pipeline, selezionare il collegamento Tutte le esecuzioni della pipeline in alto. Selezionare Aggiorna per aggiornare l'elenco.
Verificare che i dati siano scritti correttamente nel pool SQL dedicato.
Passaggi successivi
Leggere gli articoli seguenti per altre informazioni sul supporto di Azure Synapse Analytics: