Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Tip
Power BI Dataflow Gen1 è ora in uno stato legacy e non riceverà nuovi investimenti di funzionalità. Invece di creare un dashboard di monitoraggio personalizzato, Dataflow Gen2 fornisce il rilevamento predefinito degli aggiornamenti tramite l'hub di monitoraggio in Microsoft Fabric, con informazioni dettagliate sullo stato, sulla durata e sugli errori in tempo reale. Per informazioni sull'aggiornamento dei flussi di dati esistenti, vedere Eseguire l'aggiornamento da Dataflow Gen1 a Dataflow Gen2.
I flussi di dati di Power BI consentono di connettersi, trasformare, combinare e distribuire i dati per l'analisi downstream. Un elemento chiave nei flussi di dati è il processo di aggiornamento, che applica i passaggi di trasformazione creati nei flussi di dati e aggiorna i dati negli elementi stessi.
Per comprendere i tempi di esecuzione, le prestazioni e se si ottiene il massimo dal flusso di dati, è possibile scaricare la cronologia degli aggiornamenti dopo l'aggiornamento di un flusso di dati.
Comprensione dei rinfreschi
Esistono due tipi di aggiornamenti applicabili ai flussi di dati:
Completa, che esegue uno scaricamento completo e ricaricamento dei dati.
Incrementale (solo Premium), che elabora un subset dei tuoi dati in base a regole basate sul tempo, espresse come filtri e che configuri. Il filtro sulla colonna data partiziona dinamicamente i dati in intervalli nel servizio Power BI. Dopo aver configurato l'aggiornamento incrementale, il flusso di dati modifica automaticamente la query in modo da includere il filtro in base alla data. È possibile modificare la query generata automaticamente usando l'editor avanzato in Power Query per ottimizzare o personalizzare l'aggiornamento. Se si usa Azure Data Lake Storage personalizzato, è possibile visualizzare le sezioni temporali dei dati in base ai criteri di aggiornamento impostati.
Annotazioni
Per altre informazioni sull'aggiornamento incrementale e sul relativo funzionamento, vedere Uso dell'aggiornamento incrementale con flussi di dati.
L'aggiornamento incrementale consente flussi di dati di grandi dimensioni in Power BI con i vantaggi seguenti:
Gli aggiornamenti sono più veloci dopo il primo aggiornamento, a causa dei fatti seguenti:
- Power BI aggiorna le ultime N partizioni specificate dall'utente (dove la partizione è giorno/settimana/mese e così via) o
- Power BI aggiorna solo i dati che devono essere aggiornati. Ad esempio, l'aggiornamento solo degli ultimi cinque giorni di un modello semantico di 10 anni.
- Power BI aggiorna solo i dati che sono stati modificati, purché si specifichi la colonna da controllare per verificare la presenza di modifiche.
Gli aggiornamenti sono più affidabili: non è più necessario mantenere connessioni a esecuzione prolungata ai sistemi di origine volatili.
Il consumo di risorse è ridotto: meno dati da aggiornare riducono il consumo complessivo di memoria e altre risorse.
Laddove possibile, Power BI usa l'elaborazione parallela nelle partizioni, che può portare a aggiornamenti più rapidi.
In uno di questi scenari di aggiornamento, se un aggiornamento non riesce, i dati non vengono aggiornati. I tuoi dati potrebbero non essere aggiornati fino al completamento dell'ultimo aggiornamento, oppure puoi aggiornarli manualmente e l'aggiornamento si completerà senza errori. L'aggiornamento si verifica in una partizione o un'entità, quindi se un aggiornamento incrementale ha esito negativo o se un'entità presenta un errore, l'intera transazione di aggiornamento non si verifica. In altre parole, se una partizione (criteri di aggiornamento incrementale) o un'entità ha esito negativo per un flusso di dati, l'intera operazione di aggiornamento ha esito negativo e non vengono aggiornati dati.
Comprendere e ottimizzare gli aggiornamenti
Per comprendere meglio come si svolge un'operazione di aggiornamento del flusso di dati, esaminare la Cronologia aggiornamenti passando a uno dei flussi di dati. Selezionare Altre opzioni (...) per il flusso di dati. Scegliere quindi Impostazioni > Aggiorna cronologia. È anche possibile selezionare il flusso di dati nell'area di lavoro. Scegliere quindi Altre opzioni (...) > Cronologia aggiornamenti.
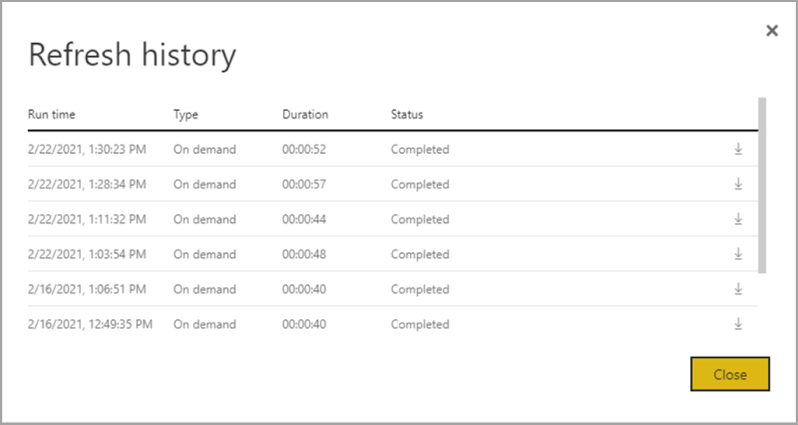
La cronologia aggiornamenti offre una panoramica degli aggiornamenti, tra cui il tipo , su richiesta o pianificato, la durata e lo stato dell'esecuzione. Per visualizzare i dettagli sotto forma di file CSV, selezionare l'icona di download all'estrema destra della riga della descrizione dell'aggiornamento. Il file CSV scaricato include gli attributi descritti nella tabella seguente. Gli aggiornamenti Premium offrono altre informazioni in base alle funzionalità di calcolo e flussi di dati aggiuntive, rispetto ai flussi di dati basati su Pro che risiedono nella capacità condivisa. Di conseguenza, alcune delle metriche seguenti sono disponibili solo in Premium.
| Elemento | Description | Pro | Di alta qualità |
|---|---|---|---|
| Richiesto il | L'aggiornamento è stato pianificato o è stato cliccato su aggiorna ora, in ora locale. | ✔ | ✔ |
| Nome del flusso di dati | Nome del flusso di dati. | ✔ | ✔ |
| Stato dell'aggiornamento del flusso di dati | Completato, Non riuscito o Saltato (per un'entità) sono possibili stati. I casi d'uso come le entità collegate sono motivi per cui si potrebbe vedere ignorato. | ✔ | ✔ |
| Nome entità | Nome della tabella. | ✔ | ✔ |
| Nome partizione | Questo elemento dipende dal fatto che il flusso di dati è Premium o meno e se Pro viene visualizzato come NA perché non supporta gli aggiornamenti incrementali. Premium visualizza FullRefreshPolicyPartition o IncrementalRefreshPolicyPartition-[DateRange]. | ✔ | |
| Stato di aggiornamento | Stato di aggiornamento della singola entità o partizione, che fornisce lo stato per la sezione temporale dei dati da aggiornare. | ✔ | ✔ |
| Ora di avvio | In Premium, questo elemento indica il momento in cui il flusso di dati è stato accodato per l'elaborazione per l'entità o la partizione. Questo tempo può variare se i flussi di dati hanno dipendenze e devono attendere che l'insieme di risultati di un flusso di dati upstream inizi l'elaborazione. | ✔ | ✔ |
| Ora di fine | Ora di fine è l'ora in cui l'entità o la partizione del flusso di dati è stata completata, se applicabile. | ✔ | ✔ |
| Durata | Tempo totale trascorso per l'aggiornamento del flusso di dati espresso in HH:MM:SS. | ✔ | ✔ |
| Righe elaborate | Per una determinata entità o partizione, il numero di righe analizzate o scritte dal motore dei flussi di dati. Questo elemento potrebbe non contenere sempre dati in base all'operazione eseguita. I dati potrebbero essere omessi quando il motore di calcolo non viene usato o quando si usa un gateway durante l'elaborazione dei dati. | ✔ | |
| Byte elaborato | Per una determinata entità o partizione, i dati scritti dal motore dei flussi di dati, espressi in byte. Quando si usa un gateway in questo particolare flusso di dati, queste informazioni non vengono fornite. |
✔ | |
| Commit massimo (KB) | Il Max Commit è la memoria di commit di picco utile per la diagnosi di malfunzionamenti dovuti a memoria insufficiente quando la query M non è ottimizzata. Quando si usa un gateway in questo particolare flusso di dati, queste informazioni non vengono fornite. |
✔ | |
| Tempo CPU | Per una determinata entità o partizione, il tempo espresso in HH:MM:SS che il motore di dataflow ha trascorso eseguendo le trasformazioni. Quando si usa un gateway in questo particolare flusso di dati, queste informazioni non vengono fornite. |
✔ | |
| Tempo di attesa | Per una determinata entità o partizione, il tempo impiegato da un'entità nello stato di attesa, in base al carico di lavoro sulla capacità Premium. | ✔ | |
| Motore di calcolo | Per una determinata entità o partizione, vengono fornite informazioni dettagliate sul modo in cui l'operazione di aggiornamento usa il motore di calcolo. I valori sono: -NA - Piegato -Memorizzati nella cache - Memorizzato nella cache + piegato Questi elementi sono descritti in modo più dettagliato più avanti in questo articolo. |
✔ | |
| Errore | Se applicabile, il messaggio di errore dettagliato viene descritto per entità o partizione. | ✔ | ✔ |
Linee guida per l'aggiornamento del flusso di dati
Le statistiche di aggiornamento forniscono informazioni preziose che è possibile usare per ottimizzare e velocizzare le prestazioni dei flussi di dati. Nelle sezioni seguenti vengono descritti alcuni scenari, cosa prestare attenzione e come ottimizzare in base alle informazioni fornite.
Orchestrazione
L'uso dei flussi di dati nella stessa area di lavoro consente un'orchestrazione semplice. Ad esempio, potrebbero essere presenti flussi di dati A, B e C in una singola area di lavoro e concatenamento come A > B > C. Se si aggiorna l'origine (A), vengono aggiornate anche le entità downstream. Tuttavia, se si aggiorna C, è necessario aggiornare altri in modo indipendente. Inoltre, se si aggiunge una nuova origine dati nel flusso di dati B (che non è incluso in A) i dati non vengono aggiornati come parte dell'orchestrazione.
Potresti voler collegare gli elementi che non si adattano all'orchestrazione gestita eseguita da Power BI. In questi scenari è possibile usare le API e/o usare Power Automate. È possibile fare riferimento alla documentazione dell'API e allo script di PowerShell per l'aggiornamento a livello di codice. È disponibile un connettore Power Automate che consente di eseguire questa procedura senza scrivere codice. È possibile visualizzare esempi dettagliati, con procedure dettagliate specifiche per gli aggiornamenti sequenziali.
Monitoraggio
Usando le statistiche di aggiornamento avanzate descritte in precedenza in questo articolo, è possibile ottenere informazioni dettagliate sull'aggiornamento per flusso di dati. Tuttavia, se si vogliono visualizzare flussi di dati con una panoramica a livello di tenant o a livello di area di lavoro degli aggiornamenti, ad esempio per creare un dashboard di monitoraggio, è possibile usare le API o imodelli di Power Automate. Analogamente, per casi d'uso come l'invio di notifiche semplici o complesse, è possibile usare il connettore Power Automate o creare un'applicazione personalizzata usando le API.
Errori di timeout
L'ottimizzazione del tempo necessario per eseguire scenari di estrazione, trasformazione e caricamento (ETL) è ideale. In Power BI si applicano i casi seguenti:
- Alcuni connettori hanno impostazioni di timeout esplicite che è possibile configurare. Per altre informazioni, vedere Connettori in Power Query.
- I flussi di dati di Power BI, che utilizzano Power BI Pro, possono riscontrare timeout durante l'esecuzione di query prolungate all'interno di un'entità o nei propri flussi di dati. Tale limitazione non esiste nelle aree di lavoro di Power BI Premium.
Indicazioni sul timeout
Le soglie di timeout per i flussi di dati di Power BI Pro sono:
- Due ore a livello di singola entità.
- Tre ore a livello di flusso di dati intero.
Ad esempio, se si dispone di un flusso di dati con tre tabelle, nessuna singola tabella può richiedere più di due ore e l'intero flusso di dati raggiunge il timeout se la durata supera tre ore.
Se si verificano timeout, valutare la possibilità di ottimizzare le query sui flussi di dati e considerare l'uso del query folding nei sistemi di origine.
Inoltre, prendere in considerazione l'upgrade a Premium per utente, che non è soggetto a questi timeout e offre prestazioni migliorate grazie a numerose funzionalità di Power BI Premium per utente.
Durate lunghe
I flussi di dati complessi o di grandi dimensioni possono richiedere più tempo per l'aggiornamento, così come quelli ottimizzati in modo non adeguato. Le sezioni seguenti forniscono indicazioni su come attenuare le durate di aggiornamento lunghe.
Linee guida per durate lunghe di aggiornamento
Il primo passaggio per migliorare le durate di aggiornamento lunghe per i flussi di dati consiste nel creare flussi di dati in base alle procedure consigliate. I modelli rilevanti includono:
- Usare le entità collegate per dati che possono essere utilizzati in un secondo momento in altre trasformazioni.
- Usare le entità calcolate per memorizzare nella cache i dati, riducendo il carico di caricamento dei dati e il carico di inserimento dati nei sistemi di origine.
- Suddividere i dati in flussi di dati di staging e flussi di dati di trasformazione, separando l'ETL in flussi di dati diversi.
- Ottimizzare le operazioni di espansione delle tabelle.
- Seguire le indicazioni per flussi di dati complessi.
Può quindi essere utile per valutare se è possibile usare l'aggiornamento incrementale.
L'uso dell'aggiornamento incrementale può migliorare le prestazioni. È importante che i filtri di partizione vengano inseriti nel sistema di origine quando le query vengono inviate per le operazioni di aggiornamento. Per eseguire il push del filtro verso il basso, l'origine dati deve supportare la riduzione delle query oppure è possibile esprimere la logica di business tramite una funzione o altri mezzi che consentono a Power Query di eliminare e filtrare file o cartelle. La maggior parte delle origini dati che supportano le query SQL consente il ripiegamento delle query, e alcuni feed OData possono anche supportare il filtraggio.
Tuttavia, origini dati come file flat, BLOB e API in genere non supportano il filtro. Nei casi in cui il back-end dell'origine dati non supporta il filtro, non è possibile fare il pushdown. In questi casi, il motore di mash-up compensa e applica il filtro in locale, che potrebbe richiedere il recupero del modello semantico completo dall'origine dati. Questa operazione può causare un rallentamento dell'aggiornamento incrementale e il processo può esaurire le risorse nel servizio Power BI o nel gateway dati locale, se usato.
Dato i vari livelli di supporto per la riduzione delle query per ogni origine dati, è necessario eseguire la verifica per assicurarsi che la logica del filtro sia inclusa nelle query di origine. Per semplificare questa operazione, Power BI tenta di eseguire questa verifica, con indicatori di riduzione dei passaggi per Power Query Online. Molte di queste ottimizzazioni sono esperienze in fase di progettazione, ma dopo un aggiornamento è possibile analizzare e ottimizzare le prestazioni di aggiornamento.
Infine, prendere in considerazione l'ottimizzazione dell'ambiente. È possibile ottimizzare l'ambiente Power BI aumentando la capacità, ridimensionando correttamente i gateway dati e riducendo la latenza di rete con le ottimizzazioni seguenti:
Quando si usano le capacità disponibili con Power BI Premium o Premium per utente, è possibile aumentare le prestazioni aumentando l'istanza Premium o assegnando il contenuto a una capacità diversa.
Un gateway è necessario ogni volta che Power BI deve accedere ai dati non disponibili direttamente tramite Internet. È possibile installare il gateway dati locale su un server locale o su una macchina virtuale.
- Per informazioni sui carichi di lavoro e sulle dimensioni dei gateway, vedere Dimensionamento del gateway dati locale.
- Valutare anche l'importazione iniziale dei dati in un dataflow di staging e il loro riferimento a valle utilizzando entità collegate e calcolate.
La latenza di rete può influire sulle prestazioni di aggiornamento aumentando il tempo necessario per le richieste per raggiungere il servizio Power BI e per fornire risposte. I tenant in Power BI vengono assegnati a un'area specifica. Per determinare dove si trova il tenant, vedere Trovare l'area predefinita per l'organizzazione. Quando gli utenti di un tenant accedono al servizio Power BI, le richieste instradano sempre a tale area. Quando le richieste raggiungono il servizio Power BI, il servizio potrebbe quindi inviare richieste aggiuntive, ad esempio, all'origine dati sottostante o a un gateway dati, anch'esso soggetto alla latenza di rete.
- Strumenti come Test di velocità di Azure forniscono un'indicazione della latenza di rete tra il client e l'area di Azure. In generale, per ridurre al minimo l'impatto della latenza di rete, cercare di mantenere le origini dati, i gateway e il cluster Power BI il più vicino possibile. È preferibile risiedere nella stessa area. Se la latenza di rete è un problema, provare a individuare gateway e origini dati più vicini al cluster di Power BI inserendoli all'interno di macchine virtuali ospitate nel cloud.
Tempo elevato del processore
Se si nota un tempo di utilizzo elevato del processore, è probabile che si verifichino trasformazioni costose che non vengono ottimizzate. Il tempo elevato del processore è dovuto al numero di passaggi applicati o al tipo di trasformazioni che si sta effettuando. Ognuna di queste possibilità può comportare tempi di aggiornamento più elevati.
Linee guida per tempi di elaborazione elevati
Sono disponibili due opzioni per ottimizzare il tempo di elaborazione elevato.
In primo luogo, usa il folding delle query all'interno della stessa origine dati, per ridurre il carico sul motore di calcolo del flusso di dati. Il ripiegamento delle query all'interno della sorgente dati consente al sistema di origine di eseguire la maggior parte del lavoro. Il flusso di dati può quindi passare attraverso query nel linguaggio nativo dell'origine, anziché dover eseguire tutti i calcoli in memoria dopo la query iniziale.
Non tutte le origini dati possono eseguire la riduzione delle query e, anche quando possibile, ci possono essere flussi di dati che eseguono determinate trasformazioni che non possono essere ricondotte all'origine. In questi casi, il motore di calcolo avanzato è una funzionalità introdotta da Power BI per migliorare potenzialmente le prestazioni fino a 25 volte, per le trasformazioni in particolare.
Usare il motore di calcolo per ottimizzare le prestazioni
Mentre Power Query ha visibilità in fase di progettazione sulla piega delle query, la colonna del motore di calcolo fornisce informazioni dettagliate sull'uso effettivo del motore interno. Il motore di calcolo è utile quando si dispone di un flusso di dati complesso e si eseguono trasformazioni in memoria. Questa situazione è la posizione in cui le statistiche di aggiornamento avanzate possono essere utili, poiché la colonna del motore di calcolo fornisce informazioni dettagliate sull'uso o meno del motore stesso.
Le sezioni seguenti forniscono indicazioni sull'uso del motore di calcolo e sulle relative statistiche.
Avvertimento
Durante la fase di progettazione, l'indicatore di riduzione nell'editor potrebbe indicare che la query non si riduce quando si utilizzano dati da un altro flusso di dati. Controllare il flusso di dati di origine se è abilitata l'elaborazione avanzata per assicurarsi che la compressione del flusso di dati di origine sia abilitata.
Indicazioni sugli stati del motore di calcolo
L'attivazione del motore di calcolo avanzato e la comprensione dei vari stati è utile. Internamente, il motore di calcolo avanzato usa un database SQL per leggere e archiviare i dati. È consigliabile eseguire le trasformazioni contro il motore di query qui. I paragrafi seguenti forniscono varie situazioni e indicazioni sulle operazioni da eseguire per ognuna.
NA : questo stato indica che il motore di calcolo non è stato usato, perché:
- Si usano flussi di dati di Power BI Pro.
- Il motore di calcolo è stato disattivato in modo esplicito.
- Stai utilizzando il ripiegamento delle query sull'origine dati.
- Si eseguono trasformazioni complesse che non possono usare il motore SQL usato per velocizzare le query.
Se si verificano durate lunghe e si ottiene comunque lo stato na, assicurarsi che sia attivato e non disattivato accidentalmente. Un modello consigliato consiste nell'usare i flussi di dati di staging per importare inizialmente i dati nel servizio Power BI, quindi costruire flussi di dati sopra questi, una volta che i dati si trovano già in un flusso di dati di staging. Questo modello può ridurre il carico sui sistemi di origine e, insieme al motore di calcolo, offre una spinta rapida per le trasformazioni e migliorare le prestazioni.
Memorizzato nella cache : se viene visualizzato lo stato memorizzato nella cache , i dati del flusso di dati sono stati archiviati nel motore di calcolo e disponibili per essere referenziati come parte di un'altra query. Questa situazione è ideale se viene usata come entità collegata, perché il motore di calcolo memorizza nella cache i dati per l'uso a valle. I dati memorizzati nella cache non devono essere aggiornati più volte nello stesso flusso di dati. Questa situazione è anche potenzialmente ideale se si vuole usarla per DirectQuery.
Quando viene memorizzata nella cache, l'impatto sulle prestazioni dell'inserimento iniziale viene compensato in un momento successivo, nello stesso flusso di dati o in un flusso di dati diverso nella stessa area di lavoro.
Se si ha una durata elevata per l'entità, è consigliabile disattivare il motore di calcolo. Per memorizzare nella cache l'entità, Power BI lo scrive nell'archiviazione e in SQL. Se si tratta di un'entità a uso singolo, il vantaggio in termini di prestazioni per gli utenti potrebbe non giustificare la penalizzazione della doppia ingestione.
Piegato significa che il flusso di dati è in grado di utilizzare il calcolo SQL per leggere i dati. L'entità calcolata ha usato la tabella da SQL per leggere i dati, e l'SQL usato è correlato ai costrutti della loro query.
Lo stato piegato viene visualizzato se, quando si usano origini dati locali o cloud, i dati sono stati caricati prima in un flusso di dati di staging e si è fatto riferimento a tale flusso di dati in questo flusso di dati. Questo stato si applica solo alle entità che fanno riferimento a un'altra entità. Ciò significa che le query sono state eseguite sopra il motore SQL e hanno il potenziale per essere migliorate con il calcolo SQL. Per garantire che il motore SQL elabori le trasformazioni, usare trasformazioni che supportano il SQL folding, ad esempio merge (join), raggruppa per (aggregazione) e accoda (unione) nell'Editor di Query.
Cached + Folded : quando viene visualizzato memorizzato nella cache + piegato, è probabile che l'aggiornamento dei dati sia ottimizzato, poiché si dispone di un'entità che fa riferimento a un'altra entità e a cui fa riferimento un'altra entità upstream. Questa operazione viene eseguita anche su SQL e, di conseguenza, ha anche il potenziale per il miglioramento con il calcolo SQL. Per assicurarsi di ottenere le migliori prestazioni possibili, usare trasformazioni che supportano la piegatura SQL, ad esempio merge (join), raggruppamento in base a (aggregazione) e azioni di accodamento (unione) nell'Editor query.
Linee guida per l'ottimizzazione delle prestazioni del motore di calcolo
I passaggi seguenti consentono ai carichi di lavoro di attivare il motore di calcolo e di conseguenza migliorare sempre le prestazioni.
Entità calcolate e collegate nella stessa area di lavoro:
Per l'inserimento, concentrarsi sull'inserimento dei dati nella memoria il più velocemente possibile, usare i filtri solo se riducono le dimensioni complessive del modello semantico. Mantenere la logica di trasformazione separata da questo passaggio. Separare quindi la trasformazione e la logica di business in un flusso di dati separato nella stessa area di lavoro. Usare entità collegate o calcolate. In questo modo il motore può attivare e accelerare i calcoli. Per una semplice analogia, è come la preparazione alimentare in una cucina: la preparazione alimentare è in genere un passaggio separato e distinto dalla raccolta degli ingredienti crudi, e un prerequisito per mettere il cibo nel forno. Analogamente, è necessario preparare la logica separatamente prima di poter sfruttare i vantaggi del motore di calcolo.
Assicurarsi di eseguire le operazioni che includono, ad esempio, merge, join, conversione e altre.
Inoltre, compilare flussi di dati all'interno di linee guida e limitazioni pubblicate.
Quando il motore di calcolo è attivo, ma le prestazioni sono lente:
Eseguire i passaggi seguenti durante l'analisi degli scenari in cui è attivo il motore di calcolo, ma si riscontrano prestazioni scarse:
- Limitare le entità calcolate e collegate esistenti nell'area di lavoro.
- Se l'aggiornamento iniziale viene eseguito con il motore di calcolo acceso, i dati vengono scritti nel data lake e nella cache. Questa doppia scrittura comporta un rallentamento dei rinfreschi.
- Se si dispone di un flusso di dati collegato a più flussi di dati, assicurarsi di pianificare gli aggiornamenti dei flussi di dati di origine in modo che non vengano aggiornati contemporaneamente.
Considerazioni e limitazioni
Una licenza di Power BI Pro ha un limite di aggiornamento dei flussi di dati di 8 aggiornamenti al giorno.
Contenuti correlati
- Uso dell'aggiornamento incrementale con flussi di dati
- Aggiornamento incrementale e dati in tempo reale per i modelli semantici
- Procedure consigliate per i flussi di dati
- Funzionalità Premium dei flussi di dati
- Considerazioni e limitazioni per i flussi di dati
- Risolvere i problemi relativi agli scenari di aggiornamento