Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il collegamento semantico è una funzionalità che consente di stabilire una connessione tra modelli semantic e Synapse Data Science in Microsoft Fabric. L'uso del collegamento semantico è supportato solo in Microsoft Fabric.
Per Fabric Runtime 1.2 (Spark 3.4) e versioni successive, il collegamento semantico è disponibile nel runtime predefinito e non è necessario installarlo.
Per eseguire l'aggiornamento alla versione più recente del collegamento semantico, eseguire il comando seguente:
%pip install -U semantic-link
Gli obiettivi principali del collegamento semantico sono:
- Facilitare la connettività dei dati.
- Abilitare la propagazione delle informazioni semantiche.
- Integrazione senza problemi con gli strumenti consolidati usati dai data scientist, ad esempio i notebook.
Il collegamento semantico consente di mantenere le conoscenze del dominio sulla semantica dei dati in modo standardizzato consentendo di velocizzare l'analisi dei dati e ridurre gli errori.
Flusso di dati del collegamento semantico
Il flusso di dati del collegamento semantico inizia con modelli semantici che contengono dati e informazioni semantiche. Il collegamento semantico consente di colmare il divario tra Power BI e l'esperienza di data science di Synapse.
Un diagramma 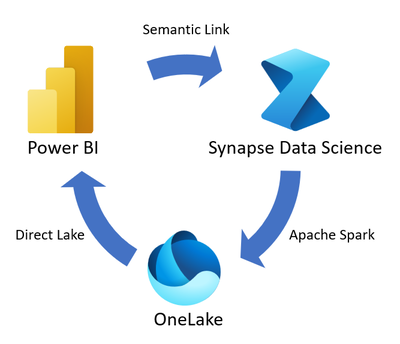
Il collegamento semantico consente di usare modelli semantici di Power BI nell'esperienza di data science di Synapse per eseguire attività come l'analisi statistica approfondita e la modellazione predittiva con tecniche di Machine Learning. È possibile archiviare l'output del lavoro di data science in OneLake usando Apache Spark e inserire l'output archiviato in Power BI usando Direct Lake.
Connettività di Power BI
Un modello semantico funge da singolo modello di oggetti tabulari che fornisce origini affidabili per le definizioni semantiche, ad esempio le misure di Power BI. Il collegamento semantico si connette ai modelli semantici negli ecosistemi seguenti, semplificando il funzionamento dei data scientist nel sistema con cui hanno più familiarità.
- Python pandas attraverso l'ecosistema della libreria SemPy Python.
- Ecosistema Apache Spark, tramite il connettore nativo Spark. Questa implementazione supporta vari linguaggi, tra cui PySpark, Spark SQL, R e Scala.
Applicazioni di informazioni semantiche
Le informazioni semantiche nei dati includono Power BI categorie di dati come indirizzo e codice postale, relazioni tra tabelle e informazioni gerarchica.
Queste categorie di dati comprendono metadati che il collegamento semantico propaga nell'ambiente di Data Science Synapse per consentire nuove esperienze e gestire la lineage dei dati.
Alcune applicazioni di esempio di collegamento semantico includono:
- Suggerimenti intelligenti di funzioni semantiche predefinite.
- Integrazione innovativa per l'aumento dei dati con misure di Power BI, usando misure aggiuntive.
- Strumenti per la convalida della qualità dei dati in base alle relazioni tra tabelle e dipendenze funzionali all'interno delle tabelle.
Il collegamento semantico è uno strumento potente che consente agli analisti aziendali di usare i dati in modo efficace in un ambiente di data science completo.
Il collegamento semantico semplifica la collaborazione tra i data scientist e i business analyst eliminando la necessità di riimplementare la logica di business incorporata nelle misure di Power BI. Questo approccio garantisce che entrambe le parti possano lavorare in modo efficiente e produttivo, ottimizzando il potenziale delle informazioni dettagliate basate sui dati.
Struttura dei dati FabricDataFrame
FabricDataFrame è la struttura di dati primaria usata dal collegamento semantico per propagare informazioni semantiche dai modelli semantici nell'ambiente di data science synapse.

Classe FabricDataFrame:
- Supporta tutte le operazioni Pandas.
- Sottoclassa il dataframe pandas e aggiunge metadati, ad esempio informazioni semantiche e derivazione.
- Espone funzioni semantiche e il metodo add-measure che consente di usare le misure di Power BI nel lavoro di data science.
Contenuto correlato
- Explore la documentazione di riferimento per il pacchetto di collegamento semantico Python (SemPy)
- Esercitazione: Ripulire i dati con dipendenze funzionali
- Connettività di Power BI con collegamento semantico e Microsoft Fabric
- Esplorare e convalidare i dati usando il collegamento semantico
- Esplorare e convalidare le relazioni nei modelli semantici