Esercitazione: configurare il database con mirroring di Microsoft Fabric per Azure Cosmos DB (anteprima)
In questa esercitazione si configurerà un database con mirroring di Fabric da un account Azure Cosmos DB per NoSQL esistente.
Il mirroring replica in modo incrementale i dati di Azure Cosmos DB in Infrastruttura OneLake quasi in tempo reale, senza influire sulle prestazioni dei carichi di lavoro transazionali o sull'utilizzo di unità richiesta (UR). È possibile compilare report di Power BI direttamente sui dati in OneLake, usando la modalità DirectLake. È possibile eseguire query ad hoc in SQL o Spark, compilare modelli di dati usando notebook e usare funzionalità di intelligenza artificiale predefinite Copilot e avanzate in Fabric per analizzare i dati.
Importante
Il mirroring per Azure Cosmos DB attualmente è disponibile in anteprima. I carichi di lavoro di produzione non sono supportati durante l'anteprima. Attualmente sono supportati solo gli account Azure Cosmos DB for NoSQL.
Prerequisiti
- Un account Azure Cosmos DB per NoSQL già presente.
- Se non si ha un abbonamento ad Azure, prova gratuitamente Azure Cosmos DB per NoSQL.
- Se si ha dispone già di un abbonamento ad Azure, creare un nuovo account di Azure Cosmos DB for NoSQL.
- Una capacità di Fabric esistente. Se non si ha una capacità esistente, avviare una versione di valutazione di Fabric. Il mirroring potrebbe non essere disponibile in alcune aree di Fabric. Per altre informazioni, vedere Aree supportate.
Suggerimento
Durante l'anteprima pubblica, è consigliabile usare una copia di test o sviluppo dei dati di Azure Cosmos DB esistenti che possono essere recuperati rapidamente da un backup.
Configurare i propri account Azure Cosmos DB
Assicurarsi prima di tutto che l'account azure Cosmos DB di origine sia configurato correttamente per l'uso con il mirroring di Fabric.
Nel portale di Azure passare all'account Azure Cosmos DB.
Assicurarsi che il backup continuo sia abilitato. Se non è abilitato, seguire la guida alla migrazione di un account Azure Cosmos DB esistente al backup continuo per abilitare il backup continuo. Questa funzionalità potrebbe non essere disponibile in alcuni scenari. Per altre informazioni, vedere limiti di database e account.
Assicurarsi che le opzioni di rete siano impostate su accesso alla rete pubblica per tutte le reti. In caso contrario, seguire la guida Configurare l'accesso di rete a un account Azure Cosmos DB.
Creare un database con mirroring
A questo punto, creare un database con mirroring, che funge da destinazione per i dati replicati. Per altre informazioni, vedere Cosa aspettarsi dal mirroring.
Passare alla home page del Portale di Fabric.
Aprire un’area di lavoro esistente o crearne una nuova.
Nel menu di spostamento, selezionare Crea.
Selezionare Crea, individuare la sezione Data Warehouse e quindi selezionare Azure Cosmos DB con mirroring (anteprima).
Specificare un nome per il database con mirroring e quindi selezionare Crea.
Connettersi al database di origine
Connettere quindi il database di origine al database con mirroring
Nella sezione Nuova connessione, selezionare Azure Cosmos DB for NoSQL.
Specificare le credenziali per l'account Azure Cosmos DB for NoSQL, inclusi gli elementi seguenti:
Valore Endpoint Azure Cosmos DB Endpoint URL per l'account di origine. Nome connessione Nome univoco per la connessione Tipo di autenticazione Selezionare Chiave dell’account. Chiave dell’account Chiave di lettura-scrittura per l'account di origine. 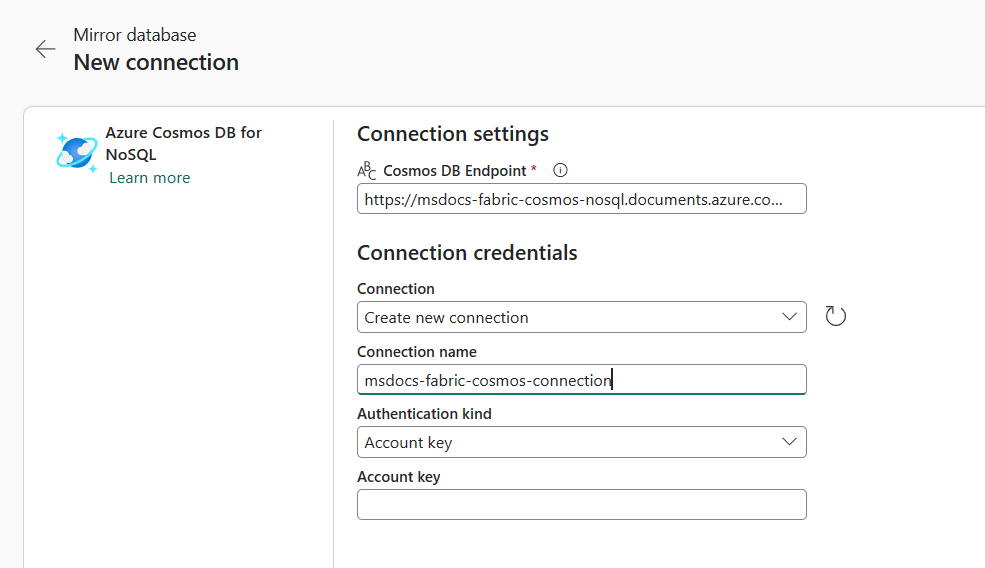
Selezionare Connetti. Selezionare quindi un database di cui eseguire il mirroring.
Nota
Tutti i contenitori nel database sono con mirroring.

Avviare il processo di mirroring
Selezionare Database mirror. A questo punto, il mirroring avrà inizio.
Attendere da due a cinque minuti. Quindi, selezionare Monitoraggio replica per visualizzare lo stato dell'azione di replica.
Dopo alcuni minuti, lo stato dovrebbe diventare In esecuzione, il che indica che i contenitori stanno venendo sincronizzati.
Suggerimento
Se non si riescono a trovare i contenitori e lo stato di replica corrispondente, attendere alcuni secondi e quindi aggiornare il riquadro. In rari casi, è possibile che vengano visualizzati messaggi di errore temporanei. È possibile ignorarli tranquillamente e continuare ad aggiornare il riquadro.
Quando il mirroring termina l’operazione di copia iniziale dei contenitori, verrà visualizzata una data nella colonna di ultimo aggiornamento. Se i dati sono stati replicati correttamente, la colonna delle righe totali conterrà il numero di elementi replicati.
Monitorare il mirroring di Fabric
Ora che i dati sono operativi, in Fabric esistono diversi scenari di analisi disponibili.
Dopo aver configurato il mirroring di Fabric, si verrà automaticamente reindirizzati al riquadro Stato replica.
Qui è possibile monitorare lo stato corrente della replica. Per altre informazioni e dettagli sugli stati di replica, vedere Monitorare la replica del database con mirroring di Fabric.
Eseguire query sul database di origine da Fabric
Usare il portale di Fabric per esplorare i dati già esistenti nell'account Azure Cosmos DB ed eseguire query sul database Cosmos DB di origine.
Passare al database con mirroring nel portale di Fabric.
Selezionare Visualizza, quindi Database di origine. Questa azione apre Esplora dati di Azure Cosmos DB con una vista di sola lettura del database di origine.
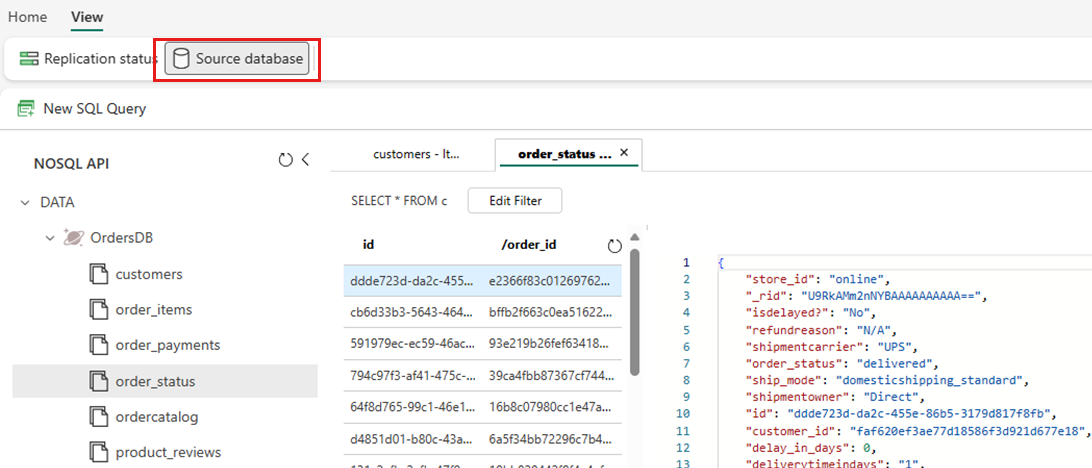
Selezionare un contenitore, quindi aprire il menu di scelta rapida e selezionare Nuova query SQL.
Esegue una qualsiasi query. Ad esempio, usare
SELECT COUNT(1) FROM containerper contare il numero di elementi nel contenitore.Nota
Tutte le letture nel database di origine vengono instradate ad Azure e utilizzeranno Unità richiesta (UR) allocate nell'account.

Analizzare il database con mirroring di destinazione
A questo punto, usare T-SQL per eseguire query sui dati NoSQL archiviati in Fabric OneLake.
Passare al database con mirroring nel portale di Fabric.
Passare da Azure Cosmos DB con mirroring all'Endpoint di Analisi SQL.
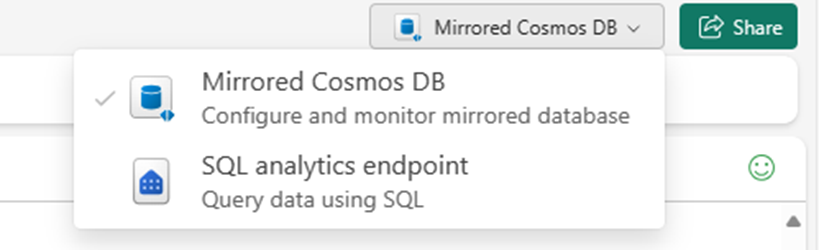
Ogni contenitore nel database di origine deve essere rappresentato nell'endpoint di analisi SQL come tabella warehouse.
Selezionare una tabella, aprire il menu di scelta rapida, quindi selezionare Nuova query SQL e infine selezionare Seleziona primi 100.
La query viene eseguita e restituisce 100 record nella tabella selezionata.
Aprire il menu di scelta rapida per la stessa tabella e selezionare Nuova query SQL. Scrivere una query di esempio che faccia uso di aggregazioni come
SUM,COUNT,MINoMAX. Unire più tabelle nel warehouse per eseguire la query in più contenitori.Nota
Ad esempio, questa query viene eseguita in più contenitori:
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]In questo esempio si presuppone il nome della tabella e delle colonne. Usare tabelle e colonne personalizzate durante la scrittura della query SQL.
Selezionare la query e quindi selezionare Salva come visualizzazione. Assegnare alla visualizzazione un nome univoco. È possibile accedere a questa visualizzazione in qualsiasi momento dal portale di Fabric.
Tornare al database con mirroring nel portale di Fabric.
Selezionare Nuova query visiva. Usare l'editor di query per compilare query complesse.
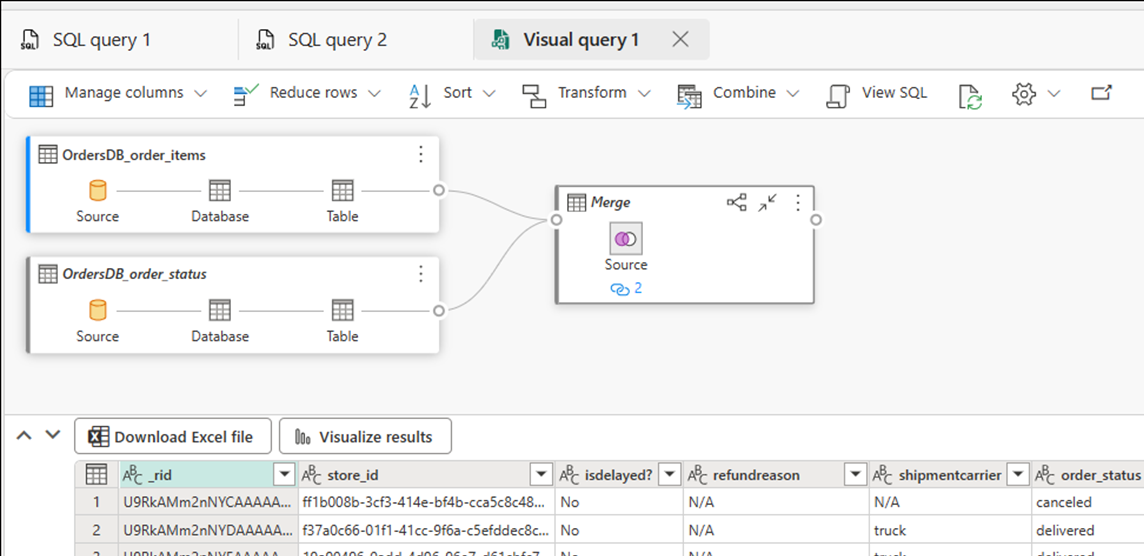


Creare report BI sulle query o sulle viste SQL
- Selezionare la query o la visualizzazione e quindi selezionare Esplora questi dati (anteprima). Quest’azione esplora direttamente la query in Power BI usando Direct Lake sui dati con mirroring di OneLake.
- Modificare i grafici in base alle esigenze e salvare il report.
Suggerimento
Facoltativamente, è anche possibile usare Copilot o alte migliorie per creare dashboard e report senza ulteriori spostamenti di dati.
Altri esempi
Altre informazioni su come accedere ed eseguire query su dati di Azure Cosmos DB con mirroring in Fabric:
- Procedura: Eseguire query sui dati annidati nei database con mirroring di Microsoft Fabric da Azure Cosmos DB (anteprima)
- Come fare a...: accedere ai dati di Azure Cosmos DB con mirroring in Lakehouse e ai notebook da Microsoft Fabric (anteprima)
- Procedura: Aggiungere dati di Azure Cosmos DB con mirroring con altri database con mirroring in Microsoft Fabric (anteprima)