Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo documento descrive il funzionamento della Deduplicazione dei dati.
Come funziona la deduplicazione dati?
La Deduplicazione dati in Windows Server è stata creata con i due principi seguenti:
L'ottimizzazione non dovrebbe intralciare le operazioni di scrittura su disco Deduplicazione Dati ottimizza i dati utilizzando un modello di post-elaborazione. Tutti i dati vengono scritti sul disco senza essere ottimizzati per poi essere ottimizzati in un secondo tempo con la deduplicazione dati.
L’ottimizzazione non deve modificare la semantica di accesso Utenti e applicazioni che accedono ai dati in un volume ottimizzato non sono completamente consapevoli del fatto che i file a cui accedono sono stati deduplicati.
Dopo essere stata abilitata per un volume, la deduplicazione dati viene eseguita in background per:
- Identificare i modelli ripetuti in tutti i file di quel volume.
- Spostare facilmente tali porzioni, o blocchi, con puntatori speciali denominati reparse points che puntano a una copia univoca di quel blocco.
Ciò si verifica nei quattro passaggi seguenti:
- Analizzare il file system per individuare i file che soddisfano i criteri di ottimizzazione.

- Suddivisione dei file in blocchi di dimensioni variabili.

- Identificazione dei blocchi univoci.
- Collocazione dei blocchi nell'archivio blocchi e, facoltativamente, compressione.
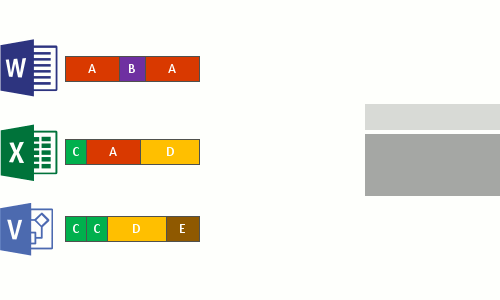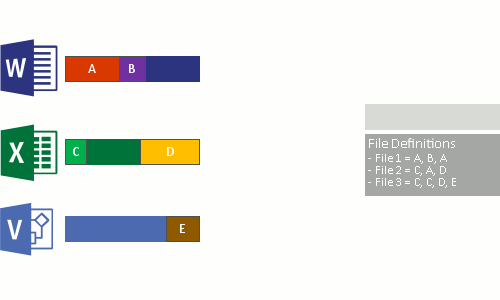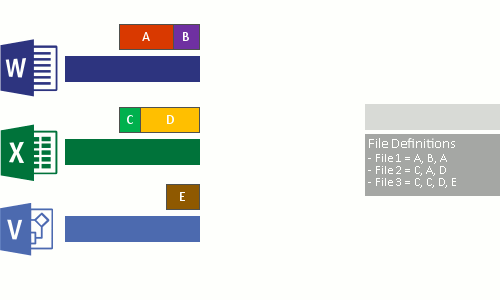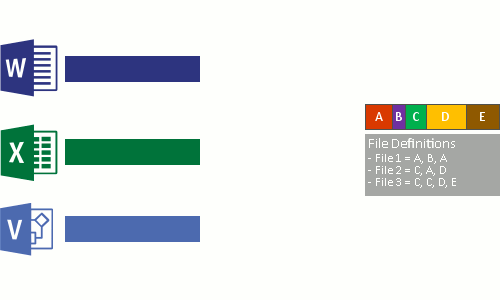
- Sostituire il flusso di file originale, che è ora ottimizzato, con un punto di reparse nel deposito di blocchi.
Quando il file system legge i file ottimizzati, invia i file con un reparse point al filtro del file system di deduplicazione dei dati (Dedup.sys). Il filtro reindirizza l'operazione di lettura ai blocchi appropriati che costituiscono il flusso per il file nell'archivio blocchi. Le modifiche agli intervalli di file deduplicati vengono scritte non ottimizzate sul disco e ottimizzate dal processo di ottimizzazione alla successiva esecuzione.
Tipi di utilizzo
I seguenti tipi di uso indicano la configurazione più ragionevole di deduplicazione dati per carichi di lavoro comuni:
| Tipo di utilizzo | Carichi di lavoro ideali | Cosa c'è di diverso |
|---|---|---|
| Predefinito | File server per uso generale:
|
|
| Hyper-V | Server VDI (Infrastruttura Desktop Virtuale) |
|
| Backup | Applicazioni di backup virtualizzate, ad esempio Microsoft Data Protection Manager (DPM) |
|
Jobs
La deduplicazione dei dati usa una strategia di post-elaborazione per ottimizzare e preservare l'efficienza dello spazio del volume.
| Nome attività | Descrizioni delle mansioni | Pianificazione predefinita |
|---|---|---|
| Ottimizzazione | Il processo di ottimizzazione viene deduplicato suddividendo i dati in un volume in base alle impostazioni dei criteri del volume, comprimendo (facoltativamente) tali blocchi e archiviando blocchi in modo univoco nell'archivio blocchi. Il processo di ottimizzazione che usa la deduplicazione dati è descritto in dettaglio in Come funziona la deduplicazione dati?. | Una volta ogni ora |
| Raccolta dei Rifiuti | Il processo di Garbage Collection recupera lo spazio su disco rimuovendo blocchi non necessari a cui non viene più fatto riferimento dai file che sono stati modificati o eliminati di recente. | Ogni sabato alle 2:35 |
| Verifica dell'integrità | L'attività di verifica dell'integrità identifica i danneggiamenti nell'archivio dei chunk a causa di guasti del disco o di settori danneggiati. Quando possibile, la deduplicazione dei dati può utilizzare automaticamente le funzionalità del volume (come il mirroring o la parità su un volume di Spazi di archiviazione) per ricostruire i dati danneggiati. Tramite la deduplicazione dati vengono anche mantenute copie di backup dei blocchi usati più di frequente quando vi viene fatto riferimento più di 100 volte in un'area denominata hotspot. | Ogni sabato alle 3:35 |
| Annullamento dell'ottimizzazione | Il lavoro di Deottimizzazione, che è un lavoro speciale da eseguire solo manualmente, annulla l'ottimizzazione eseguita dalla deduplicazione e disabilita la deduplicazione dei dati per quel volume. | Solo su richiesta |
Terminologia della deduplicazione dei dati
| Term | Definition |
|---|---|
| Blocco | Un chunk è una sezione di un file che è stata selezionata dall'algoritmo di suddivisione in chunk di Deduplicazione Dati perché potrebbe verificarsi in altri file simili. |
| Archivio blocchi | L'archivio dei blocchi è una serie organizzata di file contenitore nella cartella Informazioni del volume di sistema che la Deduplicazione Dati utilizza per memorizzare in modo distinto i blocchi. |
| Dedup | Un'abbreviazione di Deduplicazione dati usata in PowerShell, nelle API e nei componenti di Windows Server e di uso comune nella community di Windows Server. |
| Metadati del file | Ogni file contiene metadati che descrivono le proprietà interessanti sul file che non sono correlate al contenuto principale del file. Ad esempio, data di creazione, data dell'ultima lettura, autore e così via. |
| Flusso di file | Il flusso di file è il contenuto principale del file. Questa è la parte del file che la deduplicazione dati ottimizza. |
| Sistema di file | Il file system è la struttura dei dati su disco e software che consente al sistema operativo di archiviare i file sul supporto di archiviazione. La deduplicazione dati è supportata nei volumi NTFS formattati. |
| Filtro del file system | Un filtro del file system è un plug-in che modifica il comportamento predefinito del file system. Per mantenere la semantica di accesso, la deduplicazione dei dati usa un filtro del file system (Dedup.sys) per reindirizzare le letture verso il contenuto ottimizzato in modo completamente trasparente all'utente o all'applicazione che effettua la richiesta di lettura. |
| Ottimizzazione | Un file viene considerato ottimizzato (o deduplicato) da Data Deduplication se è stato suddiviso in chunk e i suoi chunk unici sono stati archiviati nello store dei chunk. |
| Criteri di ottimizzazione | I criteri di ottimizzazione specificano quali file devono essere considerati per la deduplicazione dati. Ad esempio, i file potrebbero essere considerati fuori dai criteri se sono completamente nuovi, aperti, in un determinato percorso del volume o di un determinato tipo di file. |
| Punto di ri-analisi | Un reparse point è un tag speciale che notifica al file system di indirizzare le operazioni di I/O verso un filtro specificato del file system. Quando il flusso di file del file è stato ottimizzato, Deduplicazione dei dati sostituisce il flusso di file con un reparse point, che consente a Deduplicazione dei dati di mantenere la semantica di accesso per tale file. |
| Volume | Un volume è un costrutto di Windows per un'unità di archiviazione logica che può estendere diversi dispositivi di archiviazione fisica in un uno o più server. La deduplicazione è abilitata su base volume per volume. |
| Carico di lavoro | Un carico di lavoro è un'applicazione che viene eseguita su Windows Server. Esempi dei carichi di lavoro includono file server a scopi generici, Hyper-V e SQL Server. |
Warning
A meno che non sia richiesto dal personale di supporto Microsoft autorizzato, non tentare di modificare manualmente l'archivio dei blocchi. Questa azione può comportare il danneggiamento o la perdita dei dati.
Domande frequenti
In che modo la Deduplicazione dei dati è diversa dagli altri prodotti di ottimizzazione? Vi sono alcune differenze importanti tra la deduplicazione dati e altri prodotti comuni di ottimizzazione dell'archiviazione:
In che modo la Deduplicazione dei dati differisce da un Archivio a Istanza Unica? Single Instance Store, o SIS, è una tecnologia precedente alla Deduplicazione dei dati introdotta per la prima volta in Windows Storage Server 2008 R2. Single Instance Store ottimizzava un volume identificando i file completamente identici e sostituendoli con collegamenti logici a una singola copia di un file archiviato nell'archivio comune SIS. A differenza di Single Instance Store, Deduplicazione dati può risparmiare spazio da file che non sono identici ma condividono molti modelli comuni e da file che a loro volta contengono molti modelli ripetuti. Single Instance Store non è più supportata in Windows Server 2012 R2 e rimossa in Windows Server 2016 a favore di Deduplicazione Dati.
In che modo la deduplicazione dei dati differisce dalla compressione NTFS? La compressione NTFS è una funzionalità di NTFS che può essere abilitata facoltativamente a livello di volume. Con la compressione NTFS ogni singolo file è ottimizzato singolarmente tramite la compressione in fase di scrittura. A differenza della compressione NTFS, la deduplicazione dati può ottenere risparmi di spazio su tutti i file di un volume. Questo è preferibile rispetto alla compressione NTFS perché i file possono avere sia la duplicazione interna (che viene risolta dalla compressione NTFS) sia analogie con altri file nel volume (che non sono indirizzate dalla compressione NTFS). La deduplicazione dei dati include anche un modello di post-elaborazione, il che significa che i nuovi file o le modifiche ai file esistenti verranno scritti sul disco in maniera non ottimizzata e saranno ottimizzati solo in un momento successivo dalla deduplicazione dei dati.
In che modo la deduplicazione dei dati è diversa dai formati di file come zip, rar, 7z, cab, ecc.? I formati file di archivio come i file con estensione zip, rar, 7z, cab e così via eseguono la compressione su un set di file specificato. Come la deduplicazione dei dati, i modelli duplicati all'interno dei file e modelli duplicati tra file sono ottimizzati. È tuttavia necessario scegliere i file che si vuole includere nell'archivio. Anche la semantica di accesso è diversa. Per accedere a un file specifico all'interno dell'archivio, è necessario aprire l'archivio, selezionare un file specifico e decomprimere il file per l'uso. Deduplicazione dati funziona in modo trasparente per gli utenti e gli amministratori e non richiede un avvio manuale. Deduplicazione dati consente anche di mantenere la semantica di accesso: i file ottimizzati appaiono invariati dopo l'ottimizzazione.
È possibile modificare le impostazioni di Deduplicazione dati per il tipo di uso selezionato? Yes. Sebbene Deduplicazione dati fornisca impostazioni predefinite ragionevoli per i carichi di lavoro consigliati, è comunque possibile modificare le impostazioni di Deduplicazione dati per sfruttare al meglio l'archiviazione. Inoltre, altri carichi di lavoro richiederanno alcuni aggiustamenti per garantire che la Deduplicazione dati non interferisca con il carico di lavoro.
È possibile eseguire manualmente un processo di deduplicazione dati? Sì, tutti i processi di Deduplicazione dati possono essere eseguiti manualmente. Ciò può essere opportuno se i processi pianificati non sono stati eseguiti a causa di risorse di sistema insufficienti o di un errore. Inoltre, il processo di annullamento dell'ottimizzazione può essere eseguito solo manualmente.
È possibile monitorare la cronologia dei risultati dei processi di deduplicazione dati? Sì, ogni processo di deduplicazione dati costituisce una voce nel registro eventi di Windows.
È possibile modificare le pianificazioni predefinite per i processi di deduplicazione dati sul sistema? Sì, tutte le pianificazioni sono configurabili. Modificare le pianificazioni predefinite della deduplicazione dei dati è particolarmente utile per garantire che i processi di deduplicazione dispongano di tempo a sufficienza per essere completati e non competano per le risorse con il carico di lavoro.