Come configurare Istanza gestita di SQL di Azure nell'attività di copia
Questo articolo illustra come usare l'attività di copia nella pipeline di dati per copiare dati da e in Istanza gestita di SQL di Azure.
Configurazione supportata
Per la configurazione di ogni scheda nell'attività di copia, passare rispettivamente alle sezioni seguenti.
- generale
- origine
- Destinazione
- mappatura
- Impostazioni
Generale
Fare riferimento alle linee guida per le impostazioni generali per configurare la scheda delle Impostazioni Generali.
Fonte
Le proprietà seguenti sono supportate per Istanza SQL Gestita di Azure nella scheda origine di un'attività di copia.
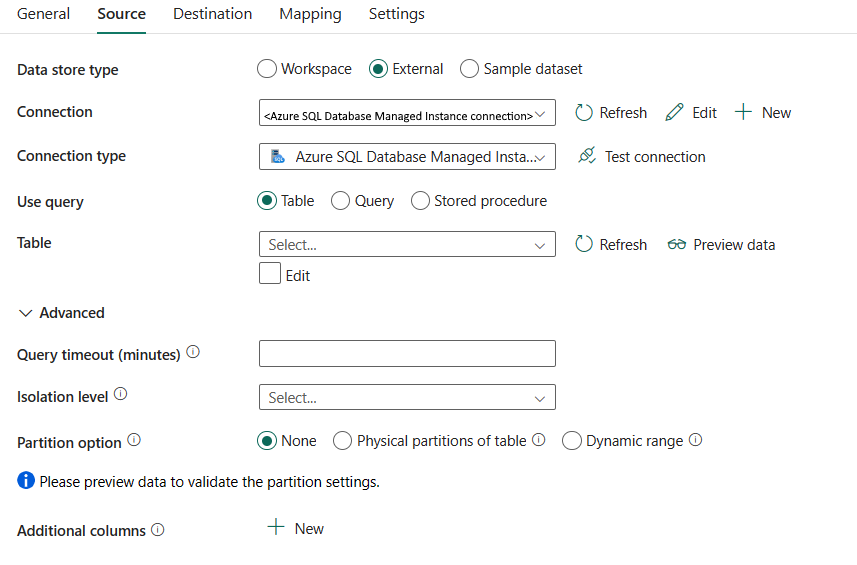
Le proprietà seguenti sono necessarie:
tipo di archivio dati: selezionare esterno.
Connessione: selezionare una connessione a Istanza gestita di SQL di Azure dall'elenco delle connessioni. Se la connessione non esiste, creare una nuova connessione a Istanza gestita di SQL di Azure selezionando Nuovo.
Tipo di connessione: selezionare Istanza gestita di SQL di Azure.
Usarequery: specificare il modo in cui leggere i dati. È possibile scegliere Tabella, Queryo Stored Procedure. L'elenco seguente descrive la configurazione di ogni impostazione:
Table: legge i dati dalla tabella specificata. Selezionare la tabella di origine dall'elenco a discesa oppure selezionare Modifica per immetterla manualmente.
query: specificare la query SQL personalizzata per leggere i dati. Un esempio è
select * from MyTable. In alternativa, selezionare l'icona a forma di matita da modificare nell'editor di codice.
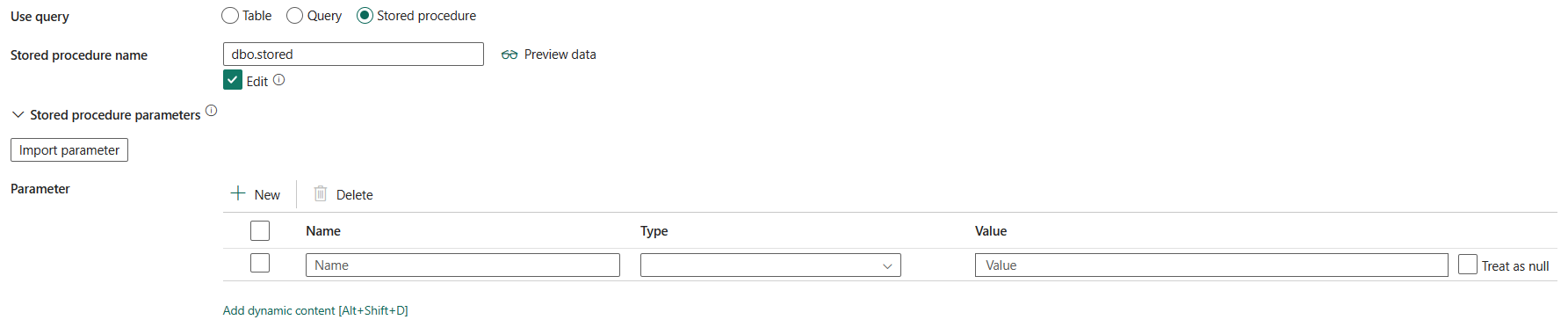
Stored Procedure: Usare la Stored Procedure che legge i dati dalla tabella di origine. L'ultima istruzione SQL deve essere un'istruzione SELECT nella stored procedure.
Nome della stored procedure: Seleziona la stored procedure o specifica manualmente il nome della stored procedure quando selezioni Modifica per leggere i dati dalla tabella di origine.
Parametri della stored procedure: Fornire i valori per i parametri della stored procedure. I valori consentiti sono coppie nome o valore. I nomi e le maiuscole/minuscole dei parametri devono corrispondere ai nomi e alla combinazione di maiuscole e minuscole dei parametri della stored procedure. Puoi selezionare Importa parametri per visualizzare i parametri della stored procedure.
In advancedè possibile specificare i campi seguenti:
timeout query (minuti): specificare il timeout per l'esecuzione del comando di query, il valore predefinito è 120 minuti. Se per questa proprietà è impostato un parametro, i valori consentiti sono timepan, ad esempio "02:00:00" (120 minuti).
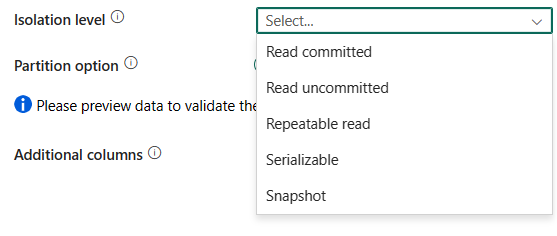
livello di isolamento: specifica il comportamento di blocco delle transazioni per l'origine SQL. I valori consentiti sono: Read committed, Read uncommitted, Repeatable read, Serializable, Snapshot. Se non specificato, viene utilizzato il livello di isolamento predefinito del database. Per ulteriori dettagli, fare riferimento a IsolationLevel Enum.
Opzione Partizione: Specificare le opzioni di partizionamento dei dati usate per caricare i dati da Azure SQL Managed Instance. I valori consentiti sono: Nessuna (impostazione predefinita), Partizioni fisiche della tabellae Intervallo dinamico. Quando un'opzione di partizione è abilitata (ovvero non Nessuna), il grado di parallelismo per caricare simultaneamente i dati da Azure SQL Managed Instance è controllato da Grado di parallelismo della copia nella scheda delle impostazioni dell'attività di copia.
Nessuna: scegliere questa impostazione per non usare una partizione.
partizioni fisiche della tabella: quando si usa una partizione fisica, la colonna e il meccanismo di partizione vengono determinati automaticamente in base alla definizione della tabella fisica.
intervallo dinamico: quando si utilizza una query con parallelismo abilitato, è necessario il parametro di partizione del range(
?DfDynamicRangePartitionCondition). Query di esempio:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Nome colonna partizione: specificare il nome della colonna di origine del tipo integer o date/datetime (
int,smallint,bigint,date,smalldatetime,datetime,datetime2odatetimeoffset) utilizzato per il partizionamento degli intervalli nella copia parallela. Se non specificato, l'indice o la chiave primaria della tabella vengono rilevati automaticamente e usati come colonna di partizione.Se si usa una query per recuperare i dati di origine, associare
?DfDynamicRangePartitionConditionnella clausola WHERE. Per un esempio, fare riferimento alla sezione Copia parallela dall'istanza gestita di SQL di Azure.Limite superiore della partizione: specificare il valore massimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride della partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività di copia rileva automaticamente il valore. Per un esempio, vedere la sezione Copia parallela da Istanza SQL gestita di Azure.
limite inferiore della partizione: specificare il valore minimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride della partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività di copia rileva automaticamente il valore. Per un esempio, vedere la sezione Copia parallela da Azure SQL Istanza gestita.
Colonne aggiuntive: aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. L'espressione è supportata per quest'ultima.
Si notino i punti seguenti:
- Se Query viene specificata per l'origine, l'attività di copia esegue questa query sull'origine dell'istanza SQL gestita di Azure per ottenere i dati. È anche possibile specificare una stored procedure specificando nome stored procedure e parametri della stored procedure se la stored procedure accetta parametri.
- Quando si usa la stored procedure nell'origine per recuperare i dati, si noti se la stored procedure è progettata come restituzione di uno schema diverso quando viene passato un valore di parametro diverso, è possibile che si verifichi un errore o si verifichi un risultato imprevisto durante l'importazione dello schema dall'interfaccia utente o quando si copiano dati nel database SQL con la creazione automatica della tabella.
Destinazione
Le seguenti proprietà sono supportate per Istanza gestita di SQL di Azure nella scheda destinazione di un'attività di copia.
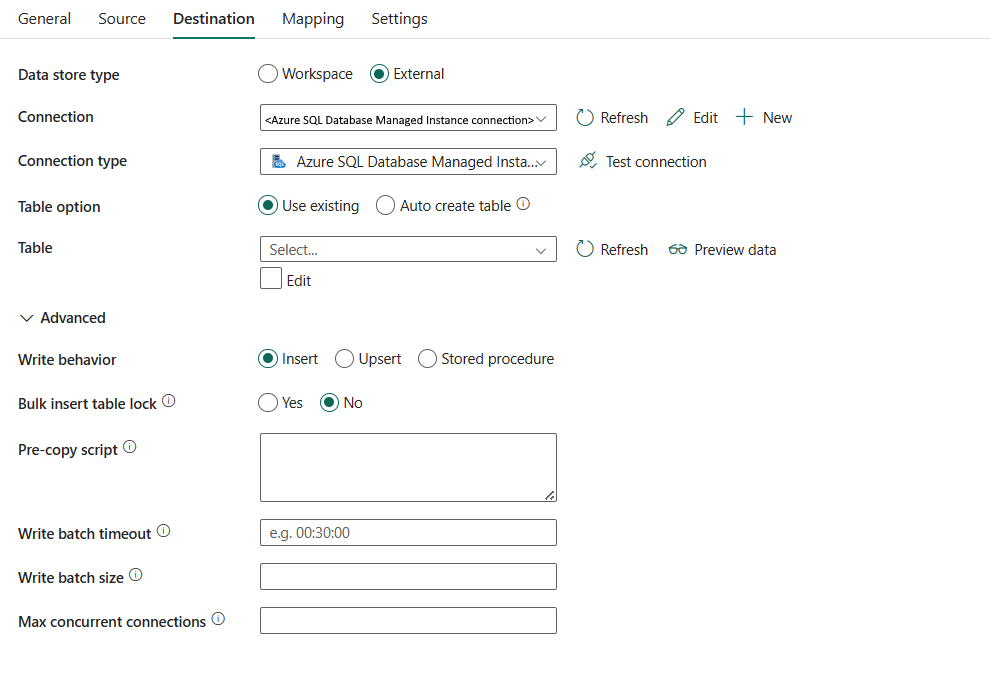
Le proprietà seguenti sono necessarie:
tipo di archivio dati: selezionare esterno.
Connessione: selezionare una connessione a Istanza SQL gestita di Azure dall'elenco delle connessioni. Se la connessione non esiste, creare una nuova connessione a Istanza gestita di SQL di Azure selezionando Nuovo.
Tipo di connessione: selezionare Istanza gestita di SQL di Azure.
'opzione Tabella: è possibile scegliere Usare le esistenti per usare la tabella specificata. In alternativa, scegliere Creazione automatica tabella per creare automaticamente una tabella di destinazione se la tabella non esiste nello schema di origine e si noti che questa selezione non è supportata quando la stored procedure viene usata come comportamento di scrittura.
Se si seleziona Usaesistente:
- Tabella: selezionare la tabella nel database di destinazione dall'elenco a discesa. In alternativa, selezionare Modifica per immettere manualmente il nome della tabella.
Se si seleziona: Creazione automatica tabella:
- tabella: specificare il nome per la tabella di destinazione creata automaticamente.
In advancedè possibile specificare i campi seguenti:
Comportamento di scrittura: definisce il comportamento di scrittura quando l'origine è file da un archivio dati basato su file. È possibile scegliere Inserisci, **Upsert o Stored Procedure.
Inserisci: scegliere questa opzione per usare il comportamento di inserimento della scrittura per caricare i dati in Azure SQL Managed Instance.
Upsert: scegliere questa opzione per usare il comportamento di scrittura upsert per caricare i dati in Istanza gestita SQL di Azure.
Usare tempDB: specificare se usare una tabella temporanea globale o una tabella fisica come tabella provvisoria per upsert. Per impostazione predefinita, il servizio usa la tabella temporanea globale come tabella provvisoria e questa proprietà è selezionata.
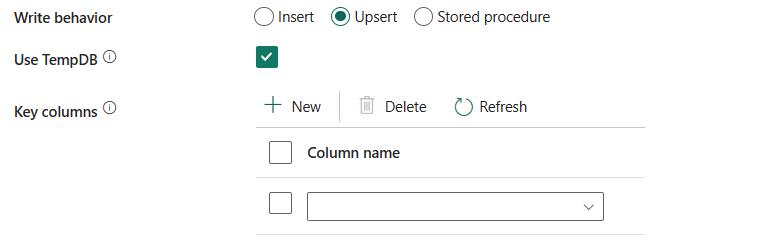
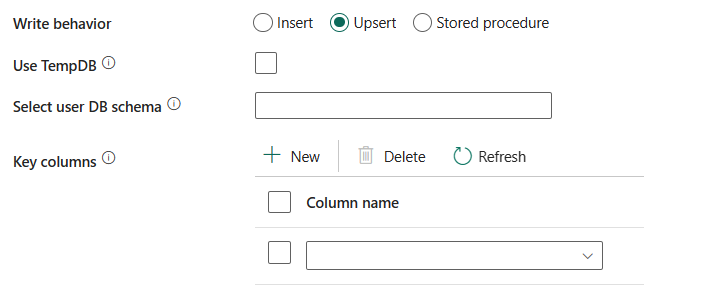
Selezionare lo schema del database utente: quando l'Usa TempDB non è selezionata, specificare lo schema provvisorio per la creazione di una tabella provvisoria se viene usata una tabella fisica.
Nota
È necessario disporre dell'autorizzazione per la creazione e l'eliminazione di tabelle. Per impostazione predefinita, una tabella provvisoria condividerà lo stesso schema di una tabella di destinazione.
Colonne chiave: specificare i nomi di colonna per l'identificazione univoca delle righe. È possibile usare una singola chiave o una serie di chiavi. Se non specificato, viene usata la chiave primaria.
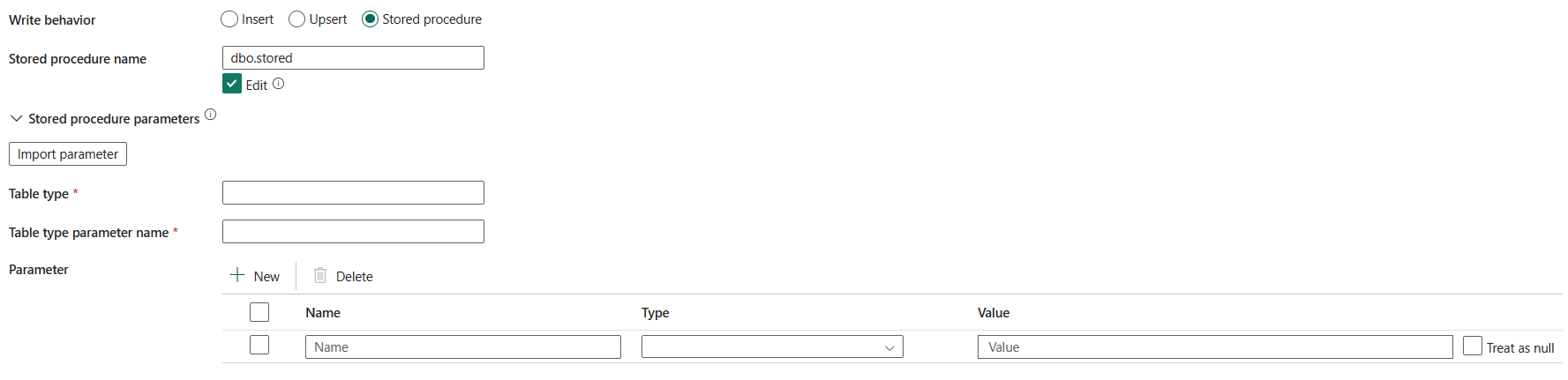
*stored procedure*: utilizzare la *stored procedure* che definisce come applicare i dati di origine a una tabella di destinazione. Questa stored procedure viene richiamata per batch. Per operazioni eseguite una sola volta che non hanno nulla a che fare con i dati di origine, ad esempio eliminare o troncare, utilizzare la proprietà di script di pre-copia .
Nome stored procedure: Selezionare la stored procedure o specificare manualmente il nome della stored procedure nell'ambito del controllo del Modifica per leggere i dati dalla tabella di origine.
Parametri della Stored Procedure:
- Tipo di tabella: specificare il nome del tipo di tabella da utilizzare nella stored procedure. L'attività di copia rende i dati spostati disponibili in una tabella temporanea con questo tipo di tabella. Il codice della stored procedure può quindi unire i dati copiati con i dati esistenti.
- Nome parametro tipo di tabella; Specificare il nome del parametro del tipo di tabella specificato nella procedura memorizzata.
- Parametri: Specificare i valori per i parametri della procedura memorizzata. I valori consentiti sono coppie nome o valore. I nomi e la combinazione di maiuscole e minuscole dei parametri devono corrispondere ai nomi e alla stessa combinazione dei parametri della stored procedure. È possibile selezionare Importa parametri per ottenere i parametri della procedura memorizzata.
Blocco di tabella per inserimento massivo: Scegliere Sì o No (impostazione predefinita). Utilizzare questa impostazione per migliorare le prestazioni di copia dei dati durante un'operazione di inserimento massivo in una tabella senza indici da più clienti. È possibile specificare questa proprietà quando si seleziona Inserisci o Upsert come comportamento di scrittura. Per altre informazioni, vedere BULK INSERT (Transact-SQL)
Script di Pre-Copia: specificare uno script per l'operazione di copia da eseguire prima di scrivere dati in una tabella di destinazione ad ogni esecuzione. È possibile utilizzare questa proprietà per pulire i dati precaricati.
timeout batch di scrittura: specificare il tempo di attesa per il completamento dell'operazione di inserimento batch prima del timeout. Il valore consentito è intervallo di tempo. Se non viene specificato alcun valore, per impostazione predefinita il timeout è "02:00:00".
Dimensione del batch di scrittura: Specificare il numero di righe da inserire nella tabella SQL per batch. Il valore consentito è integer (numero di righe). Per impostazione predefinita, il servizio determina in modo dinamico le dimensioni del batch appropriate in base alle dimensioni della riga.
Numero massimo di connessioni simultanee: limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee.
Mappatura
Per la configurazione della scheda Mapping , se non applichi Azure SQL Managed Instance con l'opzione di creazione automatica della tabella come destinazione, vai a Mapping.
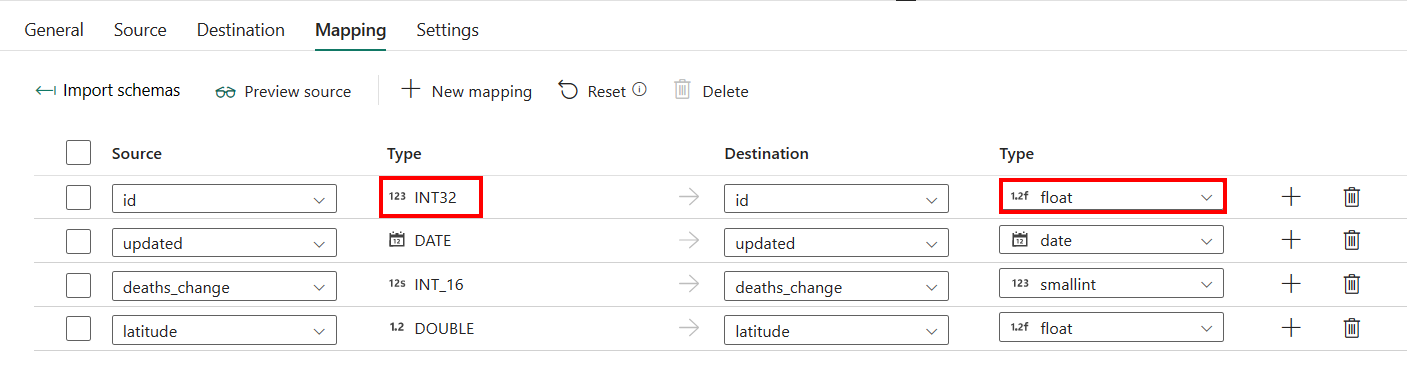
Se si utilizza Azure SQL Managed Instance con la funzionalità di creazione automatica delle tabelle come destinazione, ad eccezione della configurazione in Mapping, è possibile modificare il tipo per le colonne di destinazione. Dopo aver selezionato Importa schemi, è possibile specificare il tipo di colonna nella destinazione.
Ad esempio, il tipo per ID colonna nell'origine è int ed è possibile modificarlo in tipo float quando si esegue il mapping alla colonna di destinazione.
Impostazioni
Per Configurazione della scheda Impostazioni, passare a Configurare le altre impostazioni nella scheda delle Impostazioni.
Copia parallela da Istanza SQL gestita di Azure
Il connettore Istanza gestita di SQL di Azure nell'attività di copia fornisce il partizionamento dei dati predefinito per copiare i dati in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella scheda Source dell'attività di copia.
Quando si abilita la copia partizionata, l'attività di copia esegue query parallele sull'origine dell'istanza gestita di SQL di Azure per caricare i dati in base alle partizioni. Il grado parallelo è controllato dal grado di parallelismo di copia nella scheda delle impostazioni dell'attività di copia. Ad esempio, se si imposta grado di parallelismo di copia su quattro, il servizio genera e esegue simultaneamente quattro query in base all'opzione e alle impostazioni di partizione specificate e ogni query recupera una parte di dati dall'istanza gestita di SQL di Azure.
È consigliabile abilitare la copia parallela con il partizionamento dei dati, soprattutto quando si caricano grandi quantità di dati dall'istanza gestita di SQL di Azure. Di seguito sono riportate le configurazioni consigliate per diversi scenari. Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come più file (specificare solo il nome della cartella), nel qual caso le prestazioni sono migliori rispetto alla scrittura in un singolo file.
| Scenario | Impostazioni suggerite |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni, con partizioni fisiche. |
opzione Partizione: Partizioni fisiche della tabella. Durante l'esecuzione, il servizio rileva automaticamente le partizioni fisiche e copia i dati in base alle partizioni. Per verificare se la tabella include o meno una partizione fisica, è possibile fare riferimento a questa query. |
| Caricamento completo da una tabella di grandi dimensioni, senza partizioni fisiche, ma con una colonna integer o datetime utilizzata per il partizionamento dei dati. |
opzioni di partizione: partizione di intervallo dinamico. colonna Partizione (facoltativo): specificare la colonna usata per partizionare i dati. Se non specificato, viene utilizzata la colonna di indice o chiave primaria. Limite superiore della partizione e limite inferiore della partizione (facoltativo): Specificare se si desidera determinare lo stride della partizione. Non si tratta di filtrare le righe nella tabella, tutte le righe della tabella verranno partizionate e copiate. Se non specificato, l'attività di copia rileva automaticamente i valori. Ad esempio, se la colonna di partizione "ID" include valori compresi tra 1 e 100 e si imposta il limite inferiore su 20 e il limite superiore come 80, con copia parallela come 4, il servizio recupera i dati per 4 partizioni- ID nell'intervallo <=20, [21, 50], [51, 80], e >=81 rispettivamente. |
| Caricare una grande quantità di dati usando una query personalizzata, senza partizioni fisiche, ma utilizzando una colonna integer o di tipo date/datetime per il partizionamento dei dati. |
opzioni di partizione: partizione di intervallo dinamico. query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.colonna Partizione: specificare la colonna usata per partizionare i dati. limite superiore della partizione e limite inferiore della partizione (facoltativo): specificare se si desidera determinare lo stride della partizione. Questo non è per filtrare le righe nella tabella, tutte le righe nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività di copia rileva automaticamente il valore. Ad esempio, se la colonna di partizione "ID" include valori compresi tra 1 e 100 e si imposta il limite inferiore su 20 e il limite superiore come 80, con copia parallela come 4, il servizio recupera i dati rispettivamente per 4 partizioni- ID nell'intervallo <=20, [21, 50], [51, 80], e >=81. Di seguito sono riportate altre query di esempio per diversi scenari: • Eseguire una query sull'intera tabella: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Eseguire una query da una tabella con la selezione di colonne e filtri aggiuntivi di clausola where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Query con sottoquery: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Eseguire query con partizione nella sottoquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedure consigliate per caricare i dati con l'opzione di partizione:
- Scegliere una colonna distintiva come colonna di partizione (ad esempio chiave primaria o chiave univoca) per evitare l'asimmetria dei dati.
- Se la tabella include una partizione predefinita, usare l'opzione di partizione Partizioni fisiche della tabella per ottenere prestazioni migliori.
Query di esempio per controllare la partizione fisica
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Se la tabella ha una partizione fisica, viene visualizzato "HasPartition" come "sì" come illustrato di seguito.

Riepilogo tabella
Vedere la tabella seguente per il riepilogo e altre informazioni sull'attività di copia di Istanza gestita di SQL di Azure.
Informazioni sull'origine
| Nome | Descrizione | Valore | Obbligatorio | Proprietà script JSON |
|---|---|---|---|---|
| tipo di archivio dati | Tipo di archivio dati. | esterni | Sì | / |
| Connessione | Connessione all'archivio dati di origine. | < la tua connessione > | Sì | connessione |
| Tipo di connessione | Tipo di connessione. Selezionare Istanza SQL gestita di Azure. | Istanza SQL gestita di Azure | Sì | / |
| Usare la query | Query SQL personalizzata per leggere i dati. | • Tavolo •Quesito • Procedura memorizzata |
Sì | / |
| Tabella | Tabella dati di origine. | < nome della tua tabella> | No | schema tabella |
| query | Query SQL personalizzata per leggere i dati. | < > della query | No | sqlReaderQuery |
| nome della stored procedure | Questa proprietà è il nome della stored procedure che legge i dati dalla tabella di origine. L'ultima istruzione SQL deve essere un'istruzione SELECT nella stored procedure. | < nome della stored procedure > | No | sqlReaderStoredProcedureName |
| parametro della procedura memorizzata | Questi parametri sono per la procedura memorizzata. I valori consentiti sono coppie nome o valore. I nomi e il formato dei parametri devono corrispondere ai nomi e al formato dei parametri della stored procedure. | < coppie nome-valore > | No | parametriDellaProceduraMemorizzata |
| timeout della query | Timeout per l'esecuzione del comando di query. | intervallo di tempo (il valore predefinito è 120 minuti) |
No | queryTimeout |
| livello di isolamento | Specifica il comportamento di blocco delle transazioni per l'origine SQL. | • Lettura confermata • Leggi non confermati • Lettura ripetibile •Serializzabile •Istantanea |
No | livelloDiIsolamento • ReadCommitted • ReadUncommitted (Lettura non confermata) • RepeatableRead (Lettura Ripetibile) •Serializzabile •Istantanea |
| Opzione partizione | Le opzioni di partizionamento dei dati usate per caricare i dati da Istanza gestita di SQL di Azure. | • Nessuno (impostazione predefinita) • Partizioni fisiche della tabella • Intervallo dinamico |
No | partitionOption: • Nessuno (impostazione predefinita) • PartizioniFisicheDellaTabella • DynamicRange |
| nome colonna della partizione | Il nome della colonna di origine nel tipo integer o date/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2o datetimeoffset) usato dal partizionamento della gamma per la copia parallela. Se non specificato, l'indice o la chiave primaria della tabella vengono rilevati automaticamente e usati come colonna di partizione. Se si usa una query per recuperare i dati di origine, associare ?DfDynamicRangePartitionCondition nella clausola WHERE. |
< i nomi delle tue colonne di partizione > | No | partitionColumnName |
| limite superiore della partizione | Valore massimo della colonna di partizione utilizzata per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride della partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività di copia rileva automaticamente il valore. | < limite superiore della partizione > | No | partitionUpperBound |
| limite inferiore della partizione | Valore minimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride della partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività di copia rileva automaticamente il valore. | < limite inferiore della partizione > | No | partitionLowerBound |
| colonne aggiuntive | Aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. L'espressione è supportata per quest'ultima. | •Nome •Valore |
No | colonne aggiuntive •nome •valore |
Informazioni sulla destinazione
| Nome | Descrizione | Valore | Obbligatorio | Proprietà script JSON |
|---|---|---|---|---|
| tipo di archivio dati | Tipo di archivio dati. | esterni | Sì | / |
| Connessione | Connessione all'archivio dati di destinazione. | < la tua connessione > | Sì | connessione |
| Tipo di connessione | Tipo di connessione. Selezionare Istanza SQL Gestita di Azure. | Istanza gestita di Azure SQL | Sì | / |
| opzione tabella | Specifica se creare automaticamente la tabella di destinazione se non esiste in base allo schema di origine. | • Usa esistente • Creazione automatica tabella |
Sì | tableOption: • Creazione automatica |
| Tabella | Tabella dei dati di destinazione. | <nome della tua tabella> | Sì | schema tavolo |
| comportamento di scrittura | Il comportamento di scrittura per l'attività di copia per caricare i dati nel database dell’Istanza SQL gestita di Azure. | •Inserire • Upsert • Procedura memorizzata |
No | writeBehavior: • inserire • aggiorna o inserisci sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureTableTypeParameterName, storedProcedureParameters |
| Usare TempDB | Indica se utilizzare la tabella temporanea globale o la tabella fisica come tabella provvisoria per upsert. | selezionato (impostazione predefinita) o deselezionato | No | useTempDB: true (impostazione predefinita) o false |
| Selezionare lo schema del database dell'utente | Schema provvisorio per la creazione di una tabella provvisoria se viene utilizzata la tabella fisica. Nota: l'utente deve disporre dell'autorizzazione per la creazione e l'eliminazione di una tabella. Per impostazione predefinita, la tabella provvisoria condividerà lo stesso schema della tabella di destinazione. Applicare quando non si seleziona Usare TempDB. | selezionato (impostazione predefinita) o deselezionato | No | interimSchemaName |
| colonne chiave | Nomi di colonna per l'identificazione univoca delle righe. È possibile usare una singola chiave o una serie di chiavi. Se non specificato, viene usata la chiave primaria. | < la colonna chiave> | No | Chiavi |
| nome procedura memorizzata | Nome della stored procedure che definisce come applicare i dati di origine in una tabella di destinazione. Questa stored procedure viene richiamata per batch. Per le operazioni che vengono eseguite una sola volta e che non hanno nulla a che fare con i dati di origine, ad esempio eliminare o troncare, utilizzare la proprietà script di pre-copia. | < il nome della stored procedure > | No | sqlWriterStoredProcedureName |
| tipo di tabella | Nome del tipo di tabella da utilizzare nella procedura memorizzata. L'attività di copia rende i dati spostati disponibili in una tabella temporanea con questo tipo di tabella. Il codice della stored procedure può quindi unire i dati copiati con i dati esistenti. | < il nome del tuo tipo di tabella > | No | sqlWriterTableType |
| nome del parametro del tipo di tabella | Nome del parametro del tipo di tabella specificato nella stored procedure. | < il nome del parametro del tipo di tabella > | No | NomeParametroTipoTabellaProceduraMemorizzata |
| Parametri | Parametri per la procedura memorizzata. I valori consentiti sono coppie nome e valore. I nomi e l'uso di maiuscole/minuscole dei parametri devono corrispondere ai nomi e all'uso di maiuscole/minuscole dei parametri della procedura memorizzata. | < coppie di nome e valore > | No | parametriProceduraArchiviata |
| blocco inserimento bulk tabella | Utilizzare questa impostazione per migliorare le prestazioni di copia durante un'operazione di inserimento massivo in una tabella senza indice da più client. | Sì o No (impostazione predefinita) | No | sqlWriterUseTableLock: true o false (impostazione predefinita) |
| script di pre-copia | Script per l'esecuzione dell'attività di copia prima di scrivere dati in una tabella di destinazione in ogni esecuzione. È possibile utilizzare questa proprietà per pulire i dati precaricati. | script di pre-copia <> (string) |
No | preCopyScript |
| Timeout di scrittura batch | Il tempo di attesa per il completamento dell'operazione di inserimento in batch prima del timeout. | intervallo di tempo Il valore predefinito è "02:00:00") |
No | writeBatchTimeout |
| scrivi dimensione batch | Numero di righe da inserire nella tabella SQL per batch. Per impostazione predefinita, il servizio determina in modo dinamico le dimensioni del batch appropriate in base alle dimensioni della riga. |
< numero di righe > (intero) |
No | writeBatchSize |
| Numero massimo di connessioni simultanee | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. |
< limite massimo di connessioni simultanee > (intero) |
No | maxConcurrentConnections |