Report di fatturazione e utilizzo per Apache Spark in Microsoft Fabric
Si applica a: ![]() Ingegneria dei dati e data science in Microsoft Fabric
Ingegneria dei dati e data science in Microsoft Fabric
Questo articolo illustra l'utilizzo e la creazione di report di calcolo per ApacheSpark che supporta i carichi di lavoro synapse Ingegneria dei dati e science in Microsoft Fabric. L'utilizzo del calcolo include operazioni lakehouse come l'anteprima della tabella, il caricamento su delta, le esecuzioni dei notebook dall'interfaccia, le esecuzioni pianificate, le esecuzioni attivate dai passaggi dei notebook nelle pipeline e le esecuzioni di definizione del processo Apache Spark.
Analogamente ad altre esperienze in Microsoft Fabric, Ingegneria dei dati usa anche la capacità associata a un'area di lavoro per eseguire questi processi e gli addebiti complessivi per la capacità vengono visualizzati nella portale di Azure nella sottoscrizione di Gestione costi Microsoft. Per altre informazioni sulla fatturazione dell'infrastruttura, vedere Informazioni sulla fattura di Azure per una capacità di Infrastruttura.
Capacità dell'infrastruttura
L'utente può acquistare una capacità di Infrastruttura da Azure specificando l'uso di una sottoscrizione di Azure. La dimensione della capacità determina la quantità di potenza di calcolo disponibile. Per Apache Spark per Fabric, ogni cu acquistato si traduce in 2 VCore Apache Spark. Ad esempio, se si acquista una capacità di Fabric F128, si traduce in 256 SparkVCore. Una capacità di Infrastruttura viene condivisa in tutte le aree di lavoro aggiunte e in cui il calcolo totale di Apache Spark consentito viene condiviso tra tutti i processi inviati da tutte le aree di lavoro associate a una capacità. Per informazioni sui diversi SKU, sull'allocazione dei core e sulla limitazione delle richieste in Spark, vedere Limiti di concorrenza e accodamento in Apache Spark per Microsoft Fabric.
Configurazione di calcolo Spark e capacità acquistata
L'ambiente di calcolo Apache Spark per Fabric offre due opzioni per la configurazione di calcolo.
Pool di avvio: questi pool predefiniti sono un modo semplice e veloce per usare Spark nella piattaforma Microsoft Fabric in pochi secondi. È possibile usare immediatamente le sessioni Spark, invece di attendere che Spark configuri automaticamente i nodi, che consente di eseguire altre operazioni con i dati e ottenere informazioni più rapide. Quando si tratta di fatturazione e consumo di capacità, vengono addebitati costi quando si avvia l'esecuzione del notebook o della definizione del processo Spark o dell'operazione lakehouse. Non viene addebitato il tempo in cui i cluster sono inattivi nel pool.
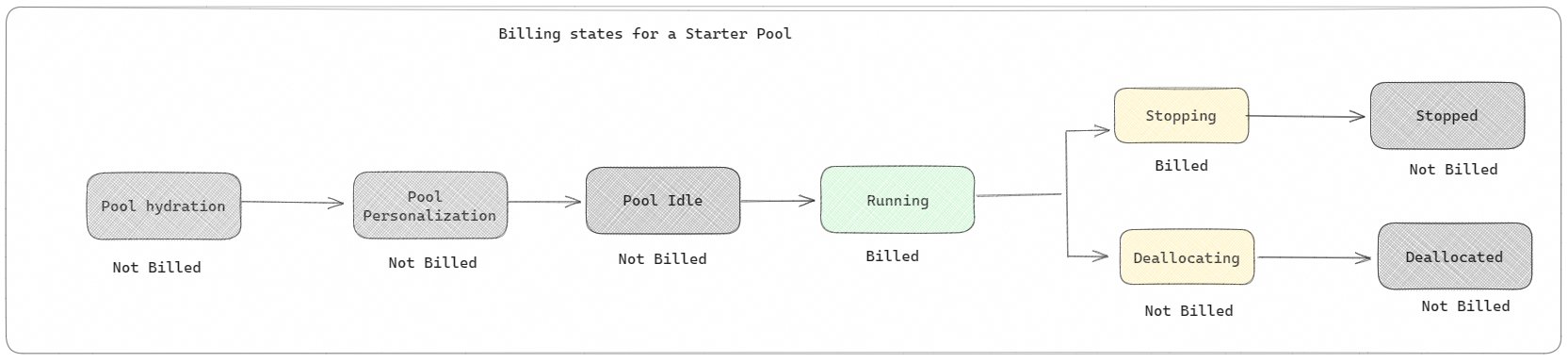
Ad esempio, se si invia un processo del notebook a un pool di avvio, viene addebitato solo per il periodo di tempo in cui è attiva la sessione del notebook. Il tempo fatturato non include il tempo di inattività o il tempo impiegato per personalizzare la sessione con il contesto Spark. Per altre informazioni sulla configurazione dei pool starter in base allo SKU della capacità di infrastruttura acquistata, vedere Configuring Starter Pools based on Fabric Capacity (Configurazione dei pool di avvio in base alla capacità infrastruttura)
Pool di Spark: si tratta di pool personalizzati, in cui è possibile personalizzare le dimensioni delle risorse necessarie per le attività di analisi dei dati. È possibile assegnare un nome al pool di Spark e scegliere il numero e le dimensioni dei nodi (i computer che eseguono il lavoro). È anche possibile indicare a Spark come modificare il numero di nodi a seconda della quantità di lavoro disponibile. La creazione di un pool di Spark è gratuita; si paga solo quando si esegue un processo Spark nel pool e quindi Spark configura automaticamente i nodi.
- Le dimensioni e il numero di nodi che è possibile avere nel pool di Spark personalizzato dipendono dalla capacità di Microsoft Fabric. È possibile usare questi VCore Spark per creare nodi di dimensioni diverse per il pool di Spark personalizzato, purché il numero totale di VCore Spark non superi 128.
- I pool di Spark vengono fatturati come pool di avvio; non si paga per i pool di Spark personalizzati creati, a meno che non sia stata creata una sessione Spark attiva per l'esecuzione di un notebook o una definizione di processo Spark. La fatturazione viene addebitata solo per la durata delle esecuzioni del processo. Non vengono fatturate fasi come la creazione e la deallocazione del cluster al termine del processo.

Ad esempio, se si invia un processo notebook a un pool di Spark personalizzato, viene addebitato solo il periodo di tempo in cui la sessione è attiva. La fatturazione per la sessione del notebook si arresta dopo che la sessione Spark è stata arrestata o scaduta. Non vengono addebitati i costi per l'acquisizione delle istanze del cluster dal cloud o per il tempo impiegato per l'inizializzazione del contesto Spark. Per altre informazioni sulla configurazione dei pool di Spark in base allo SKU di capacità dell'infrastruttura acquistato, vedere Configurazione dei pool in base alla capacità dell'infrastruttura


Nota
Il periodo di scadenza della sessione predefinito per i pool di avvio e i pool di Spark creati è impostato su 20 minuti. Se non si usa il pool di Spark per 2 minuti dopo la scadenza della sessione, il pool di Spark verrà deallocato. Per arrestare la sessione e la fatturazione dopo aver completato l'esecuzione del notebook prima del periodo di scadenza della sessione, è possibile fare clic sul pulsante Arresta sessione dal menu Home dei notebook oppure passare alla pagina dell'hub di monitoraggio e arrestare la sessione.
Creazione di report sull'utilizzo delle risorse di calcolo Spark
L'app Microsoft Fabric Capacity Metrics offre visibilità sull'utilizzo della capacità per tutti i carichi di lavoro di Fabric in un'unica posizione. Viene usato dagli amministratori della capacità per monitorare le prestazioni dei carichi di lavoro e il relativo utilizzo, rispetto alla capacità acquistata.
Dopo aver installato l'app, selezionare il tipo di elemento Notebook,Lakehouse,Spark Job Definition nell'elenco a discesa Seleziona tipo di elemento: . Il grafico a nastri Multi metrica può ora essere modificato in base a un intervallo di tempo desiderato per comprendere l'utilizzo da tutti questi elementi selezionati.
Tutte le operazioni correlate a Spark vengono classificate come operazioni in background. Il consumo di capacità da Spark viene visualizzato in un notebook, in una definizione di processo Spark o in una lakehouse e viene aggregato in base al nome e all'elemento dell'operazione. Ad esempio: se si esegue un processo notebook, è possibile visualizzare l'esecuzione del notebook, le UNITÀ di configurazione usate dal notebook (Total Spark VCores/2 come 1 CU fornisce 2 VCore Spark), la durata del processo è stata eseguita nel report.
 Per altre informazioni sulla creazione di report sull'utilizzo della capacità spark, vedere Monitorare il consumo di capacità di Apache Spark
Per altre informazioni sulla creazione di report sull'utilizzo della capacità spark, vedere Monitorare il consumo di capacità di Apache Spark
Esempio di fatturazione
Prendi in considerazione lo scenario seguente:
È presente una capacità C1 che ospita un'area di lavoro infrastruttura W1 e questa area di lavoro contiene Lakehouse LH1 e Notebook NB1.
- Qualsiasi operazione Spark eseguita dal notebook(NB1) o lakehouse(LH1) viene segnalata rispetto alla capacità C1.
Estensione di questo esempio a uno scenario in cui è presente un'altra capacità C2 che ospita un'area di lavoro infrastruttura W2 e indica che questa area di lavoro contiene una definizione di processo Spark (SJD1) e Lakehouse (LH2).
- Se la definizione del processo Spark (SDJ2) da Workspace (W2) legge i dati da lakehouse (LH1) l'utilizzo viene segnalato rispetto alla capacità C2 associata all'area di lavoro (W2) che ospita l'elemento.
- Se il notebook (NB1) esegue un'operazione di lettura da Lakehouse(LH2), il consumo di capacità viene segnalato rispetto alla capacità C1 che alimenta l'area di lavoro W1 che ospita l'elemento del notebook.
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per