Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: ✅ Endpoint di analisi SQL e data warehouse in Microsoft Fabric
I pool SQL personalizzati offrono agli amministratori un maggiore controllo sulla modalità di allocazione delle risorse per gestire le richieste. In questa guida rapida, configurerai pool SQL personalizzati e osserverai i valori del classificatore utilizzando l'API REST di Fabric.
Gli amministratori dell'area di lavoro possono usare il nome dell'applicazione (o il nome del programma) dalla stringa di connessione per instradare le richieste a pool di calcolo diversi. Gli amministratori dell'area di lavoro possono anche controllare la percentuale di risorse a cui ogni pool SQL di calcolo può accedere, in base al limite di scalabilità a scoppio della capacità dell'area di lavoro.
L'API REST di Fabric definisce un endpoint unificato per le operazioni.
Prerequisiti
- Accesso a un elemento del magazzino in un'area di lavoro. Dovresti essere un membro del ruolo di amministratore.
Ottenere la configurazione corrente
Usare l'API seguente per ottenere la configurazione corrente.
Esempio di notebook di Fabric
È possibile eseguire il codice Python di esempio seguente in un notebook di Fabric Spark.
- Il codice invia una
GETrichiesta all'API di configurazione del pool SQL personalizzato e restituisce la configurazione del pool SQL personalizzato per l'area di lavoro. - Il
workspace_idcampo usamssparkutils.runtime.contextper ottenere il GUID dell'area di lavoro in cui viene eseguito il notebook. Per configurare un pool SQL personalizzato in un'area di lavoro diversa, aggiornare ilworkspace_idal GUID dell'area di lavoro in cui si vuole configurare i pool SQL personalizzati.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Configurare pool SQL personalizzati
L'esempio python seguente abilita e configura pool SQL personalizzati. È possibile eseguire questo codice Python in un notebook di Fabric Spark.
- La configurazione dei pool SQL personalizzati è attiva solo quando
customSQLPoolsEnabledl'attributo è impostato su true. È possibile definire un payload nella definizione dell'oggettocustomSQLPools, ma se non si imposta customSQLPoolsEnabled su true, il payload viene ignorato e viene usata la gestione autonoma del carico di lavoro . - Il codice configura due pool SQL personalizzati,
ContosoSQLPooleAdhocPool.-
ContosoSQLPoolè impostato per ricevere 70% delle risorse disponibili. Il classificatore Application Name ha il valore diMyContosoApp. - Tutte le query SQL provenienti da una stringa di connessione che specifica il nome dell'applicazione
MyContosoAppvengono classificate nelContosoSQLPoolpool SQL personalizzato e hanno accesso a 70% dei nodi totali della capacità burstable. - Tutte le query SQL che non contengono
MyContosoAppnel nome dell'applicazione della stringa di connessione vengono inviate alAdhocpool SQL personalizzato, definito come pool predefinito. Queste richieste ottengono l'accesso al 30% dei nodi totali della capacità burstable.
-
- Tutte le configurazioni personalizzate del pool SQL devono avere un pool SQL predefinito identificato impostando l'attributo
isDefaultsu true. - La somma di tutti i
maxResourcePercentagevalori deve essere minore o uguale a 100%. - Il campo
workspace_idutilizzamssparkutils.runtime.contextper ottenere il GUID dell'area di lavoro in cui viene eseguito il notebook. Per configurare un pool SQL personalizzato in un'area di lavoro diversa, aggiornare ilworkspace_idal GUID dell'area di lavoro in cui si desidera configurare i pool SQL personalizzati.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Suggerimento
Usare questi valori di classificatore regex (Application Name) utili per il traffico proveniente da Fabric:
- Per classificare le query dalle pipeline di Fabric, usare
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$. - Per classificare le query da Power BI, usare
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?). - Per classificare le query dall'editor di query SQL del portale di Fabric, utilizzare
DMS_user.
Impostare il nome dell'applicazione in SQL Server Management Studio (SSMS)
Il classificatore per i pool SQL personalizzati usa il nome dell'applicazione o il parametro del nome del programma delle stringhe di connessione comuni.
In SQL Server Management Studio (SSMS) specificare il nome del server per il warehouse e fornire l'autenticazione. Microsoft Entra MFA è consigliato.
Selezionare il pulsante Avanzate .
Nella pagina Proprietà avanzate, in Contesto, modificare il valore di Nome applicazione in
MyContosoApp.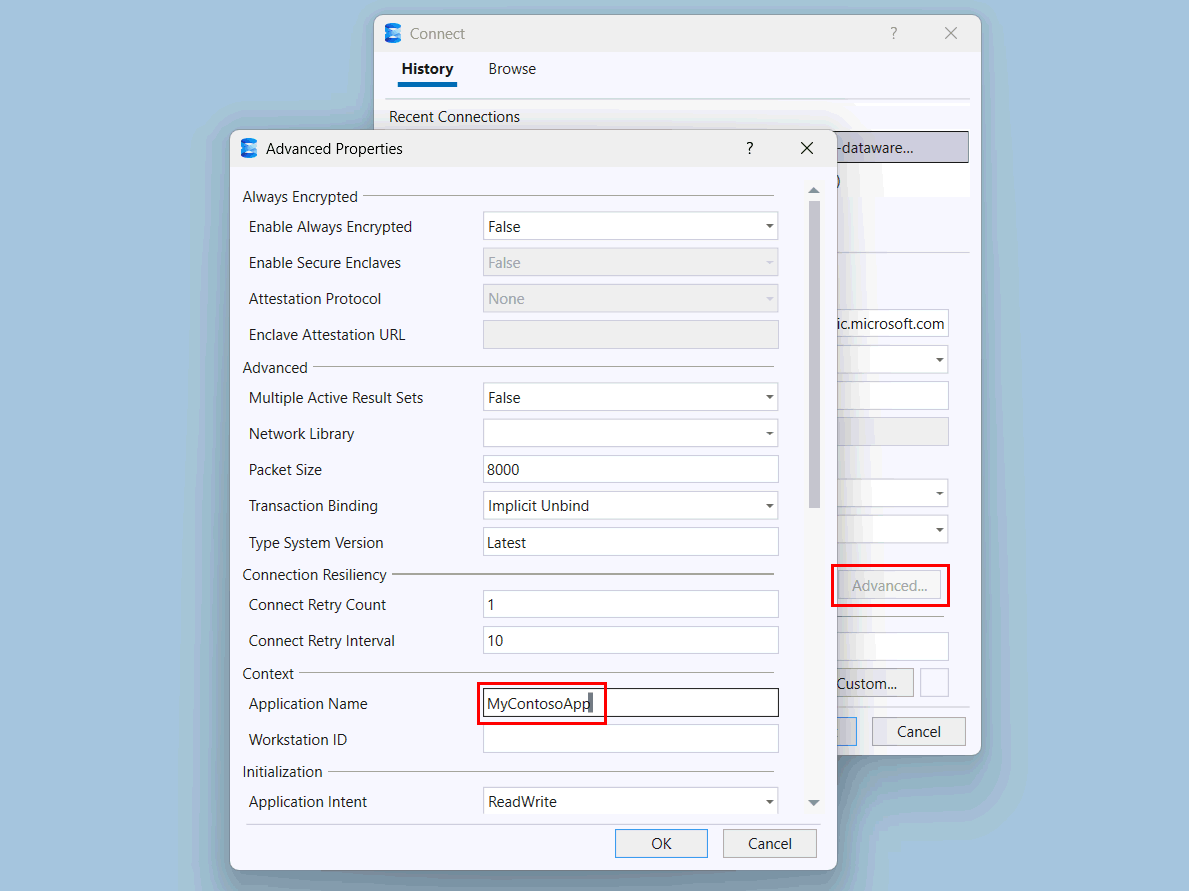
Seleziona OK.
Selezionare Connetti.
Per generare un'attività di esempio, usare questa connessione in SSMS per eseguire una semplice query nel warehouse, ad esempio:
SELECT * FROM dbo.DimDate;

Osservare informazioni dettagliate sulle query per il pool SQL personalizzato
Esaminare la
sys.dm_exec_sessionsvisualizzazione a gestione dinamica per verificare cheMyContosoAppvenga riconosciuto come nome dell'applicazione passato da SSMS al motore SQL.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Per esempio:
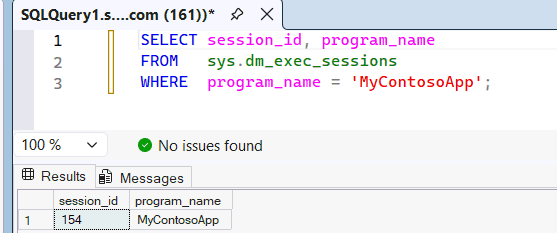
program_namePoiché corrisponde al nome dell'applicazioneMyContosoAppnel pool SQL personalizzato, questa query usa le risorse in tale pool. Per dimostrare il pool SQL personalizzato usato dalla query, è possibile eseguire una query sulla vista di sistema queryinsights.exec_requests_history . Attendere 10-15 minuti affinché le analisi delle query vengano caricate e poi eseguire la query seguente.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';È anche possibile identificare il pool di una query in base al relativo ID istruzione. Nell'editor di query SQL del portale Fabric è possibile eseguire una query sul data warehouse o sull'endpoint di analisi SQL.
SELECT * FROM dbo.DimDate;Selezionare la scheda Messaggi e registra l'ID dichiarazione per l'esecuzione della query. Nell'editor di query SQL,
program_nameèDMS_usere è stato configurato per utilizzare in seguito il pool SQL personalizzatoMyContosoApp.Attendere 10-15 minuti per il popolamento delle informazioni dettagliate sulle query.
Recuperare le
sql_pool_nameinformazioni e altre per verificare che sia stato usato il pool SQL personalizzato appropriato.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
Ripristinare la configurazione dei pool SQL personalizzati
Per restituire l'area di lavoro allo stato originale, modificare la customSQLPoolsEnabled proprietà in False. Se si vuole mantenere la configurazione dei pool SQL personalizzati, è necessario passare ogni nome del pool come nell'elenco customSQLPools .
Questo codice Python di esempio disabilita i pool SQL personalizzati e ripristina la configurazione autonoma della gestione del carico di lavoro dei pool SELECT e non-SELECT. Viene chiamata una richiesta PATCH con proprietà customSQLPoolsEnabled impostata a False.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)
Contenuti correlati
- Pool SQL personalizzati
- API di configurazione pool SQL
- Gestione del carico di lavoro