Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come eseguire il training di un modello di Deep Learning personalizzato usando il transfer learning, un modello TensorFlow pre-addestrato e l'API di classificazione delle immagini ML.NET per classificare le immagini di superfici concrete come crepate o non crepate.
In questa esercitazione si apprenderà come:
- Informazioni sul problema
- Informazioni sull'API di classificazione delle immagini ML.NET
- Informazioni sul modello con training preliminare
- Usare il transfer learning per addestrare un modello di classificazione delle immagini TensorFlow personalizzato
- Classificare le immagini con il modello personalizzato
Prerequisiti
Informazioni sul problema
La classificazione delle immagini è un problema di visione artificiale. La classificazione delle immagini accetta un'immagine come input e la classifica in una classe prestabilita. I modelli di classificazione delle immagini vengono comunemente sottoposti a training usando deep learning e reti neurali. Per altre informazioni, vedere Deep Learning e Machine Learning.
Alcuni scenari in cui la classificazione delle immagini è utile includono:
- Riconoscimento facciale
- Rilevamento delle emozioni
- Diagnosi medica
- Rilevamento di punti chiave
Questa esercitazione addestra un modello di classificazione delle immagini personalizzato per eseguire l'ispezione visiva automatizzata dei ponti di ponte, al fine di identificare strutture danneggiate da crepe.
API di classificazione delle immagini ML.NET
ML.NET offre diversi modi per eseguire la classificazione delle immagini. Questa esercitazione applica l'apprendimento trasferito usando l'API Classificazione delle immagini. L'API Classificazione immagini usa TensorFlow.NET, una libreria di basso livello che fornisce associazioni C# per l'API C++ TensorFlow.
Che cos'è l'apprendimento induttivo?
L'apprendimento di trasferimento applica le conoscenze acquisite dalla risoluzione di un problema a un altro problema correlato.
Il training di un modello di Deep Learning da zero richiede l'impostazione di diversi parametri, una grande quantità di dati di training etichettati e una grande quantità di risorse di calcolo (centinaia di ore GPU). L'uso di un modello con training preliminare insieme all'apprendimento per il trasferimento consente di creare un collegamento al processo di training.
Processo di training
L'API di classificazione delle immagini avvia il processo di training caricando un modello TensorFlow pre-addestrato. Il processo di training è costituito da due passaggi:
- Fase di collo di bottiglia.
- Fase di training.
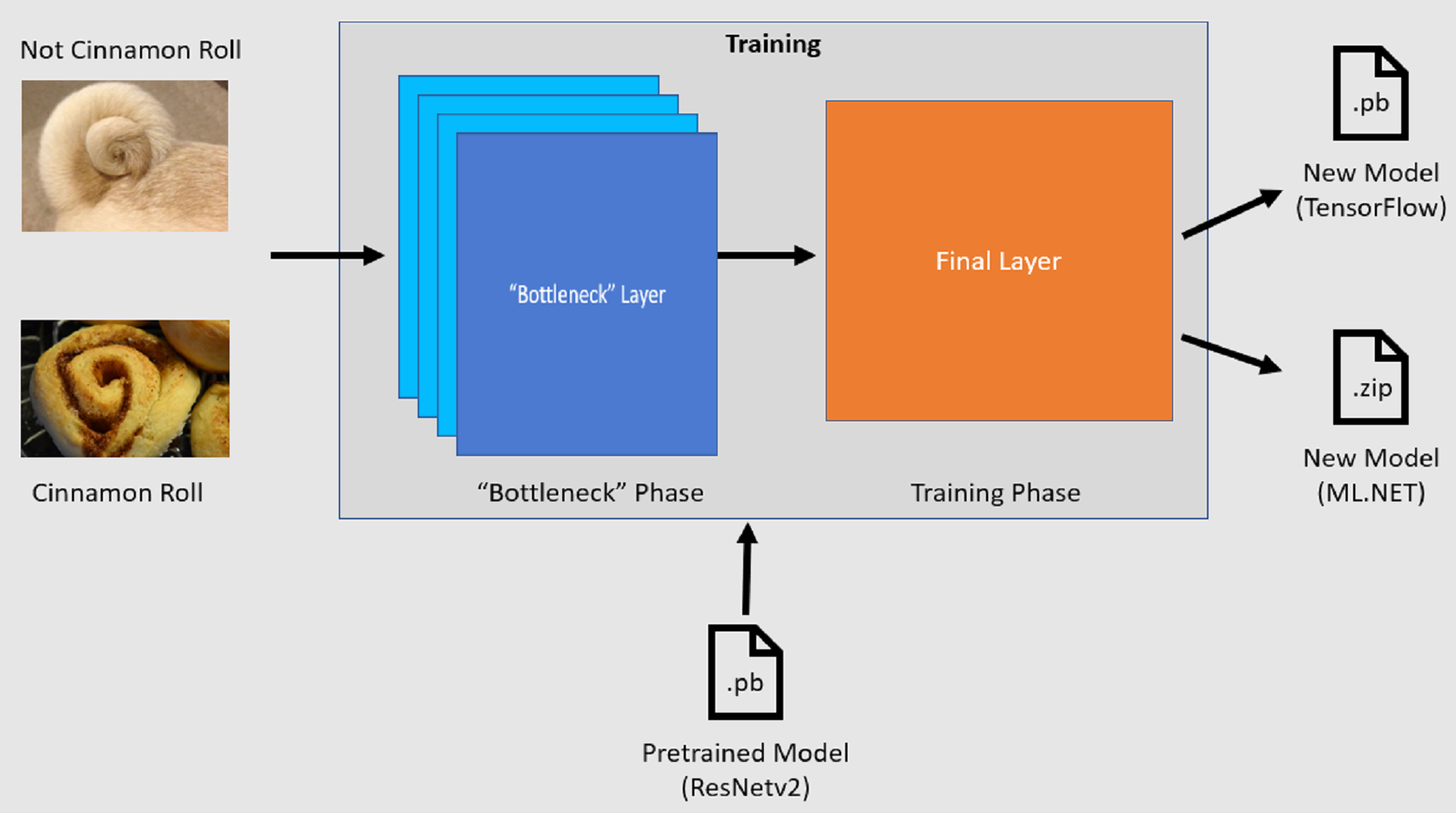
Fase collo di bottiglia
Durante la fase di bottleneck, il set di immagini di training viene caricato e i valori dei pixel vengono usati come input, o caratteristiche, per i livelli bloccati del modello pre-addestrato. I livelli congelati includono tutti i livelli nella rete neurale fino al penultimo livello, noto in modo informale come livello collo di bottiglia. Questi livelli vengono definiti congelati perché non viene eseguito alcun training su questi livelli e le operazioni vengono passate. Si tratta di questi livelli bloccati in cui vengono calcolati i modelli di livello inferiore che aiutano a distinguere un modello tra le diverse classi. Maggiore è il numero di livelli, maggiore è l'utilizzo di calcolo di questo passaggio. Fortunatamente, poiché si tratta di un calcolo monouso, i risultati possono essere memorizzati nella cache e usati in esecuzioni successive durante l'esperimento con parametri diversi.
Fase di training
Una volta calcolati i valori di output della fase di collo di bottiglia, vengono usati come input per ripetere il training del livello finale del modello. Questo processo è iterativo e viene eseguito per il numero di volte specificato dai parametri del modello. Durante ogni esecuzione, vengono valutate la perdita e l'accuratezza. Vengono quindi apportate le modifiche appropriate per migliorare il modello con l'obiettivo di ridurre al minimo la perdita e massimizzare l'accuratezza. Al termine del training, vengono restituiti due formati di modello. Una di esse è la .pb versione del modello e l'altra è la .zip ML.NET versione serializzata del modello. Quando si lavora in ambienti supportati da ML.NET, è consigliabile usare la .zip versione del modello. Tuttavia, negli ambienti in cui ML.NET non è supportato, è possibile usare la .pb versione.
Informazioni sul modello con training preliminare
Il modello preaddestrato usato in questa esercitazione è la variante a 101 livelli del modello di rete residua (ResNet) v2. Viene eseguito il training del modello originale per classificare le immagini in migliaia di categorie. Il modello accetta come input un'immagine di dimensioni 224 x 224 e restituisce le probabilità di classe per ognuna delle classi su cui viene eseguito il training. Parte di questo modello viene usata per eseguire il training di un nuovo modello usando immagini personalizzate per eseguire stime tra due classi.
Creare un'applicazione console
Ora che si ha una conoscenza generale dell'apprendimento del trasferimento e dell'API Classificazione immagini, è il momento di compilare l'applicazione.
Creare un'applicazione console C# denominata "DeepLearning_ImageClassification_Binary". Fare clic sul pulsante Avanti.
Scegliere .NET 8 come framework da usare e quindi selezionare Crea.
Installare il pacchetto NuGet Microsoft.ML
Annotazioni
In questo esempio viene usata la versione stabile più recente dei pacchetti NuGet menzionati, a meno che non diversamente specificato.
- In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e scegliere Gestisci pacchetti NuGet.
- Scegliere "nuget.org" come origine del pacchetto.
- Selezionare la scheda Sfoglia.
- Selezionare la casella di controllo Includi versione preliminare .
- Cercare Microsoft.ML.
- Selezionare il pulsante Installa .
- Selezionare il pulsante Accetto nella finestra di dialogo Accettazione della licenza se si accettano le condizioni di licenza per i pacchetti elencati.
- Ripetere questi passaggi per i pacchetti NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (versione 2.3.1) e Microsoft.ML.ImageAnalytics .
Preparare e comprendere i dati
Annotazioni
I set di dati per questa esercitazione provengono da Maguire, Marc; Dorafshan, Sattar; e Thomas, Robert J., "SDNET2018: set di dati di immagini crack concrete per le applicazioni di Machine Learning" (2018). Esplorare tutti i set di dati. Carta 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 è un set di dati di immagini che contiene annotazioni per strutture in calcestruzzo fessurate e non fessurate (ponti, pavimentazioni e muri).

I dati sono organizzati in tre sottodirectory:
- D contiene immagini bridge deck
- P contiene immagini di pavimentazione
- W contiene immagini a parete
Ognuna di queste sottodirectory contiene due sottodirectory con prefisso aggiuntivo:
- C è il prefisso usato per le superfici crepate
- U è il prefisso usato per le superfici non crittografate
In questa esercitazione vengono usate solo immagini bridge deck.
- Scaricare il set di dati e decomprimere.
- Creare una directory denominata "Assets" nel progetto per salvare i file del set di dati.
- Copiare le sottodirectory CD e UD dalla directory recentemente decompressa nella directory Assets.
Creare classi di input e output
Aprire il file Program.cs e sostituire il contenuto esistente con le direttive seguenti
using:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Creare una classe denominata
ImageData. Questa classe viene usata per rappresentare i dati inizialmente caricati.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDatacontiene le proprietà seguenti:-
ImagePathè il percorso completo in cui è archiviata l'immagine. -
Labelè la categoria a cui appartiene l'immagine. Questo è il valore da stimare.
-
Creare classi per i dati di input e output.
Sotto la
ImageDataclasse definire lo schema dei dati di input in una nuova classe denominataModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputcontiene le proprietà seguenti:-
Imageè labyte[]rappresentazione dell'immagine. Il modello prevede che i dati dell'immagine siano di questo tipo per il training. -
LabelAsKeyè la rappresentazione numerica dell'oggettoLabel. -
ImagePathè il percorso completo in cui è archiviata l'immagine. -
Labelè la categoria a cui appartiene l'immagine. Questo è il valore da stimare.
Solo
ImageeLabelAsKeyvengono usati per eseguire il training del modello ed eseguire stime. LeImagePathproprietà eLabelvengono mantenute per praticità per accedere al nome e alla categoria del file di immagine originale.-
Quindi, sotto la
ModelInputclasse , definire lo schema dei dati di output in una nuova classe denominataModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputcontiene le proprietà seguenti:-
ImagePathè il percorso completo in cui è archiviata l'immagine. -
Labelè la categoria originale a cui appartiene l'immagine. Questo è il valore da stimare. -
PredictedLabelè il valore stimato dal modello.
Analogamente a
ModelInput, è necessario soloPredictedLabelper eseguire stime perché contiene la stima eseguita dal modello. LeImagePathproprietà eLabelvengono mantenute per praticità per accedere al nome e alla categoria del file di immagine originale.-
Definire i percorsi e inizializzare le variabili
usingNelle direttive aggiungere il codice seguente a:Definire la posizione degli asset.
Inizializzare la
mlContextvariabile con una nuova istanza di MLContext.La classe MLContext è un punto di partenza per tutte le operazioni di ML.NET e l'inizializzazione di mlContext crea un nuovo ambiente ML.NET che può essere condiviso tra gli oggetti del flusso di lavoro di creazione del modello. È simile, concettualmente, a
DbContextin Entity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Caricare i dati
Creare un metodo di utilità di caricamento dati
Le immagini vengono archiviate in due sottodirectory. Prima di caricare i dati, è necessario formattarli in un elenco di ImageData oggetti. A tale scopo, creare il LoadImagesFromDirectory metodo :
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
Metodo LoadImagesFromDirectory:
- Ottiene tutti i percorsi di file dalle sottodirectory.
- Scorre ogni file usando un'istruzione
foreache verifica che le estensioni di file siano supportate. L'API Classificazione immagini supporta formati JPEG e PNG. - Ottiene l'etichetta per il file. Se il
useFolderNameAsLabelparametro è impostato sutrue, la directory padre in cui viene salvato il file viene usata come etichetta. In caso contrario, l'etichetta deve costituire un prefisso del nome del file o corrispondere al nome del file stesso. - Crea una nuova istanza di
ModelInput.
Prepara i dati
Aggiungere il codice seguente dopo la riga in cui si crea la nuova istanza di MLContext.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
Il codice precedente:
Chiama il
LoadImagesFromDirectorymetodo di utilità per ottenere l'elenco di immagini usate per il training dopo l'inizializzazione dellamlContextvariabile.Carica le immagini in un
IDataViewoggetto usando ilLoadFromEnumerablemetodo .Esegue lo shuffing dei dati usando il
ShuffleRowsmetodo . I dati vengono caricati nell'ordine in cui sono stati letti dalle directory. La sequenza casuale viene eseguita per bilanciarla.Esegue una pre-elaborazione sui dati prima del training. Questa operazione viene eseguita perché i modelli di Machine Learning prevedono che l'input sia in formato numerico. Il codice di pre-elaborazione crea un
EstimatorChainoggetto costituito dalleMapValueToKeytrasformazioni eLoadRawImageBytes. LaMapValueToKeytrasformazione accetta il valore categorico nellaLabelcolonna, la converte in un valore numericoKeyTypee la archivia in una nuova colonna denominataLabelAsKey.LoadImagesacquisisce i valori dalla colonnaImagePathinsieme al parametroimageFolderper caricare le immagini per l'addestramento.Usa il
Fitmetodo per applicare i dati all'oggettopreprocessingPipelineEstimatorChainseguito dalTransformmetodo , che restituisce un oggettoIDataViewcontenente i dati pre-elaborati.Suddivide i dati in set di training, convalida e test.
Per eseguire il training di un modello, è importante avere un set di dati di training e un set di dati di convalida. Il training del modello viene eseguito sul set di training. L'accuratezza delle stime sui dati non visualizzati viene misurata in base alle prestazioni rispetto al set di convalida. In base ai risultati di tali prestazioni, il modello apporta modifiche a ciò che ha appreso nel tentativo di migliorare. Il set di convalida può provenire dalla suddivisione del set di dati originale o da un'altra origine già messa da parte a questo scopo.
L'esempio di codice esegue due divisioni. Prima di tutto, i dati pre-elaborati vengono suddivisi e 70% vengono usati per il training mentre per la convalida vengono usati i rimanenti 30%. Il set di convalida 30% viene quindi suddiviso ulteriormente in set di convalida e di test in cui vengono usati 90% per la convalida e 10% viene usato per i test.
Un modo per considerare lo scopo di queste partizioni di dati consiste nell'eseguire un esame. Quando si studia per un esame, si esaminano le note, i libri o altre risorse per comprendere i concetti che si trovano nell'esame. Questo è a cosa serve il set di treni. È quindi possibile eseguire un esame fittizio per convalidare le conoscenze. Questo è il percorso in cui il set di convalida è utile. Si vuole verificare se si ha una buona comprensione dei concetti prima di eseguire l'esame effettivo. In base a questi risultati, prendi nota di ciò che hai sbagliato o che non hai capito bene e incorpora le modifiche durante la revisione dell'esame reale. Infine, si prende l'esame. Questo è ciò a cui serve il set di test. Non hai mai visto le domande che sono nell'esame e ora usi le nozioni apprese dalla formazione e dalla verifica per applicare le tue conoscenze al compito da svolgere.
Assegna le partizioni i rispettivi valori per i dati di training, convalida e test.
Definire la pipeline di training
L'addestramento del modello consiste in due passaggi. Prima di tutto, l'API Classificazione immagini viene usata per eseguire il training del modello. Le etichette codificate nella PredictedLabel colonna vengono quindi convertite nuovamente nel valore categorico originale usando la MapKeyToValue trasformazione .
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Il codice precedente:
Crea una nuova variabile per archiviare un set di parametri obbligatori e facoltativi per un oggetto ImageClassificationTrainer. Un ImageClassificationTrainer accetta diversi parametri facoltativi:
-
FeatureColumnNameè la colonna usata come input per il modello. -
LabelColumnNameè la colonna per il valore da stimare. -
ValidationSetè l'oggettoIDataViewcontenente i dati di convalida. -
Archdefinisce quale delle architetture del modello con training preliminare da usare. Questa esercitazione usa la variante di livello 101 del modello ResNetv2. -
MetricsCallbackassocia una funzione per tenere traccia dello stato di avanzamento durante il training. -
TestOnTrainSetindica al modello di misurare le prestazioni rispetto al set di training quando non è presente alcun set di convalida. -
ReuseTrainSetBottleneckCachedValuesindica al modello se usare i valori memorizzati nella cache dalla fase di collo di bottiglia nelle esecuzioni successive. La fase di collo di bottiglia è una computazione unica di passaggio che è computazionalmente intensiva la prima volta che viene eseguita. Se i dati di training non cambiano e si vuole sperimentare usando un numero diverso di periodi o dimensioni batch, l'uso dei valori memorizzati nella cache riduce significativamente la quantità di tempo necessaria per eseguire il training di un modello. -
ReuseValidationSetBottleneckCachedValuesè simile aReuseTrainSetBottleneckCachedValues, solo che in questo caso è per il set di dati di convalida.
-
Definisce la pipeline di formazione costituita sia da
mapLabelEstimatorche da ImageClassificationTrainer.Usa il metodo per eseguire il
Fittraining del modello.
Usa il modello
Ora che è stato eseguito il training del modello, è possibile usarlo per classificare le immagini.
Creare un nuovo metodo di utilità denominato OutputPrediction per visualizzare le informazioni di stima nella console.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Classificare una singola immagine
Creare un metodo chiamato
ClassifySingleImageper creare e restituire una stima di una singola immagine.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }Metodo
ClassifySingleImage:- Crea un oggetto
PredictionEngineall'interno delClassifySingleImagemetodo .PredictionEngineè un'API utile che consente di passare e quindi eseguire una stima su una singola istanza di dati. - Per accedere a una singola
ModelInputistanza, converte ilIEnumerableindataIDataViewutilizzando il metodoCreateEnumerablee quindi ottiene la prima osservazione. - Usa il
Predictmetodo per classificare l'immagine. - Restituisce la stima nella console con il
OutputPredictionmetodo .
- Crea un oggetto
Chiamare dopo aver chiamato
ClassifySingleImageilFitmetodo usando il set di test di immagini.ClassifySingleImage(mlContext, testSet, trainedModel);
Classificare più immagini
Creare un metodo chiamato
ClassifyImagesper eseguire e restituire più stime di immagini.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }Metodo
ClassifyImages:- Crea un oggetto
IDataViewcontenente le stime utilizzando ilTransformmetodo . - Per iterare sulle previsioni, converte il
predictionDataIDataViewin unIEnumerableutilizzando il metodoCreateEnumerablee quindi ottiene le prime 10 osservazioni. - Esegue l'iterazione e restituisce le etichette originali e stimate per le stime.
- Crea un oggetto
Chiamare dopo aver chiamato
ClassifyImagesilClassifySingleImage()metodo usando il set di test di immagini.ClassifyImages(mlContext, testSet, trainedModel);
Eseguire l'applicazione
Esegui l'app console. L'output dovrebbe essere simile all'output seguente.
Annotazioni
Potrebbero essere visualizzati avvisi o messaggi di elaborazione; tali messaggi sono stati rimossi dai risultati seguenti per maggiore chiarezza. Per brevità, l'output è stato condensato.
Fase collo di bottiglia
Non viene stampato alcun valore per il nome dell'immagine perché le immagini vengono caricate come byte[], quindi non c'è alcun nome di immagine da visualizzare.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Fase di training
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Classificare l'output delle immagini
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Dopo l'ispezione dell'immagine 7001-220.jpg , è possibile verificare che non sia rotto, come previsto dal modello.

Congratulazioni! A questo punto è stato creato un modello di Deep Learning per classificare le immagini.
Migliorare il modello
Se non si è soddisfatti dei risultati del modello, è possibile provare a migliorarne le prestazioni provando alcuni degli approcci seguenti:
- Altri dati: più esempi imparano da un modello, migliori sono le prestazioni. Scaricare il set di dati completo SDNET2018 e usarlo per il training.
- Aumentare i dati: una tecnica comune per aggiungere varietà ai dati consiste nell'aumentare i dati prendendo un'immagine e applicando trasformazioni diverse (ruotare, capovolgere, spostare, ritagliare). In questo modo vengono aggiunti esempi più diversi per il modello da cui apprendere.
- Eseguire il training per un periodo di tempo più lungo: più a lungo si esegue il training, più sarà ottimizzato il modello. L'aumento del numero di periodi potrebbe migliorare le prestazioni del modello.
- Sperimentare con gli iper parametri: oltre ai parametri usati in questa esercitazione, è possibile ottimizzare altri parametri per migliorare potenzialmente le prestazioni. La modifica della frequenza di apprendimento, che determina la grandezza degli aggiornamenti apportati al modello dopo ogni periodo, potrebbe migliorare le prestazioni.
- Usare un'architettura del modello diversa: a seconda dell'aspetto dei dati, il modello in grado di apprendere meglio le funzionalità potrebbe differire. Se non si è soddisfatti delle prestazioni del modello, provare a modificare l'architettura.
Passaggi successivi
In questa esercitazione si è appreso come creare un modello di Deep Learning personalizzato usando l'apprendimento di trasferimento, un modello TensorFlow di classificazione delle immagini con training preliminare e l'API di classificazione delle immagini ML.NET per classificare le immagini di superfici concrete come crepate o non crittografate.
Passa all'esercitazione successiva per saperne di più.
Vedere anche
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.