Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In una pipeline è possibile usare l'attività Copia per copiare dati tra archivi dati nel cloud. Dopo aver copiato i dati, è possibile usare altre attività nella pipeline per trasformarli e analizzarli.
L'attività Copia si connette alle origini dati e alle destinazioni, quindi sposta i dati in modo efficiente tra di essi. Ecco come il servizio gestisce il processo di copia:
- Si connette all'origine: crea una connessione sicura per leggere i dati dall'archivio dati di origine.
- Elabora i dati: gestisce la serializzazione/deserializzazione, la compressione/decompressione, il mapping delle colonne e le conversioni dei tipi di dati in base alla configurazione.
- Scrive verso la destinazione: trasferisce i dati elaborati nel tuo archivio dati di destinazione.
- Fornisce il monitoraggio: tiene traccia dell'operazione di copia e fornisce log dettagliati e metriche per la risoluzione dei problemi e l'ottimizzazione.
Tip
Se è sufficiente copiare i dati e non sono necessarie trasformazioni, un processo di copia potrebbe essere un'opzione migliore. I processi di copia offrono un'esperienza semplificata per gli scenari di spostamento dei dati che non richiedono la creazione di una pipeline completa. Consulta: la panoramica del lavoro di copia o usa la tabella decisionale per confrontare l'attività di copia e il lavoro di copia.
Prerequisites
Per iniziare, è necessario completare questi prerequisiti:
- Un account tenant Microsoft Fabric con una sottoscrizione attiva. Creare un account gratuitamente.
- Area di lavoro abilitata con Microsoft Fabric.
Aggiungere un'attività di copia utilizzando l'assistente di copia
Seguire questa procedura per configurare l'attività di copia utilizzando l'assistente copia.
Inizia con l'assistente di copia
Aprire una pipeline esistente o creare una nuova pipeline.
Selezionare Copia dati nell'area di lavoro per aprire lo strumento Assistente Copia e per iniziare. In alternativa, selezionare Usa assistente copia dall'elenco a discesa Copia dati nella scheda Attività della barra multifunzione.
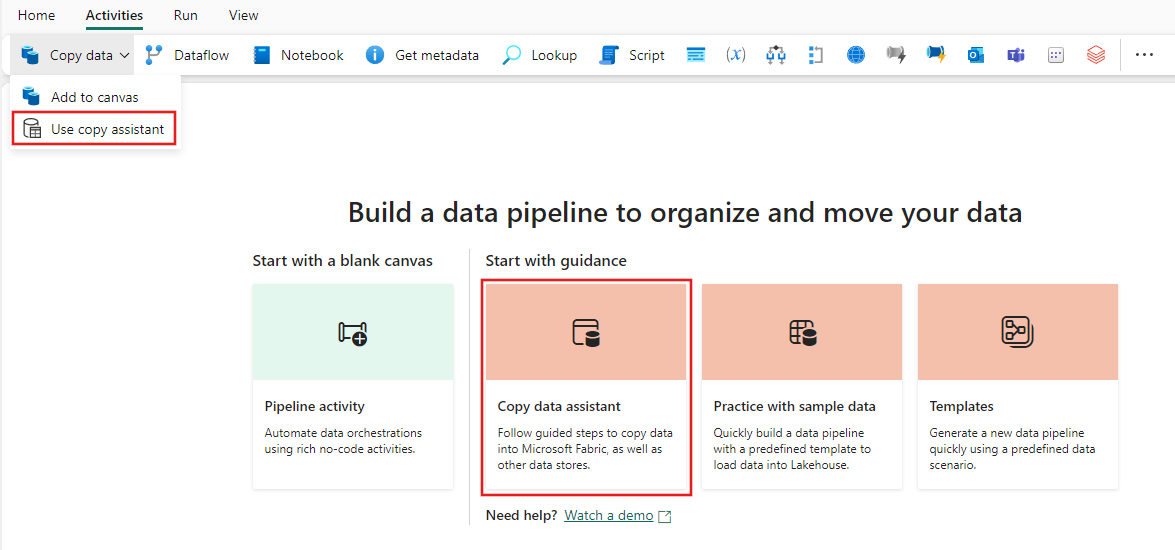

Configura la tua sorgente
Seleziona un tipo di origine dati dalla categoria. Userai l'archiviazione BLOB di Azure come esempio. Seleziona Archiviazione BLOB di Azure.
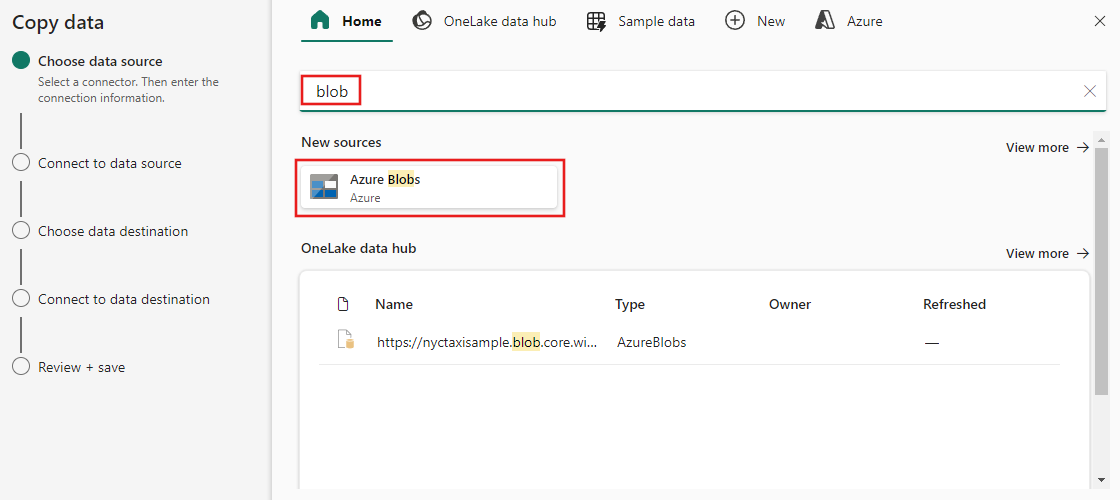
Creare una connessione con l'origine dati selezionando Crea nuova connessione.
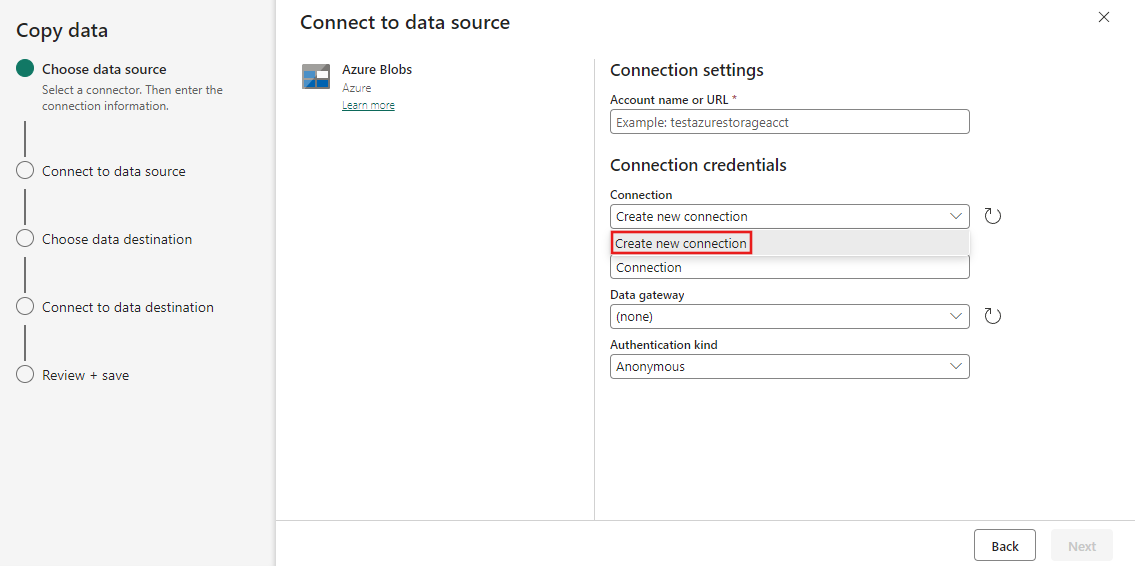
Dopo aver selezionato Crea nuova connessione, compilare le informazioni di connessione richieste, poi selezionare Avanti. Per i dettagli sulla creazione delle connessioni per ciascun tipo di origine dati, si rimanda ai vari articoli connettore.
Se si dispone già di connessioni, è possibile selezionare Connessione esistente e selezionare la connessione dall'elenco a discesa.
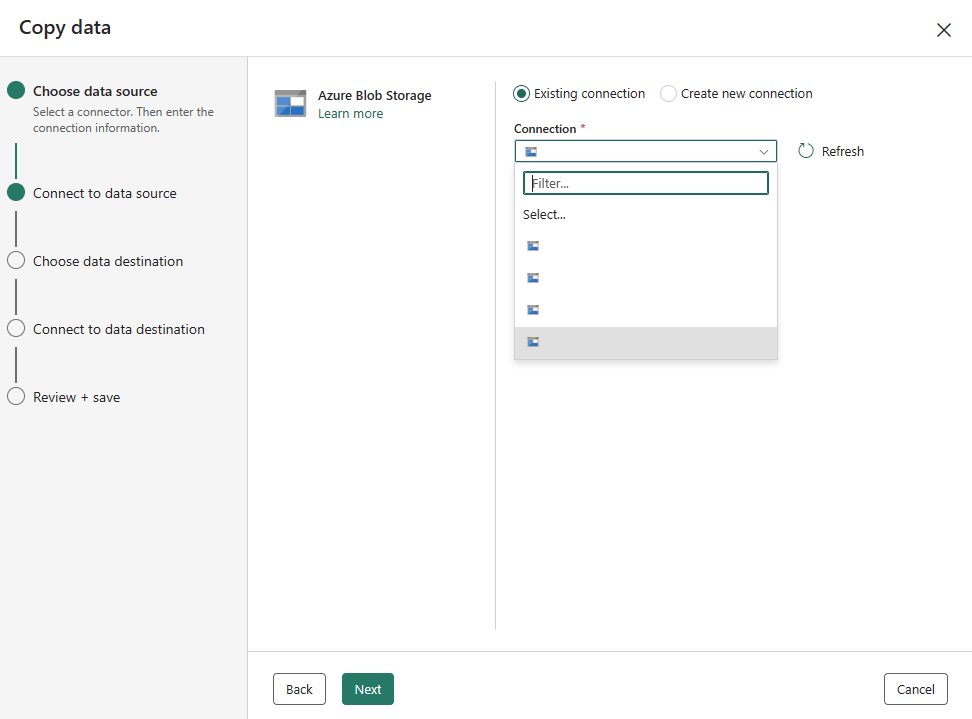
Scegliere il file o la cartella da copiare in questo passaggio di configurazione dell’origine e poi selezionare Avanti.





Configurare la destinazione
Seleziona un tipo di origine dati dalla categoria. Userai l'archiviazione BLOB di Azure come esempio. È possibile creare una nuova connessione per collegarsi a un nuovo account di Archiviazione BLOB di Azure seguendo la procedura indicata nella sezione precedente, oppure utilizzare una connessione esistente selezionandola dall'elenco a discesa delle connessioni. Le funzionalità Test connessione e Modifica sono disponibili per ogni connessione selezionata.
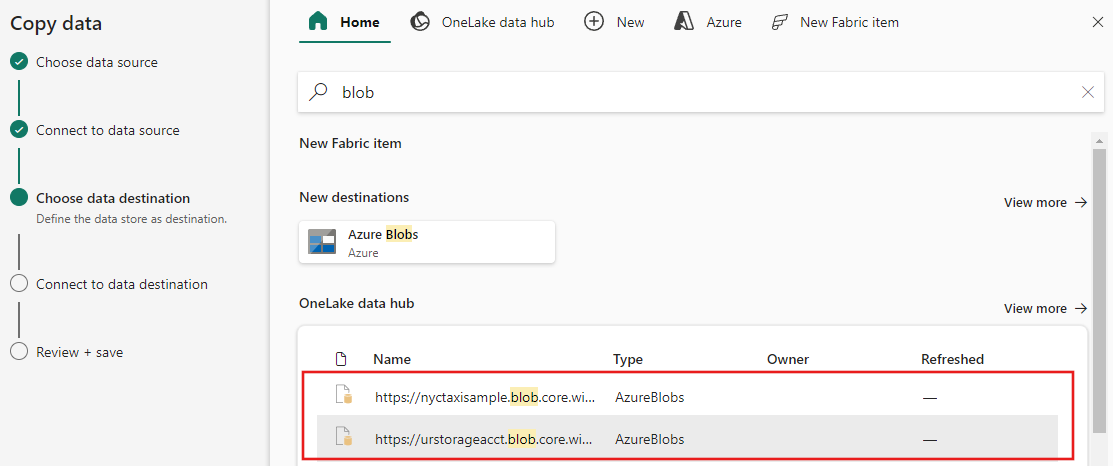
Configura e associa i dati di origine alla destinazione. Poi selezionare Avanti per completare le configurazioni di destinazione.
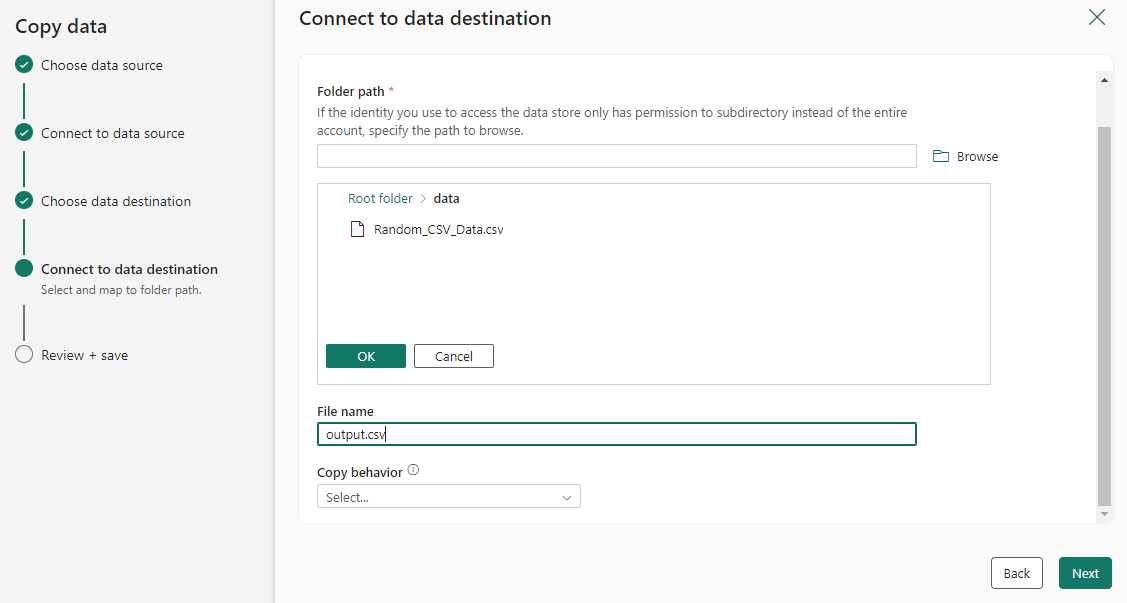
Note
È possibile usare un singolo gateway dati locale solo nella stessa attività di copia. Se sia l'origine che il sink sono origini dati locali, è necessario usare lo stesso gateway. Per spostare i dati tra origini dati locali con gateway diversi, è necessario copiare utilizzando il primo gateway verso un'origine cloud intermedia in un'unica attività di copia. Successivamente, è possibile utilizzare un'altra operazione di copia per copiarla dall'origine cloud intermedia utilizzando il secondo gateway.



Esamina e crea la tua attività di copia
Esamina le impostazioni dell'attività di copia nei passaggi precedenti e seleziona OK per completare. In alternativa, è possibile tornare ai passaggi precedenti per modificare, se necessario, le impostazioni nello strumento.


Al termine, l'attività di copia verrà quindi aggiunta all'area di lavoro della pipeline. Tutte le impostazioni, incluse le impostazioni avanzate per l’attività Copia, sono disponibili nelle schede quando l’attività è selezionata.

È ora possibile salvare la pipeline con questa singola attività di copia o continuare a progettare la pipeline.
Aggiungere direttamente un'attività Copia
Seguire i seguenti passaggi per aggiungere direttamente un'attività di copia.
Aggiungere un'attività copia
Aprire una pipeline esistente o creare una nuova pipeline.
Aggiungere un'attività di copia selezionando Aggiungi attività alla pipeline>Attività di copia oppure selezionando Copia dati>Aggiungi all'area di lavoro sotto la scheda Attività.


Configurare le impostazioni generali nella scheda Generale
Per informazioni su come configurare le impostazioni generali, si veda Generale.
Configurare la tua origine nella scheda Origine
In Connessione selezionare una connessione esistente o selezionare Altro per creare una nuova connessione.
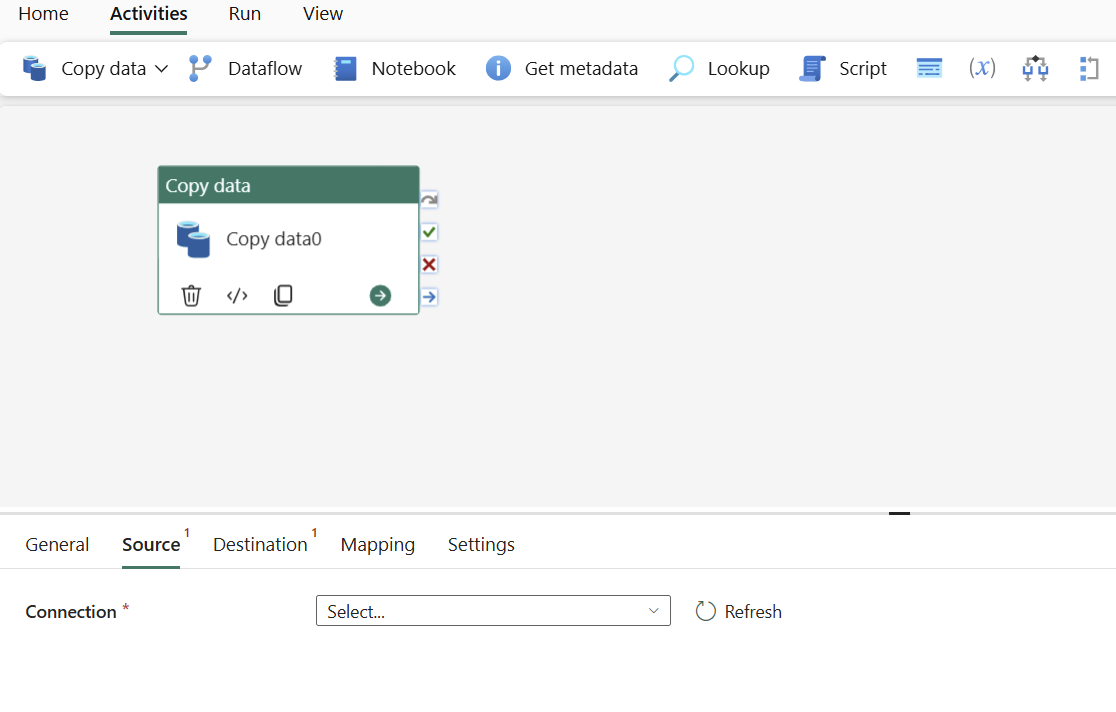
Scegliere il tipo di origine dati dalla finestra popup. In questo esempio verrà usato il database SQL di Azure. Selezionare Database SQL di Azure e quindi selezionare Continua.

Si passa alla pagina di creazione della connessione. Inserire le informazioni di connessione richieste nel pannello, quindi selezionare Crea. Per i dettagli sulla creazione delle connessioni per ciascun tipo di origine dati, si rimanda ai vari articoli connettore.
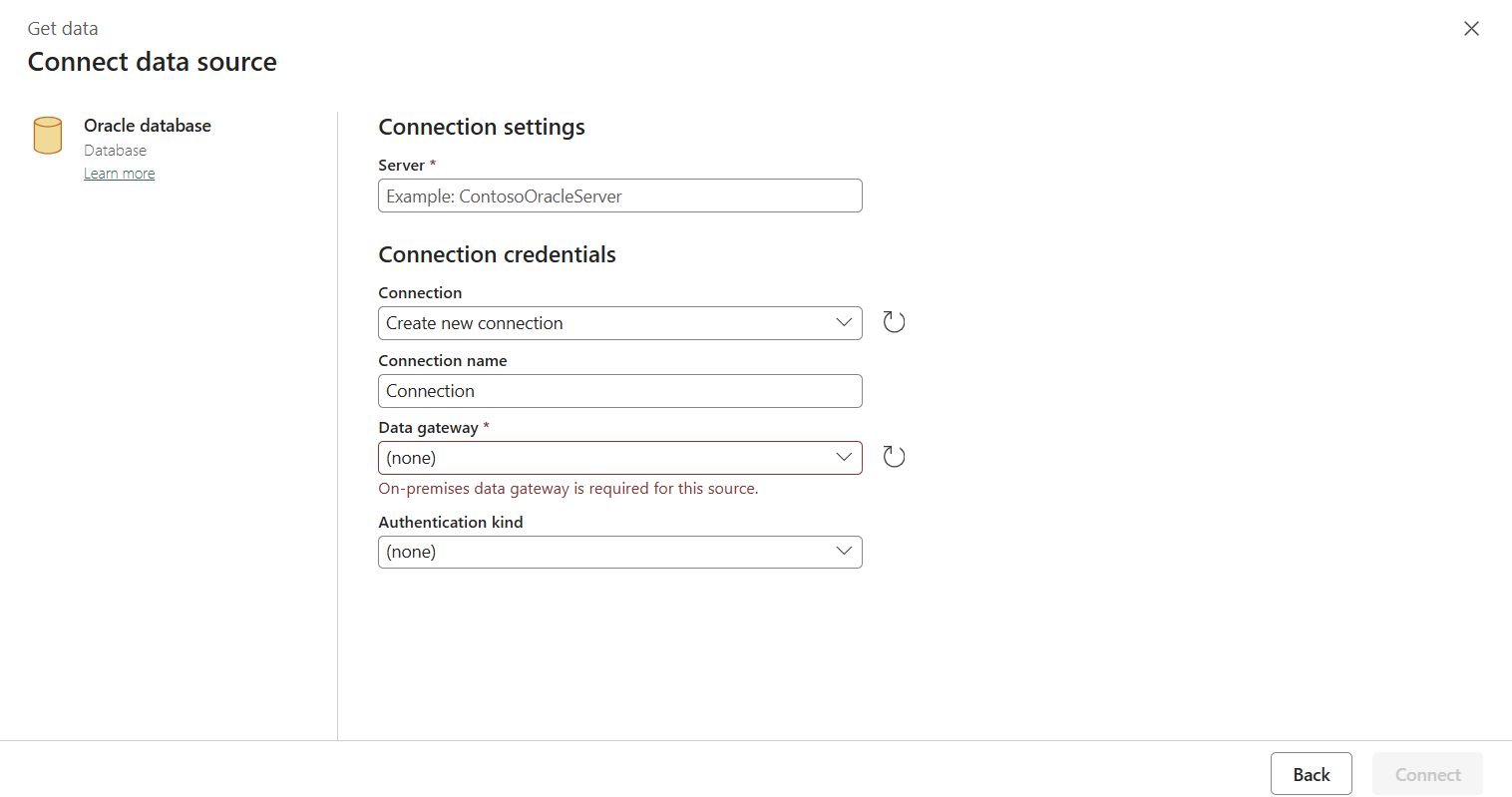
Dopo aver creato la connessione, viene visualizzata nuovamente la pagina della pipeline. Selezionare quindi Aggiorna per ottenere la connessione creata dall'elenco a discesa. È anche possibile scegliere una connessione al database SQL di Azure esistente direttamente dall'elenco a discesa se è già stata creata in precedenza. Le funzionalità Test connessione e Modifica sono disponibili per ogni connessione selezionata. Selezionare poi Database SQL di Azure nel tipo di connessione.
Specificare una tabella da copiare. Selezionare Anteprima dei dati per visualizzare in anteprima la tabella di origine. È anche possibile usare Query e Stored procedure per leggere i dati dall'origine.
Espandi Avanzate per visualizzare impostazioni avanzate, come ad esempio il timeout delle query o il partizionamento. Le impostazioni avanzate variano in base al connettore.



Configurare la destinazione nella scheda destinazione
In Connessione selezionare una connessione esistente oppure selezionare Altro per creare una nuova connessione. Può essere l'archivio dati interno di prima classe dalla tua area di lavoro, come il Lakehouse, o gli archivi dati esterni. In questo esempio si usa Lakehouse.
Dopo aver creato la connessione, viene visualizzata nuovamente la pagina della pipeline. Selezionare quindi Aggiorna per ottenere la connessione creata dall'elenco a discesa. È anche possibile scegliere una connessione Lakehouse esistente dall'elenco a discesa direttamente se è già stata creata in precedenza.
Specificare una tabella o configurare il percorso del file per definire il file o la cartella come destinazione. In questo caso selezionare Tabelle e specificare una tabella per scrivere i dati.
Espandere Avanzate per impostazioni più avanzate, ad esempio le righe massime per file o l'azione tabella. Le impostazioni avanzate variano in base al connettore.
È ora possibile salvare la pipeline con questa attività di copia o continuare a progettare la pipeline.
Configurare i mappaggi nella scheda Mappaggi
Se il connettore usato supporta il mapping, è possibile passare alla scheda Mapping per configurare il mapping.
Selezionare Importa schemi per importare lo schema dei dati.
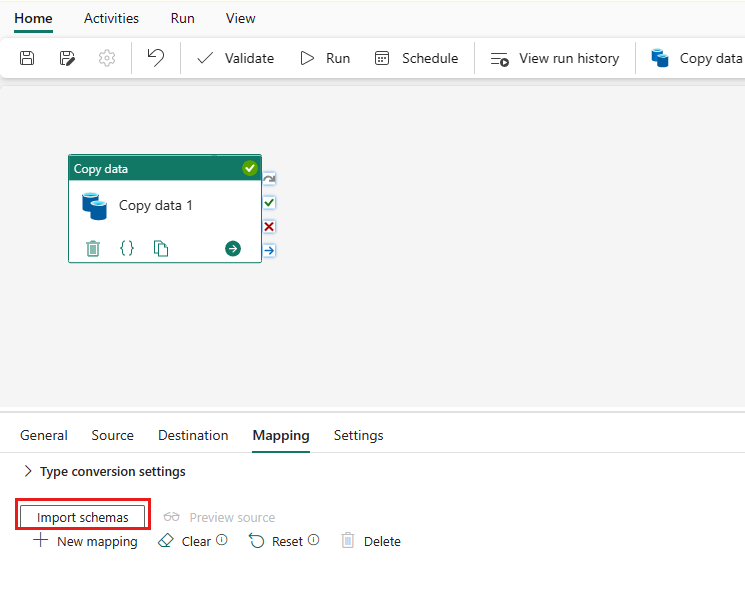
È possibile visualizzare il mapping automatico. Specificare la colonna Origine e la colonna Destinazione. Se si crea una nuova tabella nella destinazione, si può personalizzare il nome della colonna di Destinazione qui. Se si desidera scrivere dati nella tabella di destinazione esistente, non è possibile modificare il nome della colonna di Destinazione esistente. È anche possibile visualizzare il Tipo di colonne di origine e di destinazione.



È anche possibile selezionare + Nuovo mapping per aggiungere nuovo mapping, selezionare Cancella per cancellare tutte le impostazioni di mapping e selezionare Reimposta per reimpostare tutte le colonne origine mapping.
Mappatura del tipo di dati
L'attività di copia nelle pipeline e il processo di copia eseguono il mapping dei tipi di origine ai tipi di destinazione con il seguente flusso:
- Eseguire la conversione da tipi di dati nativi di origine a tipi di dati provvisori usati da Fabric Data Factory.
- Convertire automaticamente il tipo di dati provvisorio in base alle esigenze per trovare le corrispondenze con i tipi di destinazione corrispondenti.
- Eseguire la conversione da tipi di dati provvisori a tipi di dati nativi di destinazione.
L'attività di copia nelle pipeline e il processo copy supportano attualmente i tipi di dati provvisori seguenti: Boolean, Byte, Byte array, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 e UInt64.
Le conversioni dei tipi di dati seguenti sono supportate tra i tipi provvisori dall'origine alla destinazione.
| Source\Destination | Booleano | Matrice di byte | Data/ora | Decimale | Punto mobile | Identificatore Unico Globale (GUID) | Integer | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Booleano | ✓ | ✓ | ✓ | ✓ | |||||
| Matrice di byte | ✓ | ✓ | |||||||
| Data/ora | ✓ | ✓ | |||||||
| Decimale | ✓ | ✓ | ✓ | ✓ | |||||
| Punto mobile | ✓ | ✓ | ✓ | ✓ | |||||
| Identificatore Unico Globale (GUID) | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Date/Time includono DateTime, DateTimeOffset, Data e Ora.
(2) I numeri a punto mobile includono Single e Double.
(3) Integer include SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 e UInt64.
Per informazioni sulle conversioni dettagliate dei tipi di dati per un determinato connettore, vedere l'articolo sulla configurazione dell'attività di copia per tale connettore da qui.
Note
Attualmente questa conversione del tipo di dati è supportata durante la copia tra dati tabulari. Le origini/destinazioni gerarchiche non sono supportate, il che significa che non esiste alcuna conversione del tipo di dati definita dal sistema tra i tipi intermedi di origine e di destinazione.
Configurare le altre impostazioni nella scheda Impostazioni
La scheda Impostazioni contiene le impostazioni per le prestazioni, la gestione temporanea e così via.

Per la descrizione di ciascuna impostazione, si veda la seguente tabella.
| Setting | Description | Proprietà script JSON |
|---|---|---|
| Ottimizzazione intelligente della velocità effettiva | Specificare per ottimizzare la capacità di elaborazione. È possibile scegliere tra: • Auto • Standard • Bilanciato • Massimo Se si sceglie Auto, viene applicata dinamicamente l'impostazione ottimale in base alla coppia origine-destinazione e allo schema dei dati. È anche possibile personalizzare la velocità effettiva e il valore personalizzato può essere 4-256, mentre un valore più alto implica ulteriori guadagni. |
dataIntegrationUnits |
| Grado di parallelismo di copia | Specificare il grado di parallelismo usato dal caricamento dati. | parallelCopies |
| Ottimizzazione delle prestazioni adattive (anteprima) | Specificare se il servizio può applicare ottimizzazioni delle prestazioni e ottimizzazione in base alla configurazione personalizzata. | regolazioneAdattivaDellePrestazioni |
| Verifica della coerenza dei dati | Se si imposta true per questa proprietà, quando si copiano file binari, l'attività di copia verificherà le dimensioni del file, lastModifiedDate e il checksum per ogni file binario copiato dall'archivio di origine a quello di destinazione per garantire la coerenza dei dati tra l'archivio di origine e quello di destinazione. Quando si copiano dati tabulari, l'attività di copia verificherà il numero totale di righe al termine del processo, assicurando che il numero totale di righe lette dall'origine corrisponda al numero di righe copiate nella destinazione e al numero di righe incompatibili ignorate. Tenere presente che le prestazioni della copia sono influenzate dall'abilitazione di questa opzione. |
validateDataConsistency |
| Tolleranza ai guasti | Quando si seleziona questa opzione, è possibile ignorare alcuni errori che si verificano durante il processo di copia. Ad esempio, righe incompatibili tra l'archivio di origine e quello di destinazione, file eliminati durante lo spostamento dei dati e così via. | • abilitaSaltaRigaIncompatibile • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Abilitare la registrazione | Quando si seleziona questa opzione, è possibile registrare file copiati, file e righe ignorati. | / |
| Abilitare la gestione temporanea | Specificare se copiare i dati tramite un archivio di staging provvisorio. Abilitare la gestione temporanea solo per scenari utili. | enableStaging |
| Per l'area di lavoro | ||
| Workspace | Specificare per usare l'archiviazione di staging predefinita. Verificare che l'utente che ha effettuato l'ultima modifica alla pipeline abbia almeno il ruolo di Collaboratore assegnato nell'area di lavoro. | / |
| Per esterno | ||
| Connessione dell'account di staging | Specificare la connessione di Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2, che si riferisce all'istanza di archiviazione usata come archivio di staging temporaneo. Crea una connessione di staging se non ce l'hai. | Connessione (sotto externalReferences) |
| Percorso di archiviazione | Specificare il percorso in cui si desidera contenere i dati temporanei. Se non si specifica un percorso, il servizio crea un contenitore in cui archiviare i dati temporanei. Specificare un percorso solo se si usa l'archiviazione con una firma di accesso condiviso o se i dati temporanei devono trovarsi in un percorso specifico. | path |
| Abilitare la compressione | Specifica se è necessario comprimere i dati prima di copiarli nella destinazione. Questa impostazione ridurre il volume dei dati da trasferire. | enableCompression |
| Preserve | Specificare se mantenere metadati ed elenchi di controllo di accesso (ACL) durante la copia dei dati. | preserve |
Note
Se si usa la copia di staging con compressione abilitata, l'autenticazione principale del servizio per la connessione di staging BLOB non è supportata.
Note
Lo staging dell'area di lavoro va in timeout dopo 60 minuti. Per i processi a esecuzione prolungata, è consigliabile usare l'archiviazione esterna per la memorizzazione temporanea.
Configurare i parametri in un'attività di copia
I parametri possono essere usati per controllare il comportamento di una pipeline e le relative attività. Si può usare Aggiungi contenuto dinamico per specificare i parametri per le proprietà dell'attività Copia. Prendiamo specificare Lakehouse/Data Warehouse come esempio per vedere come utilizzarlo.
Nell'origine o nella destinazione selezionare Usa contenuto dinamico nell'elenco a discesa Connessione.
Nel riquadro popup Aggiungi contenuto dinamico, nella scheda Parametri selezionare +.
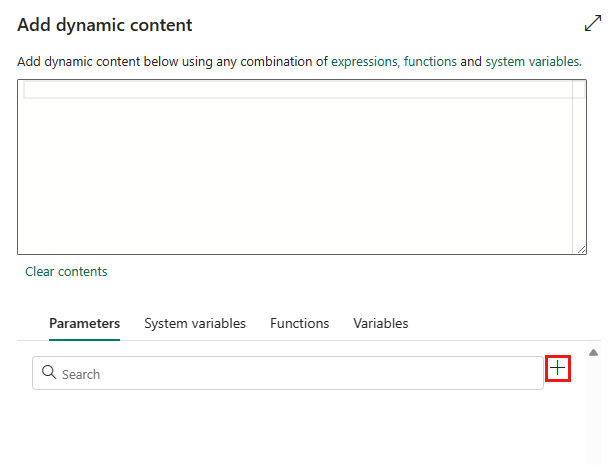
Specificare il nome per il parametro e assegnargli un valore predefinito, se necessario, oppure specificare il valore per il parametro quando viene attivato nella pipeline.

Il valore del parametro deve essere l'ID connessione Lakehouse/Data Warehouse. Per ottenerlo, aprire Gestisci connessioni e gateway, scegliere la connessione Lakehouse/Data Warehouse che si vuole usare e aprire Impostazioni per ottenere l'ID connessione. Se si vuole creare una nuova connessione, è possibile selezionare + Nuovo in questa pagina o passare alla pagina dei dati tramite l'elenco a discesa Connessione .
Selezionare Salva per tornare al riquadro Aggiungi contenuto dinamico. Poi, selezionare il parametro in modo che venga visualizzato nella casella di espressione. Quindi, selezionare OK. Si tornerà alla pagina della pipeline e si noterà che l'espressione del parametro è specificata dopo Connection.
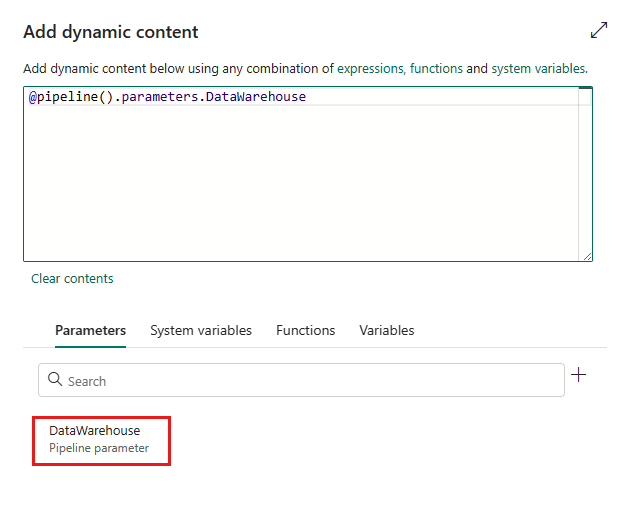
Specificare l'ID di Lakehouse o Data Warehouse. Per trovare l'ID, vai a Lakehouse o Data Warehouse nella tua area di lavoro. L'ID viene visualizzato nell'URL dopo
/lakehouses/o/datawarehouses/.ID Lakehouse:

ID magazzino:

Specificare la stringa di connessione SQL per Data Warehouse.