Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: ✔️ macchine virtuali di Linux
Azure è la casa di tutti i carichi di lavoro Oracle, inclusi i carichi di lavoro che devono continuare a essere eseguiti in modo ottimale in Azure con Oracle. Se si dispone di Oracle Diagnostic Pack o del repository automatico del carico di lavoro, è possibile raccogliere dati sui carichi di lavoro. Usare questi dati per valutare il carico di lavoro Oracle, ridimensionare le esigenze delle risorse ed eseguire la migrazione del carico di lavoro in Azure. Le varie metriche fornite da Oracle in questi report possono fornire informazioni sulle prestazioni dell'applicazione e sull'utilizzo della piattaforma.
Questo articolo illustra come preparare un carico di lavoro Oracle da eseguire in Azure ed esplorare le migliori soluzioni di architettura per offrire prestazioni cloud ottimali. I dati forniti da Oracle in Statspack e ancora di più nel relativo discendente, AWR, aiutano a sviluppare aspettative chiare. Queste aspettative includono i limiti dell'ottimizzazione fisica tramite l'architettura, i vantaggi dell'ottimizzazione logica del codice del database e la progettazione complessiva del database.
Differenze tra i due ambienti
Quando si esegue la migrazione di applicazioni locali ad Azure, tenere presenti alcune importanti differenze tra i due ambienti.
Una differenza importante è che in un'implementazione in Azure le risorse, ad esempio VM, dischi e reti virtuali, vengono condivise con gli altri client. Le risorse possono anche essere limitate in base ai requisiti. Invece di concentrarsi sull'evitare errori, Azure si concentra maggiormente sulla sopravvivenza dell'errore. Il primo approccio tenta di aumentare il tempo medio tra errori (MTBF) e il secondo tenta di ridurre il tempo medio per il ripristino (MTTR).
La tabella seguente elenca alcune differenze tra un'implementazione locale e un'implementazione in Azure di un database Oracle.
| Implementazione locale | Implementazione in Azure | |
|---|---|---|
| Networking | LAN/WAN | Software-Defined Networking (SDN) |
| Gruppo di sicurezza | Strumenti di restrizione per indirizzi IP/porte | Gruppo di sicurezza di rete |
| Resilienza | MTBF | Tempo medio di ripristino |
| Manutenzione pianificata | Applicazione di patch/aggiornamenti | Set di disponibilità con patch/aggiornamenti gestiti da Azure |
| Conto risorse | Dedicato | Condivisa con altri client |
| Aree geografiche | Data center | Coppie di aree |
| Storage | Dischi fisici/SAN | Archiviazione gestita da Azure |
| Ridimensiona | Scalabilità verticale | Scalabilità orizzontale |
Requisiti
Prima di avviare la migrazione, considerare i requisiti seguenti:
- Determinare l'utilizzo effettivo della CPU. Le licenze Oracle per core, il che significa che il ridimensionamento delle esigenze di vCPU può essere essenziale per ridurre i costi.
- Determinare le dimensioni del database, l'archiviazione di backup e il tasso di crescita.
- Determinare i requisiti di I/O, che è possibile stimare in base a Oracle Statspack e ai report AWR. È anche possibile stimare i requisiti degli strumenti di monitoraggio dell'archiviazione disponibili nel sistema operativo.
Opzioni di configurazione
È consigliabile generare un report AWR e ottenere alcune metriche da esso per prendere decisioni sulla configurazione. Esistono quattro potenziali aree che è possibile ottimizzare per migliorare le prestazioni in un ambiente Azure:
- Dimensioni della macchina virtuale
- Velocità effettiva della rete
- Tipi di disco e configurazioni
- Impostazioni della cache su disco
Generare un report AWR
Se si dispone di un database Oracle Enterprise Edition e si prevede di eseguire la migrazione ad Azure, sono disponibili diverse opzioni. Se si dispone del Diagnostics Pack per le istanze Oracle, è possibile eseguire il report Oracle AWR per ottenere le metriche, ad esempio IOPS, Mbps e GiBs. Per questi database senza la licenza Diagnostics Pack o per un database Oracle Standard Edition, è possibile raccogliere le stesse metriche importanti con un report Statspack dopo aver raccolto snapshot manuali. Le principali differenze tra questi due metodi di report sono che AWR viene raccolto automaticamente e che fornisce più informazioni sul database rispetto a Statspack.
Valutare se eseguire il report AWR durante i carichi di lavoro sia normali che di picco, per poter effettuare un confronto. Per raccogliere il carico di lavoro più accurato, prendere in considerazione un report di finestra estesa di una settimana, anziché un giorno. AWR fornisce medie come parte dei relativi calcoli nel report. Per impostazione predefinita, il repository AWR mantiene otto giorni di dati e acquisisce snapshot a intervalli orari.
Per una migrazione del data center, è necessario raccogliere report per il ridimensionamento nei sistemi di produzione. Stimare le copie rimanenti del database usate per test, test e sviluppo degli utenti in base alle percentuali. Ad esempio, stimare il 50% delle dimensioni di produzione.
Per eseguire un report AWR dalla riga di comando, usare il comando seguente:
sqlplus / as sysdba
@$ORACLE_HOME/rdbms/admin/awrrpt.sql;
Metrica chiave
Il report richiede le informazioni seguenti:
- Tipo di report: HTML o TEXT. Il tipo HTML fornisce altre informazioni.
- Numero di giorni di snapshot da visualizzare. Ad esempio, per intervalli di un'ora, un report di una settimana genera 168 ID snapshot.
SnapshotIDiniziale per la finestra del report.SnapshotIDfinale per la finestra del report.- Nome del report creato dallo script AWR.
Se si esegue il report AWR in un cluster applicazione reale, il report della riga di comando è il file awrgrpt.sql anziché awrrpt.sql. Il report g crea un report per tutti i nodi del database RAC in un singolo report. Questo report elimina la necessità di eseguire un report in ogni nodo RAC.
È possibile ottenere le metriche seguenti dal report AWR:
- Nome del database, nome istanza e nome host
- Versione del database per supportare Oracle
- Core CPU
- SGA/PGA e consulenti per comunicare se sottodimensionati
- Memoria totale in GB
- Percentuale della CPU occupata
- CPU del database
- Operazioni di I/O al secondo (lettura/scrittura)
- MBP (lettura/scrittura)
- Velocità effettiva della rete
- Latenza di rete (bassa/alta)
- Eventi di attesa più frequenti
- Impostazioni dei parametri per il database
- Che il database sia RAC, Exadata o che usi funzionalità o configurazioni avanzate
Dimensioni della macchina virtuale
Ecco alcuni passaggi che è possibile eseguire per configurare le dimensioni della macchina virtuale per ottenere prestazioni ottimali.
Stimare le dimensioni della macchina virtuale in base a utilizzo di CPU, memoria e I/O dal report AWR
Esaminare i primi cinque eventi in primo piano che indicano dove si trovano i colli di bottiglia del sistema. Nel diagramma seguente, ad esempio, la sincronizzazione dei file di log è all'inizio. Indica il numero di attese necessarie prima che il writer di log scriva il buffer di log nel file di log di rollforward. Questi risultati indicano che è necessario migliorare le prestazioni della risorsa di archiviazione o dei dischi. Il diagramma indica anche il numero di CPU (core) e la quantità di memoria.
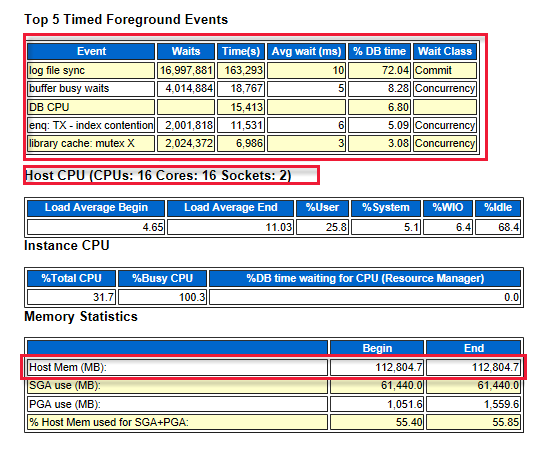 Screenshot che mostra la sincronizzazione dei file di log nella parte superiore della tabella.
Screenshot che mostra la sincronizzazione dei file di log nella parte superiore della tabella.
Il diagramma seguente mostra l'I/O totale di lettura e scrittura. Sono stati registrati 59 GB in lettura e 247,3 GB in scrittura durante il periodo di esecuzione del report.
 Screenshot che mostra l'I/O totale di lettura e scrittura.
Screenshot che mostra l'I/O totale di lettura e scrittura.
Scegliere una VM
In base alle informazioni raccolte dal report AWR, il passaggio successivo è scegliere una macchina virtuale di dimensioni simili che soddisfi i requisiti. Per altre informazioni sulle macchine virtuali disponibili, vedere dimensioni delle macchine virtuali ottimizzate per la memoria.
Ottimizzare il dimensionamento delle macchine virtuali con una serie di macchine virtuali simili basate sull'ACU
Dopo aver scelto la macchina virtuale, prestare attenzione all'unità di calcolo di Azure per la macchina virtuale. In base al valore ACU, è possibile scegliere una macchina virtuale diversa più adatta agli specifici requisiti. Per altre informazioni, vedere Unità di calcolo di Azure.
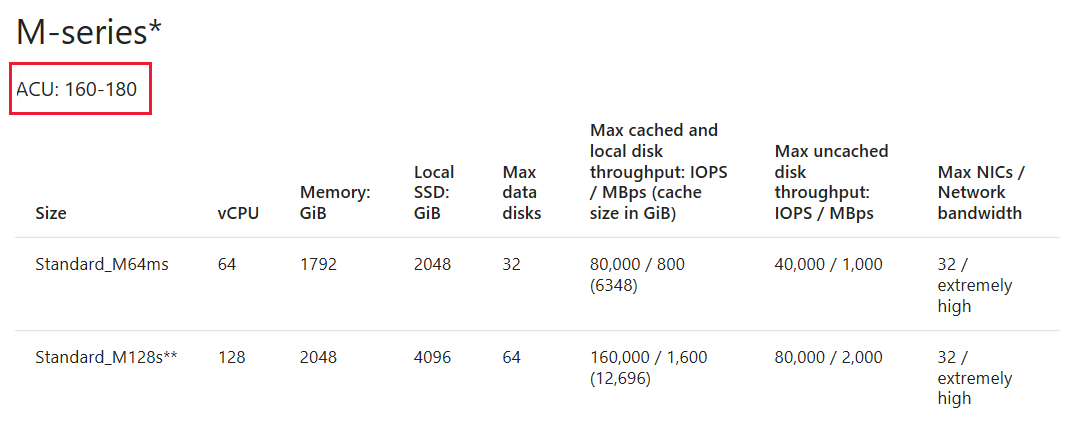 Screenshot della pagina unità ACU.
Screenshot della pagina unità ACU.
Velocità effettiva della rete
Come illustra il diagramma seguente, esiste una relazione tra velocità effettiva e IOPS:
 Diagramma che mostra la relazione tra velocità effettiva e operazioni di I/O al secondo, ovvero le dimensioni di I/O al secondo pari alla velocità effettiva.
Diagramma che mostra la relazione tra velocità effettiva e operazioni di I/O al secondo, ovvero le dimensioni di I/O al secondo pari alla velocità effettiva.
La velocità effettiva totale della rete viene stimata in base alle informazioni seguenti:
- Traffico SQL*Net
- MBps volte il numero di server (flusso in uscita, ad esempio Oracle Data Guard)
- Altri fattori, ad esempio la replica dell'applicazione
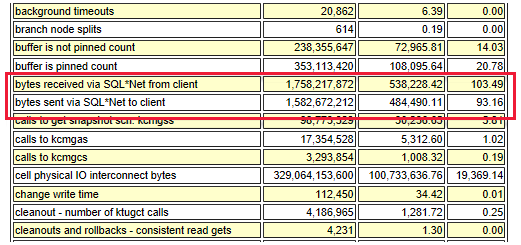 Screenshot della velocità effettiva SQL*Net.
Screenshot della velocità effettiva SQL*Net.
In base ai requisiti di larghezza di banda della rete, sono disponibili diversi tipi di gateway tra cui scegliere, Questi tipi includono Basic, VpnGw e Azure ExpressRoute. Per altre informazioni, vedere Prezzi di Gateway VPN.
Consigli
- La latenza di rete è superiore rispetto a una distribuzione locale. La riduzione dei round trip di rete può migliorare notevolmente le prestazioni.
- Per ridurre i round trip, consolidare le applicazioni con transazioni elevate o con un livello di comunicazioni elevato nella stessa macchina virtuale.
- Usare le macchine virtuali con rete accelerata per migliorare le prestazioni di rete.
- Per determinate distribuzioni Linux, è consigliabile abilitare il supporto TRIM/UNMAP.
- Installare Oracle Enterprise Manager in una macchina virtuale separata.
- Per impostazione predefinita, le pagine di grandi dimensioni non sono abilitate in Linux. Valutare la possibilità di abilitare grandi pagine e impostare
use_large_pages = ONLYnel database Oracle. Questo approccio potrebbe contribuire a migliorare le prestazioni. Per altre informazioni, vedere USE_LARGE_PAGES.
Tipi di disco e configurazioni
Ecco alcuni suggerimenti quando si considerano i dischi.
Dischi del sistema operativo predefiniti: questi tipi di dischi offrono dati persistenti e memorizzazione nella cache. Sono ottimizzati per l'accesso al sistema operativo all'avvio e non sono progettati per carichi di lavoro transazionali o di data warehouse (analitici).
Dischi gestiti: Azure gestisce gli account di archiviazione usati per i dischi delle macchine virtuali. Specificare il tipo di disco e le dimensioni del disco necessario. Il tipo è più spesso Premium (SSD) per i carichi di lavoro Oracle. Azure crea e gestisce il disco automaticamente. Un disco gestito da SSD Premium è disponibile solo per le serie di macchine virtuali ottimizzate per la memoria e progettate. Dopo avere scelto determinate dimensioni per la VM, il menu mostra solo gli SKU di Archiviazione Premium disponibili in base a tali dimensioni della VM.
 Screenshot della pagina del disco gestito.
Screenshot della pagina del disco gestito.Dopo avere configurato la risorsa di archiviazione in una macchina virtuale, è possibile sottoporre i dischi a test di carico prima di creare un database. Conoscendo la velocità di I/O in termini di latenza e velocità effettiva, è possibile determinare se le macchine virtuali supportano la velocità effettiva prevista con gli obiettivi di latenza. Sono disponibili numerosi strumenti per il test di carico delle applicazioni, ad esempio Oracle Orion, SLOB, Sysbench e Fio.
Dopo avere distribuito un database Oracle, eseguire nuovamente il test di carico. Avviare i carico di lavoro normali e di picco. I risultati indicheranno la baseline dell'ambiente. Essere realistici nel test del carico di lavoro. Non ha senso eseguire un carico di lavoro che non è simile a quello eseguito nella macchina virtuale in realtà.
Poiché Oracle può essere un database a elevato utilizzo di I/O, è importante ridimensionare l'archiviazione in base alla velocità di I/O al secondo anziché alle dimensioni di archiviazione. Se ad esempio le operazioni di I/O al secondo necessarie sono 5.000, ma servono solo 200 GB, si potrebbe comunque scegliere il disco Premium classe P30 anche se ha più di 200 GB di spazio di archiviazione.
È possibile ottenere la frequenza delle operazioni di I/O al secondo dal report AWR. Il log di rollforward, le letture fisiche e la frequenza di scrittura determinano la frequenza di operazioni di I/O al secondo. Verificare sempre che la serie di macchine virtuali scelta abbia la possibilità di gestire la richiesta di I/O del carico di lavoro. Se la macchina virtuale ha un limite di I/O inferiore rispetto all'archiviazione, la macchina virtuale imposta il limite massimo.
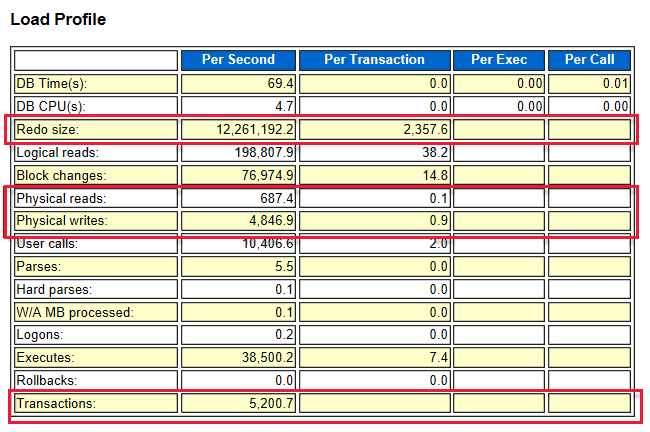 Screenshot della pagina del report AWR.
Screenshot della pagina del report AWR.
Ad esempio: la dimensione di rollforward è 12.200.000 byte al secondo, equivalente a 11,63 Mbps. Il valore di operazioni di I/O al secondo è 12.200.000 / 2.358 = 5.174.
Dopo avere ottenuto un quadro preciso dei requisiti di I/O, è possibile scegliere la combinazione delle unità più adatte per soddisfare tali requisiti.
Consigli sul tipo di disco
- Per lo spazio tabelle dati, distribuire il carico di lavoro di I/O tra più dischi usando l'archiviazione gestita o Oracle Automatic Storage Management (ASM).
- Usare la compressione avanzata Oracle per ridurre l'I/O per i dati e gli indici.
- Separare log di rollforward, temp e spazi di tabella di annullamento in dischi dati separati.
- Non inserire file dell'applicazione nei dischi predefiniti del sistema operativo. Questi dischi non sono ottimizzati per l'avvio rapido delle macchine virtuali e potrebbero non offrire prestazioni valide per l'applicazione.
- Quando si usano macchine virtuali serie M nell'archiviazione Premium, abilitare acceleratore di scrittura sul disco dei log di rollforward.
- Prendere in considerazione lo spostamento dei log di rollforward con una latenza elevata nel disco Ultra.
Impostazioni della cache su disco
Sebbene siano disponibili tre opzioni per la memorizzazione nella cache dell'host, è consigliabile usare solo la memorizzazione nella cache di sola lettura per un carico di lavoro del database in un database Oracle. La lettura/scrittura può introdurre vulnerabilità significative a un file di dati, perché l'obiettivo di una scrittura di database è registrarlo nel file di dati, non memorizzare nella cache le informazioni. Con sola lettura, tutte le richieste vengono memorizzate nella cache per letture future. Tutte le scritture continuano a essere scritte su disco.
Consigli relativi alla cache dei dischi
Per ottimizzare la velocità effettiva, iniziare con sola lettura per la memorizzazione nella cache dell'host quando possibile. Per l'archiviazione Premium, tenere presente che è necessario disabilitare le barriere quando si monta il file system con le opzioni di sola lettura. Aggiornare il file /etc/fstab con l'identificatore univoco universale ai dischi.
 Screenshot della pagina del disco gestito che mostra l'opzione di sola lettura.
Screenshot della pagina del disco gestito che mostra l'opzione di sola lettura.
- Per i dischi del sistema operativo, usare SSD Premium con memorizzazione nella cache dell'host di lettura/scrittura.
- Per i dischi dati che contengono quanto segue, usare SSD Premium con memorizzazione nella cache host di sola lettura: file di dati Oracle, file temporanei, file di controllo, blocco file di rilevamento delle modifiche, BFILEs, file per tabelle esterne e log di flashback.
- Per i dischi dati che contengono file di log di rollforward online Oracle, usare SSD Premium o UltraDisk senza memorizzazione nella cache dell'host, l'opzione Nessuno. I file di log di rollforward Oracle archiviati e i set di backup di Oracle Recovery Manager possono risiedere anche con i file di log di rollforward online. La memorizzazione nella cache dell'host è limitata a 4.095 GiB, quindi non allocare un'unità SSD Premium superiore a P50 con memorizzazione nella cache dell'host. Se sono necessari più di 4 TiB di archiviazione, eseguire lo striping di diverse unità SSD Premium con RAID-0. Usare Linux LVM2 o Oracle Automatic Storage Management.
Se i carichi di lavoro variano notevolmente tra il giorno e la sera e il carico di lavoro di I/O può supportarlo, l'unità SSD Premium P1-P20 con bursting potrebbe offrire le prestazioni necessarie durante i carichi batch notturni o richieste di I/O limitate.
Sicurezza
Dopo aver configurato e configurato l'ambiente Azure, è necessario proteggere la rete. Di seguito sono elencati alcuni suggerimenti:
Criterio del gruppo di sicurezza di rete: è possibile definire il gruppo di sicurezza di rete in base a una subnet o a una scheda di interfaccia di rete. È più semplice controllare l'accesso a livello di subnet, sia per la sicurezza che per i firewall delle applicazioni di routing forzato.
Jumpbox: per un accesso più sicuro, gli amministratori non devono connettersi direttamente al servizio o al database dell'applicazione. Usare un jumpbox tra il computer amministratore e le risorse di Azure.
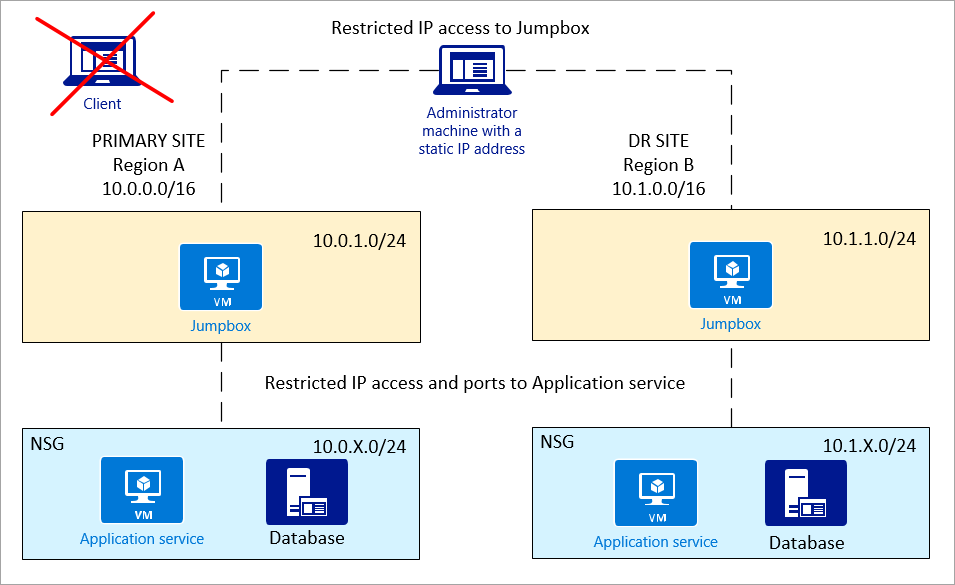 Diagramma che mostra la topologia jumpbox.
Diagramma che mostra la topologia jumpbox.
Il computer amministratore deve offrire solo l'accesso con restrizioni IP al jumpbox. Il jumpbox deve avere accesso all'applicazione e al database.
Rete privata (subnet): è consigliabile avere il servizio applicazione e il database in subnet separate, in modo che i criteri del gruppo di sicurezza di rete possano impostare un controllo migliore.
 Diagramma che mostra la topologia jumpbox.
Diagramma che mostra la topologia jumpbox.Risorse
- Configurare Oracle ASM
- Configurare Oracle Data Guard
- Configurare Oracle GoldenGate
- Backup e ripristino di Oracle