Inviare processi Spark nei cluster Big Data di SQL Server in Azure Data Studio
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Uno degli scenari chiave per i cluster Big Data di SQL Server è la possibilità di inviare processi Spark per SQL Server. La funzionalità di invio di processi Spark consente di inviare file Jar o Py locali con riferimenti ai cluster Big Data di SQL Server 2019. Consente inoltre di eseguire file Jar o Py che si trovano già nel file system HDFS.
Prerequisiti
Strumenti per Big Data di SQL Server 2019:
- Azure Data Studio
- Estensione di SQL Server 2019
- kubectl
Connettere Azure Data Studio al gateway HDFS/Spark del cluster Big Data.
Aprire la finestra di dialogo di invio dei processi Spark
Ci sono diversi modi per aprire la finestra di dialogo di invio dei processi Spark. A tale scopo è possibile usare il dashboard, il menu di scelta rapida in Esplora oggetti e il riquadro comandi.
Per aprire la finestra di dialogo di invio dei processi Spark, fare clic su New Spark Job (Nuovo processo Spark) nel dashboard.
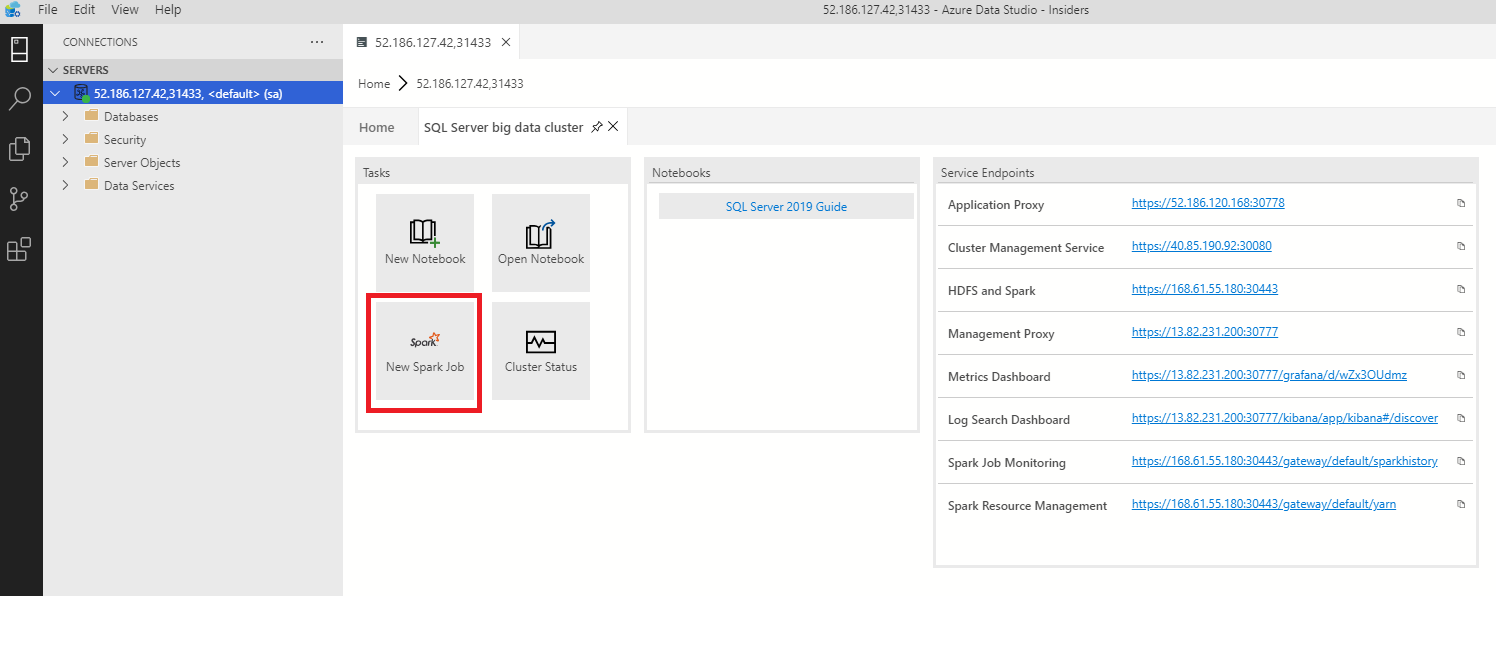
In alternativa, fare clic con il pulsante destro del mouse sul cluster in Esplora oggetti e scegliere Submit Spark Job (Invia processo Spark) dal menu di scelta rapida.
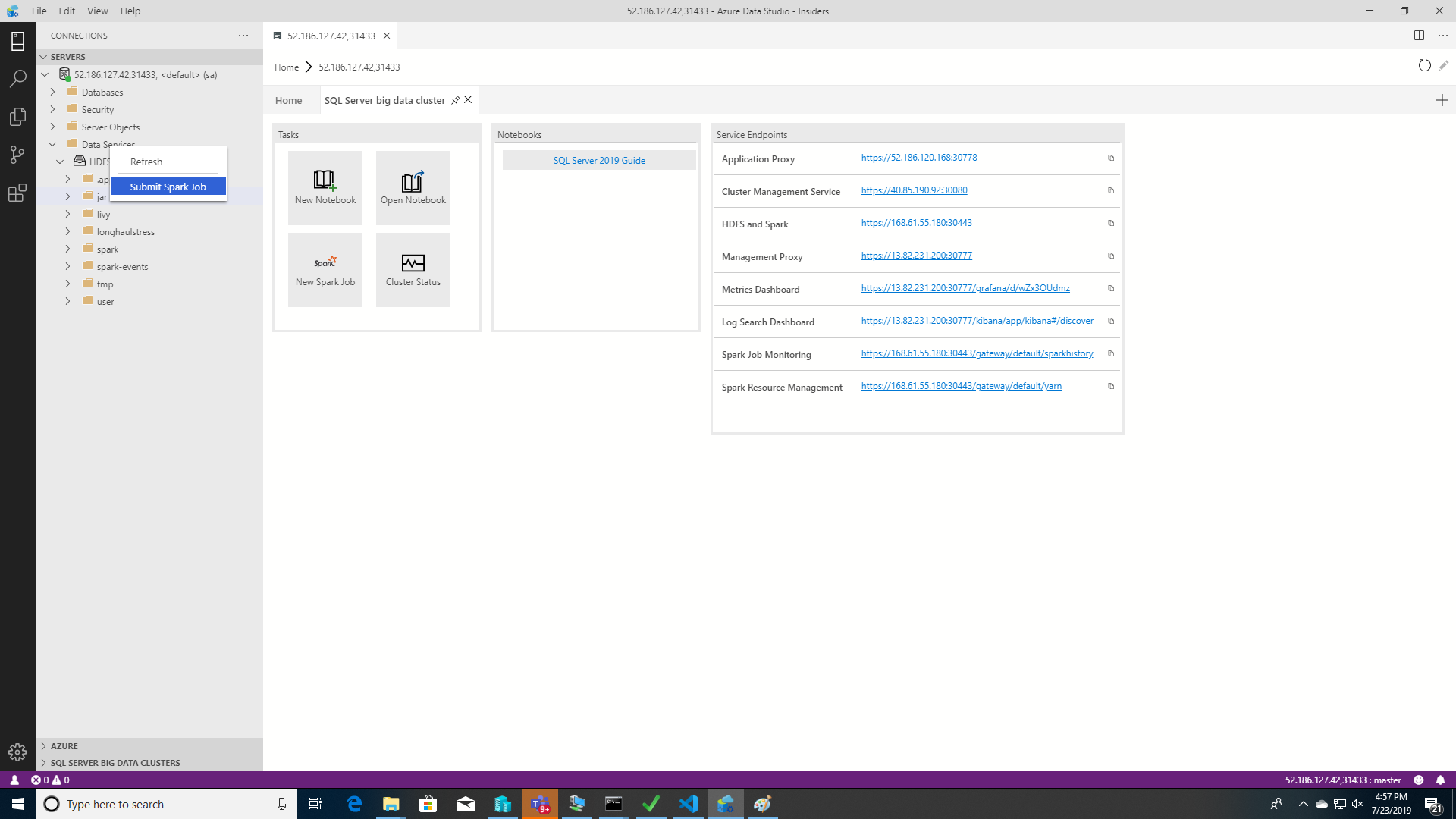
Per aprire la finestra di dialogo di invio dei processi Spark con i campi relativi a Jar/Py prepopolati, fare clic con il pulsante destro del mouse su un file Jar/Py in Esplora oggetti e scegliere Submit Spark Job (Invia processo Spark) dal menu di scelta rapida.
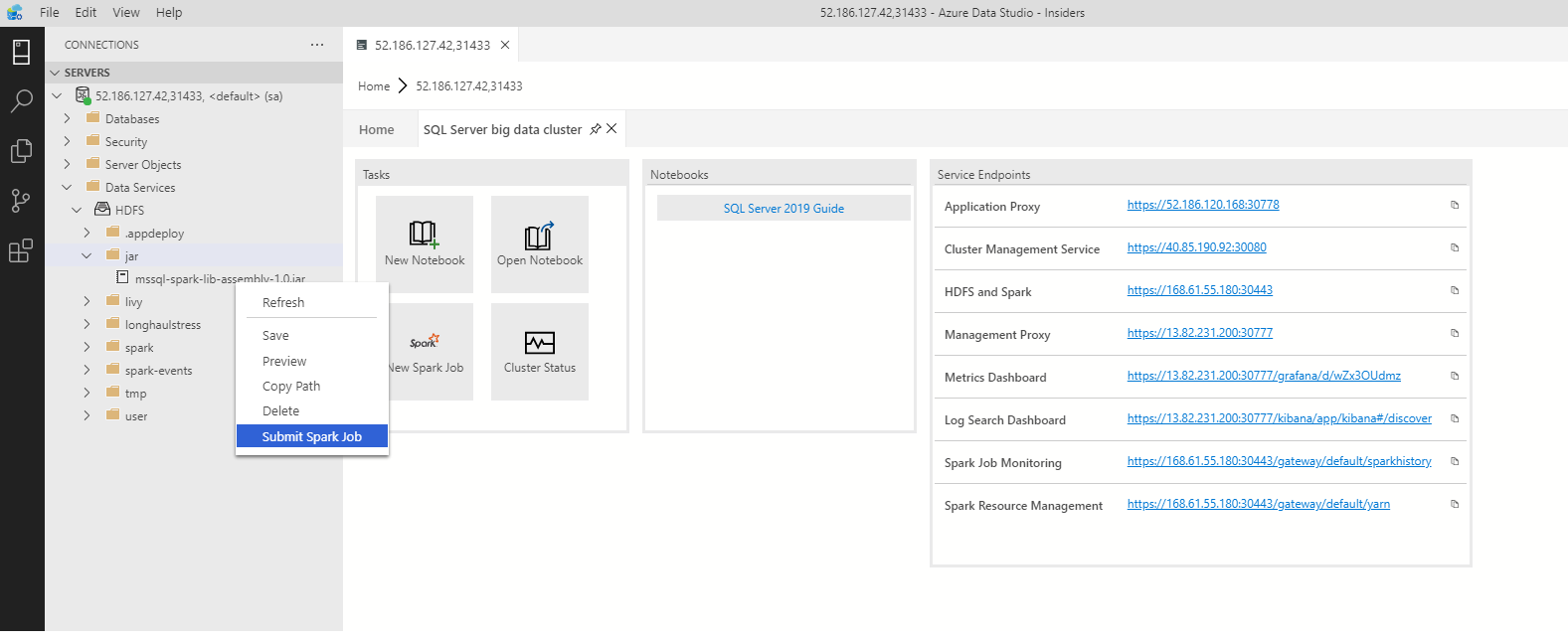
Usare il comando Submit Spark Job (Invia processo Spark) dal riquadro comandi premendo CTRL+MAIUSC+P (in Windows) e CMD+MAIUSC+P (in Mac).

Inviare un processo Spark
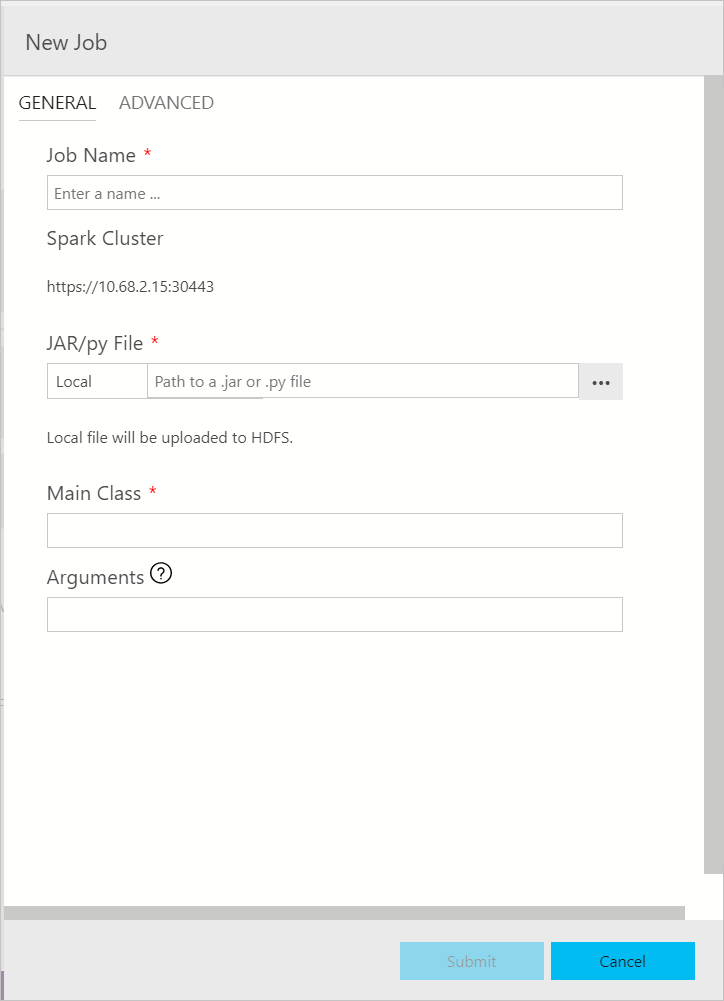
La finestra di dialogo di invio dei processi Spark viene visualizzata come illustrato di seguito. Immettere il nome del processo, il percorso del file JAR/Py, la classe principale e gli altri campi. L'origine del file Jar/Py può essere locale o in HDFS. Se il processo Spark contiene file Py, file Jar di riferimento o file aggiuntivi, fare clic sulla scheda ADVANCED (AVANZATE) e immettere i percorsi di file corrispondenti. Fare clic su Submit (Invia) per inviare il processo Spark.
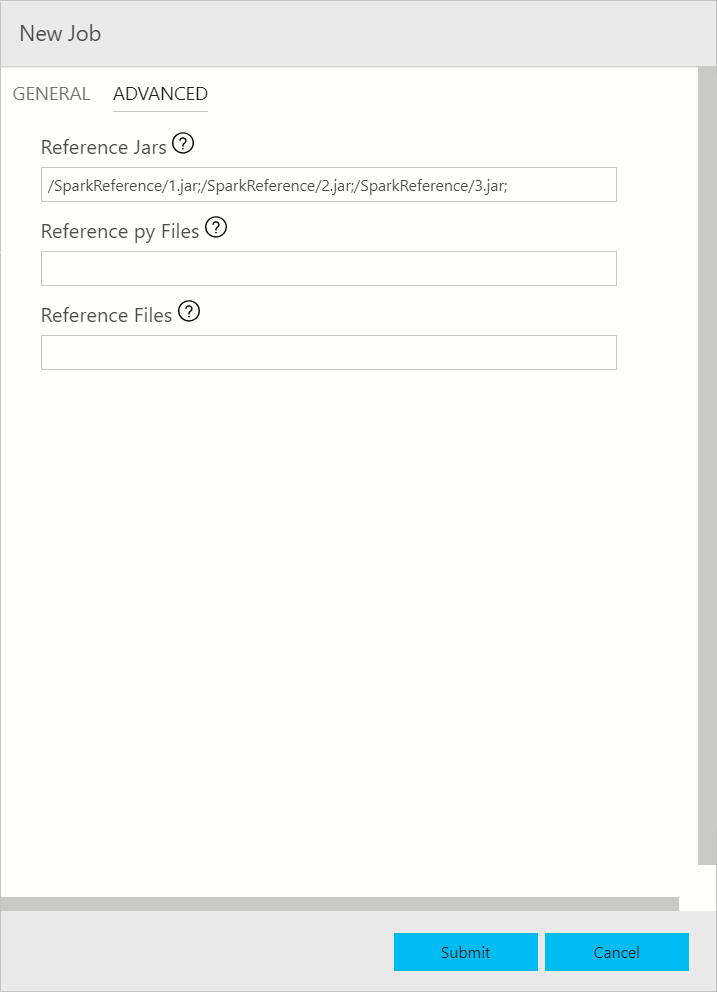
Monitorare l'invio del processo Spark
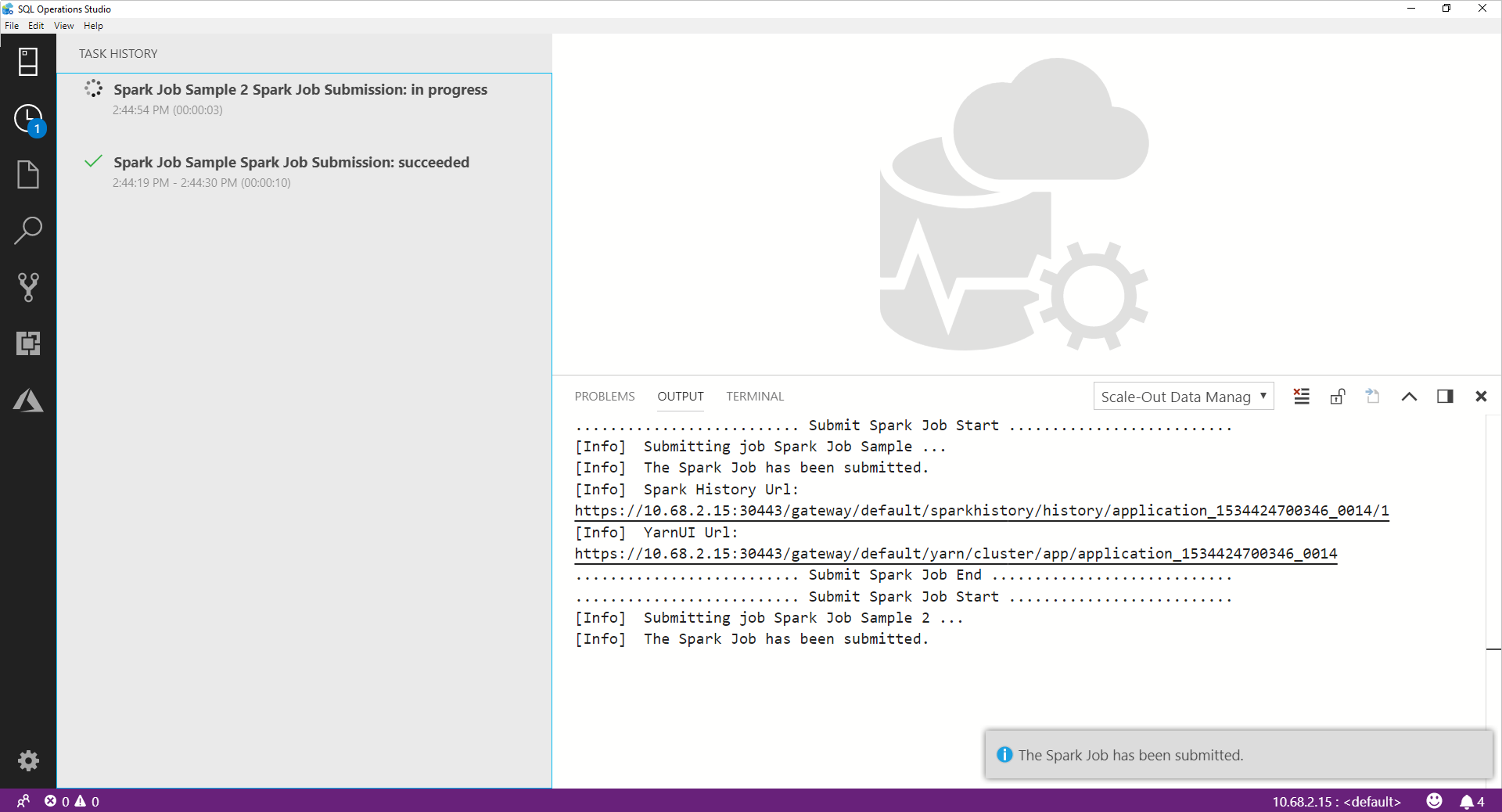
Una volta inviato il processo Spark, le informazioni sullo stato di invio e di esecuzione del processo vengono visualizzate nella cronologia attività a sinistra. I dettagli sullo stato di avanzamento e i log vengono visualizzati anche nella finestra OUTPUT nella parte inferiore.
Quando il processo Spark è in corso, il pannello Task History (Cronologia attività) e la finestra OUTPUT vengono aggiornati in base allo stato di avanzamento.
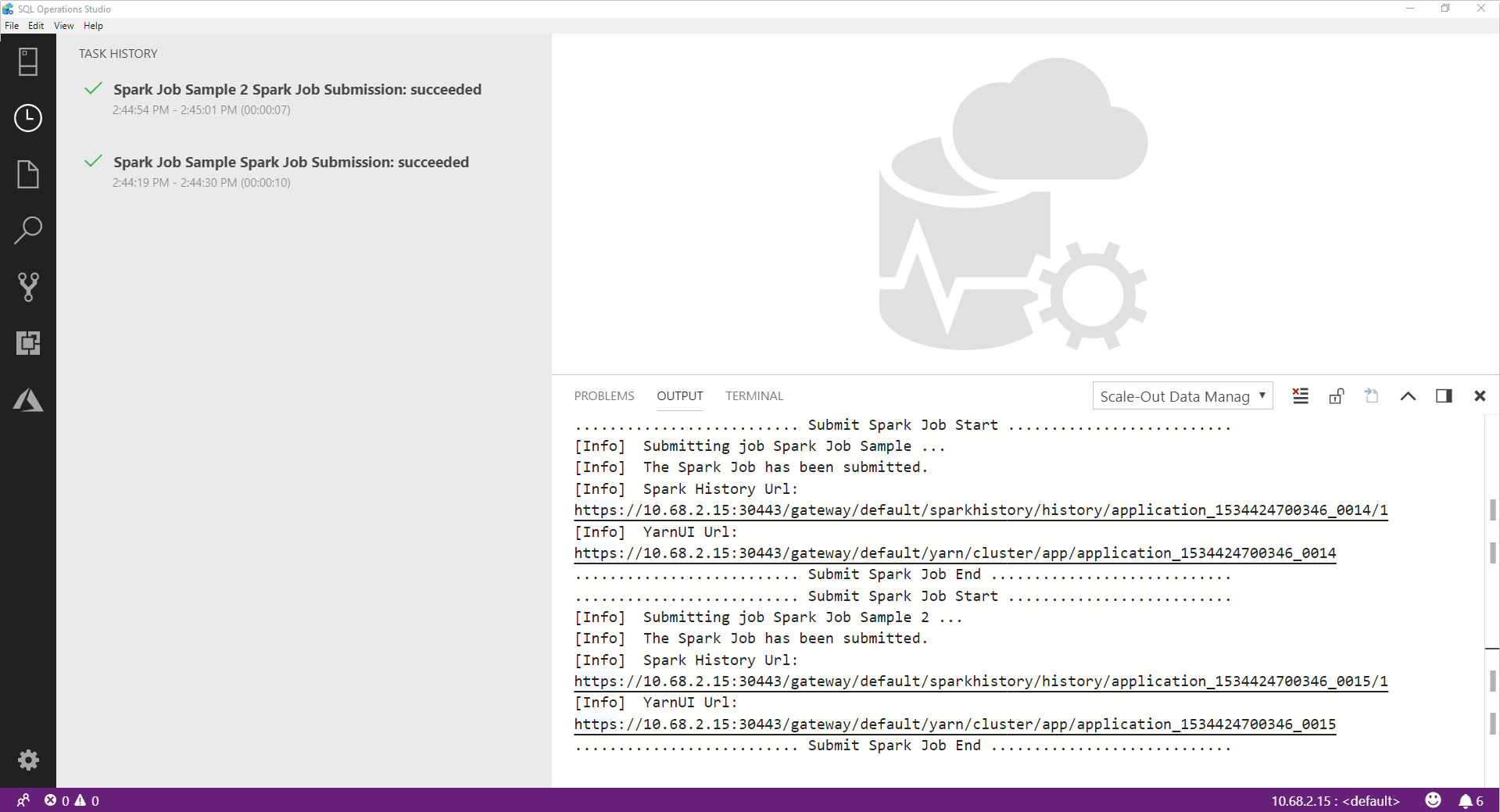
Al termine del processo Spark, i collegamenti dell'interfaccia utente Spark e dell'interfaccia utente Yarn vengono visualizzati nella finestra OUTPUT. Fare clic sui collegamenti per ulteriori informazioni.
Passaggi successivi
Per altre informazioni sui cluster Big Data di SQL Server e sugli scenari correlati, vedere Introduzione ai cluster Big Data di SQL Server.