Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa esercitazione si apprenderà come eseguire l'analisi esplorativa dei dati (EDA) per esaminare e analizzare i dati riepilogando le caratteristiche principali tramite l'uso di tecniche di visualizzazione dei dati.
Si userà seaborn, una libreria di visualizzazione dei dati Python che fornisce un'interfaccia di alto livello per la compilazione di oggetti visivi su DataFrame e matrici. Per altre informazioni su seaborn, vedere Seaborn: visualizzazione dati statistici.
Si userà anche Data Wrangler, uno strumento basato su notebook che offre un'esperienza immersiva per eseguire analisi esplorative dei dati e pulizia.
La procedura principale dell'esercitazione è la seguente:
- Leggere i dati archiviati da una tabella delta nel lakehouse.
- Convertire un DataFrame Spark in DataFrame Pandas, supportato da librerie di visualizzazioni Python.
- Usare Data Wrangler per eseguire la pulizia e la trasformazione iniziali dei dati.
- Eseguire l'analisi esplorativa dei dati usando
seaborn.
Prerequisiti
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione di Microsoft Fabric gratuita.
Accedere a Microsoft Fabric.
Passare a Fabric usando il commutatore dell'esperienza in basso a sinistra della tua home page.

Questa è la parte 2 di 5 di questa serie di esercitazioni. Per procedere con questa esercitazione, è necessario completare:
Seguire la procedura in Notebook
2-explore-cleanse-data.ipynb è il notebook che accompagna questa esercitazione.
Per aprire il notebook di accompagnamento per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni di data science per importare il notebook nell'area di lavoro.
Se si preferisce copiare e incollare il codice da questa pagina, è possibile creare un nuovo notebook.
Assicurarsi di collegare un lakehouse al notebook prima di iniziare a eseguire il codice.
Importante
Collegare la stessa lakehouse usata nella parte 1.
Leggere i dati non elaborati dal lakehouse
Leggere i dati non elaborati dalla sezione File del lakehouse. Questi dati sono stati caricati nel notebook precedente. Assicurarsi di aver collegato la stessa lakehouse usata nella parte 1 a questo notebook prima di eseguire questo codice.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Creare un DataFrame Pandas da un set di dati
Convertire il DataFrame spark in DataFrame pandas per semplificare l'elaborazione e la visualizzazione.
df = df.toPandas()
Visualizzare dati non elaborati
Esplorare i dati non elaborati con display, eseguire alcune statistiche di base e mostrare le visualizzazioni del grafico. Si noti che è prima necessario importare le librerie necessarie, ad esempio Numpy, Pnadas, Seaborn e Matplotlib per l'analisi e la visualizzazione dei dati.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
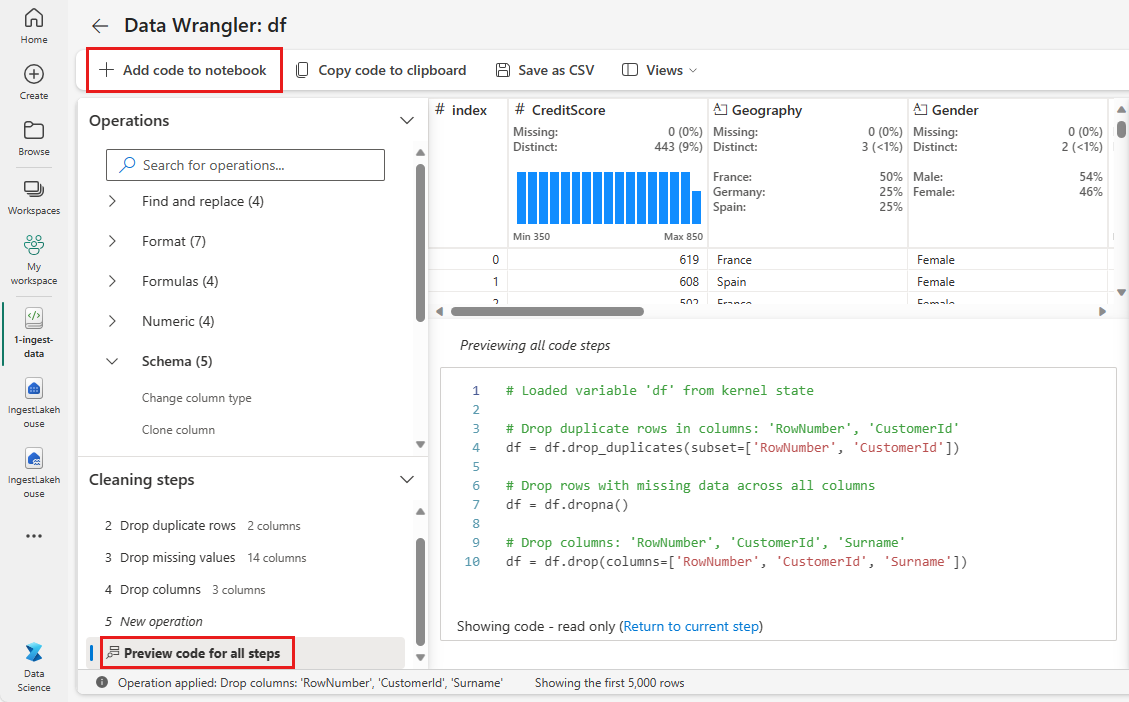
Usare Data Wrangler per eseguire la pulizia iniziale dei dati
Per esplorare e trasformare i DataFrame pandas nel notebook, avviare Data Wrangler direttamente dal notebook.
Nota
I dati Wrangler non possono essere aperti mentre il kernel del notebook è occupato. L'esecuzione della cella deve essere completata prima di avviare Data Wrangler.
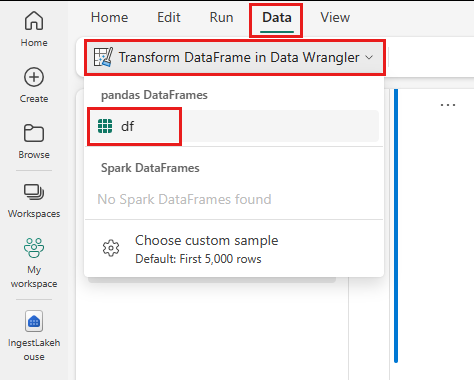
- Nella scheda Dati della barra multifunzione del notebook, selezionare Avvia Data Wrangler. Verrà visualizzato un elenco di DataFrame pandas attivati disponibili per la modifica.
- Selezionare il DataFrame da aprire in Data Wrangler. Poiché questo notebook contiene solo un DataFrame,
df, selezionaredf.
Data Wrangler si avvia e genera una panoramica descrittiva dei dati. La tabella al centro mostra ogni colonna di dati. Il pannello Riepilogo accanto alla tabella mostra informazioni sul DataFrame. Quando si seleziona una colonna nella tabella, il riepilogo viene aggiornato con informazioni sulla colonna selezionata. In alcuni casi, i dati visualizzati e riepilogati saranno una visualizzazione troncata del DataFrame. In questo caso, verrà visualizzata l'immagine di avviso nel riquadro di riepilogo. Passare il puntatore del mouse su questo avviso per visualizzare il testo che spiega la situazione.

Ogni operazione eseguita può essere applicata in pochi clic, aggiornando la visualizzazione dei dati in tempo reale e generando codice che è possibile salvare nuovamente nel notebook come funzione riutilizzabile.
La parte restante di questa sezione illustra i passaggi per eseguire la pulizia dei dati con Data Wrangler.
Eliminare righe duplicate
Nel pannello sinistro è riportato un elenco di operazioni, ad esempio Trova e sostituisci, Formato, Formule, Numerico, che è possibile eseguire nel set di dati.
Espandere Trova e sostituisci e selezionare Elimina righe duplicate.
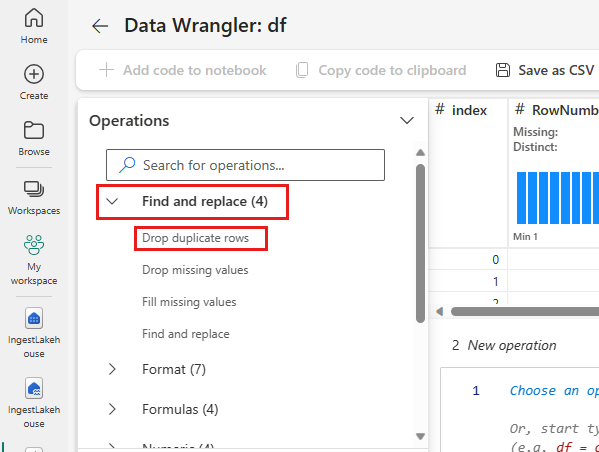
Viene visualizzato un pannello che consente di selezionare l'elenco di colonne da confrontare per definire una riga duplicata. Selezionare RowNumber e CustomerId.
Nel pannello centrale è disponibile un'anteprima dei risultati di questa operazione. Nell'anteprima c'è il codice per eseguire l'operazione. In questo caso, i dati sembrano essere invariati. Tuttavia, poiché si sta esaminando una visualizzazione troncata, è consigliabile applicare comunque l'operazione.
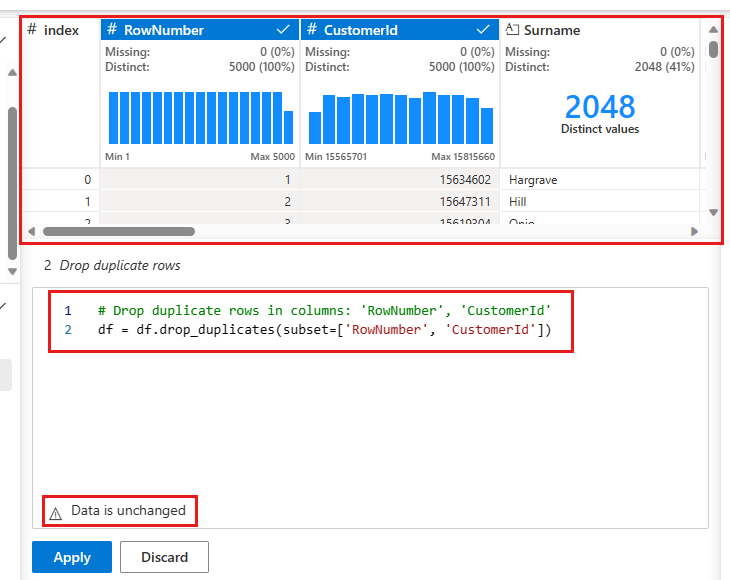
Selezionare Applica (sul lato o nella parte inferiore) per andare al passaggio successivo.

Eliminare righe con dati mancanti
Usare Data Wrangler per eliminare righe con dati mancanti in tutte le colonne.
Selezionare Elimina valori mancanti in Trova e sostituisci.
Scegliere Seleziona tutto dalle colonne di destinazione.

Selezionare Avanti per andare al passaggio successivo.

Eliminazione delle colonne
Usare Data Wrangler per eliminare colonne non necessarie.
Espandere Schema e selezionare Elimina colonne.
Selezionare RowNumber, CustomerId, Surname. Queste colonne vengono visualizzate in rosso nell'anteprima, per mostrare che sono state modificate dal codice (in questo caso, rimosse).
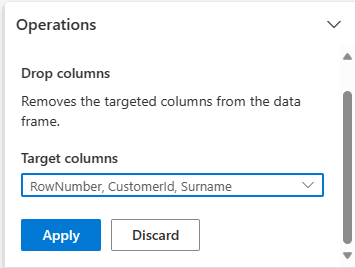
Selezionare Avanti per andare al passaggio successivo.

Aggiungere codice al notebook
Ogni volta che si seleziona Applica, viene creato un nuovo passaggio nel pannello Passaggi di pulizia in basso a sinistra. Nella parte inferiore del pannello selezionare Codice di anteprima per tutti i passaggi per visualizzare una combinazione di tutti i passaggi separati.
Selezionare Aggiungi codice al notebook in alto a sinistra per chiudere Data Wrangler e aggiungere automaticamente il codice. L'opzione Aggiungi codice al notebook racchiude il codice in una funzione, quindi chiama la funzione .
Suggerimento
Il codice generato da Data Wrangler non verrà applicato fino a quando non si esegue manualmente la nuova cella.
Se non si usa Data Wrangler, è invece possibile usare questa cella di codice successiva.
Questo codice è simile al codice prodotto da Data Wrangler, ma aggiunge l'argomento inplace=True a ognuno dei passaggi generati. Impostando inplace=True, pandas sovrascriverà il DataFrame originale anziché produrre un nuovo DataFrame come output.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Esplorare i dati
Visualizzare alcuni riepiloghi e visualizzazioni dei dati puliti.
Determinare gli attributi categorici, numerici e di destinazione
Usare questo codice per determinare gli attributi categorici, numerici e di destinazione.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
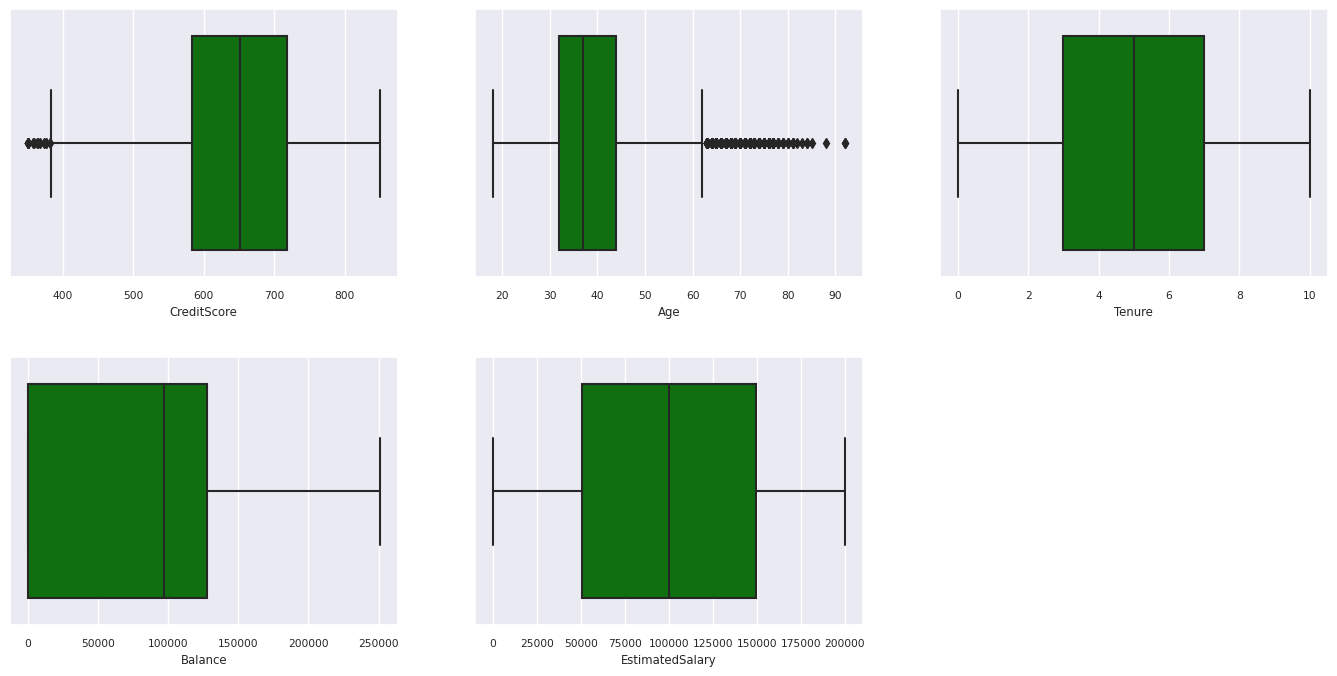
Riepilogo dei cinque numeri
Mostra il riepilogo a cinque numeri (punteggio minimo, primo quartile, mediano, terzo quartile e punteggio massimo) per gli attributi numerici, con tracciati box.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
Distribuzione dei clienti usciti e non usciti
Mostra la distribuzione dei clienti usciti rispetto ai clienti non usciti tra gli attributi categorici.
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

Distribuzione di attributi numerici
Visualizzare la distribuzione della frequenza degli attributi numerici usando l'istogramma.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Eseguire l'ingegneria delle funzionalità
Eseguire la progettazione delle funzionalità per generare nuovi attributi in base agli attributi correnti:
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Usare Data Wrangler per eseguire la codifica one-hot
Data Wrangler può essere usato anche per eseguire la codifica one-hot. A tale scopo, riaprire Data Wrangler. Questa volta, selezionare i dati df_clean.
- Espandere Formule e selezionare Codifica one-hot.
- Viene visualizzato un pannello in cui selezionare l'elenco di colonne su cui si vuole eseguire la codifica one-hot. Selezionare Geografia e Genere.
È possibile copiare il codice generato, chiudere Data Wrangler per tornare al notebook e quindi incollarlo in una nuova cella. In alternativa, selezionare Aggiungi codice al notebook in alto a sinistra per chiudere Data Wrangler e aggiungere automaticamente il codice.
Se non si usa Data Wrangler, è invece possibile usare questa cella di codice successiva:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Riepilogo delle osservazioni dell'analisi esplorativa dei dati
- La maggior parte dei clienti proviene dalla Francia rispetto alla Spagna e alla Germania, mentre la Spagna ha il tasso di varianza più basso rispetto alla Francia e alla Germania.
- La maggior parte dei clienti ha carte di credito.
- Ci sono clienti la cui età e punteggio di credito sono superiori a 60 e al di sotto di 400, rispettivamente, ma non possono essere considerati come outlier.
- Pochissimi clienti hanno più di due dei prodotti della banca.
- I clienti che non sono attivi hanno una varianza più elevata.
- Il genere e gli anni di permanenza non sembrano avere un impatto sulla decisione del cliente di chiudere il conto bancario.
Creare una tabella differenziale per i dati puliti
Questi dati verranno usati nel notebook successivo di questa serie.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Passaggio successivo
Eseguire il training e la registrazione di modelli di Machine Learning con questi dati: