Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:✅ endpoint di Analisi SQL e Warehouse in Microsoft Fabric
Il recupero dei dati dal data lake è un'operazione di input/output (I/O) cruciale con implicazioni sostanziali per le prestazioni delle query. Fabric Data Warehouse usa modelli di accesso perfezionati per migliorare le letture dei dati dall'archiviazione e aumentare la velocità di esecuzione delle query. Inoltre, riduce al minimo la necessità di letture di archiviazione remota sfruttando le cache locali.
La memorizzazione nella cache è una tecnica che migliora le prestazioni delle applicazioni di elaborazione dati riducendo le operazioni di I/O. La memorizzazione nella cache archivia i dati e i metadati a cui si accede di frequente in un livello di archiviazione più veloce, ad esempio memoria locale o disco SSD locale, in modo che le richieste successive possano essere gestite più rapidamente, direttamente dalla cache. Se in precedenza è stato eseguito l'accesso a un determinato set di dati da una query, tutte le query successive recuperano tali dati direttamente dalla cache in memoria. Questo approccio riduce significativamente la latenza di I/O, poiché le operazioni di memoria locale sono notevolmente più veloci rispetto al recupero dei dati dall'archiviazione remota.
La memorizzazione nella cache in memoria e su disco in Fabric Data Warehouse è completamente trasparente per l'utente. Indipendentemente dall'origine, sia che si tratti di una tabella di magazzino, di un collegamento OneLake o anche di un collegamento OneLake che fa riferimento a servizi non di Azure, la query memorizza nella cache tutti i dati a cui accede.
Esistono due tipi di cache descritte più avanti in questo articolo, cache in memoria e cache del disco. La memorizzazione nella cache dei set di risultati è illustrata in un altro articolo.
Cache in memoria
Man mano che la query accede e recupera i dati dall'archiviazione, esegue un processo di trasformazione che transcodifica i dati dal formato originale basato su file in strutture altamente ottimizzate nella cache in memoria.

I dati nella cache sono organizzati in un formato a colonne compresso ottimizzato per le query analitiche. Ogni colonna di dati viene archiviata insieme, separata dalle altre, consentendo una compressione migliore perché i valori di dati simili vengono archiviati insieme, con conseguente riduzione del footprint di memoria. Quando le query devono eseguire operazioni su una colonna specifica, ad esempio aggregazioni o filtri, il motore può funzionare in modo più efficiente perché non è necessario elaborare dati non necessari da altre colonne.
Inoltre, questa risorsa di archiviazione a colonne è favorevole all'elaborazione parallela, che può velocizzare notevolmente l'esecuzione delle query per set di dati di grandi dimensioni. Il motore può eseguire operazioni su più colonne contemporaneamente, sfruttando i moderni processori multi-core.
Questo approccio è particolarmente utile per i carichi di lavoro analitici in cui le query comportano l'analisi di grandi quantità di dati per eseguire aggregazioni, filtri e altre manipolazioni dei dati.
Cache del disco
Alcuni set di dati sono troppo grandi da ospitare all'interno di una cache in memoria. Per sostenere prestazioni rapide delle query per questi set di dati, il magazzino usa lo spazio su disco come estensione complementare alla cache in memoria. Tutte le informazioni caricate nella cache in memoria vengono serializzate anche nella cache SSD.
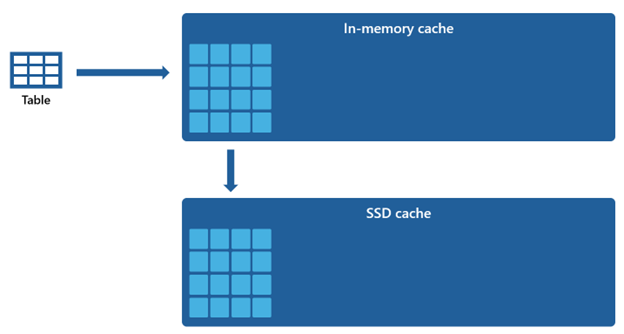
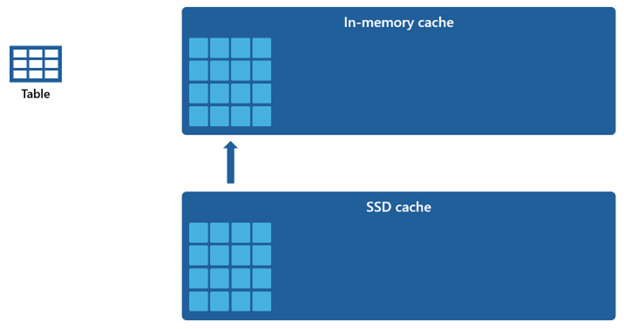
Dato che la cache in memoria ha una capacità inferiore rispetto alla cache SSD, i dati rimossi dalla cache in memoria rimangono nella cache SSD per un periodo prolungato. Quando la query successiva richiede questi dati, viene recuperata dalla cache SSD nella cache in memoria in modo significativamente più rapido rispetto a se recuperata dall'archiviazione remota, offrendo in definitiva prestazioni di query più coerenti.
Gestione della cache
La memorizzazione nella cache rimane sempre attiva e funziona senza problemi in background, senza alcun intervento da parte dell'utente. La disabilitazione della memorizzazione nella cache non è necessaria, perché ciò comporta inevitabilmente un deterioramento notevole delle prestazioni delle query.
Il meccanismo di memorizzazione nella cache viene orchestrato e mantenuto da Microsoft Fabric stesso e non offre agli utenti la possibilità di cancellare manualmente la cache.
La coerenza transazionale della cache completa garantisce che le modifiche apportate ai dati nell'archiviazione, ad esempio tramite operazioni Data Manipulation Language (DML), dopo che sono state inizialmente caricate nella cache in memoria, generano dati coerenti.
Quando la cache raggiunge la soglia di capacità e i dati aggiornati vengono letti per la prima volta, gli oggetti rimasti inutilizzati per la durata più lunga verranno rimossi dalla cache. Questo processo viene applicato per creare spazio per l'afflusso di nuovi dati e mantenere una strategia di utilizzo ottimale della cache.