Concetti relativi al ripristino di emergenza di Desktop virtuale Azure
Desktop virtuale Azure è cresciuto enormemente come soluzione di lavoro remota e ibrida negli ultimi anni. Poiché molti utenti ora lavorano in remoto, le organizzazioni richiedono soluzioni con velocità di distribuzione elevata e costi ridotti. Gli utenti devono anche avere un ambiente di lavoro remoto con disponibilità e resilienza garantite che consentano loro di accedere alle macchine virtuali anche durante le emergenze. Questo documento descrive i piani di ripristino di emergenza consigliati per mantenere operativa l'organizzazione.
Per evitare interruzioni o tempi di inattività del sistema, ogni sistema e componente nella distribuzione di Desktop virtuale Azure deve essere a tolleranza di errore. La tolleranza di errore è quando si dispone di una configurazione duplicata o di un sistema in un'altra area di Azure che assume il controllo per la configurazione principale durante un'interruzione. Questa configurazione o sistema secondario riduce l'impatto di un'interruzione localizzata. Esistono molti modi per configurare la tolleranza di errore, ma questo articolo si concentrerà sui metodi attualmente disponibili in Azure.
Infrastruttura di Desktop virtuale Azure
Per capire quali aree rendere a tolleranza di errore, dobbiamo prima sapere chi è responsabile della gestione di ogni area. È possibile dividere la responsabilità nel servizio Desktop virtuale Azure in due aree: Gestito da Microsoft e gestito dal cliente. I metadati come i pool di host, i gruppi di applicazioni e le aree di lavoro sono controllati da Microsoft. I metadati sono sempre disponibili e non richiedono una configurazione aggiuntiva da parte del cliente per replicare i dati o le configurazioni del pool di host. L'infrastruttura gateway è stata progettata per connettere le persone agli host di sessione in modo che siano un servizio globale e altamente resiliente gestito da Microsoft. Nel frattempo, le aree gestite dal cliente coinvolgono le macchine virtuali (VM) usate in Desktop virtuale Azure e le impostazioni e le configurazioni univoche per la distribuzione del cliente. La tabella seguente fornisce un'idea più chiara delle aree gestite da quale parte.
| Gestito da Microsoft | Gestito dal cliente |
|---|---|
| Bilanciamento del carico | Rete |
| Gestore di sessioni | Host di sessione |
| Gateway | Storage |
| Diagnostica | Dati del profilo utente |
| Cloud Identity Platform | Identità |
In questo articolo ci concentreremo sui componenti gestiti dal cliente, in quanto si tratta di impostazioni che è possibile configurare manualmente.
Nozioni di base sul ripristino di emergenza
In questa sezione verranno illustrati le azioni e i principi di progettazione che consentono di proteggere i dati e impedire un'enorme attività di ripristino dei dati dopo piccole interruzioni o emergenze complete. Per interruzioni più piccole, seguire alcuni passaggi più piccoli può aiutare a evitare che diventino emergenze più grandi. Verranno ora illustrati alcuni termini di base che consentono di iniziare a configurare il piano di ripristino di emergenza.
Quando si progetta un piano di ripristino di emergenza, tenere presenti i tre aspetti seguenti:
- Disponibilità elevata: la distribuzione dell'infrastruttura in modo più piccolo e le interruzioni localizzate non interrompono l'intera distribuzione. La progettazione con disponibilità elevata può ridurre al minimo l'impatto sull'interruzione del servizio ed evitare la necessità di un ripristino di emergenza completo.
- Continuità aziendale: come un'organizzazione può continuare a funzionare durante le interruzioni di qualsiasi dimensione.
- Ripristino di emergenza: processo di ripristino di emergenza dopo un'interruzione completa.
Azure offre molte funzionalità predefinite e gratuite che possono offrire disponibilità elevata a molti livelli. La prima funzionalità è costituita dai set di disponibilità, che distribuiscono le macchine virtuali tra domini di errore e di aggiornamento diversi all'interno di Azure. Di seguito sono riportate le zone di disponibilità, che sono gruppi di data center fisicamente isolati e distribuiti geograficamente che possono ridurre l'impatto di un'interruzione. Infine, la distribuzione degli host di sessione in più aree di Azure offre una distribuzione ancora più geografica, riducendo ulteriormente l'impatto sull'interruzione del servizio. Tutte e tre le funzionalità offrono un certo livello di protezione all'interno di Desktop virtuale Azure ed è consigliabile valutarle attentamente insieme a eventuali implicazioni sui costi.
Fondamentalmente, la strategia di ripristino di emergenza consigliata per Desktop virtuale Azure consiste nel distribuire le risorse in più zone di disponibilità all'interno di un'area. Se è necessaria una maggiore protezione, è anche possibile distribuire le risorse in più aree di Azure abbinate.
Distribuzioni attive-passive e attive
Qualcos'altro da tenere presente è la differenza tra i piani attivi-passivi e attivi-attivi. I piani attivo-passivo sono quando si dispone di un'area con un set di risorse attivo e uno disattivato fino a quando non è necessario (passivo). Se l'area attiva viene portata offline da un'emergenza, l'organizzazione può passare all'area passiva attivandola e spostando tutti gli utenti.
Un'altra opzione è una distribuzione attiva-attiva, in cui si usano entrambi i set di infrastruttura contemporaneamente. Anche se alcuni utenti potrebbero essere interessati da interruzioni, l'impatto è limitato agli utenti dell'area che sono stati disattivati. Gli utenti dell'altra area ancora online non saranno interessati e il ripristino è limitato agli utenti dell'area interessata che si riconnettono all'area attiva funzionante. Le distribuzioni attive possono assumere molte forme, tra cui:
- Infrastruttura di overprovisioning in ogni area per supportare gli utenti interessati in caso di arresto di una delle aree. Un potenziale svantaggio di questo metodo è che la gestione delle risorse aggiuntive costa di più.
- Avere host di sessione aggiuntivi in entrambe le aree attive, ma deallocarli quando non sono necessari, riducendo così i costi.
- Effettuare il provisioning di una nuova infrastruttura durante il ripristino di emergenza e consentire agli utenti interessati di connettersi agli host di sessione di cui è stato appena effettuato il provisioning. Questo metodo richiede test regolari con strumenti di infrastruttura come codice, in modo da poter distribuire la nuova infrastruttura il più rapidamente possibile durante un'emergenza.
Metodi di ripristino di emergenza consigliati
I metodi di ripristino di emergenza consigliati sono:
Configurare e distribuire le risorse di Azure in più zone di disponibilità.
Configurare e distribuire le risorse di Azure in più aree in configurazioni attive-attive o attive-passive. Queste configurazioni sono in genere disponibili nei pool di host condivisi.
Per i pool di host personali con macchine virtuali dedicate, replicare le macchine virtuali usando Azure Site Recovery in un'altra area.
Configurare un pool di host "ripristino di emergenza" separato nell'area secondaria. Durante un'emergenza, è possibile passare gli utenti all'area secondaria.
Verranno illustrati in dettaglio i due metodi principali con cui è possibile ottenere questi metodi per i pool di host condivisi e personali nelle sezioni seguenti.
Ripristino di emergenza per i pool di host condivisi
In questa sezione verranno illustrati i pool di host condivisi (o "in pool") usando un approccio attivo-passivo. L'approccio attivo-passivo è quando si suddividono le risorse esistenti in un'area primaria e secondaria. In genere, l'organizzazione eseguirà tutto il proprio lavoro nell'area primaria (o "attiva"), ma durante un'emergenza, tutto ciò che serve per passare all'area secondaria (o "passiva") consiste nel disattivare le risorse nell'area primaria (se possibile, a seconda dell'estensione dell'interruzione) e attivare quelle nell'area secondaria.
Il diagramma seguente mostra un esempio di distribuzione con infrastruttura ridondante in un'area secondaria. "Ridondante" significa che esiste una copia dell'infrastruttura originale in questa altra area ed è standard nelle distribuzioni per fornire resilienza per tutti i componenti. Sotto un singolo ID Microsoft Entra sono presenti due aree: Stati Uniti occidentali e Stati Uniti orientali. Ogni area dispone di due host di sessione che eseguono un sistema operativo multisessione, un server che esegue Microsoft Entra Connessione, un controller di Dominio di Active Directory, una condivisione file File di Azure Premium per i profili FSLogix, un account di archiviazione e una rete virtuale (VNET). Nell'area primaria, Stati Uniti occidentali, tutte le risorse vengono attivate. Nell'area secondaria, Stati Uniti orientali, gli host di sessione nel pool di host sono disattivati o in modalità di svuotamento e il server Microsoft Entra Connessione è in modalità di gestione temporanea. Le due reti virtuali in entrambe le aree sono connesse tramite peering.
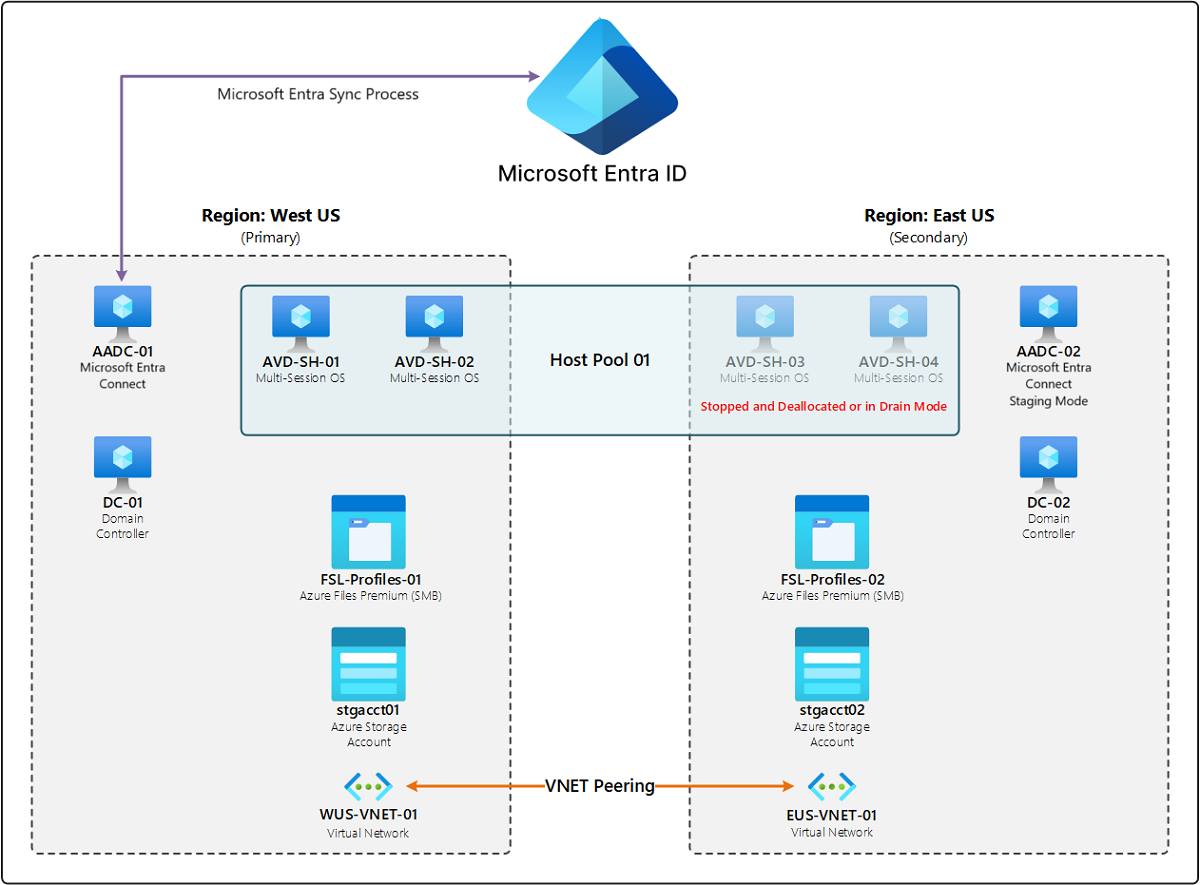
Nella maggior parte dei casi, se un componente ha esito negativo o l'area primaria non è disponibile, l'unica azione che il cliente deve eseguire consiste nell'attivare gli host o rimuovere la modalità di svuotamento nell'area secondaria per abilitare le connessioni dell'utente finale. Questo scenario è incentrato sulla riduzione dei tempi di inattività. Tuttavia, un piano di ripristino di emergenza basato sulla ridondanza può costare di più a causa della necessità di gestire tali componenti aggiuntivi nell'area secondaria.
I potenziali vantaggi di questo piano sono i seguenti:
- Meno tempo impiegato per il ripristino da emergenze. Ad esempio, si passerà meno tempo al provisioning, alla configurazione, all'integrazione e alla convalida delle risorse appena distribuite.
- Non è necessario usare procedure complesse.
- È facile testare il failover all'esterno delle emergenze.
I potenziali svantaggi sono i seguenti:
- Può costare di più a causa della disponibilità di un'infrastruttura maggiore, ad esempio account di archiviazione, host e così via.
- Sarà necessario dedicare più tempo alla configurazione della distribuzione per soddisfare questo piano.
- È necessario mantenere l'infrastruttura aggiuntiva configurata anche quando non è necessaria.
Informazioni importanti per il ripristino del pool di host condiviso
Quando si usa questa strategia di ripristino di emergenza, è importante tenere presente quanto segue:
La presenza di più host di sessione online in più aree può influire sull'esperienza utente. Il servizio di bilanciamento del carico di rete gestito non tiene conto della prossimità geografica, ma tratta tutti gli host in un pool di host allo stesso modo.
Durante un'emergenza, gli utenti creeranno nuovi profili nell'area secondaria. È consigliabile archiviare tutti i dati aziendali o cruciali in OneDrive (usando il reindirizzamento di cartelle note) o SharePoint. L'archiviazione dei dati in questo caso consentirà agli utenti di accedere rapidamente alle applicazioni con un'interruzione secondaria dell'esperienza utente.
Assicurarsi di configurare esattamente le macchine virtuali (VM) nello stesso modo all'interno del pool di host. Assicurarsi anche che tutte le macchine virtuali all'interno del pool di host siano le stesse dimensioni. Se le macchine virtuali non sono uguali, il servizio di bilanciamento del carico di rete gestito distribuirà le connessioni utente in modo uniforme in tutte le macchine virtuali disponibili. Le macchine virtuali più piccole possono diventare vincolate alle risorse prima del previsto rispetto alle macchine virtuali di dimensioni maggiori, con conseguente esperienza utente negativa.
La disponibilità dell'area influisce sul monitoraggio dei dati o dell'area di lavoro. Se un'area non è disponibile, il servizio potrebbe perdere tutti i dati di monitoraggio cronologici durante un'emergenza. È consigliabile usare un'esportazione personalizzata o un dump dei dati di monitoraggio cronologici.
È consigliabile aggiornare gli host di sessione almeno una volta ogni mese. Questa raccomandazione si applica agli host di sessione che si mantengono disattivati per lunghi periodi di tempo.
Testare la distribuzione eseguendo un failover controllato almeno una volta ogni sei mesi. Parte del failover controllato potrebbe significare che la posizione secondaria diventa primaria fino al successivo failover controllato. La modifica della posizione secondaria a quella primaria consente agli utenti di avere profili quasi identici durante un'emergenza reale.
La tabella seguente elenca le raccomandazioni per la distribuzione per le strategie di ripristino di emergenza del pool di host:
| Tecnologia | Consigli |
|---|---|
| Rete | Creare e distribuire una rete virtuale secondaria in un'altra area e configurare il peering di Azure con la rete virtuale primaria. |
| Host di sessione | Creare e distribuire un pool di host condivisi di Desktop virtuale Azure con SKU del sistema operativo multisessione e includere macchine virtuali di altre zone di disponibilità e un'altra area. |
| Storage | Creare account di archiviazione in più aree usando account di livello Premium. |
| Dati del profilo utente | Creare posizioni di archiviazione SMB in più aree. |
| Identità | Dominio di Active Directory Controller dalla stessa directory. |
Ripristino di emergenza per i pool di host personali
Per i pool di host personali, la strategia di ripristino di emergenza deve comportare la replica delle risorse in un'area secondaria usando Azure Site Recovery Services Vault. Se l'area primaria si arresta durante un'emergenza, Azure Site Recovery può eseguire il failover e attivare le risorse nell'area secondaria.
Si supponga, ad esempio, di avere una distribuzione con un'area primaria negli Stati Uniti occidentali e un'area secondaria negli Stati Uniti orientali. L'area primaria ha un pool di host personale con due host di sessione ciascuno. Ogni host di sessione ha il proprio disco locale contenente i dati del profilo utente e la propria rete virtuale che non è associata a nulla. In caso di emergenza, è possibile usare Azure Site Recovery per eseguire il failover nell'area secondaria negli Stati Uniti orientali (o in una zona di disponibilità diversa nella stessa area). A differenza dell'area primaria, l'area secondaria non dispone di computer o dischi locali. Durante il failover, Azure Site Recovery accetta i dati replicati dall'insieme di credenziali di Azure Site Recovery e li usa per creare due nuove macchine virtuali che sono copie degli host di sessione originali, inclusi i dati del disco locale e del profilo utente. L'area secondaria ha una propria rete virtuale indipendente, quindi la rete virtuale in uscita nell'area primaria non influirà sulle funzionalità.
Il diagramma seguente illustra la distribuzione di esempio appena descritta.
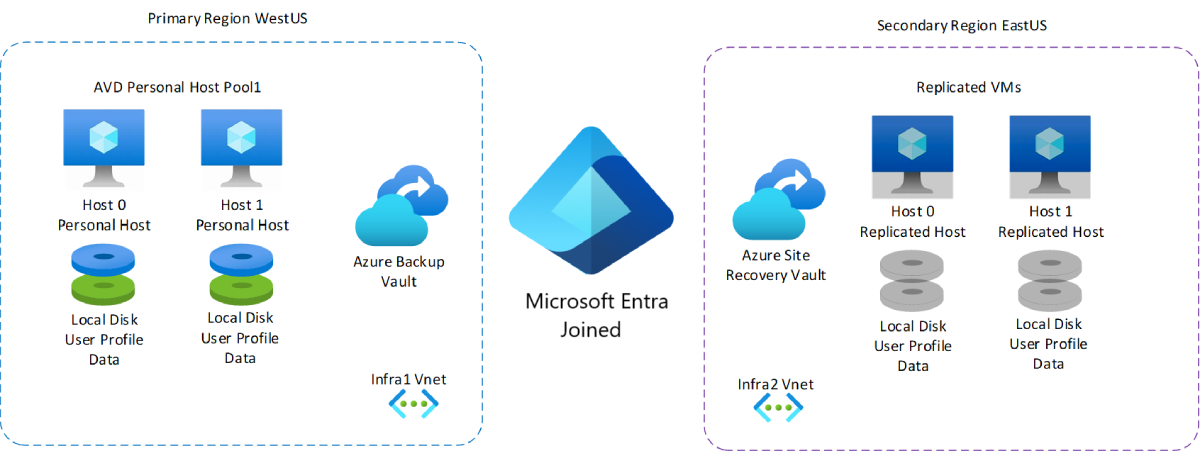
I vantaggi di questo piano includono un costo complessivo inferiore e non richiedono la manutenzione per applicare patch o aggiornare a causa del provisioning delle risorse solo quando sono necessarie. Tuttavia, un potenziale svantaggio è che si spenderà più tempo per il provisioning, l'integrazione e la convalida dell'infrastruttura di failover rispetto a una configurazione di ripristino di emergenza del pool di host condiviso.
Informazioni importanti sul ripristino del pool di host personali
Quando si usa questa strategia di ripristino di emergenza, è importante tenere presente quanto segue:
Potrebbe essere necessario che le macchine virtuali del pool di host funzionino nel sito secondario, ad esempio reti virtuali, subnet, sicurezza di rete o VPN per accedere a una directory, ad esempio Active Directory locale.
Nota
L'uso di una macchina virtuale aggiunta a Microsoft Entra soddisfa automaticamente alcuni di questi requisiti.
È possibile che si verifichino problemi di integrazione, prestazioni o contesa per le risorse se un'emergenza su larga scala interessa più clienti o tenant.
I pool di host personali usano macchine virtuali dedicate a un utente, il che significa che le regole di bilanciamento del carico di affinità indirizzano tutte le sessioni utente a una macchina virtuale specifica. Questo mapping uno-a-uno tra l'utente e la macchina virtuale significa che se una macchina virtuale è inattiva, l'utente non sarà in grado di accedere fino a quando la macchina virtuale non torna online o la macchina virtuale viene ripristinata al termine del ripristino di emergenza.
Le macchine virtuali in un profilo utente dell'archivio pool di host personali nell'unità C, il che significa che FSLogix non è obbligatorio.
La disponibilità dell'area influisce sul monitoraggio dei dati o dell'area di lavoro. Se un'area non è disponibile, il servizio potrebbe perdere tutti i dati di monitoraggio cronologici durante un'emergenza. È consigliabile usare un'esportazione personalizzata o un dump dei dati di monitoraggio cronologici.
È consigliabile evitare di usare FSLogix quando si usa una configurazione del pool di host personale.
Il provisioning delle macchine virtuali non è garantito nell'area di failover.
Eseguire test di failover e failback controllati almeno una volta ogni sei mesi.
La tabella seguente elenca le raccomandazioni per la distribuzione per le strategie di ripristino di emergenza del pool di host:
| Tecnologia | Consigli |
|---|---|
| Rete | Creare e distribuire una rete virtuale secondaria in un'altra area per seguire convenzioni di denominazione personalizzate o requisiti di sicurezza all'esterno dello schema di denominazione predefinito di Azure Site Recovery. |
| Host di sessione | Abilitare e configurare Azure Site Recovery per le macchine virtuali. Facoltativamente, è possibile pre-preparare un'immagine manualmente o usare il servizio Azure Image Builder per il provisioning continuo. |
| Storage | La creazione di un account Archiviazione di Azure è facoltativa per archiviare i profili. |
| Dati del profilo utente | I dati del profilo utente vengono archiviati localmente nell'unità C. |
| Identità | Dominio di Active Directory Controller dalla stessa directory in più aree. |
Passaggi successivi
Per informazioni più approfondite sul ripristino di emergenza in Azure, vedere gli articoli seguenti: