Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa esercitazione si usano notebook con il runtimeSpark per trasformare e preparare dati non elaborati nel lakehouse.
Prerequisiti
Prima di iniziare, è necessario completare le esercitazioni precedenti in questa serie:
- Creare un lakehouse
- Inserire i dati nel lakehouse
- Assicurarsi che gli schemi lakehouse siano abilitati nel lakehouse.
Preparazione dei dati
Nei passaggi precedenti del tutorial, hai fatto inserire dati non elaborati dall'origine nella sezione File del lakehouse. Ora è possibile trasformare i dati e prepararli per la creazione di tabelle Delta.
Scarica i notebook dalla cartella Codice sorgente dell’esercitazione Lakehouse.
Nel browser, vai all'area di lavoro Fabric nel portale Fabric.
Selezionare Importa>notebook>da questo computer.
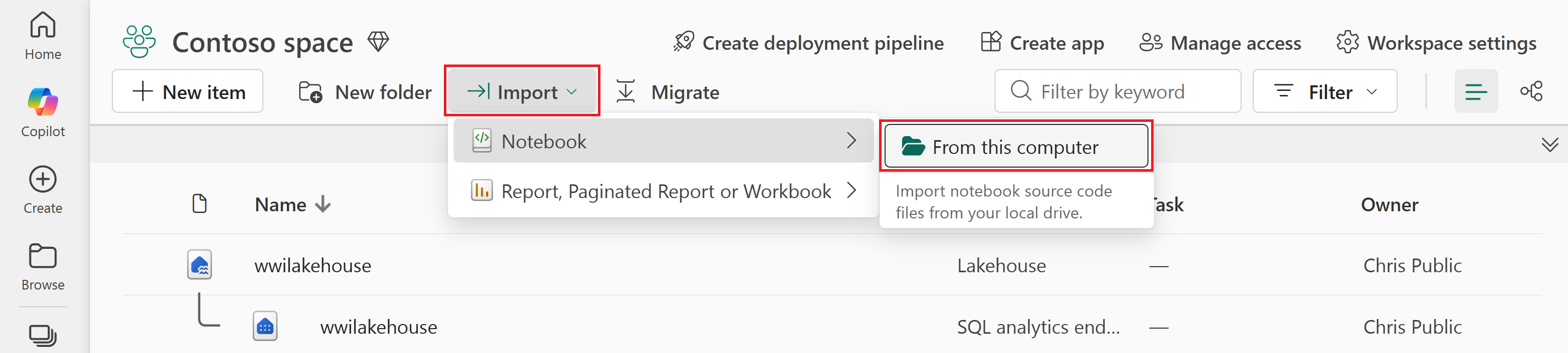
Selezionare Carica dal riquadro Stato importazione che si apre sul lato destro della schermata.
Selezionare solo il notebook corrispondente al linguaggio di codifica preferito.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Selezionare Apri. Viene visualizzata una notifica che indica lo stato dell'importazione nell'angolo superiore destro della finestra del browser.
Al termine dell'importazione, passare alla visualizzazione elementi dell'area di lavoro per verificare il notebook importato.
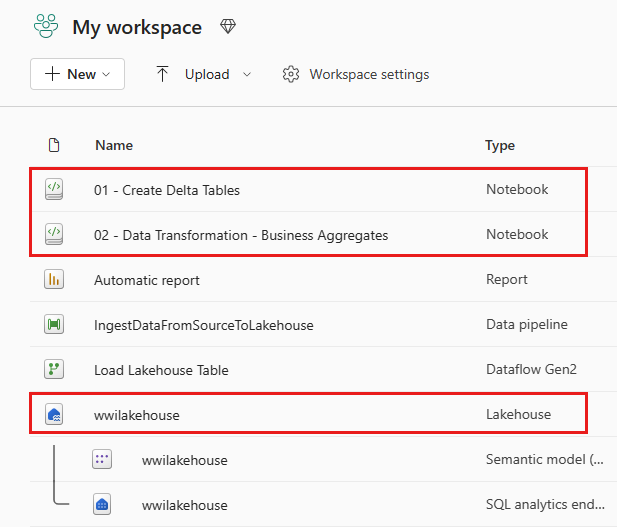
Seleziona il lakehouse wwilakehouse per aprirlo, in modo che il prossimo notebook che apri sia collegato ad esso.
Nel menu di spostamento in alto selezionare Apri notebook>esistente.
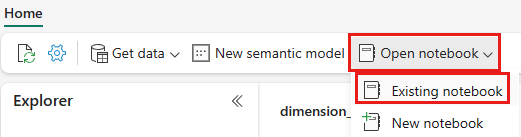
Selezionare il notebook importato per PySpark o Spark SQL e selezionare Apri. Il notebook è già collegato al Lakehouse aperto, come mostrato in Lakehouse Explorer.



A questo punto è possibile eseguire le celle del notebook che creano e trasformano le tabelle Delta.
Nelle sezioni seguenti eseguire le celle del notebook in sequenza. Per eseguire una cella, selezionare l'icona Esegui visualizzata a sinistra della cella al passaggio del mouse. È anche possibile selezionare Esegui tutto sulla barra multifunzione superiore (Home) per eseguire tutte le celle in sequenza.
Importante
Per questa esercitazione è necessario abilitare gli schemi lakehouse. Se gli schemi non sono abilitati, il codice in questa esercitazione non funzionerà come previsto.
Nel notebook importato vengono visualizzate entrambe le sezioni Path 1 e Path 2 . Per questa esercitazione, usare Il percorso 1 (schemi lakehouse abilitati) e ignorare il percorso 2 (schemi lakehouse non abilitati).
Creare tabelle Delta
In questa sezione, esegui le celle del notebook per creare tabelle Delta dai dati non elaborati.
Le tabelle seguono uno schema star, che è un modello comune per organizzare i dati analitici:
- Una tabella dei fatti (
fact_sale) contiene gli eventi misurabili dell'azienda, in questo caso singole transazioni di vendita con quantità, prezzi e profitto. -
Le tabelle delle dimensioni (
dimension_city,dimension_customer,dimension_datedimension_employee, , )dimension_stock_itemcontengono gli attributi descrittivi che danno contesto ai fatti, ad esempio dove si è verificata una vendita, chi l'ha fatto e quando.
In questa pagina dell'esercitazione selezionare la scheda corrispondente al notebook importato e continuare a usare la stessa scheda per tutti i passaggi. Le tab sono nell'articolo, non nel notebook.
Cella 1 - Configurazione della sessione Spark. Questa cella abilita due funzionalità di Fabric che ottimizzano la modalità di scrittura e lettura dei dati nelle celle successive. L'ordine V ottimizza il layout del file Parquet per letture più veloci e una migliore compressione. Ottimizzare la scrittura riduce il numero di file scritti e aumenta le dimensioni dei singoli file.
Esegui questa cella e attendi il completamento prima di passare al passaggio successivo.
Cella 2 - Fatto - Vendita. Questa cella legge i dati parquet non elaborati da
Files/wwi-raw-data/full/fact_sale_1y_full, aggiunge le colonne della parte di data (Year, Quarter e Month) e scrivefact_salecome tabella Delta partizionata da Year e Quarter.Esegui questa cella e attendi il completamento prima di passare al passaggio successivo.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Cella 3 - Dimensioni. Questa cella legge i cinque set di dati Parquet delle cinque dimensioni e li scrive come tabelle Delta (
dimension_city,dimension_customer,dimension_date,dimension_employee, edimension_stock_item) inTables/dbo/....Esegui questa cella e attendi il completamento prima di passare al passaggio successivo.
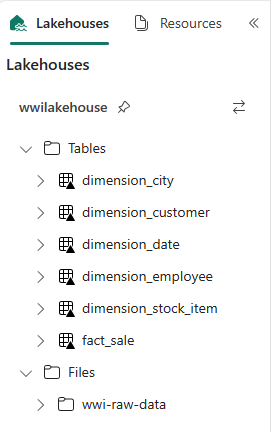
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Per convalidare le tabelle create, fare clic con il pulsante destro del mouse sul lakehouse wwilakehouse nella finestra di esplorazione e quindi scegliere Aggiorna. Appaiono le tabelle.

Trasformare i dati per le aggregazioni aziendali
In questa sezione si continua nello stesso notebook ed si eseguono le celle successive per creare tabelle di aggregazione dalle tabelle Delta create nella sezione precedente.
Assicurarsi che il notebook sia ancora collegato a wwilakehouse.
Cella 4- Caricare le tabelle di origine per la trasformazione (solo PySpark). Se si usa il notebook PySpark, eseguire questa cella per caricare tabelle Delta in dataframe per i passaggi di aggregazione che seguono.
Esegui questa cella e attendi il completamento prima di passare al passaggio successivo.
Cella 5 - Crea
aggregate_sale_by_date_city. Questa cella unisce i dati di vendita, data e città, quindi crea la tabella di aggregazione a livello di città.Esegui questa cella e attendi il completamento prima di passare al passaggio successivo.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Cella 6 - Crea
aggregate_sale_by_date_employee. Questo campo unisce i dati di vendita, data e dipendente, quindi crea la tabella aggregata per livello di dipendente.Esegui questa cella e attendi il completamento prima di passare al passaggio successivo.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Per convalidare le tabelle create, fare clic con il pulsante destro del mouse sul lakehouse wwilakehouse nella finestra di esplorazione e quindi scegliere Aggiorna. Appaiono le tabelle di aggregazione.

Questa guida scrive i dati come file Delta Lake. Fabric individua e registra automaticamente queste tabelle nel metastore, quindi non è necessario eseguire istruzioni separate CREATE TABLE .