Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida introduttiva si apprenderà come interagiscono i flussi di dati e le pipeline per creare una soluzione data factory potente. Tu pulirai i dati con i flussi di dati e li sposterai con le pipeline.
Prerequisiti
Prima di iniziare, è necessario:
- Un account tenant con una sottoscrizione attiva. Creare un account gratuito.
- Un'area di lavoro abilitata per Microsoft Fabric: configurare un'area di lavoro che non è l'area di lavoro personale predefinita.
- Un database SQL di Azure con dati di tabella.
- Account di archiviazione BLOB.
Confrontare flussi di dati e pipeline
Dataflow Gen2 offre un'interfaccia a basso codice con 300+ dati e trasformazioni basate sull'intelligenza artificiale. È possibile pulire, preparare e trasformare facilmente i dati con flessibilità. Le pipeline offrono funzionalità avanzate di orchestrazione dei dati per comporre flussi di lavoro di dati flessibili che soddisfano le esigenze aziendali.
In una pipeline è possibile creare raggruppamenti logici di attività che eseguono un'attività. Ciò potrebbe includere la chiamata di un flusso di dati per pulire e preparare i dati. Anche se esistono alcune funzionalità che si sovrappongono tra i due, la scelta dipende dal fatto che siano necessarie le funzionalità complete delle pipeline o che possano usare le funzionalità più semplici dei flussi di dati. Per ulteriori informazioni, consultare il Fabric decision guide.
Trasformare i dati con i flussi di dati
Seguire questa procedura per configurare il flusso di dati.
Creazione di un flusso di dati
Seleziona la tua area di lavoro abilitata per Fabric, quindi Nuovo e scegli Flusso di dati Gen2.
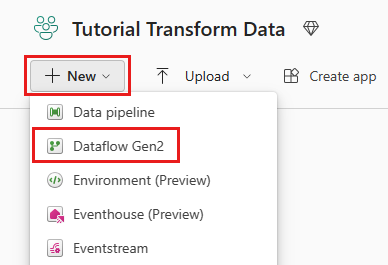
Nell'editor del flusso di dati selezionare Importa da SQL Server.
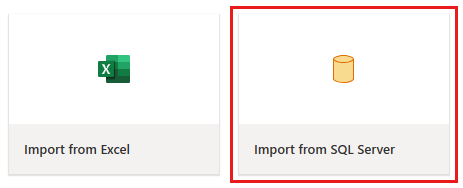


Ottieni dati
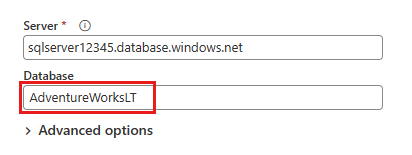
Nella finestra di dialogo Connetti all'origine dati immettere i dettagli del database SQL di Azure e selezionare Avanti. Usare il database di esempio AdventureWorksLT dai prerequisiti.
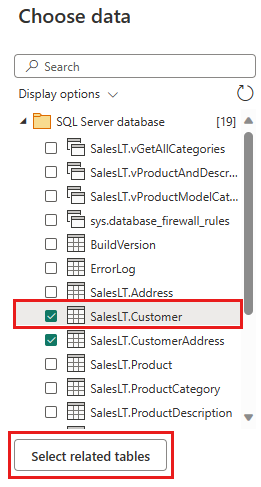
Selezionare i dati da trasformare, ad esempio SalesLT.Customer e selezionare le tabelle correlate per includere tabelle correlate. Successivamente, seleziona Crea.


Trasforma i tuoi dati
Selezionare Visualizzazione diagramma dalla barra di stato o dal menu Visualizza nell'editor di Power Query.
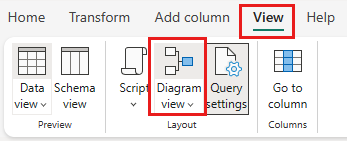
Fare clic con il tasto destro del mouse sulla query SalesLT Customer oppure selezionare i puntini di sospensione verticali a destra della query, quindi selezionare Unisci query.
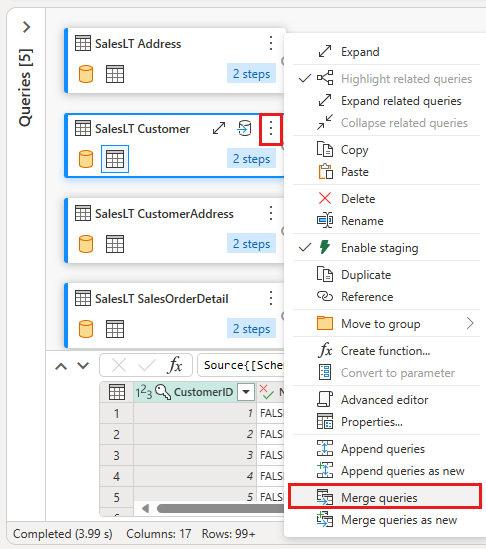
Configurare l'unione con SalesLTOrderHeader come tabella destra, CustomerID come colonna di unione e left outer come tipo di join. Seleziona OK.
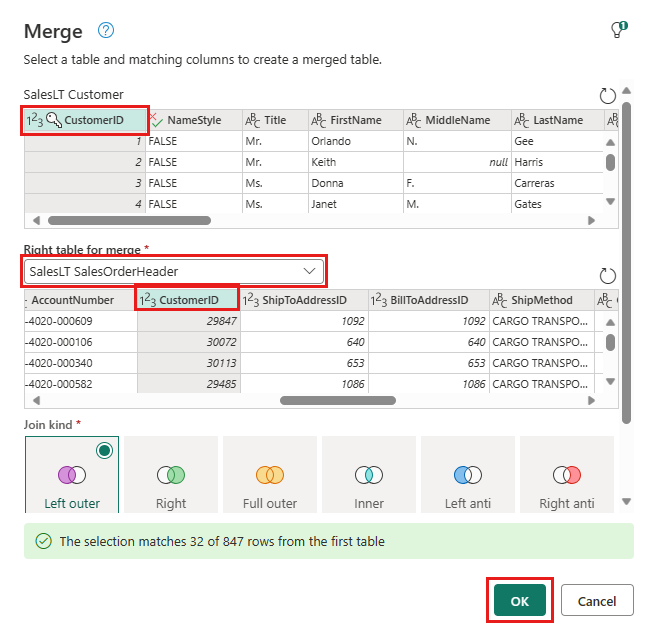
Aggiungere una destinazione dati selezionando il simbolo del database con una freccia. Scegliere Database SQL di Azure come tipo di destinazione.
Specificare i dettagli per la connessione al database SQL di Azure in cui pubblicare la query di unione. In questo esempio viene usato anche il database AdventureWorksLT usato come origine dati per la destinazione.
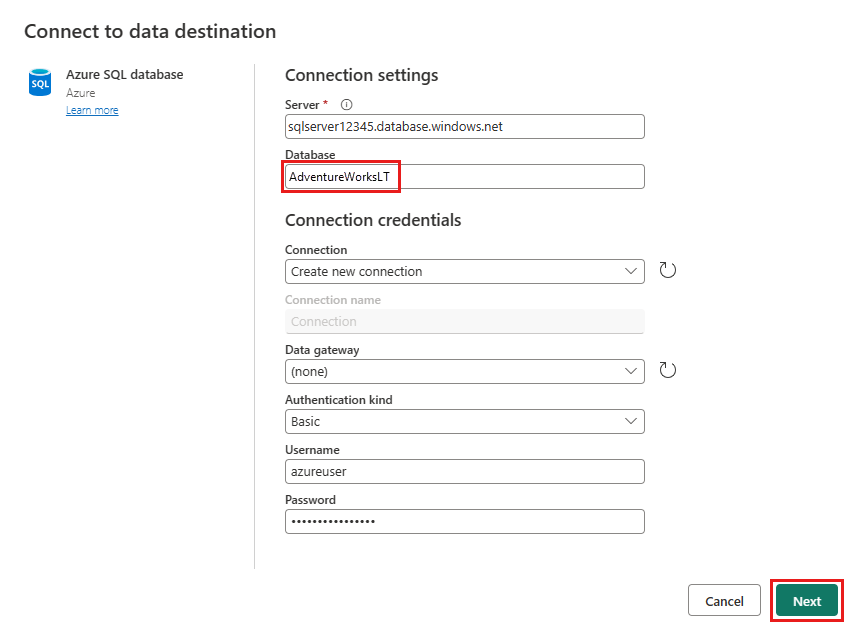
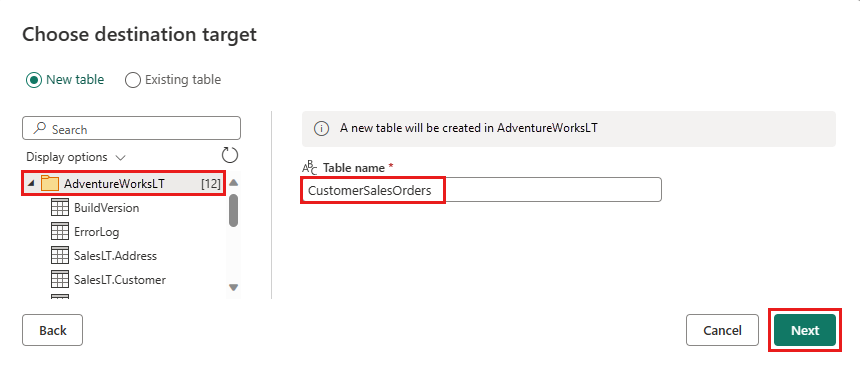
Scegliere un database per archiviare i dati e specificare un nome di tabella, quindi selezionare Avanti.
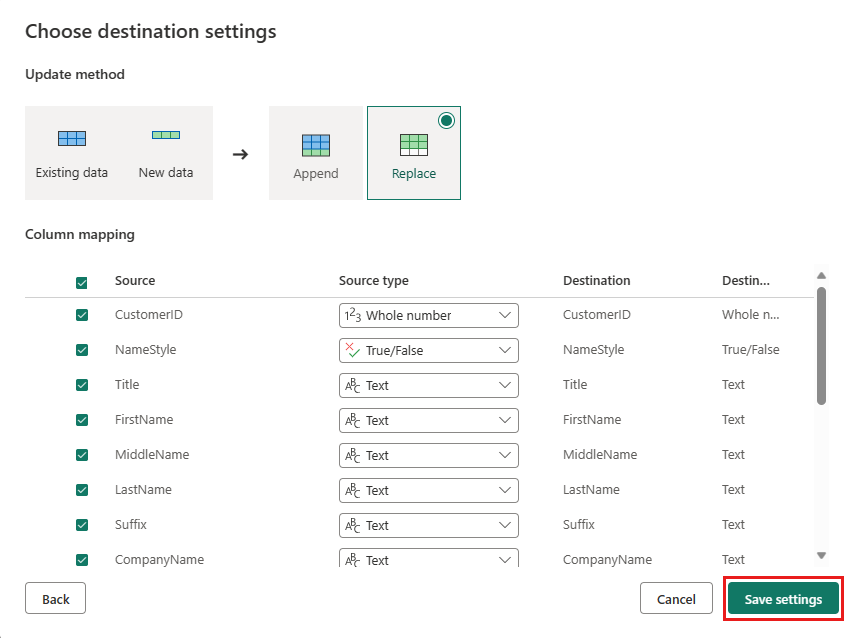
Accettare le impostazioni predefinite nella finestra di dialogo Scegli impostazioni di destinazione e selezionare Salva impostazioni.
Selezionare Pubblica nell'editor del flusso di dati per pubblicare il flusso di dati.



Spostare dati con le pipeline
Dopo aver creato un dataflow Gen2, è possibile usarlo in una pipeline. In questo esempio si copiano i dati generati dal flusso di dati in formato testo in un account Archiviazione BLOB di Azure.
Creare una nuova pipeline
Nell'area di lavoro selezionare Nuovo, quindi Pipeline.
Screenshot della creazione di una nuova pipeline.
Assegnare un nome alla pipeline e selezionare Crea.
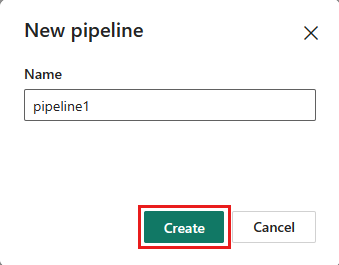
Configurare il flusso di dati
Aggiungere un'attività del flusso di dati alla pipeline selezionando Flusso di dati nella scheda Attività .

Selezionare il flusso di dati nell'area di disegno della pipeline, passare alla scheda Impostazioni e scegliere il flusso di dati creato in precedenza.
Screenshot della selezione di un flusso di dati.
Selezionare Salva, quindi Esegui per popolare la tabella della query risultante.
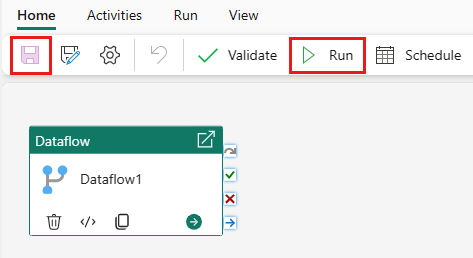
Aggiungere un'attività Copia
Selezionare Copia dati nell'area di disegno o usare l'Assistente copia nella scheda Attività .
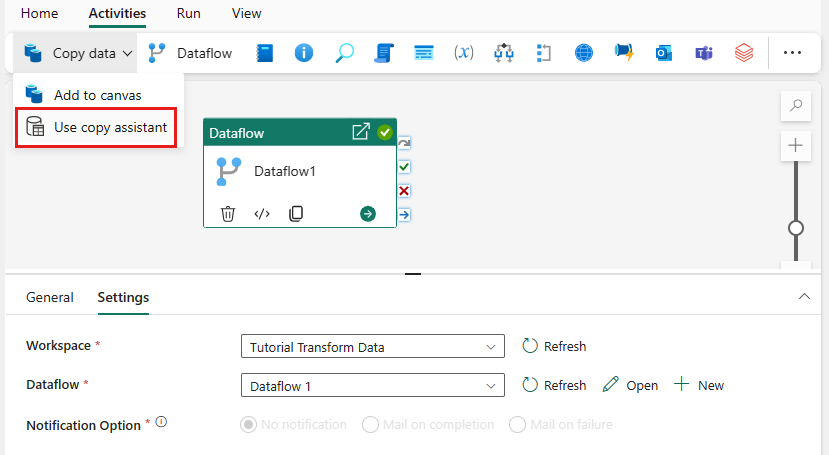
Scegliere Database SQL di Azure come origine dati e selezionare Avanti.
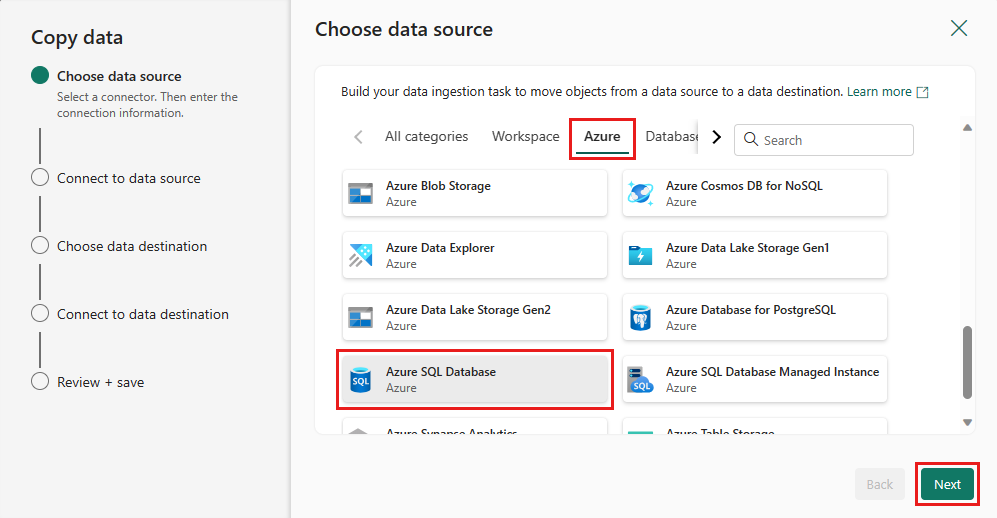
Creare una connessione all'origine dati selezionando Crea nuova connessione. Immettere le informazioni di connessione necessarie nel pannello e immettere AdventureWorksLT per il database, in cui è stata generata la query di unione nel flusso di dati. Quindi seleziona Avanti.
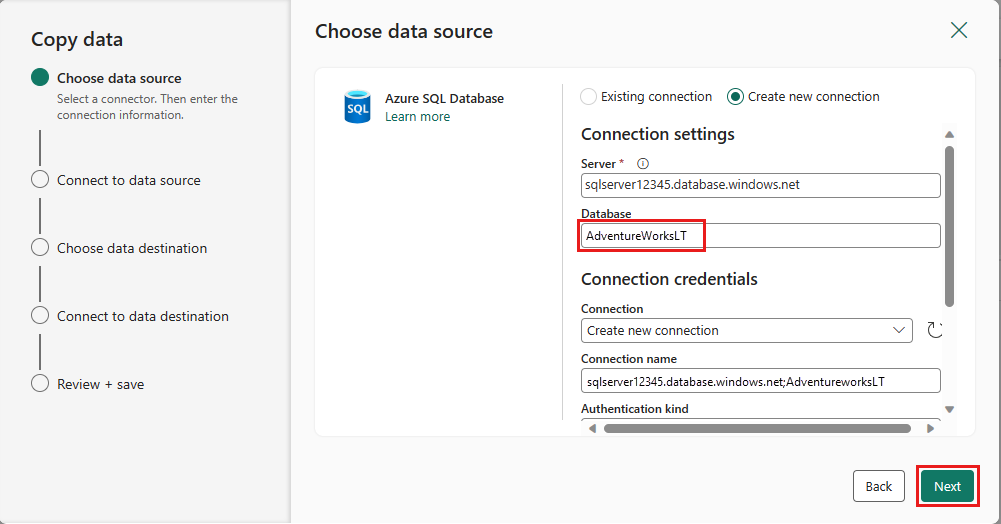
Selezionare la tabella generata nel passaggio del flusso di dati precedente e quindi selezionare Avanti.
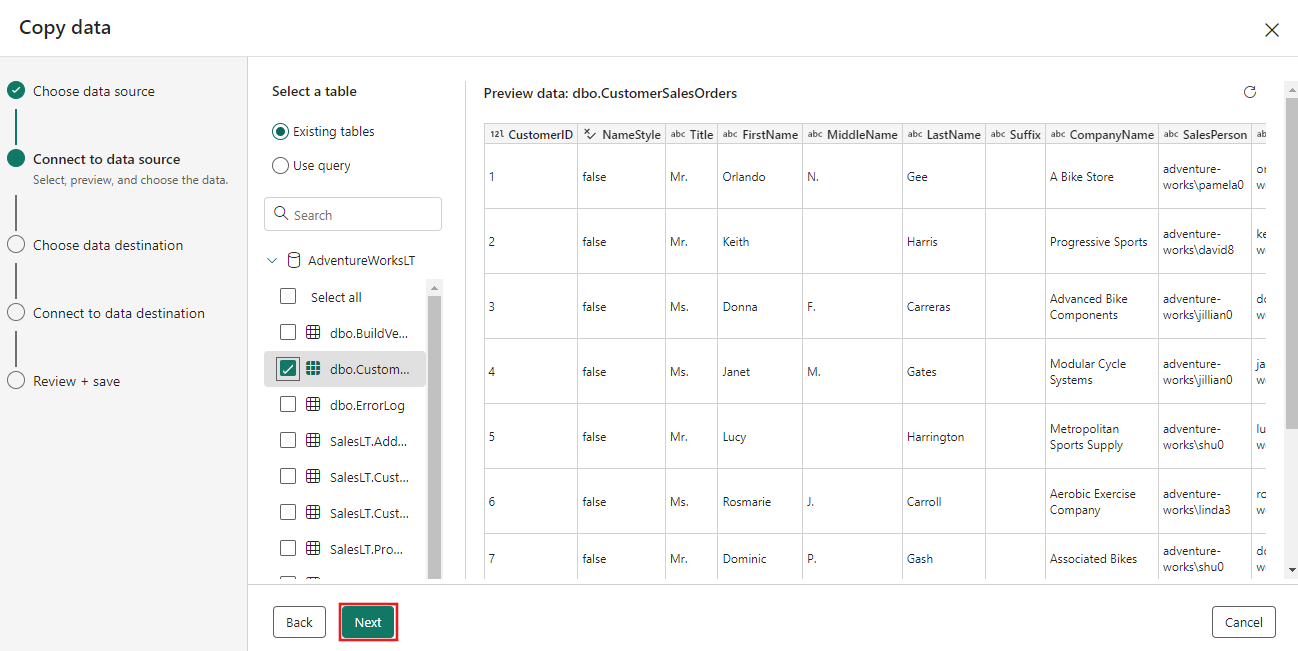
Per la destinazione scegliere Archiviazione BLOB di Azure e quindi selezionare Avanti.
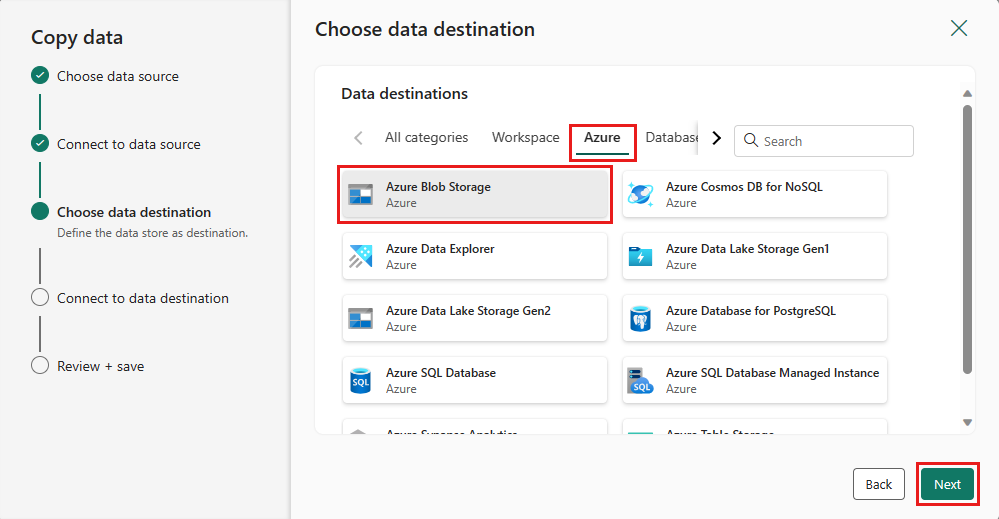
Creare una connessione alla destinazione selezionando Crea nuova connessione. Fornire i dettagli per la connessione, quindi selezionare Successivo.
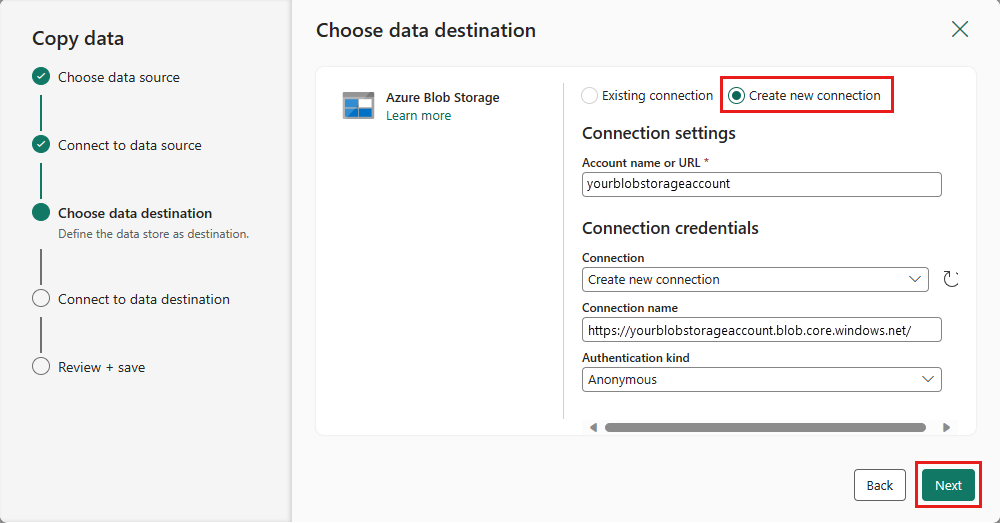
Selezionare il percorso della cartella e specificare un nome file, quindi selezionare Avanti.
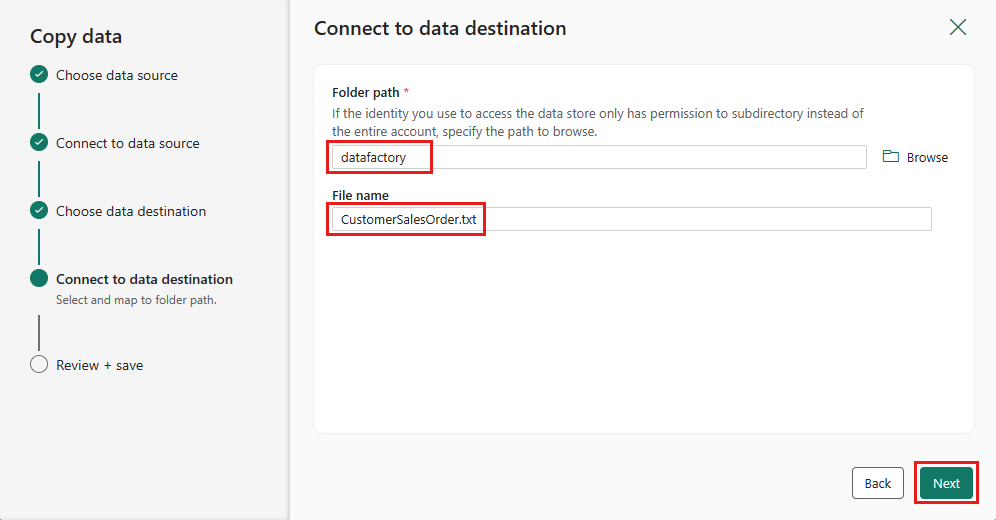
Selezionare di nuovo Avanti per accettare il formato di file predefinito, il delimitatore di colonna, il delimitatore di riga e il tipo di compressione, includendo facoltativamente un'intestazione.
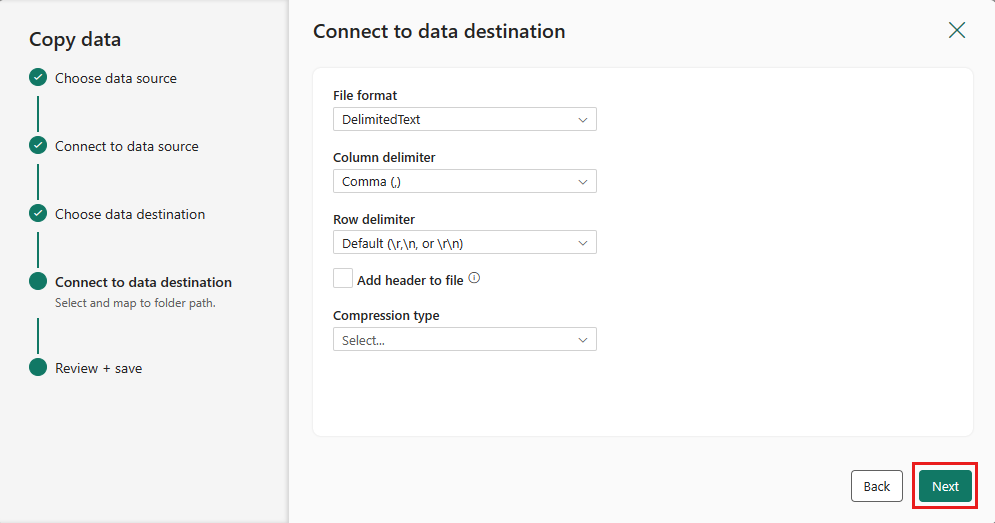
Finalizzare le impostazioni. Quindi, esaminare e selezionare Salva + Esegui per completare il processo.
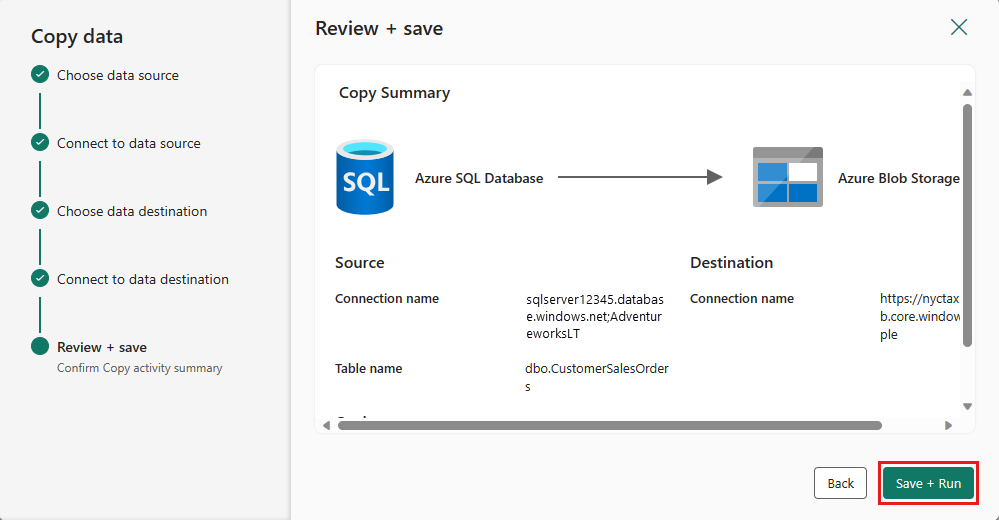
Progettare la pipeline e salvare per l'esecuzione e il caricamento dei dati
Per eseguire l'attività di copia dopo l'attività Flusso di dati, trascinare da Riuscito nell'attività Flusso di dati all'attività di copia. L'attività di copia viene eseguita solo dopo che l'attività flusso di dati ha esito positivo.

Selezionare Salva per salvare la pipeline. Selezionare quindi Esegui per eseguire la pipeline e caricare i dati.
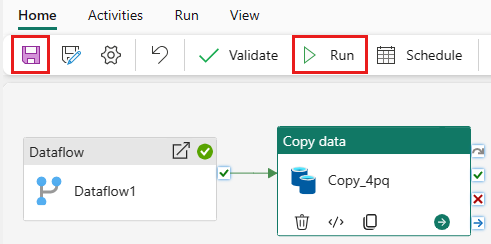
Pianificare l'esecuzione della pipeline
Dopo aver completato lo sviluppo e il test della pipeline, è possibile pianificarlo per l'esecuzione automatica.
Nella scheda Home della finestra dell'editor della pipeline selezionare Pianifica.
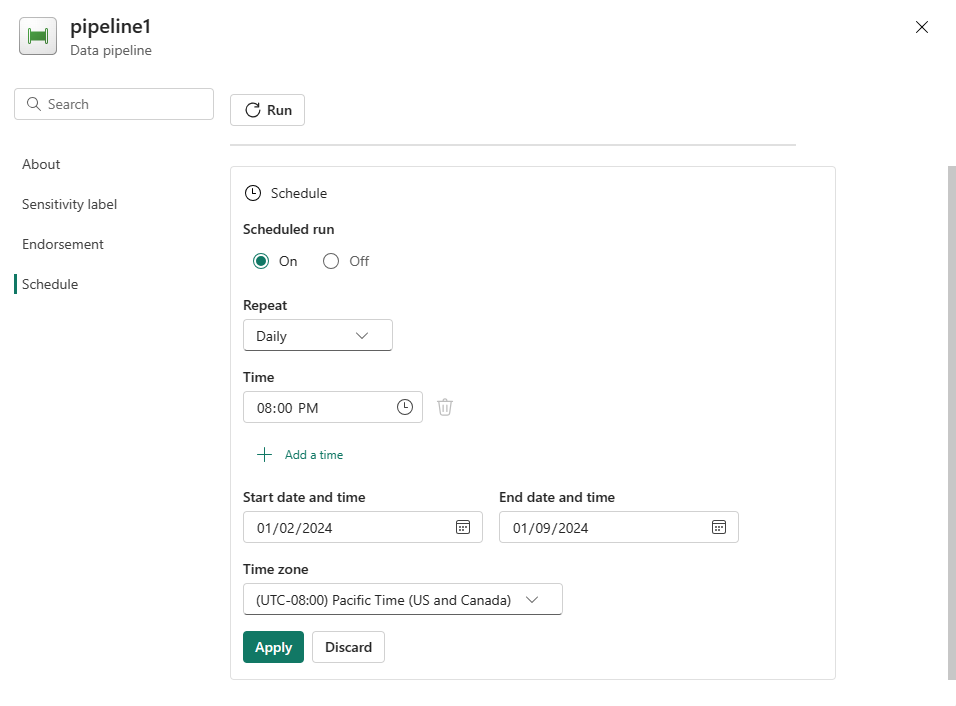
Configurare la pianificazione in base alle esigenze. L'esempio qui pianifica l'esecuzione della pipeline ogni giorno alle 20:00 fino alla fine dell'anno.
Contenuto correlato
Questo esempio illustra come creare e configurare un flusso di dati Gen2 per creare una query di unione e archiviarla in un database SQL di Azure, quindi copiare i dati dal database in un file di testo in Archiviazione BLOB di Azure. Hai imparato come:
- Creare un flusso di dati.
- Trasforma i dati con il flusso di dati.
- Creare una pipeline usando il flusso di dati.
- Ordinare l'esecuzione delle fasi nella pipeline.
- Copia i dati con l'Assistente Copia.
- Esegui e pianifica la tua pipeline.
Passare quindi a altre informazioni sul monitoraggio delle esecuzioni della pipeline.