Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Dopo aver esportato i dati da Microsoft Dataverse a Azure Data Lake Storage Gen2 con Collegamento a Azure Synapse per Dataverse, puoi usare Azure Data Factory per creare flussi di dati, trasformare i dati ed eseguire analisi.
Nota
In precedenza Azure Synapse Link per Dataverse era denominato Esporta in Data Lake. Il servizio è stato rinominato a partire da maggio 2021 e continuerà a esportare dati in Azure Data Lake nonché in Azure Synapse Analytics.
Questo articolo mostra come eseguire le seguenti attività:
Imposta l'account di archiviazione di Data Lake Storage Gen2 con dati Dataverse come origine in un flusso di dati di Data Factory.
Trasforma i dati di Dataverse in Data Factory con un flusso di dati.
Imposta l'account di archiviazione di Data Lake Storage Gen2 con dati Dataverse come sink in un flusso di dati di Data Factory.
Esegui il tuo flusso di dati creando una pipeline.
Prerequisiti
Questa sezione descrive i prerequisiti necessari per inserire i dati Dataverse esportati con Data Factory.
Ruoli di Azure. L'account utente utilizzato per accedere ad Azure deve essere un membro del ruolo contributore o proprietario o amministratore della sottoscrizione di Azure. Per visualizzare le autorizzazioni di cui disponi nella sottoscrizione, vai al portale di Azure, seleziona il tuo nome utente nell'angolo in alto a destra, seleziona ... e quindi seleziona Autorizzazioni personali. Se hai accesso a più sottoscrizioni, seleziona quella appropriata. Per creare e gestire risorse figlio per Data Factory nel portale di Azure inclusi set di dati, servizi collegati, pipeline, trigger e runtime di integrazione devi appartenere al ruolo Collaboratore Data factory a livello di gruppo di risorse o superiore.
Collegamento ad Azure Synapse per Dataverse. Questa guida presuppone che tu abbia già esportato i dati Dataverse utilizzando Azure Synapse Link for Dataverse. In questo esempio, i dati della tabella account vengono esportati nel data lake.
Azure Data Factory. Questa guida presuppone che tu abbia già creato un data factory con la stessa sottoscrizione e gruppo di risorse dell'account di archiviazione contenente i dati Dataverse esportati.
Imposta l'account di archiviazione Data Lake Storage Gen2 come origine
Apri Azure Data Factory e seleziona il data factory che si trova nella stessa sottoscrizione e gruppo di risorse dell'account di archiviazione contenente i dati Dataverse esportati. Quindi seleziona Crea flusso di dati dalla home page.
Attiva la modalità Debug del flusso di dati e seleziona l'ora preferita per il passaggio allos tato live. Questa operazione potrebbe richiedere fino a 10 minuti, ma puoi procedere con i seguenti passaggi.

Seleziona Aggiungi origine.

In Impostazioni origine, effettua le operazioni seguenti:
- Nome del flusso di output: immetti il nome desiderato.
- Tipo di origine: seleziona Inline.
- Tipo di set di dati inline: Seleziona Common Data Model.
- Servizio collegato: seleziona l'account di archiviazione dal menu a discesa, quindi collega un nuovo servizio fornendo i dettagli della sottoscrizione e lasciando tutte le configurazioni predefinite.
- Campionamento: se desideri utilizzare tutti i tuoi dati, seleziona Disattiva.
In Opzioni origine, eseguire le operazioni seguenti:
Formato dei metadati: seleziona Model.json.
Posizione principale: immetti il nome del contenitore nella prima casella (Contenitore) o Sfoglia per trovare il nome del contenitore e seleziona OK.
Entità: immetti il nome della tabella o Sfoglia per trovare la tabella.

Controlla la scheda Proiezione per assicurarti che lo schema sia stato importato correttamente. Se non vedi alcuna colonna, seleziona Opzioni dello schema e controlla l'opzione Deduci i tipi di colonna spostati. Configura le opzioni di formattazione in modo che corrispondano al tuo set di dati, quindi seleziona Applica.
Puoi visualizzare i tuoi dati nella scheda Anteprima dati per garantire che la creazione dell'origine fosse completa e accurata.
Trasfomare i dati di Dataverse
Dopo aver impostato i dati Dataverse esportati nell'account Azure Data Lake Storage Gen2 come origine nel flusso di dati di Data Factory, vi sono molte possibilità per trasformare i dati. Maggiori informazioni: Azure Data Factory
Segui queste istruzioni per creare una classificazione per ogni riga del campo ricavi della tabella account.
Seleziona + nell'angolo inferiore destro della trasformazione precedente, quindi cerca e seleziona Classificazione.
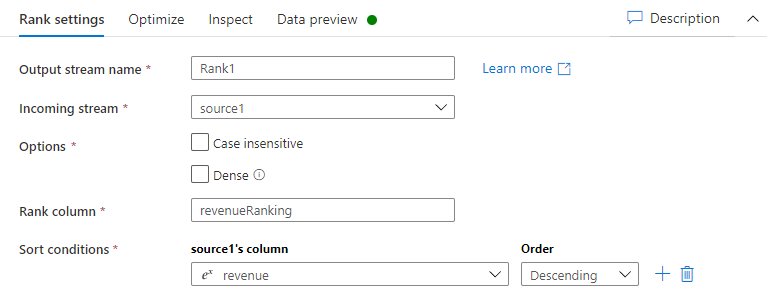
Nella scheda Impostazioni classificazione, immetti le informazioni seguenti:
Nome del flusso di output: immetti il nome desiderato, ad esempio Rank1.
Flusso in arrivo: seleziona il nome dell'origine desiderata. In questo caso, il nome dell'origine dal passaggio precedente.
Opzioni: lascia le opzioni deselezionate.
Colonna classificazione: immetti il nome della colonna di classificazione generata.
Condizione ordinamento: seleziona la colonna dei ricavi e scegli l'ordine Decrescente.
Puoi visualizzare i tuoi dati nella scheda Anteprima dati dove troverai la nuova colonna revenueRank nella posizione più a destra.
Imposta l'account di archiviazione Data Lake Storage Gen2 come sink
Infine, devi impostare un sink per il flusso di dati. Segui queste istruzioni per inserire i dati trasformati come file di testo delimitato nel Data Lake.
Seleziona + nell'angolo inferiore destro della trasformazione precedente, quindi cerca e seleziona Sink.
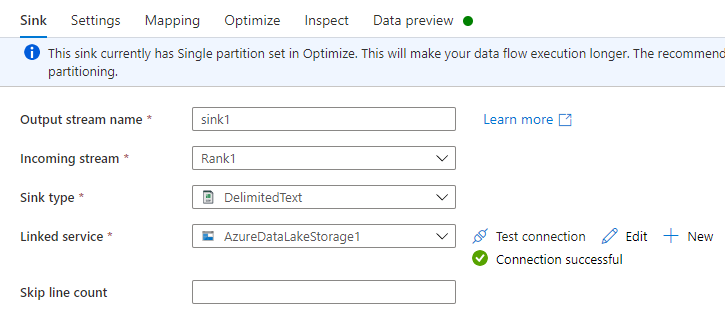
Nella scheda Sink esegui una delle procedure seguenti:
Nome del flusso di output: immetti il nome desiderato, ad esempio Sink1.
Flusso in arrivo: seleziona il nome dell'origine desiderata. In questo caso, il nome dell'origine dal passaggio precedente.
Tipo di sink: seleziona DelimitedText.
Servizio collegato: seleziona il contenitore di archiviazione Data Lake Storage Gen2 contenente i dati esportati utilizzando il servizio Collegamento a Azure Synapse per Dataverse.
Nella scheda Impostazioni puoi effettuare le operazioni seguenti:
Percorso cartella: immetti il nome del contenitore nella prima casella (File system) o Sfoglia per trovare il nome del contenitore e seleziona OK.
Opzione nome file: seleziona output in un singolo file.
Output su file singolo: immetti un nome file, ad esempio ADFOutput
Lascia tutte le altre impostazioni predefinite.
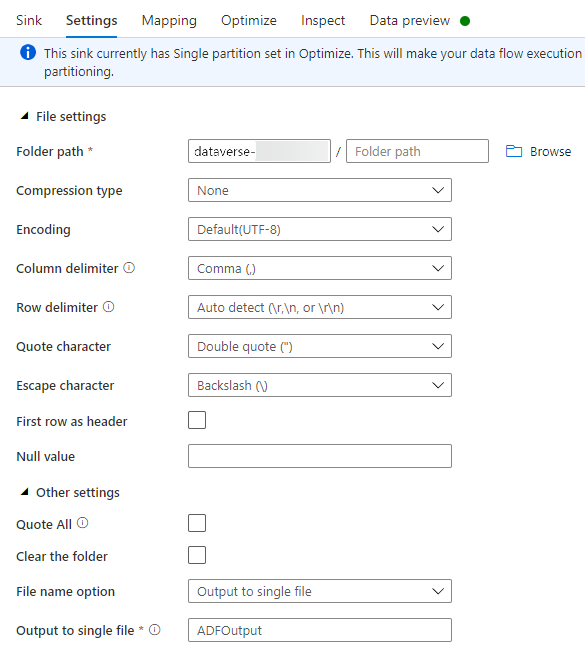
Nella scheda Ottimizza, impostare Opzione di partizione su Partizione singola.
Puoi visualizzare i tuoi dati nella scheda Anteprima dati.
Esegui il tuo flusso di dati
Nel riquadro di sinistra in Risorse di fabbrica, seleziona +, quindi seleziona Pipeline.

In Attività, seleziona Sposta e trasforma, quindi trascina Flusso di dati nell'area di lavoro.
Seleziona Usa il flusso di dati esistente, quindi seleziona il flusso di dati creato nei passaggi precedenti.
Nella barra dei comandi, seleziona Debug.
Lascia che il flusso di dati venga eseguito finché la vista inferiore non mostra che è stato completato. L'operazione potrebbe richiedere alcuni minuti.
Vai al contenitore di archiviazione di destinazione finale e trova il file di dati della tabella trasformato.
Vedi anche
Configurare Azure Synapse Link for Dataverse con Azure Data Lake
Analisi dei dati Dataverse in Azure Data Lake Storage Gen2 con Power BI