Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida introduttiva si usa Azure Synapse Analytics per creare una pipeline usando la definizione del processo Apache Spark.
Prerequisiti
- Sottoscrizione di Azure: se non si dispone di una sottoscrizione di Azure, prima di iniziare, creare un account Azure gratuito.
- Area di lavoro di Azure Synapse: creare un'area di lavoro di Synapse usando il portale di Azure e seguendo le istruzioni in Avvio rapido: creare un'area di lavoro di Synapse.
- Definizione del processo Apache Spark: creare una definizione di processo Apache Spark nell'area di lavoro di Synapse seguendo le istruzioni fornite in Esercitazione: creare una definizione di processo Apache Spark in Synapse Studio.
Passare a Synapse Studio
Dopo aver creato l'area di lavoro di Azure Synapse, è possibile aprire Synapse Studio in due modi:
- Aprire l'area di lavoro di Synapse nel portale di Azure. Selezionare Apri nella scheda Apri Synapse Studio sotto Attività iniziali.
- Aprire Azure Synapse Analytics e accedere all'area di lavoro.
In questo avvio rapido viene usata come esempio l'area di lavoro denominata "sampletest".
Creare una pipeline con una definizione di processo Apache Spark
Una pipeline contiene il flusso logico per un'esecuzione di un set di attività. In questa sezione viene creata una pipeline che contiene un'attività di definizione del processo Apache Spark.
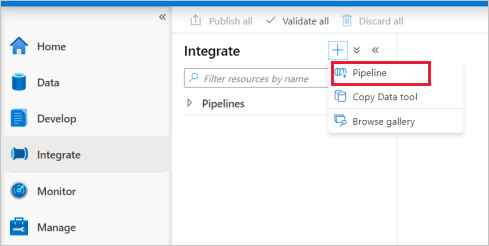
Passare alla scheda Integrazione. Selezionare l'icona con il segno più accanto all'intestazione della pipeline e quindi selezionare Pipeline.
Nella pagina delle impostazioni Proprietà della pipeline immettere demo per Nome.
In Synapse nel riquadro Attività trascinare la definizione del processo Spark nel canvas della pipeline.
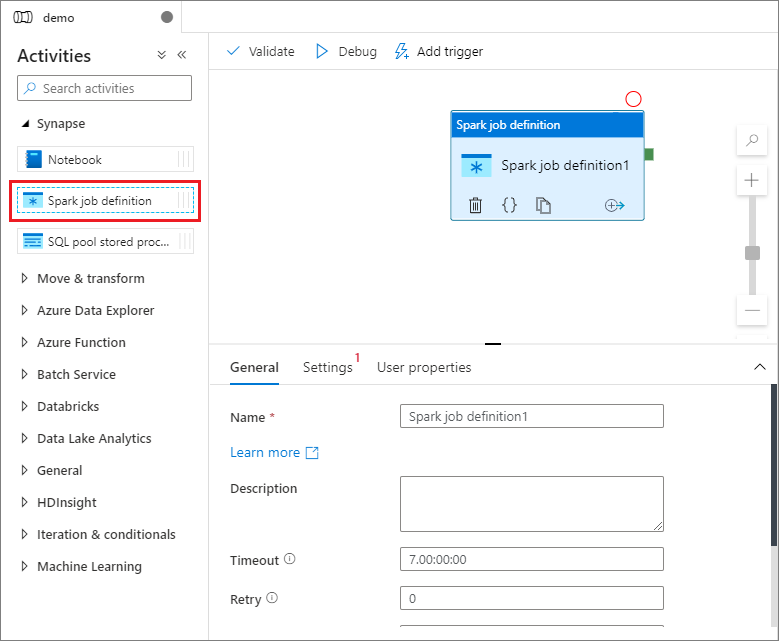
Impostare il canvas della definizione del processo Apache Spark
Dopo aver creato la definizione del processo Apache Spark, l'utente viene inviato automaticamente all'area di disegno della definizione del processo Spark.
Impostazioni generali
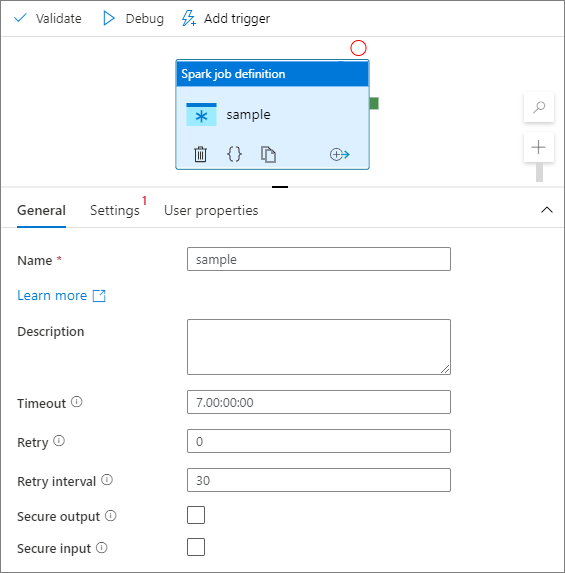
Selezionare il modulo di definizione del processo Spark nel canvas.
Nella scheda Generale immettere sample per Nome.
(Facoltativo) È anche possibile immettere una descrizione.
Timeout: tempo massimo di esecuzione di un'attività. Il valore predefinito è sette giorni, ovvero la quantità massima di tempo consentita. Il formato è in D.HH:MM:SS.
Retry: il numero massimo di tentativi.
Intervallo tra tentativi: numero di secondi tra ogni tentativo.
Output sicuro: quando selezionato, l'output dell'attività non viene acquisito nella registrazione.
Input sicuro: se selezionato, l'input dell'attività non viene acquisito nella registrazione.
Scheda Impostazioni
In questo pannello è possibile fare riferimento alla definizione del processo Spark da eseguire.
Espandere l'elenco delle definizioni di processo Spark; è possibile scegliere una definizione di processo Apache Spark esistente. È anche possibile creare una nuova definizione di processo Apache Spark selezionando il pulsante Nuovo per fare riferimento alla definizione del processo Spark da eseguire.
(Facoltativo) È possibile immettere le informazioni per la definizione di processo Apache Spark. Se le impostazioni seguenti sono vuote, le impostazioni della definizione del processo Spark vengono usate per l'esecuzione; se le impostazioni seguenti non sono vuote, queste impostazioni sostituiscono le impostazioni della definizione del processo Spark stessa.
Proprietà Descrizione File di definizione principale File principale usato per il processo. Selezionare un file PY/JAR/ZIP dalla risorsa di archiviazione. È possibile selezionare Carica file per caricare il file in un account di archiviazione.
Esempio:abfss://…/path/to/wordcount.jarRiferimenti da sottocartelle L'analisi delle sottocartelle dalla cartella radice del file di definizione principale, questi file vengono aggiunti come file di riferimento. Le cartelle denominate "jars", "pyFiles", "files" o "archives" vengono analizzate e il nome delle cartelle fa distinzione tra maiuscole e minuscole. Nome della classe principale Identificatore completo o classe principale inclusa nel file di definizione principale.
Esempio:WordCountArgomenti della riga di comando È possibile aggiungere argomenti della riga di comando facendo clic sul pulsante Nuovo. Si noti che l'aggiunta di argomenti della riga di comando sostituisce gli argomenti della riga di comando definiti dalla definizione del processo Spark.
Esempio:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultPool di Apache Spark È possibile selezionare il pool di Apache Spark dall'elenco. Informazioni di riferimento sul codice Python Altri file di codice Python usati per riferimento nel file di definizione principale.
Supporta il passaggio di file (.py, py3 .zip) alla proprietà "pyFiles". Esegue l'override della proprietà "pyFiles" definita nella definizione del processo Spark.File di riferimento Altri file usati per riferimento nel file di definizione principale. Allocare dinamicamente gli executor Questa impostazione esegue il mapping alla proprietà di allocazione dinamica nella configurazione Spark per l'allocazione degli executor dell'applicazione Spark. Numero minimo di executor Numero minimo di executor da allocare nel pool di Spark specificato per il processo. Numero massimo di executor Numero massimo di executor da allocare nel pool di Spark specificato per il processo. Dimensioni driver Numero di core e memoria da usare per il driver indicato nel pool di Apache Spark specificato per il processo. Configurazione di Spark Specificare i valori per le proprietà di configurazione di Spark elencate nell'articolo: Configurazione Spark - Proprietà dell'applicazione. Gli utenti possono usare la configurazione predefinita e quella personalizzata. 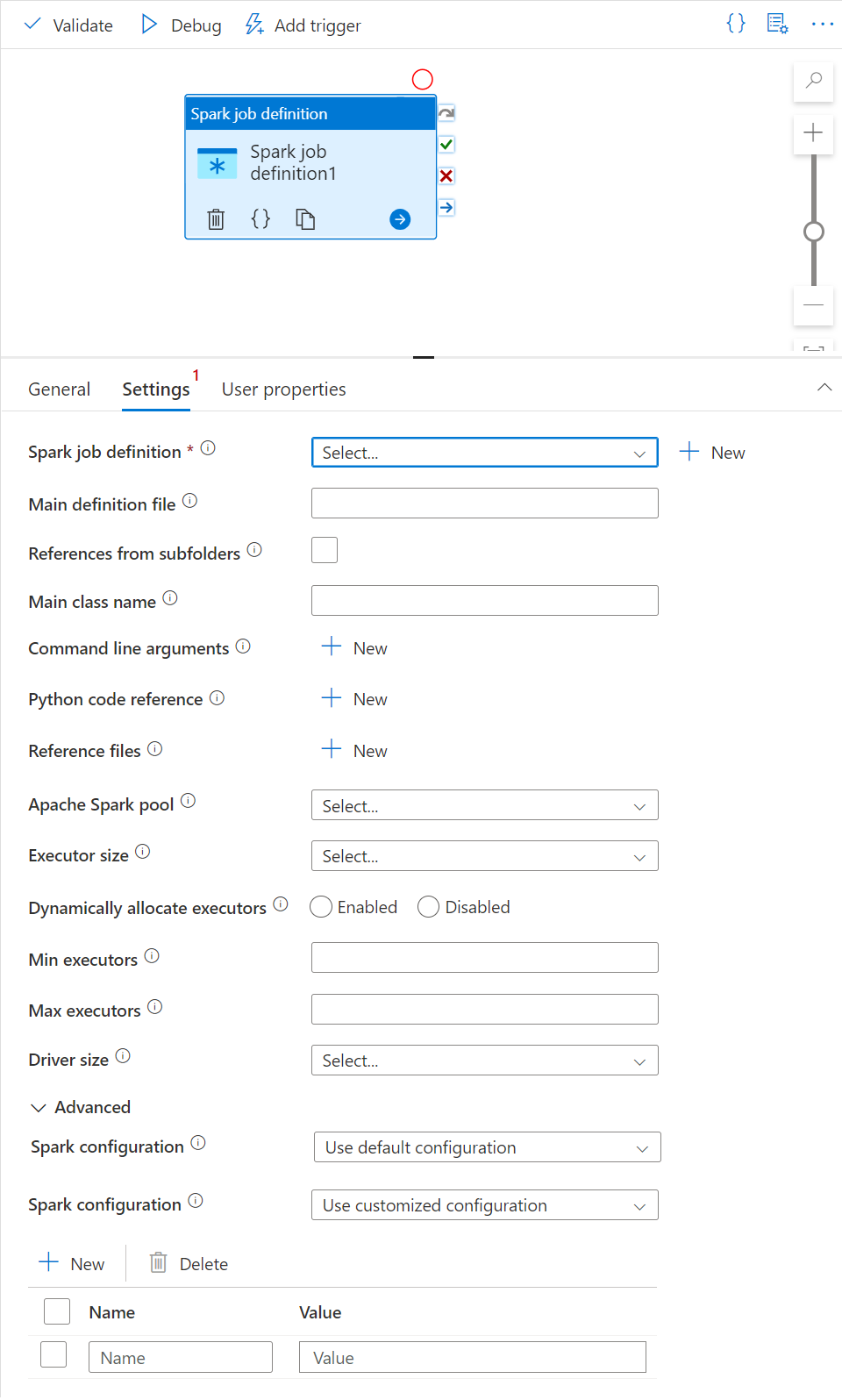
È possibile aggiungere contenuto dinamico facendo clic sul pulsante Aggiungi contenuto dinamico o premendo il tasto di scelta rapida Alt+Maiusc+D. Nella pagina Aggiungi contenuto dinamico è possibile usare qualsiasi combinazione di espressioni, funzioni e variabili di sistema da aggiungere al contenuto dinamico.
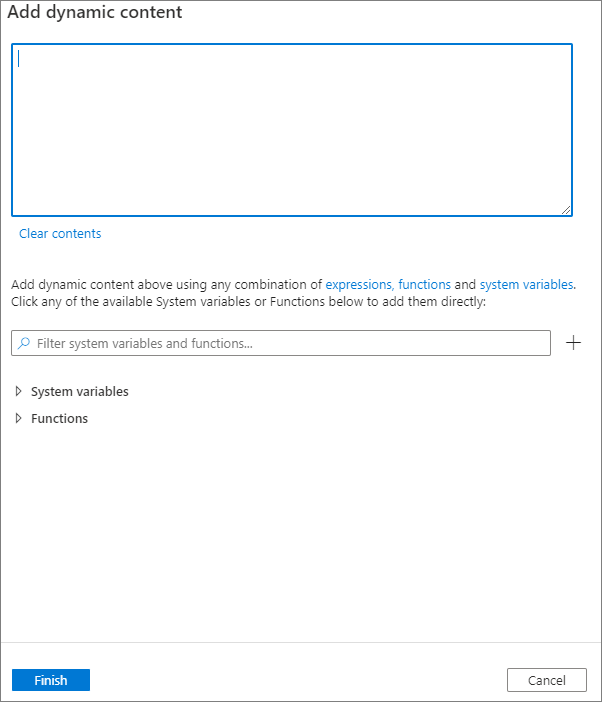
Scheda Proprietà utente
In questo pannello è possibile aggiungere proprietà per l'attività di definizione del processo Apache Spark.

Contenuto correlato
Leggere gli articoli seguenti per altre informazioni sul supporto di Azure Synapse Analytics: