Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
I flussi di dati sono supportati per gli utenti di Power BI Pro, Premium Per Utente (PPU) e Power BI Premium. Alcune funzionalità sono disponibili solo con una sottoscrizione di Power BI Premium (ovvero una capacità Premium o una licenza PPU). Questo articolo descrive e illustra in dettaglio le funzionalità solo Premium e PPU e come vengono usate.
Le seguenti funzionalità sono disponibili solo con Power BI Premium (PPU o una sottoscrizione di capacità Premium):
- Motore di calcolo avanzato
- DirectQuery
- Entità calcolate
- Entità collegate
- Aggiornamento incrementale
Le sezioni seguenti descrivono in dettaglio ognuna di queste funzionalità.
Importante
Questo articolo si applica alla prima generazione di flussi di dati (Gen1) e non si applica alla seconda generazione (Gen2) dei flussi di dati, disponibili in Microsoft Fabric. Per altre informazioni, vedere Eseguire l'aggiornamento da Dataflow Gen1 a Dataflow Gen2.
Motore di calcolo avanzato
Il motore di calcolo avanzato in Power BI consente ai sottoscrittori di Power BI Premium di usare la propria capacità per ottimizzare l'uso dei flussi di dati. L'uso del motore di calcolo avanzato offre i vantaggi seguenti:
- Riduzione drastica del tempo di aggiornamento necessario per i passaggi ETL (estrazione, trasformazione e caricamento ) con esecuzione prolungata sulle entità calcolate, ad esempio l'esecuzione di operazioni join, distinct, filter e group by.
- Esegue le query DirectQuery sulle entità.
Note
- I processi di convalida e aggiornamento informano i flussi di dati dello schema del modello. Per impostare manualmente lo schema delle tabelle, usare l'editor di Power Query e impostare i tipi di dati.
- Questa funzionalità è disponibile in tutti i cluster di Power BI ad eccezione di WABI-INDIA-CENTRAL-A-PRIMARY
Abilitare il motore di calcolo avanzato
Importante
Il motore di calcolo avanzato funziona solo per le capacità di Power BI A3 o successive.
In Power BI Premium il motore di calcolo avanzato viene impostato singolarmente per ogni flusso di dati. Esistono tre configurazioni tra cui scegliere:
Disattivato
Ottimizzato (impostazione predefinita): il motore di calcolo avanzato è disattivato. Viene attivato automaticamente quando viene fatto riferimento a una tabella nel flusso di dati da un'altra tabella o quando il flusso di dati è connesso a un altro flusso di dati nella stessa area di lavoro.
On
Per modificare l'impostazione predefinita e abilitare il motore di calcolo avanzato, seguire questa procedura:
Nell'area di lavoro, accanto al flusso di dati per cui si desidera modificare le impostazioni, selezionare Altre opzioni.
Nel menu Altre opzioni del flusso di dati selezionare Impostazioni.
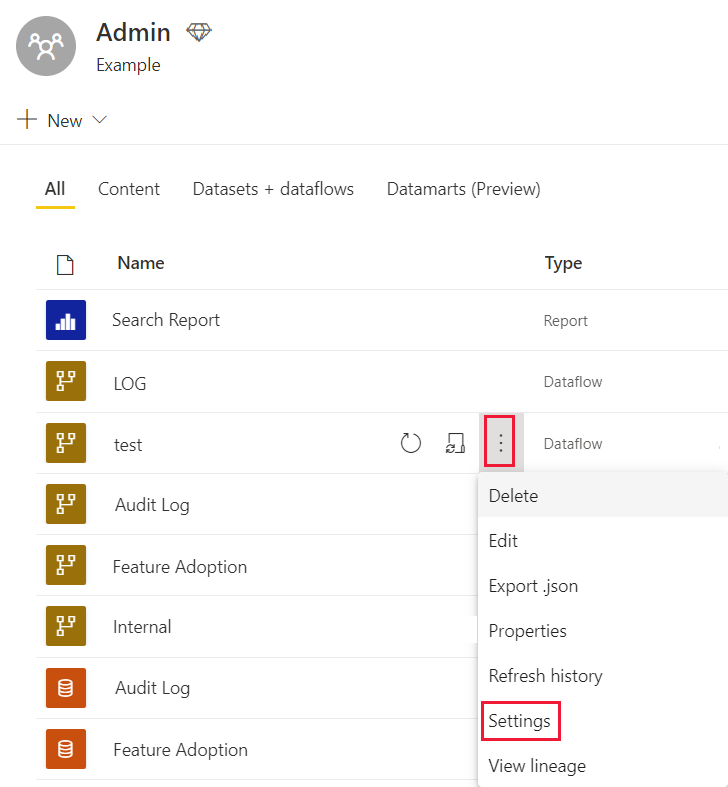
Espandere le impostazioni del motore di calcolo avanzato.
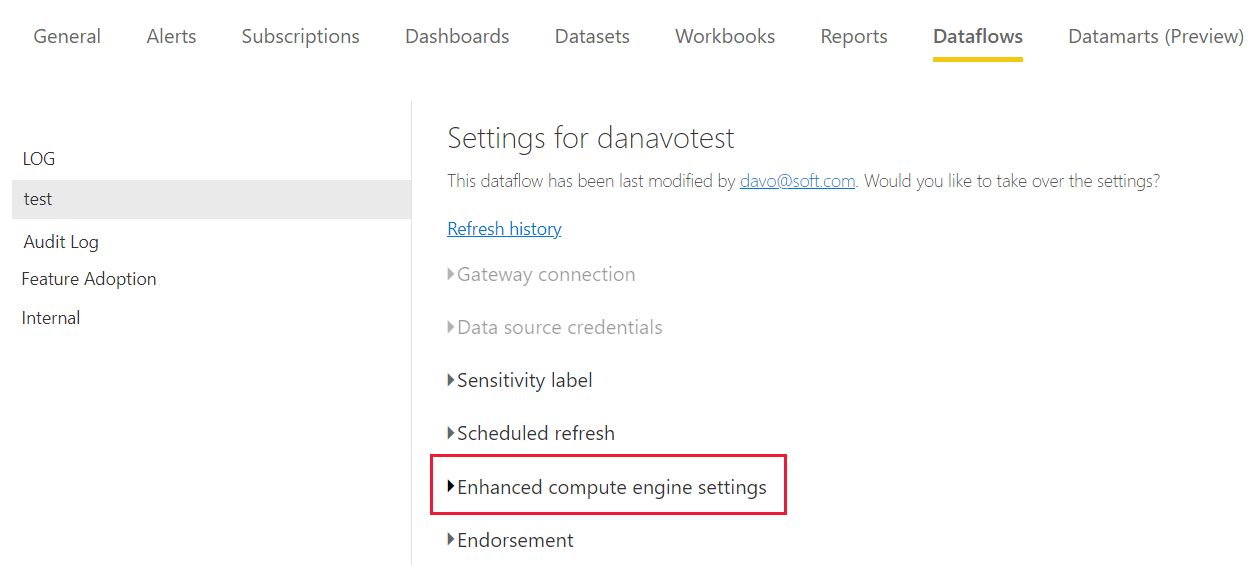
Nelle impostazioni del motore di calcolo avanzato selezionare Sì e quindi scegliere Applica.
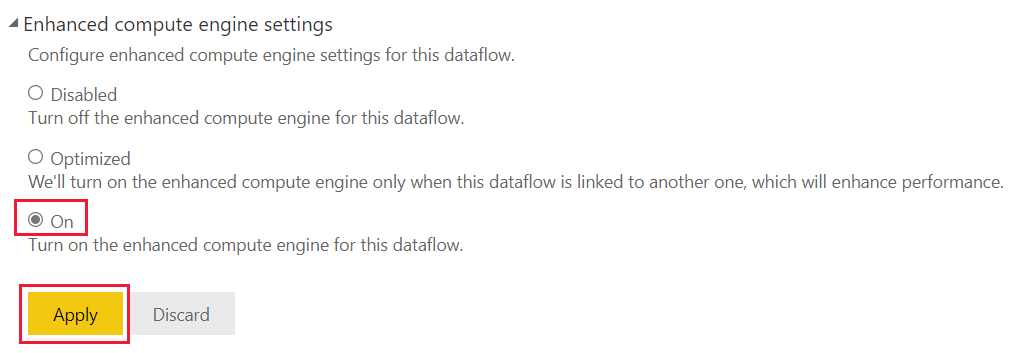
Usare il motore di calcolo avanzato
Dopo aver attivato il motore di calcolo avanzato, tornare ai flussi di dati e si riscontrerà un miglioramento delle prestazioni in qualsiasi tabella calcolata che esegue operazioni complesse, ad esempio operazioni join o group by, per i flussi di dati creati da entità collegate esistenti nella stessa capacità.
Per usare al meglio il motore di calcolo, suddividere la fase ETL in due flussi di dati separati nella stessa area di lavoro, nel modo seguente:
- Flusso di dati 1: questo flusso di dati deve solo inserire tutti i dati richiesti da un'origine dati.
- Flusso di dati 2: eseguire tutte le operazioni ETL in questo secondo flusso di dati, ma assicurarsi di fare riferimento al flusso di dati 1, che si deve trovare nella stessa capacità. Assicurarsi anche di eseguire prima le operazioni che possono ridurre: filter, group by, distinct, join. Eseguire quindi queste operazioni prima di qualsiasi altra operazione, per assicurarsi che il motore di calcolo venga utilizzato.
Domande e risposte comuni
Domanda: dopo aver abilitato il motore di calcolo avanzato, gli aggiornamenti sono più lenti. Why?
Risposta: se si abilita il motore di calcolo avanzato, ci sono due possibili spiegazioni per il rallentamento dei tempi di aggiornamento:
Quando il motore di calcolo avanzato è abilitato, richiede una certa quantità di memoria per funzionare correttamente. Di conseguenza, la memoria disponibile per l'esecuzione di un aggiornamento è ridotta e quindi aumenta la probabilità che gli aggiornamenti vengano accodati. Questo aumento riduce quindi il numero di flussi di dati che possono essere aggiornati contemporaneamente. Per risolvere questo problema, quando si abilitano risorse di calcolo avanzate, distribuire gli aggiornamenti dei flussi di dati nel tempo e valutare se le dimensioni della capacità sono adeguate, per assicurarsi che sia disponibile memoria per gli aggiornamenti simultanei dei flussi di dati.
Un'altra possibile causa del rallentamento degli aggiornamenti è che il motore di calcolo funziona solo sulle entità esistenti. Se il flusso di dati fa riferimento a un'origine dati che non è un flusso di dati, non si riscontrerà alcun miglioramento. Non ci sarà un aumento delle prestazioni, poiché in alcuni scenari di Big Data la lettura iniziale da un'origine dati risulta più lenta, in quanto i dati devono essere passati al motore di calcolo avanzato.
Domanda: non è possibile visualizzare l'interruttore del motore di calcolo avanzato. Why?
Risposta: il motore di calcolo avanzato è in fase di rilascio graduale nelle aree in tutto il mondo, ma non è ancora disponibile in ogni area.
Domanda: quali sono i tipi di dati supportati per il motore di calcolo?
Risposta: il motore di calcolo avanzato e i flussi di dati attualmente supportano i tipi di dati seguenti. Se il flusso di dati non usa uno dei tipi di dati seguenti, si verifica un errore durante l'aggiornamento:
- Data/ora
- Numero decimale
- Testo
- Numero intero
- Data/ora/fuso orario
- True/false
- Data
- Tempo
Usare DirectQuery con flussi di dati in Power BI
È possibile usare DirectQuery per connettersi direttamente ai flussi di dati e quindi connettersi direttamente al proprio flusso di dati senza dover importare i dati.
L'uso di DirectQuery con i flussi di dati consente i miglioramenti seguenti ai processi di Power BI e dei flussi di dati:
Evitare pianificazioni di aggiornamenti separate: DirectQuery si connette direttamente a un flusso di dati, eliminando la necessità di creare un modello semantico importato. Di conseguenza, usando DirectQuery con i flussi di dati, non sono più necessarie pianificazioni di aggiornamenti separate per il flusso di dati e il set di dati per garantire la sincronizzazione dei dati.
Filtro dei dati: DirectQuery è utile per lavorare su una visualizzazione filtrata dei dati all'interno di un flusso di dati. È possibile usare DirectQuery con il motore di calcolo per filtrare i dati del flusso di dati e usare il subset filtrato necessario. Il filtro dei dati consente di usare un subset più piccolo e gestibile dei dati nel flusso di dati.
Usare DirectQuery per i flussi di dati
L'uso di DirectQuery con flussi di dati è disponibile in Power BI Desktop.
Esistono alcuni prerequisiti per l'uso di DirectQuery con i flussi di dati:
- Il flusso di dati deve trovarsi all'interno di un'area di lavoro abilitata per Power BI Premium.
- Il motore di calcolo deve essere attivato.
Per altre informazioni su DirectQuery con flussi di dati, vedere Uso di DirectQuery con flussi di dati.
Abilitare DirectQuery per i flussi di dati
Per assicurarsi che il flusso di dati sia disponibile per l'accesso con DirectQuery, il motore di calcolo avanzato deve essere ottimizzato. Per abilitare DirectQuery per i flussi di dati, impostare la nuova opzione Impostazioni del motore di calcolo avanzato su Attivato.
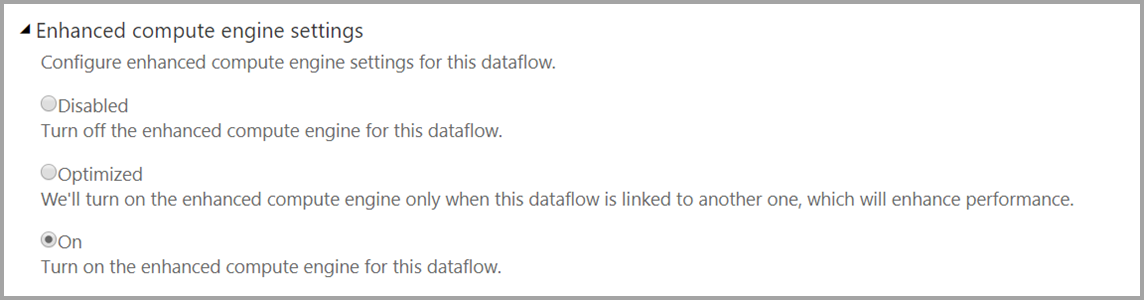
Dopo aver applicato questa impostazione, aggiornare il flusso di dati per rendere effettiva l'ottimizzazione.
Considerazioni e limitazioni per DirectQuery
A DirectQuery e ai flussi di dati si applicano alcune limitazioni note:
Attualmente non sono supportati modelli compositi/misti con origini dati importate e DirectQuery.
I flussi di dati di grandi dimensioni potrebbero riscontrare problemi di timeout quando si attivano le visualizzazioni. I flussi di dati di grandi dimensioni che riscontrano problemi di timeout devono usare la modalità importazione.
Nelle impostazioni dell'origine dati il connettore del flusso di dati visualizzerà credenziali non valide se si usa DirectQuery. Questo avviso non influisce sul comportamento e il modello semantico funzionerà correttamente.
Quando un flusso di dati ha 340 colonne o più, l'uso del connettore di flussi di dati in Power BI Desktop con l'impostazione del motore di calcolo avanzata abilitata comporta la disabilitazione dell'opzione DirectQuery per il flusso di dati. Per usare DirectQuery in tali configurazioni, usare meno di 340 colonne.
Entità calcolate
È possibile eseguire calcoli in archivio quando si usano i flussi di dati con una sottoscrizione di Power BI Premium. Questa funzionalità consente di eseguire i calcoli sui flussi di dati esistenti e ottenere risultati che consentono di concentrarsi sulla creazione di report e sull'analisi.
Per eseguire i calcoli in archivio, è prima di tutto necessario creare il flusso di dati e inserire i dati nell'archivio del flusso di dati di Power BI. Dopo aver creato un flusso di dati contenente dati, è possibile creare entità calcolate, ovvero le entità che eseguono calcoli in archivio.
Considerazioni e limitazioni delle entità calcolate
Quando si usano flussi di dati creati in un account di Azure Data Lake Storage Gen2 dell'organizzazione, le entità collegate e calcolate funzionano correttamente solo quando risiedono nello stesso account di archiviazione.
Le entità calcolate sono supportate solo all'interno di una singola area di lavoro.
Come procedura consigliata, quando si eseguono calcoli sui dati aggiunti dai dati locali e cloud, creare un nuovo flusso di dati per ogni origine (uno per l'ambiente locale e uno per il cloud) e quindi creare un terzo flusso di dati per eseguire il merge/calcolo su queste due origini dati.
Entità collegate
È possibile fare riferimento ai flussi di dati esistenti nella stessa area di lavoro usando entità collegate con una sottoscrizione di Power BI Premium, che consente di eseguire calcoli su queste entità usando entità calcolate o di creare una tabella "singola origine della verità" che è possibile riutilizzare all'interno di più flussi di dati.
Aggiornamento incrementale
I flussi di dati possono essere impostati per l'aggiornamento incrementale, per evitare di dover eseguire il pull di tutti i dati a ogni aggiornamento. A tale scopo, selezionare il flusso di dati, quindi selezionare l'icona Aggiornamento incrementale.

L'impostazione dell'aggiornamento incrementale aggiunge parametri al flusso di dati per specificare l'intervallo di date. Per informazioni dettagliate su come configurare l'aggiornamento incrementale, vedere l'articolo Uso dell'aggiornamento incrementale con i flussi di dati.
Considerazioni su quando non impostare l'aggiornamento incrementale
Non impostare un flusso di dati sull'aggiornamento incrementale nelle situazioni seguenti:
- Le entità collegate non devono usare l'aggiornamento incrementale se fanno riferimento a un flusso di dati.
Contenuti correlati
Gli articoli seguenti contengono altre informazioni sui flussi di dati e su Power BI: