Azure Data Factory および Synapse Analytics を使用して Teradata Vantage からデータをコピーする
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory および Synapse Analytics パイプラインの Copy アクティビティを使用して、Teradata Vantage からデータをコピーする方法について説明します。 これは、コピー アクティビティの概要に関する記事に基づいています。
サポートされる機能
この Teradata コネクタでは、次の機能がサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/-) | 1.1 |
| Lookup アクティビティ | 1.1 |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
コピー アクティビティによってソースまたはシンクとしてサポートされているデータ ストアの一覧については、サポートされているデータ ストアに関する記事の表をご覧ください。
具体的には、この Teradata コネクタは以下をサポートします。
- Teradata バージョン 14.10、15.0、15.10、16.0、16.10、16.20。
- 基本認証、Windows 認証、または LDAP 認証を使用したデータのコピー。
- Teradata ソースからの並列コピー。 詳細については、「Teradata からの並列コピー」セクションを参照してください。
前提条件
データ ストアがオンプレ ミスネットワーク、Azure 仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、それに接続するようセルフホステッド統合ランタイムを構成する必要があります。
データ ストアがマネージド クラウド データ サービスである場合は、Azure Integration Runtime を使用できます。 ファイアウォール規則で承認されている IP にアクセスが制限されている場合は、Azure Integration Runtime の IP を許可リストに追加できます。
また、Azure Data Factory のマネージド仮想ネットワーク統合ランタイム機能を使用すれば、セルフホステッド統合ランタイムをインストールして構成しなくても、オンプレミス ネットワークにアクセスすることができます。
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
セルフホステッド統合ランタイムを使用している場合は、バージョン 3.18 以降、組み込みの Teradata ドライバーが用意されていることに注意してください。 ドライバーを手動でインストールする必要はありません。 このドライバーでは、セルフホステッド統合ランタイム マシンに "Visual C++ 再頒布可能パッケージ 2012 Update 4" が必要です。 まだインストールしていない場合は、こちらからダウンロードしてください。
作業の開始
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して Teradata のリンク サービスを作成する
次の手順で、Azure portal の UI を使用して Teradata のリンク サービスを作成します。
Azure Data Factory または Synapse ワークスペースの Manage タブに移動して、[Linked Services](リンク サービス)、[New](新規) を順にクリックします。
Teradata を検索して Teradata コネクタを選択します。
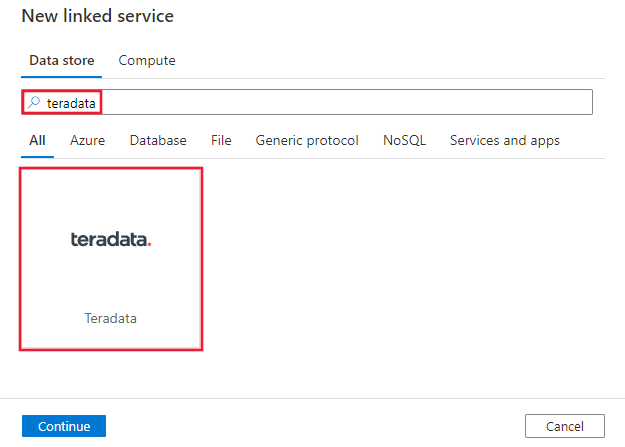
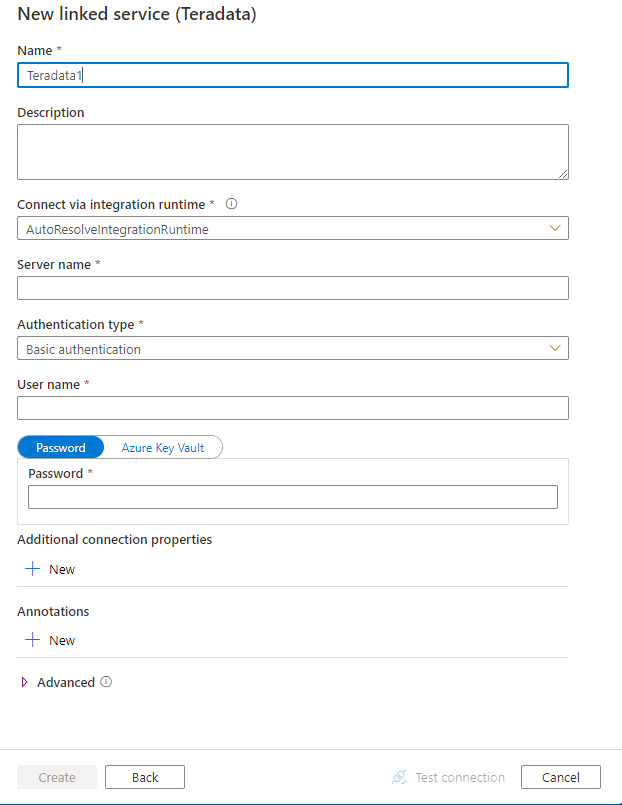
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
次のセクションでは、Teradata コネクタに固有の Data Factory エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Teradata のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | Description | 必須 |
|---|---|---|
| type | type プロパティは Teradata に設定する必要があります。 | はい |
| connectionString | Teradata インスタンスに接続するために必要な情報を指定します。 以下のサンプルを参照してください。 パスワードを Azure Key Vault に格納して、接続文字列から password 構成をプルすることもできます。 詳細については、「Azure Key Vault への資格情報の格納」を参照してください。 |
はい |
| username | Teradata に接続するユーザー名を指定します。 Windows 認証の使用時に適用されます。 | いいえ |
| password | ユーザー名に指定したユーザー アカウントのパスワードを指定します。 Azure Key Vault に格納されているシークレットを参照することも選択できます。 Windows 認証の使用時、または基本認証で Key Vault のパスワードを参照するときに適用されます。 |
いいえ |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 詳細については、「前提条件」セクションを参照してください。 指定されていない場合は、既定の Azure 統合ランタイムが使用されます。 | いいえ |
接続文字列には他にも、ケースに応じてさまざまな接続プロパティを設定できます。それらのプロパティを次に示します。
| プロパティ | Description | 既定値 |
|---|---|---|
| TdmstPortNumber | Teradata データベースへのアクセスに使用するポート番号。 サポート チームから指示されていない限り、この値を変更しないでください。 |
1025 |
| UseDataEncryption | Teradata データベースとのすべての通信を暗号化するかどうかを指定します。 使用可能な値は 0 または 1 です。 - 0 (無効、既定値) :認証情報のみを暗号化します。 - 1 (有効) :ドライバーとデータベースの間で渡されるすべてのデータを暗号化します。 |
0 |
| CharacterSet | セッションに使用する文字セット。 例: CharacterSet=UTF16。この値には、ユーザー定義の文字セットのほか、次のいずれかの定義済みの文字セットを指定できます。 - ASCII - UTF8 - UTF16 - LATIN1252_0A - LATIN9_0A - LATIN1_0A - Shift-JIS (Windows、DOS 互換、KANJISJIS_0S) - EUC (Unix 互換、KANJIEC_0U) - IBM Mainframe (KANJIEBCDIC5035_0I) - KANJI932_1S0 - BIG5 (TCHBIG5_1R0) - GB (SCHGB2312_1T0) - SCHINESE936_6R0 - TCHINESE950_8R0 - NetworkKorean (HANGULKSC5601_2R4) - HANGUL949_7R0 - ARABIC1256_6A0 - CYRILLIC1251_2A0 - HEBREW1255_5A0 - LATIN1250_1A0 - LATIN1254_7A0 - LATIN1258_8A0 - THAI874_4A0 |
ASCII |
| MaxRespSize | SQL 要求の応答バッファーの最大サイズ。単位はキロバイト (KB) です。 例: MaxRespSize=10485760。Teradata Database バージョン 16.00 以降では、7361536 が最大値となります。 それより前のバージョンを使用する接続の場合、最大値は 1048576 です。 |
65536 |
| MechanismName | LDAP プロトコルを使用して接続を認証するには、MechanismName=LDAP を指定します。 |
該当なし |
基本認証を使用した例
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows 認証を使用した例
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
LDAP 認証を使用した例
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
注意
次のペイロードは引き続きサポートされます。 しかし、今後は新しいものを使用する必要があります。
以前のペイロード:
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
このセクションでは、Teradata データセットでサポートされるプロパティの一覧を示します。 データセットの定義に使用できるセクションとプロパティの一覧については、データセットに関する記事をご覧ください。
Teradata からデータをコピーするために、次のプロパティがサポートされています。
| プロパティ | Description | 必須 |
|---|---|---|
| type | データセットの type プロパティは TeradataTable に設定する必要があります。 |
はい |
| database | Teradata インスタンスの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| table | Teradata インスタンスのテーブルの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
例:
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
注意
type が RelationalTable のデータセットは引き続きサポートされます。 ただし、新しいデータセットを使用することをお勧めします。
以前のペイロード:
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
コピー アクティビティのプロパティ
このセクションでは、Teradata ソースでサポートされるプロパティの一覧を示します。 アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関するページを参照してください。
ソースとしての Teradata
ヒント
データのパーティション分割を使用して Teradata からデータを効率的に読み込む方法の詳細については、「Teradata からの並列コピー」セクションを参照してください。
Teradata からデータをコピーするために、コピー アクティビティの source セクションでは次のプロパティがサポートされています。
| プロパティ | Description | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは TeradataSource に設定する必要があります。 |
はい |
| query | カスタム SQL クエリを使用してデータを読み取ります。 たとえば "SELECT * FROM MyTable" です。パーティション分割された読み込みを有効にするときは、クエリ内で対応する組み込みのパーティション パラメーターをすべてフックする必要があります。 例については、「Teradata からの並列コピー」セクションを参照してください。 |
いいえ (データセットのテーブルが指定されている場合) |
| partitionOptions | Teradata からのデータの読み込みに使用されるデータ パーティション分割オプションを指定します。 指定できる値は、None (既定値)、Hash、DynamicRange です。 パーティション オプションが有効になっている場合 (つまり、 None ではない場合)、Teradata から同時にデータを読み込む並列処理の次数は、コピー アクティビティの parallelCopies の設定によって制御されます。 |
いいえ |
| partitionSettings | データ パーティション分割の設定のグループを指定します。 パーティション オプションが None でない場合に適用されます。 |
いいえ |
| partitionColumnName | 並列コピーの範囲パーティションまたはハッシュ パーティションで使用されるソース列の名前を指定します。 指定されていない場合は、テーブルのプライマリ インデックスが自動検出され、パーティション列として使用されます。 パーティション オプションが Hash または DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfHashPartitionCondition または ?AdfRangePartitionColumnName をフックします。 例については、「Teradata からの並列コピー」セクションを参照してください。 |
いいえ |
| partitionUpperBound | データをコピーするパーティション列の最大値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionUpbound をフックします。 例については、「Teradata からの並列コピー」セクションを参照してください。 |
いいえ |
| partitionLowerBound | データをコピーするパーティション列の最小値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionLowbound をフックします。 例については、「Teradata からの並列コピー」セクションを参照してください。 |
いいえ |
注意
type が RelationalSource のコピー ソースは引き続きサポートされますが、これは、新しく組み込まれた Teradata からの並列読み込み (パーティション オプション) をサポートしません。 ただし、新しいデータセットを使用することをお勧めします。
例: パーティションなしで基本的なクエリを使用してデータをコピーする
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Teradata からの並列コピー
Teradata コネクタは、Teradata からデータを並列でコピーするために、組み込みのデータ パーティション分割を提供します。 データ パーティション分割オプションは、コピー アクティビティの [ソース] テーブルにあります。

パーティション分割されたコピーを有効にすると、サービスによって Teradata ソースに対する並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列度は、コピー アクティビティの parallelCopies 設定によって制御されます。 たとえば、parallelCopies を 4 に設定した場合、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。各クエリでは、Teradata からデータの一部を取得します。
特に、Teradata から大量のデータを読み込む場合は、データのパーティション分割を使用した並列コピーを有効にすることをお勧めします。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 大きなテーブル全体を読み込む。 | パーティション オプション: Hash。 実行中に、サービスによって自動的にプライマリ インデックス列が検出され、それにハッシュが適用されて、データがパーティションごとにコピーされます。 |
| カスタム クエリを使用して大量のデータを読み込む。 | パーティション オプション: Hash。 クエリ: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>パーティション列: ハッシュ パーティションの適用に使用される列を指定します。 指定されていない場合は、Teradata データセットで指定したテーブルの PK 列がサービスによって自動検出されます。 実行中に、サービスによって ?AdfHashPartitionCondition がハッシュ パーティション ロジックに置き換えられ、Teradata に送信されます。 |
| カスタム クエリを使用して大量のデータを読み込む (範囲パーティション分割のために値が均等に分散されている整数列がある場合)。 | パーティション オプション: 動的範囲パーティション。 クエリ: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>パーティション列: データのパーティション分割に使用される列を指定します。 整数データ型の列に対してパーティション分割を実行できます。 パーティションの上限とパーティションの下限: パーティション列に対してフィルター処理を実行して、下限から上限までの範囲内のデータのみを取得する場合に指定します。 実行中に、サービスによって ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound、?AdfRangePartitionLowbound が各パーティションの実際の列名および値の範囲に置き換えられ、Teradata に送信されます。 たとえば、パーティション列 "ID" で下限が 1、上限が 80 に設定され、並列コピーが 4 に設定されている場合、サービスは 4 つのパーティションでデータを取得します。 これらの ID の範囲はそれぞれ [1, 20]、[21, 40]、[41, 60]、[61, 80] です。 |
例: ハッシュ パーティションを使用してクエリを実行する
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
例: 動的範囲パーティションを使用してクエリを実行する
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Teradata のデータ型マッピング
Teradata からデータをコピーするとき、Teradata のデータ型からサービスで使用される内部データ型に次のマッピングが適用されます。 コピー アクティビティでソースのスキーマとデータ型がシンクにマッピングされるしくみについては、スキーマとデータ型のマッピングに関する記事を参照してください。
| Teradata データ型 | 中間サービス データ型 |
|---|---|
| BigInt | Int64 |
| BLOB | Byte[] |
| Byte | Byte[] |
| ByteInt | Int16 |
| Char | String |
| Clob | String |
| Date | DateTime |
| Decimal | Decimal |
| Double | Double |
| Graphic | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Integer | Int32 |
| Interval Day | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Day To Hour | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Day To Minute | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Day To Second | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Hour | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Hour To Minute | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Hour To Second | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Minute | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Minute To Second | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Month | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Second | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Year | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Interval Year To Month | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Number | Double |
| Period (Date) | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Period (Time) | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Period (Time With Time Zone) | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Period (Timestamp) | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| Period (Timestamp With Time Zone) | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| SmallInt | Int16 |
| Time | TimeSpan |
| Time With Time Zone | TimeSpan |
| Timestamp | DateTime |
| Timestamp With Time Zone | DateTime |
| VarByte | Byte[] |
| VarChar | String |
| VarGraphic | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
| xml | サポートされていません。 ソース クエリで明示的なキャストを適用します。 |
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
関連するコンテンツ
コピー アクティビティによってソース、シンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示