Disponibilità elevata di SAP HANA con scalabilità orizzontale con Azure NetApp Files in RHEL
Questo articolo descrive come configurare la replica di sistema SAP HANA nella distribuzione con scalabilità orizzontale, quando i file system HANA vengono montati tramite NFS usando Azure NetApp Files. Nelle configurazioni di esempio e nei comandi di installazione vengono usati il numero di istanza 03 e l'ID di sistema HANA HN1 . La replica di sistema SAP HANA è costituita da un nodo primario e da almeno un nodo secondario.
Quando i passaggi in questo documento sono contrassegnati con i prefissi seguenti, il significato è il seguente:
- [A]: il passaggio si applica a tutti i nodi
- [1]: il passaggio si applica solo a node1
- [2]: il passaggio si applica solo a node2
Prerequisiti
Leggere prima di tutto i documenti e le note SAP seguenti:
- Nota SAP 1928533, che include:
- Elenco delle dimensioni delle macchine virtuali di Azure supportate per la distribuzione del software SAP.
- Informazioni importanti sulla capacità per le dimensioni delle macchine virtuali di Azure.
- Combinazioni di database e software SAP e sistema operativo supportati.
- Versione del kernel SAP richiesta per Windows e Linux in Microsoft Azure.
- La nota SAP 2015553 elenca i prerequisiti per le distribuzioni di software SAP supportate da SAP in Azure.
- Nota SAP 405827 elenca i file system consigliati per gli ambienti HANA.
- Nota SAP 2002167 ha le impostazioni del sistema operativo consigliate per Red Hat Enterprise Linux.
- Nota SAP 2009879 include le linee guida di SAP HANA per Red Hat Enterprise Linux.
- Nota SAP 3108302 include le linee guida di SAP HANA per Red Hat Enterprise Linux 9.x.
- La nota SAP 2178632 contiene informazioni dettagliate su tutte le metriche di monitoraggio segnalate per SAP in Azure.
- La nota SAP 2191498 contiene la versione dell'agente host SAP per Linux necessaria in Azure.
- La nota SAP 2243692 contiene informazioni sulle licenze SAP in Linux in Azure.
- Nota SAP 1999351 contiene altre informazioni sulla risoluzione dei problemi per l'estensione di monitoraggio avanzato di Azure per SAP.
- Sap Community Wiki include tutte le note SAP necessarie per Linux.
- Pianificazione e implementazione di Macchine virtuali di Azure per SAP in Linux
- Distribuzione di Macchine virtuali di Azure per SAP in Linux
- Distribuzione DBMS di Macchine virtuali di Azure per SAP in Linux
- Replica di sistema SAP HANA nel cluster Pacemaker
- Documentazione generale di Red Hat Enterprise Linux (RHEL):
- High Availability Add-On Overview (Panoramica dei componenti aggiuntivi a disponibilità elevata)
- High Availability Add-On Administration (Amministrazione dei componenti aggiuntivi a disponibilità elevata)
- High Availability Add-On Reference (Riferimento dei componenti aggiuntivi a disponibilità elevata)
- Configurare la replica di sistema SAP HANA in scale-up in un cluster Pacemaker quando i file system HANA si trovano in condivisioni NFS
- Documentazione di RHEL specifica di Azure:
- Support Policies for RHEL High Availability Clusters - Microsoft Azure Virtual Machines as Cluster Members (Criteri di supporto per cluster RHEL a disponibilità elevata - Macchine virtuali di Microsoft Azure come membri del cluster)
- Installing and Configuring a Red Hat Enterprise Linux 7.4 (and later) High-Availability Cluster on Microsoft Azure (Installazione e configurazione di un cluster Red Hat Enterprise Linux 7.4 e versioni successive a disponibilità elevata in Microsoft Azure)
- Configurare la replica di sistema con scalabilità orizzontale di SAP HANA in un cluster Pacemaker quando i file system HANA si trovano in condivisioni NFS
- Volumi NFS v4.1 in Azure NetApp Files per SAP HANA
Panoramica
Tradizionalmente in un ambiente con scalabilità orizzontale, tutti i file system per SAP HANA vengono montati dall'archiviazione locale. La configurazione della disponibilità elevata della replica di sistema SAP HANA in Red Hat Enterprise Linux è pubblicata in Configurare la replica di sistema SAP HANA in RHEL.
Per ottenere la disponibilità elevata di SAP HANA di un sistema di scalabilità orizzontale nelle condivisioni NFS di Azure NetApp Files , è necessaria una configurazione delle risorse nel cluster per consentire il ripristino delle risorse HANA, quando un nodo perde l'accesso alle condivisioni NFS in Azure NetApp Files. Il cluster gestisce i montaggi NFS, consentendo di monitorare l'integrità delle risorse. Vengono applicate le dipendenze tra i montaggi del file system e le risorse SAP HANA.
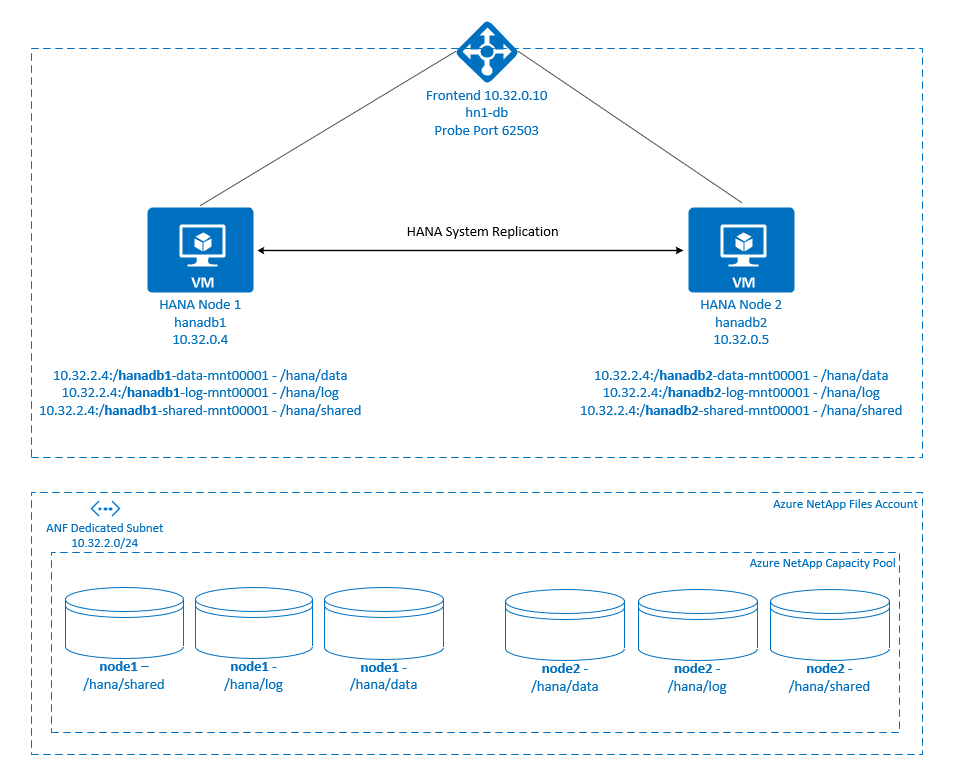 .
.
I file system SAP HANA vengono montati in condivisioni NFS usando Azure NetApp Files in ogni nodo. I file system /hana/data, /hana/loge /hana/shared sono univoci per ogni nodo.
Montato in node1 (hanadb1):
- 10.32.2.4:/hanadb1-data-mnt00001 in /hana/data
- 10.32.2.4:/hanadb1-log-mnt00001 in /hana/log
- 10.32.2.4:/hanadb1-shared-mnt00001 in /hana/shared
Montato su node2 (hanadb2):
- 10.32.2.4:/hanadb2-data-mnt00001 su /hana/data
- 10.32.2.4:/hanadb2-log-mnt00001 in /hana/log
- 10.32.2.4:/hanadb2-shared-mnt00001 su /hana/shared
Nota
I file system /hana/shared, /hana/datae /hana/log non vengono condivisi tra i due nodi. Ogni nodo del cluster ha un proprio file system separato.
La configurazione della replica di sistema SAP HANA usa un nome host virtuale dedicato e indirizzi IP virtuali. In Azure è necessario un servizio di bilanciamento del carico per usare un indirizzo IP virtuale. La configurazione illustrata di seguito include un servizio di bilanciamento del carico con:
- Indirizzo IP front-end: 10.32.0.10 per hn1-db
- Porta probe: 62503
Configurare l'infrastruttura di Azure NetApp Files
Prima di procedere con la configurazione per l'infrastruttura di Azure NetApp Files, acquisire familiarità con la documentazione di Azure NetApp Files.
Azure NetApp Files è disponibile in diverse aree di Azure. Verificare se l'area di Azure selezionata offre Azure NetApp Files.
Per informazioni sulla disponibilità di Azure NetApp Files per area di Azure, vedere Disponibilità di Azure NetApp Files in base all'area di Azure.
Considerazioni importanti
Durante la creazione dei volumi di Azure NetApp Files per i sistemi con scalabilità orizzontale DI SAP HANA, tenere presenti le considerazioni importanti documentate nei volumi NFS v4.1 in Azure NetApp Files per SAP HANA.
Ridimensionamento del database HANA in Azure NetApp Files
La velocità effettiva di un volume di Azure NetApp Files è una funzione delle dimensioni del volume e del livello di servizio, come documentato in Livello di servizio per Azure NetApp Files.
Durante la progettazione dell'infrastruttura per SAP HANA in Azure con Azure NetApp Files, tenere presente le raccomandazioni nei volumi NFS v4.1 in Azure NetApp Files per SAP HANA.
La configurazione in questo articolo viene presentata con semplici volumi di Azure NetApp Files.
Importante
Per i sistemi di produzione, dove le prestazioni sono fondamentali, è consigliabile valutare e prendere in considerazione l'uso del gruppo di volumi di applicazioni di Azure NetApp Files per SAP HANA.
Distribuire le risorse di Azure NetApp Files
Le istruzioni seguenti presuppongono che la rete virtuale di Azure sia già stata distribuita. Le risorse e le macchine virtuali di Azure NetApp Files, in cui verranno montate le risorse di Azure NetApp Files, devono essere distribuite nella stessa rete virtuale di Azure o nelle reti virtuali di Azure con peering.
Creare un account NetApp nell'area di Azure selezionata seguendo le istruzioni in Creare un account NetApp.
Configurare un pool di capacità di Azure NetApp Files seguendo le istruzioni riportate in Configurare un pool di capacità di Azure NetApp Files.
L'architettura HANA illustrata in questo articolo usa un singolo pool di capacità di Azure NetApp Files a livello di servizio Ultra . Per i carichi di lavoro HANA in Azure, è consigliabile usare un livello di servizio Ultra o Premiumdi Azure NetApp Files.
Delegare una subnet ad Azure NetApp Files, come descritto nelle istruzioni riportate in Delegare una subnet ad Azure NetApp Files.
Distribuire volumi di Azure NetApp Files seguendo le istruzioni riportate in Creare un volume NFS per Azure NetApp Files.
Durante la distribuzione dei volumi, assicurarsi di selezionare la versione NFSv4.1. Distribuire i volumi nella subnet di Azure NetApp Files designata. Gli indirizzi IP dei volumi di Azure NetApp vengono assegnati automaticamente.
Tenere presente che le risorse di Azure NetApp Files e le macchine virtuali di Azure devono trovarsi nella stessa rete virtuale di Azure o nelle reti virtuali di Azure con peering. Ad esempio,
hanadb1-data-mnt00001ehanadb1-log-mnt00001sono i nomi di volume enfs://10.32.2.4/hanadb1-data-mnt00001sononfs://10.32.2.4/hanadb1-log-mnt00001i percorsi di file per i volumi di Azure NetApp Files.In hanadb1:
- Volume hanadb1-data-mnt00001 (nfs://10.32.2.4:/hanadb1-data-mnt00001)
- Volume hanadb1-log-mnt00001 (nfs://10.32.2.4:/hanadb1-log-mnt00001)
- Volume hanadb1-shared-mnt00001 (nfs://10.32.2.4:/hanadb1-shared-mnt00001)
In hanadb2:
- Volume hanadb2-data-mnt00001 (nfs://10.32.2.4:/hanadb2-data-mnt00001)
- Volume hanadb2-log-mnt00001 (nfs://10.32.2.4:/hanadb2-log-mnt00001)
- Volume hanadb2-shared-mnt00001 (nfs://10.32.2.4:/hanadb2-shared-mnt00001)
Nota
Tutti i comandi da montare /hana/shared in questo articolo vengono presentati per i volumi NFSv4.1 /hana/shared .
Se i /hana/shared volumi sono stati distribuiti come volumi NFSv3, non dimenticare di modificare i comandi di montaggio per /hana/shared NFSv3.
Preparare l'infrastruttura
Azure Marketplace contiene immagini qualificate per SAP HANA con il componente aggiuntivo a disponibilità elevata, che è possibile usare per distribuire nuove macchine virtuali usando diverse versioni di Red Hat.
Distribuire manualmente le macchine virtuali Linux tramite il portale di Azure
Questo documento presuppone che sia già stato distribuito un gruppo di risorse, una rete virtuale di Azure e una subnet.
Distribuire macchine virtuali per SAP HANA. Scegliere un'immagine RHEL appropriata supportata per il sistema HANA. È possibile distribuire una macchina virtuale in una delle opzioni di disponibilità: set di scalabilità di macchine virtuali, zona di disponibilità o set di disponibilità.
Importante
Assicurarsi che il sistema operativo selezionato sia certificato SAP per SAP HANA nei tipi di macchina virtuale specifici che si prevede di usare nella distribuzione. È possibile cercare i tipi di VM certificati SAP HANA e le relative versioni del sistema operativo in SAP HANA Certified IaaS Platforms. Assicurarsi di esaminare i dettagli del tipo di macchina virtuale per ottenere l'elenco completo delle versioni del sistema operativo supportate da SAP HANA per il tipo di macchina virtuale specifico.
Configurare il servizio di bilanciamento del carico di Azure
Durante la configurazione della macchina virtuale, è possibile creare o selezionare l'uscita dal servizio di bilanciamento del carico nella sezione Rete. Seguire questa procedura per configurare il servizio di bilanciamento del carico standard per la configurazione a disponibilità elevata del database HANA.
Seguire la guida alla creazione del servizio di bilanciamento del carico per configurare un servizio di bilanciamento del carico standard per un sistema SAP a disponibilità elevata usando il portale di Azure. Durante la configurazione del servizio di bilanciamento del carico, prendere in considerazione i punti seguenti.
- Configurazione IP front-end: creare un indirizzo IP front-end. Selezionare la stessa rete virtuale e la stessa subnet delle macchine virtuali del database.
- Pool back-end: creare un pool back-end e aggiungere macchine virtuali del database.
- Regole in ingresso: creare una regola di bilanciamento del carico. Seguire la stessa procedura per entrambe le regole di bilanciamento del carico.
- Indirizzo IP front-end: selezionare ip front-end
- Pool back-end: selezionare il pool back-end
- Controllare "Porte a disponibilità elevata"
- Protocollo: TCP
- Probe di integrità: creare un probe di integrità con i dettagli seguenti
- Protocollo: TCP
- Porta: [ad esempio: 625<instance-no.>]
- Intervallo: 5
- Soglia probe: 2
- Timeout di inattività (minuti): 30
- Selezionare "Enable Floating IP" (Abilita IP mobile)
Nota
Il numero della proprietà di configurazione del probe di integritàOfProbes, altrimenti noto come "Soglia non integra" nel portale, non viene rispettato. Per controllare il numero di probe consecutivi riusciti o non riusciti, impostare la proprietà "probeThreshold" su 2. Attualmente non è possibile impostare questa proprietà usando portale di Azure, quindi usare l'interfaccia della riga di comando di Azure o il comando di PowerShell.
Per altre informazioni sulle porte necessarie per SAP HANA, leggere il capitolo Connections to Tenant Databases (Connessioni a database tenant) della guida SAP HANA Tenant Databases (Database tenant SAP HANA) o la nota SAP 2388694.
Importante
L'indirizzo IP mobile non è supportato in una configurazione IP secondaria della scheda di interfaccia di rete negli scenari di bilanciamento del carico. Per altre informazioni, vedere Limitazioni di Azure Load Balancer. Se è necessario un altro indirizzo IP per la macchina virtuale, distribuire una seconda scheda di interfaccia di rete.
Nota
Quando le macchine virtuali senza indirizzi IP pubblici vengono inserite nel pool back-end di un'istanza interna (nessun indirizzo IP pubblico) di Azure Load Balancer Standard, non esiste connettività Internet in uscita, a meno che non venga eseguita più configurazione per consentire il routing agli endpoint pubblici. Per altre informazioni su come ottenere la connettività in uscita, vedere Connettività degli endpoint pubblici per le macchine virtuali con Azure Load Balancer Standard in scenari a disponibilità elevata SAP.
Importante
Non abilitare i timestamp TCP nelle macchine virtuali di Azure posizionate dietro Azure Load Balancer. L'abilitazione dei timestamp TCP potrebbe causare l'esito negativo dei probe di integrità. Impostare il parametro net.ipv4.tcp_timestamps su 0. Per altre informazioni, vedere Probe di integrità del servizio di bilanciamento del carico e note SAP 2382421.
Montare il volume di Azure NetApp Files
[A] Creare punti di montaggio per i volumi di database HANA.
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] Verificare l'impostazione del dominio NFS. Assicurarsi che il dominio sia configurato come dominio predefinito di Azure NetApp Files, ovvero defaultv4iddomain.com e che il mapping sia impostato su nessuno.
sudo cat /etc/idmapd.confOutput di esempio:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyImportante
Assicurarsi di impostare il dominio NFS in
/etc/idmapd.confnella macchina virtuale in modo che corrisponda alla configurazione di dominio predefinita in Azure NetApp Files: defaultv4iddomain.com. Se si verifica una mancata corrispondenza tra la configurazione del dominio nel client NFS (ovvero la macchina virtuale) e il server NFS (ovvero la configurazione di Azure NetApp Files), le autorizzazioni per i file nei volumi di Azure NetApp Files montati nelle macchine virtuali vengono visualizzate comenobody.[1] Montare i volumi specifici del nodo in node1 (hanadb1).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] Montare i volumi specifici del nodo in node2 (hanadb2).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] Verificare che tutti i volumi HANA siano montati con la versione del protocollo NFS NFSv4.
sudo nfsstat -mVerificare che il flag
verssia impostato su 4.1. Esempio di hanadb1:/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A] Verificare nfs4_disable_idmapping. Deve essere impostato su Y. Per creare la struttura di directory in cui si trova nfs4_disable_idmapping , eseguire il comando mount. Non è possibile creare manualmente la directory in
/sys/modulesperché l'accesso è riservato per il kernel e i driver.Controlla
nfs4_disable_idmapping.sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingSe è necessario impostare
nfs4_disable_idmappingsu:sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmappingRendere permanente la configurazione.
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confPer altre informazioni su come modificare il
nfs_disable_idmappingparametro, vedere la Knowledge Base di Red Hat.
Installazione di SAP HANA
[A] Configurare la risoluzione dei nomi host per tutti gli host.
È possibile usare un server DNS o modificare il
/etc/hostsfile in tutti i nodi. In questo esempio viene illustrato come usare il/etc/hostsfile . Sostituire l'indirizzo IP e il nome host nei comandi seguenti:sudo vi /etc/hostsInserire le righe seguenti nel
/etc/hostsfile. Modificare l'indirizzo IP e il nome host in modo che corrispondano all'ambiente.10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] Preparare il sistema operativo per l'esecuzione di SAP HANA in Azure NetApp con NFS, come descritto nella nota SAP 3024346 - Kernel Linux Impostazioni per NetApp NFS. Creare il file
/etc/sysctl.d/91-NetApp-HANA.confdi configurazione per le impostazioni di configurazione di NetApp.sudo vi /etc/sysctl.d/91-NetApp-HANA.confAggiungere le voci seguenti nel file di configurazione.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Creare il file
/etc/sysctl.d/ms-az.confdi configurazione con altre impostazioni di ottimizzazione.sudo vi /etc/sysctl.d/ms-az.confAggiungere le voci seguenti nel file di configurazione.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Suggerimento
Evitare di impostare
net.ipv4.ip_local_port_rangeenet.ipv4.ip_local_reserved_portsin modo esplicito neisysctlfile di configurazione per consentire all'agente host SAP di gestire gli intervalli di porte. Per altre informazioni, vedere SAP Note 2382421.[A] Modificare le
sunrpcimpostazioni, come consigliato in SAP Note 3024346 - Linux Kernel Impostazioni per NetApp NFS.sudo vi /etc/modprobe.d/sunrpc.confInserire la riga seguente:
options sunrpc tcp_max_slot_table_entries=128[A] Eseguire la configurazione del sistema operativo RHEL per HANA.
Configurare il sistema operativo come descritto nelle note SAP seguenti in base alla versione RHEL:
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (2292690 - SAP HANA DB: impostazioni del sistema operativo consigliate per RHEL 7)
- 2777782 - DATABASE SAP HANA: Impostazioni del sistema operativo consigliato per RHEL 8
- 2455582 - Linux: Esecuzione di applicazioni SAP compilate con GCC 6.x
- 2593824 - Linux: Esecuzione di applicazioni SAP compilate con GCC 7.x
- 2886607 - Linux: Esecuzione di applicazioni SAP compilate con GCC 9.x
[A] Installare SAP HANA.
A partire da HANA 2.0 SPS 01, MDC è l'opzione predefinita. Quando si installa il sistema HANA, SYSTEMDB e un tenant con lo stesso SID vengono creati insieme. In alcuni casi, non si vuole che il tenant predefinito. Se non si vuole creare un tenant iniziale insieme all'installazione, è possibile seguire la nota SAP 2629711.
Eseguire il programma hdblcm dal DVD di HANA. Immettere i valori seguenti al prompt:
- Scegliere l'installazione: immettere 1 (per l'installazione).
- Selezionare altri componenti per l'installazione: immettere 1.
- Immettere percorso di installazione [/hana/shared]: selezionare Invio per accettare l'impostazione predefinita.
- Immettere il nome host locale [..]: selezionare Invio per accettare l'impostazione predefinita. Aggiungere altri host al sistema? (y/n) [n]: n.
- Immettere l'ID sistema SAP HANA: immettere HN1.
- Immettere numero di istanza [00]: immettere 03.
- Selezionare Modalità database/Immettere indice [1]: selezionare INVIO per accettare l'impostazione predefinita.
- Selezionare Utilizzo sistema/Immettere indice [4]: immettere 4 (per personalizzato).
- Immettere posizione dei volumi di dati [/hana/data]: selezionare INVIO per accettare il valore predefinito.
- Immettere il percorso dei volumi di log [/hana/log]: selezionare INVIO per accettare l'impostazione predefinita.
- Limitare l'allocazione massima della memoria? [n]: selezionare INVIO per accettare il valore predefinito.
- Immettere il nome host del certificato per l'host '...' [...]: selezionare Invio per accettare l'impostazione predefinita.
- Immettere la password dell'utente dell'agente host SAP (sapadm): immettere la password utente dell'agente host.
- Confermare la password dell'utente dell'agente host SAP (sapadm): immettere di nuovo la password utente dell'agente host per confermare.
- Immettere System Amministrazione istrator (hn1adm) Password: immettere la password dell'amministratore di sistema.
- Confermare la password di System Amministrazione istrator (hn1adm): immettere di nuovo la password dell'amministratore di sistema per confermare.
- Immettere System Amministrazione istrator Home Directory [/usr/sap/HN1/home]: selezionare Invio per accettare il valore predefinito.
- Immettere System Amministrazione istrator Login Shell [/bin/sh]: selezionare INVIO per accettare il valore predefinito.
- Immettere System Amministrazione istrator User ID [1001]: selezionare Invio per accettare l'impostazione predefinita.
- Immettere l'ID del gruppo di utenti (sapsys) [79]: selezionare INVIO per accettare il valore predefinito.
- Immettere Password utente database (SYSTEM): immettere la password utente del database.
- Conferma password utente database (SYSTEM): immettere di nuovo la password utente del database per confermare.
- Riavviare il sistema dopo il riavvio della macchina? [n]: selezionare INVIO per accettare il valore predefinito.
- Vuoi continuare? (y/n): convalidare il riepilogo. Immettere y per continuare.
[T] Aggiornare l'agente host SAP.
Scaricare l'archivio dell'agente host SAP più recente dal sito SAP Software Center ed eseguire il comando seguente per aggiornare l'agente. Sostituire il percorso dell'archivio in modo da puntare al file scaricato:
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] Configurare un firewall.
Creare la regola del firewall per la porta probe di Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
Configurare la replica di sistema SAP HANA
Seguire la procedura descritta in Configurare la replica di sistema SAP HANA per configurare la replica di sistema SAP HANA.
Configurazione del cluster
Questa sezione descrive i passaggi necessari per il funzionamento facile di un cluster quando SAP HANA è installato nelle condivisioni NFS usando Azure NetApp Files.
Creare un cluster Pacemaker
Seguire la procedura descritta in Configurare Pacemaker in Red Hat Enterprise Linux in Azure per creare un cluster Pacemaker di base per questo server HANA.
Importante
Con SAP Startup Framework basato su sistema, le istanze di SAP HANA possono ora essere gestite dal sistema. La versione minima richiesta di Red Hat Enterprise Linux (RHEL) è RHEL 8 per SAP. Come descritto nella nota SAP 3189534, tutte le nuove installazioni di SAP HANA SPS07 versione 70 o successive o gli aggiornamenti ai sistemi HANA a HANA 2.0 SPS07 versione 70 o successiva, SAP Startup Framework verrà registrato automaticamente con systemd.
Quando si usano soluzioni a disponibilità elevata per gestire la replica del sistema SAP HANA in combinazione con le istanze di SAP HANA abilitate per il sistema (vedere SAP Note 3189534), sono necessari passaggi aggiuntivi per garantire che il cluster a disponibilità elevata possa gestire l'istanza SAP senza interferenze di sistema. Pertanto, per il sistema SAP HANA integrato con systemd, i passaggi aggiuntivi descritti in Red Hat KBA 7029705 devono essere seguiti in tutti i nodi del cluster.
Implementare l'hook di replica del sistema Python SAPHanaSR
Questo passaggio è importante per ottimizzare l'integrazione con il cluster e migliorare il rilevamento quando è necessario un failover del cluster. È consigliabile configurare l'hook Python SAPHanaSR. Seguire la procedura descritta in Implementare l'hook della replica di sistema Python SAPHanaSR.
Configurare le risorse del file system
In questo esempio ogni nodo del cluster ha i propri file system /hana/sharedNFS HANA , /hana/datae /hana/log.
[1] Inserire il cluster in modalità di manutenzione.
sudo pcs property set maintenance-mode=true[1] Creare le risorse del file system per i montaggi hanadb1 .
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2] Creare le risorse del file system per i montaggi hanadb2 .
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfsL'attributo
OCF_CHECK_LEVEL=20viene aggiunto all'operazione di monitoraggio in modo che ogni monitoraggio esegua un test di lettura/scrittura nel file system. Senza questo attributo, l'operazione di monitoraggio verifica solo che il file system sia montato. Questo può essere un problema perché quando la connettività viene persa, il file system potrebbe rimanere montato nonostante non sia accessibile.L'attributo
on-fail=fenceviene aggiunto anche all'operazione di monitoraggio. Con questa opzione, se l'operazione di monitoraggio non riesce in un nodo, tale nodo viene immediatamente delimitato. Senza questa opzione, il comportamento predefinito consiste nell'arrestare tutte le risorse che dipendono dalla risorsa non riuscita, riavviare la risorsa non riuscita e quindi avviare tutte le risorse che dipendono dalla risorsa non riuscita.Non solo questo comportamento può richiedere molto tempo quando una risorsa SAPHana dipende dalla risorsa non riuscita, ma può anche avere esito negativo. La risorsa SAPHana non può arrestarsi correttamente se il server NFS che contiene i file eseguibili HANA non è accessibile.
I valori di timeout suggeriti consentono alle risorse del cluster di resistere alla pausa specifica del protocollo, correlata ai rinnovi di lease NFSv4.1. Per altre informazioni, vedere Procedura consigliata per NFS in NetApp. I timeout nella configurazione precedente potrebbero essere necessari per adattarsi alla configurazione SAP specifica.
Per i carichi di lavoro che richiedono una velocità effettiva maggiore, è consigliabile usare l'opzione
nconnectdi montaggio, come descritto in Volumi NFS v4.1 in Azure NetApp Files per SAP HANA. Controllare senconnectè supportato da Azure NetApp Files nella versione Linux.[1] Configurare i vincoli di posizione.
Configurare i vincoli di posizione per assicurarsi che le risorse che gestiscono i montaggi univoci di hanadb1 non possano mai essere eseguite in hanadb2 e viceversa.
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1L'opzione
resource-discovery=neverè impostata perché i montaggi univoci per ogni nodo condividono lo stesso punto di montaggio. Ad esempio,hana_data1usa il punto di montaggio/hana/dataehana_data2usa anche il punto di montaggio/hana/data. La condivisione dello stesso punto di montaggio può causare un falso positivo per un'operazione probe, quando lo stato della risorsa viene controllato all'avvio del cluster e può a sua volta causare un comportamento di ripristino non necessario. Per evitare questo scenario, impostareresource-discovery=never.[1] Configurare le risorse degli attributi.
Configurare le risorse degli attributi. Questi attributi sono impostati su true se vengono montati tutti i montaggi NFS di un nodo (
/hana/data,/hana/loge/hana/data). In caso contrario, sono impostati su false.sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] Configurare i vincoli di posizione.
Configurare i vincoli di posizione per assicurarsi che la risorsa attributo di hanadb1 non venga mai eseguita in hanadb2 e viceversa.
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] Creare vincoli di ordinamento.
Configurare i vincoli di ordinamento in modo che le risorse dell'attributo di un nodo vengano avviate solo dopo il montaggio di tutti i montaggi NFS del nodo.
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_activeSuggerimento
Se la configurazione include file system, al di fuori del gruppo
hanadb1_nfsohanadb2_nfs, includere l'opzionesequential=falsein modo che non vi siano dipendenze di ordinamento tra i file system. Tutti i file system devono iniziare primahana_nfs1_activedi , ma non devono iniziare in alcun ordine rispetto all'altro. Per altre informazioni, vedere Ricerca per categorie configurare la replica di sistema SAP HANA in scale-up in un cluster Pacemaker quando i file system HANA si trovano in condivisioni NFS
Configurare le risorse del cluster SAP HANA
Seguire la procedura descritta in Creare risorse cluster SAP HANA per creare le risorse SAP HANA nel cluster. Dopo aver creato le risorse SAP HANA, è necessario creare un vincolo di regola di posizione tra le risorse SAP HANA e i file system (montaggi NFS).
[1] Configurare i vincoli tra le risorse SAP HANA e i montaggi NFS.
I vincoli delle regole di posizione vengono impostati in modo che le risorse SAP HANA possano essere eseguite in un nodo solo se vengono montati tutti i montaggi NFS del nodo.
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueIn RHEL 7.x:
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueIn RHEL 8.x/9.x:
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueDisconnesso il cluster dalla modalità di manutenzione.
sudo pcs property set maintenance-mode=falseControllare lo stato del cluster e di tutte le risorse.
Nota
Questo articolo contiene riferimenti a un termine che Microsoft non usa più. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
sudo pcs statusOutput di esempio:
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
Configurare la replica di sistema attiva/abilitata per la lettura di HANA nel cluster Pacemaker
A partire da SAP HANA 2.0 SPS 01, SAP consente configurazioni attive/abilitate per la lettura per la replica di sistema SAP HANA, in cui i sistemi secondari della replica di sistema SAP HANA possono essere usati attivamente per carichi di lavoro con un'intensa attività di lettura. Per supportare tale configurazione in un cluster, è necessario un secondo indirizzo IP virtuale, che consente ai client di accedere al database SAP HANA abilitato per la lettura secondario.
Per assicurarsi che il sito di replica secondario sia ancora accessibile dopo che si è verificata un'acquisizione, il cluster deve spostare l'indirizzo IP virtuale con il database secondario della risorsa SAPHana.
La configurazione aggiuntiva, necessaria per gestire la replica di sistema attiva/abilitata per la lettura di HANA in un cluster Red Hat HA HA con un secondo IP virtuale, è descritta in Configurare la replica di sistema attiva/abilitata per la lettura di HANA nel cluster Pacemaker.
Prima di continuare, assicurarsi di aver configurato completamente Red Hat High Availability Cluster per la gestione del database SAP HANA, come descritto nelle sezioni precedenti della documentazione.
Testare la configurazione del cluster
Questa sezione descrive come testare la configurazione.
Prima di avviare un test, assicurarsi che Pacemaker non abbia alcuna azione non riuscita (tramite lo stato pcs), non ci siano vincoli di posizione imprevisti (ad esempio, a sinistra di un test di migrazione) e che la replica del sistema HANA sia in stato di sincronizzazione, ad esempio con
systemReplicationStatus:sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Verificare la configurazione del cluster per uno scenario di errore quando un nodo perde l'accesso alla condivisione NFS (
/hana/shared).Gli agenti di risorse SAP HANA dipendono dai file binari archiviati in
/hana/sharedper eseguire operazioni durante il failover. Il file system/hana/sharedviene montato su NFS nello scenario presentato.È difficile simulare un errore in cui uno dei server perde l'accesso alla condivisione NFS. Come test, è possibile rimontare il file system come di sola lettura. Questo approccio verifica che il cluster possa eseguire il failover, se l'accesso a
/hana/sharedviene perso nel nodo attivo.Risultato previsto: durante l'esecuzione
/hana/sharedcome file system di sola lettura, l'attributoOCF_CHECK_LEVELdella risorsahana_shared1, che esegue operazioni di lettura/scrittura nei file system, ha esito negativo. Non è in grado di scrivere nulla nel file system ed esegue il failover delle risorse HANA. Lo stesso risultato è previsto quando il nodo HANA perde l'accesso alle condivisioni NFS.Stato delle risorse prima dell'avvio del test:
sudo pcs statusOutput di esempio:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1È possibile posizionare
/hana/sharedin modalità di sola lettura nel nodo del cluster attivo usando questo comando:sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadbriavvierà o spegnerà in base all'azione impostata sustonith(pcs property show stonith-action). Quando il server (hanadb1) è inattivo, la risorsa HANA passa ahanadb2. È possibile controllare lo stato del cluster dahanadb2.sudo pcs statusOutput di esempio:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2È consigliabile testare accuratamente la configurazione del cluster SAP HANA eseguendo anche i test descritti in Configurare la replica di sistema SAP HANA in RHEL.