重要
Azure Data Box では、BLOB レベルでのアクセス層の割り当てがサポートされるようになりました。 このチュートリアルで扱うステップは、更新されたデータ コピー プロセスを反映したもので、ブロック BLOB に特化したものとなっています。
ブロック BLOB データの適切なアクセス層を決定する方法については、「ブロック BLOB の適切なアクセス層を決定する」セクションを参照してください。 適切なアクセス層へのデータのコピーについては、「データを Data Box にコピーする」セクションで説明されている手順のようにしてください。
このセクションに含まれる情報は、2024 年 4 月 1 日以降に発注された注文に適用されます。
このチュートリアルでは、ローカル Web UI を使用してホスト コンピューターに接続し、そこからデータをコピーする方法について説明します。
このチュートリアルでは、以下の内容を学習します。
- 前提条件
- Data Box に接続する
- Data Box にデータをコピーする
前提条件
開始する前に次の点を確認します。
- Azure Data Box の設定に関するチュートリアルを完了していること。
- Data Box を受け取っていて、ポータルでの注文の状態が [配送完了] であること。
- Data Box にコピーするデータが格納されているホスト コンピューターがあること。 このホスト コンピューターは次の条件を満たしている必要があります。
- サポート対象のオペレーティング システムが実行されていること。
- 高速ネットワークに接続していること。 10 GbE 接続を少なくとも 1 つ利用することを強くお勧めします。 10 GbE 接続を利用できない場合は、1 GbE データ リンクを使用できますが、コピーの速度が影響を受けます。
Data Box に接続する
選択したストレージ アカウントに基づいて、Data Box では最大で次のものが作成されます。
- GPv1 および GPv2 に対して関連付けられているストレージ アカウントごとに 3 つの共有。
- Premium ストレージに対して 1 つの共有。
- BLOB ストレージ アカウント用の 1 つの共有 (4 つのアクセス層ごとに 1 つのフォルダーが含まれます)。
次の表は、接続先となる Data Box 共有の名前と、ターゲット ストレージ アカウントにアップロードするデータの種類を示しています。 また、ソース データのコピー先である共有とディレクトリの階層も示しています。
| ストレージの種類 | 共有名 | 第 1 レベル エンティティ | 第 2 レベル エンティティ | 第 3 レベル エンティティ |
|---|---|---|---|---|
| ブロック BLOB | <storageAccountName>_BlockBlob | <\accessTier> | <\containerName> | <\blockBlob> |
| ページ BLOB | <\storageAccountName>_PageBlob | <\containerName> | <\pageBlob> | |
| File Storage | <\storageAccountName>_AzFile | <\fileShareName> | <\file> |
ファイルを Data Box 共有の "ルート" フォルダーに直接コピーすることはできません。 代わりに、ユース ケースに応じて Data Box 共有内にフォルダーを作成します。
ブロック BLOB では、ファイル レベルでのアクセス層の割り当てをサポートしています。 ブロック BLOB 共有にファイルをコピーする前のベスト プラクティスとして、適切なアクセス層内に新しいサブフォルダーを追加することをお勧めします。 新しいサブフォルダーを作成した後、必要に応じて各サブフォルダーへのファイルの追加を続けます。
ブロック BLOB 共有のルートにあるどのフォルダーにも、新しいコンテナーが作成されます。 そのフォルダー内のすべてのファイルは、ストレージ アカウントの既定のアクセス層にブロック BLOB としてコピーされます。
BLOB アクセス層の詳細については、「BLOB データのアクセス層」を参照してください。 アクセス層のベスト プラクティスについて詳しくは、「BLOB アクセス層を使用するためのベスト プラクティス」をご覧ください。
次の表は、Data Box 上の共有への UNC パスと、それに対応するデータのアップロード先である Azure Storage のパスの URL を示しています。 Azure Storage の最終的なパスの URL は、UNC 共有パスから導き出すことができます。
| Azure Storage の種類 | Data Box 共有 |
|---|---|
| Azure ブロック BLOB | \\<DeviceIPAddress>\<storageaccountname_BlockBlob>\<accessTier>\<ContainerName>\myBlob.txthttps://<storageaccountname>.blob.core.windows.net/<ContainerName>/myBlob.txt |
| Azure ページ BLOB | \\<DeviceIPAddress>\<storageaccountname_PageBlob>\<ContainerName>\myBlob.vhdhttps://<storageaccountname>.blob.core.windows.net/<ContainerName>/myBlob.vhd |
| Azure Files | \\<DeviceIPAddress>\<storageaccountname_AzFile>\<ShareName>\myFile.txthttps://<storageaccountname>.file.core.windows.net/<ShareName>/myFile.txt |
Linux ホスト コンピューターを使っている場合は、次の手順のようにして、NFS クライアントへのアクセスを許可するように Data Box を構成します。
共有にアクセスできる許可するクライアントの IP アドレスを指定します。 ローカル Web UI で、 [接続とコピー] ページに移動します。 [NFS の設定] で、[NFS のクライアント アクセス] を選択します。
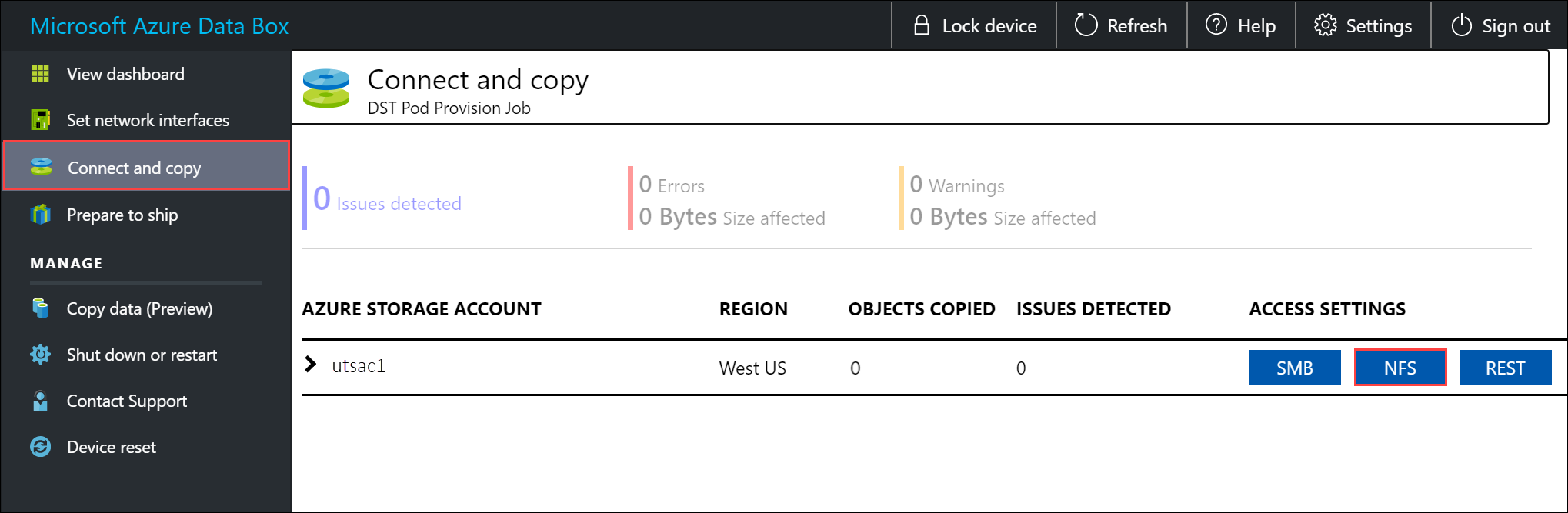
NFS クライアントの IP アドレスを指定して、[追加] を選びます。 この手順を繰り返すことにより、複数の NFS クライアントに対するアクセスを構成できます。 [OK] を選択します。
Linux ホスト コンピューターにサポートされているバージョンの NFS クライアントがインストールされていることを確認します。 お使いの Linux ディストリビューションの特定のバージョンを使用します。
NFS クライアントをインストールした後、次のコマンドを使用して、Data Box デバイスに NFS 共有をマウントします。
sudo mount <Data Box device IP>:/<NFS share on Data Box device> <Path to the folder on local Linux computer>次の例のようにして、NFS を使って Data Box の共有に接続します。 この例で、Data Box デバイスの IP は
10.161.23.130です。 共有Mystoracct_Blobは ubuntuVM にマウントされており、マウント ポイントは/home/databoxubuntuhost/databoxです。sudo mount -t nfs 10.161.23.130:/Mystoracct_Blob /home/databoxubuntuhost/databoxMac クライアントの場合は、次のように、さらにオプションを追加する必要があります。
sudo mount -t nfs -o sec=sys,resvport 10.161.23.130:/Mystoracct_Blob /home/databoxubuntuhost/databox重要
ストレージ アカウントの "ルート" フォルダーにファイルを直接コピーすることはできません。 ブロック BLOB ストレージ アカウントのルート フォルダー内には、使用可能な各アクセス層に対応するフォルダーがあります。
データを Azure Data Box にコピーするには、最初に、アクセス層のいずれかに対応するフォルダーを選ぶ必要があります。 次に、その層のフォルダー内に、データを格納するサブフォルダーを作成します。 最後に、データを新しく作成したサブフォルダーにコピーします。 新しいサブフォルダーは、インジェストの間にストレージ アカウント内に作成されるコンテナーを表します。 データはこのコンテナーに BLOB としてアップロードされます。
ブロック BLOB 用の適切なアクセス層を決定する
重要
このセクションに含まれる情報は、2024 年 4 月 1 日以降に発注された注文に適用されます。
Azure Storage では、同じストレージ アカウント内の複数のアクセス層にブロック BLOB データを保存できます。 この機能を使用すると、データにアクセスする頻度に基づいて、データをより効率的に整理して保存できます。 次の表は、Azure Storage のアクセス層に関する情報と推奨事項です。
| レベル | 推奨事項 | ベスト プラクティス |
|---|---|---|
| ホット | 頻繁にアクセスまたは変更されるオンライン データに適しています。 この層はストレージ コストが最も高く、アクセス コストは最も安くなります。 | この層のデータは、定期的かつアクティブに使う必要があるものです。 |
| クール | 頻繁にアクセスまたは変更されないオンライン データに適しています。 この層は、ホット アクセス層よりストレージ コストは安く、アクセス コストは高くなります。 | この層のデータは、30 日以上保存する必要があるものです。 |
| コールド | アクセスや変更はあまり行われないものの、高速で取得する必要があるオンライン データに適しています。 この層は、クール アクセス層よりストレージ コストは安く、アクセス コストは高くなります。 | この層のデータは、90 日以上保存する必要があるものです。 |
| アーカイブ | ほとんどアクセスされず、待ち時間の要件が低いオフライン データに適しています。 | この層のデータは、180 日以上保存する必要があるものです。 180 日以内にアーカイブ アクセス層から削除されたデータは、早期削除料金の対象になります。 |
BLOB アクセス層の詳細については、「BLOB データのアクセス層」を参照してください。 より詳細なベスト プラクティスについては、「BLOB アクセス層を使用するためのベスト プラクティス」を参照してください。
Data Box 内の対応するフォルダーにコピーすることで、ブロック BLOB データを適切なアクセス層に転送できます。 このプロセスについては、「Azure Data Box にデータをコピーする」セクションで詳しく説明します。
Data Box にデータをコピーする
1 つ以上の Data Box 共有に接続したら、次のステップはデータをコピーすることです。 データのコピーを開始する前に、次の制限事項を確認してください。
- 必ず必要なデータ形式に対応する共有にデータをコピーします。 たとえば、ブロック BLOB データは、ブロック BLOB 用の共有にコピーしてください。 VHD はページ BLOB 共有にコピーします。 データ形式が適切な共有の種類と一致しない場合は、後続の手順で、Azure へのデータのアップロードに失敗します。
- AzFile または PageBlob 共有にデータをコピーする場合は、まず共有のルートにフォルダーを作成してから、そのフォルダーにデータをコピーします。
- データを BlockBlob 共有にコピーする場合は、目的のアクセス層内にサブフォルダーを作成してから、新しく作成されたサブフォルダーにデータをコピーします。 サブフォルダーは、データが BLOB としてアップロードされるコンテナ―になります。 共有の"ルート" フォルダーにファイルを直接コピーすることはできません。
- データをコピーするときは、データのサイズが、Azure ストレージ アカウントのサイズ制限に関する記事に記載されているサイズ制限に従っていること確認してください。
- Data Box と Data Box 以外の別のアプリケーションを同時にアップロードした場合、アップロード ジョブの失敗やデータの破損が起きる可能性があります。
- データ コピーに SMB プロトコルと NFS プロトコルの両方を使用する場合、次をお勧めします。
- SMB と NFS には異なるストレージ アカウントを使用します。
- SMB と NFS の両方を使用して Azure の同じエンド宛先に同じデータをコピーすることは避けてください。 このようにした場合は、最終的な結果が不確定になります。
- SMB と NFS の両方を使用した並列コピーは可能ですが、人的エラーが発生しやすいのでお勧めしません。 SMB でのデータ コピーが完了するまで待ってから、NFS でのデータ コピーを開始してください。
- データをブロック BLOB 共有にコピーするときは、目的のアクセス層内にサブフォルダーを作成してから、新しく作成したサブフォルダーにデータをコピーします。 サブフォルダーは、データが BLOB としてアップロードされるコンテナ―を表します。 ストレージ アカウント内の root フォルダーに直接ファイルをコピーすることはできません。
- 大文字と小文字を区別するディレクトリとファイル名を NFS 共有から Data Box 上の NFS に取り込む場合:
名前の大文字と小文字の区別は保持されます。
ファイルの大文字と小文字は区別されません。
たとえば、
SampleFile.txtとSamplefile.Txtをコピーする場合、Data Box にコピーされるときは名前の大文字と小文字の区別が保持されます。 ただし、同じファイルと見なされるため、アップロードされた最後のファイルによって最初のファイルが上書きされます。
重要
データが Azure Storage にコピーされたことを確認するまでは、ソース データのコピーを保持するようにしてください。
Linux ホスト コンピューターを使用している場合は、Robocopy のようなコピー ユーティリティを使用します。 Linux で使用できる代替手段には、rsync、FreeFileSync、Unison、Ultracopier などがあります。
cp コマンドは、ディレクトリをコピーするのに最適なオプションの 1 つです。 使用方法について詳しくは、cp の man ページをご覧ください。
マルチスレッドのコピーに rsync オプションを使用する場合は、以下のガイドラインに従ってください。
Linux クライアントで使用されているファイル システムに応じて、CIFS Utils または NFS Utils パッケージをインストールします。
sudo apt-get install cifs-utilssudo apt-get install nfs-utilsrsyncおよび Parallel をインストールします (Linux ディストリビューションのバージョンによって異なります)。sudo apt-get install rsyncsudo apt-get install parallelマウント ポイントを作成します。
sudo mkdir /mnt/databoxボリュームをマウントします。
sudo mount -t NFS4 //Databox IP Address/share_name /mnt/databoxフォルダーのディレクトリ構造をミラー化します。
rsync -za --include='*/' --exclude='*' /local_path/ /mnt/databoxファイルをコピーします。
cd /local_path/; find -L . -type f | parallel -j X rsync -za {} /mnt/databox/{}j は並列化の数を指定し、X は並列コピーの数です
16 並列コピーから始めて、使用可能なリソースに応じてスレッドの数を増やすことをお勧めします。
重要
Linux ファイルの種類のうち、シンボリック リンク、文字ファイル、ブロック ファイル、ソケット、パイプはサポートされていません。 これらのファイルの種類を使用すると、発送準備手順でエラーが発生します。
エラーを示すため、コピー処理中に通知が表示されます。
![[接続とコピー] でエラーをダウンロードして表示する](media/data-box-deploy-copy-data/view-errors-1.png)
[問題の一覧をダウンロードする] を選択します。
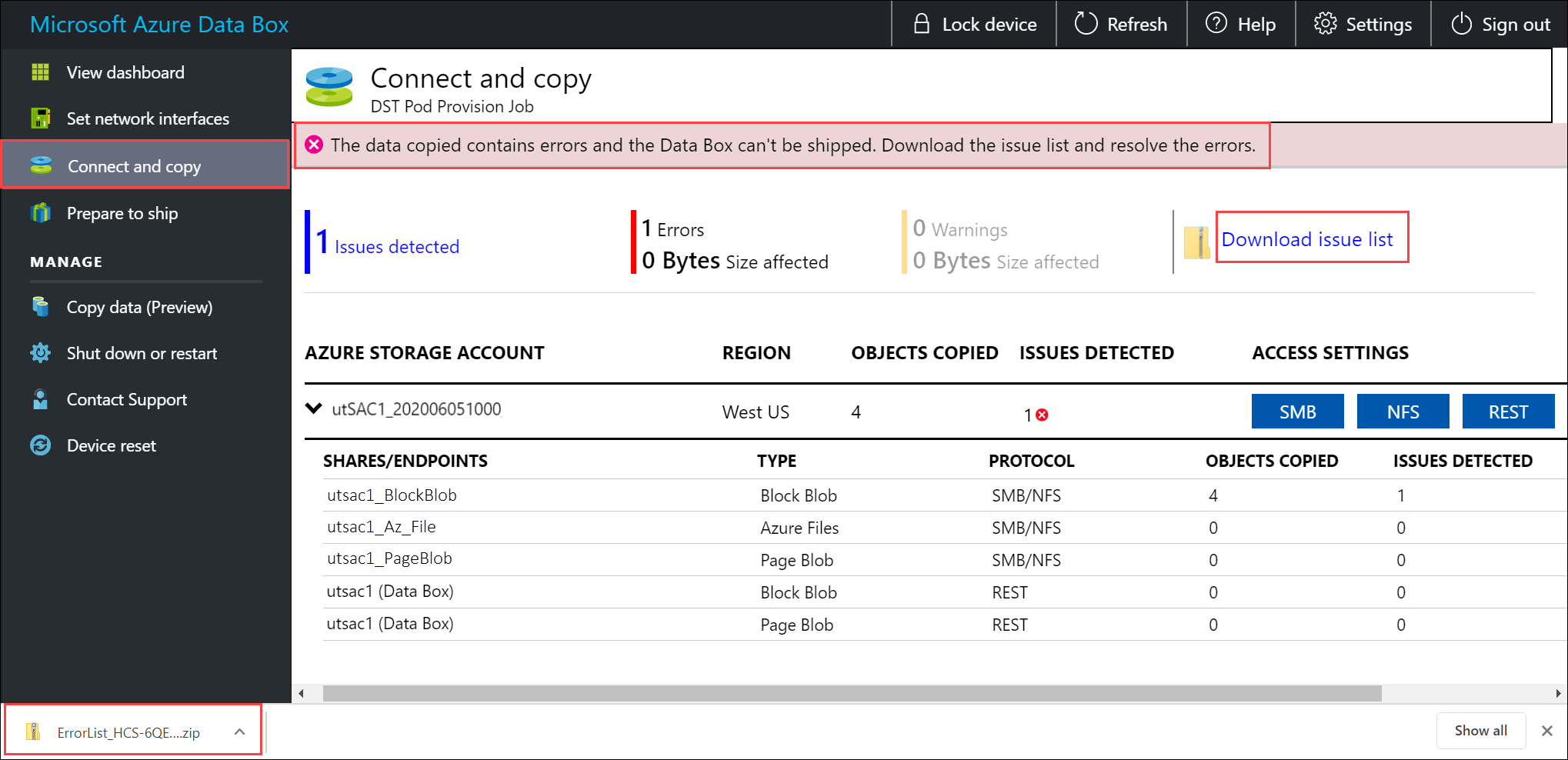
一覧を開いてエラーの詳細を表示し、解決用 URL を選択して推奨される解決方法を確認します。
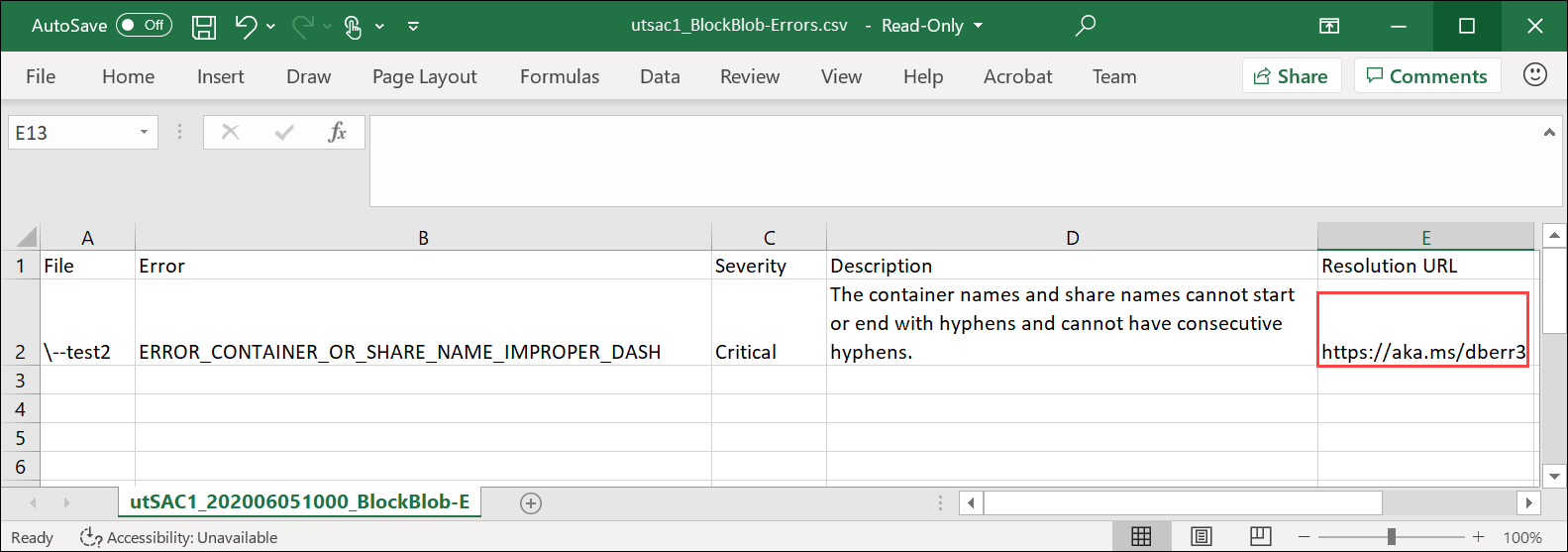
詳細については、「View error logs during data copy to Data Box (Data Box へのデータのコピー中のエラー ログを表示する)」を参照してください。 データのコピー中のエラーの詳細な一覧については、Data Box の問題のトラブルシューティングに関するページを参照してください。
データの整合性を保証するため、データがコピーされるときにインラインでチェックサムが計算されます。 コピーが完了したら、デバイスで使用済み領域と空き領域を確認します。
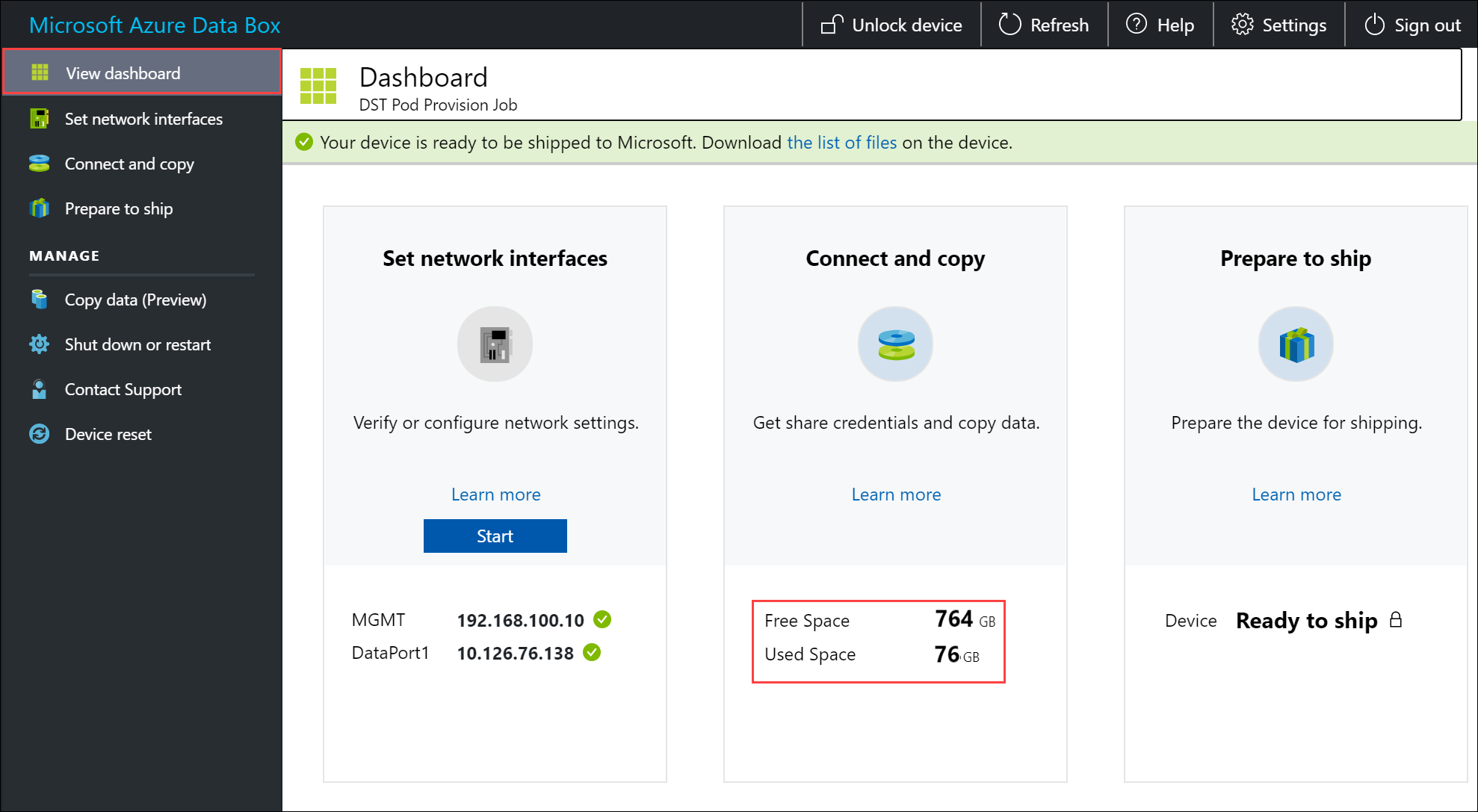
次のステップ
このチュートリアルでは、Azure Data Box に関する次のようなトピックについて説明しました。
- Data Box のデータ コピーの前提条件
- Data Box への接続
- ブロック BLOB の適切なアクセス層の決定
- Data Box へのデータのコピー
次のチュートリアルに進み、お客様の Data Box を Microsoft に返送する方法を学習してください。