重要
SharePoint Online インデクサーのサポートはパブリック プレビュー段階です。 追加使用条件に基づいて "現状のまま" 提供され、ベスト エフォートでのみサポートされます。 プレビュー機能は、運用ワークロードには推奨されず、一般提供されることを保証するものではありません。
開始 する前に、既知の制限事項に関する セクションを参照してください。
このフォームに入力 して、プレビューに登録します。 すべての要求が自動的に承認されます。 フォームに入力したら、 プレビュー REST API を使用してコンテンツのインデックスを作成します。
この記事では、Azure AI Search でのフルテキスト検索のために、検索インデクサーを構成して、SharePoint ドキュメント ライブラリに格納されているドキュメントのインデックスを作成する方法について説明します。 最初に構成手順を示し、次に動作とシナリオを示します
Azure AI Search では、インデクサーがデータ ソースから検索可能なデータとメタデータを抽出します。 SharePoint Online インデクサーは、SharePoint サイトに接続し、1 つ以上のドキュメント ライブラリにあるドキュメントのインデックスを作成します。 インデクサーには以下の機能があります。
- 1 つ以上のドキュメント ライブラリからファイルとメタデータのインデックスを作成します。
- インデックスを段階的に作成し、新しいファイルと変更されたファイルとメタデータのみを取得します。
- 削除されたコンテンツを自動的に検出します。 ライブラリ内のドキュメントの削除は、次のインデクサー実行で取得され、対応する検索ドキュメントがインデックスから削除されます。
- インデックス付きドキュメントからテキストと正規化された画像を自動的に抽出します。 必要に応じて、スキルセットを追加して、OCR やテキスト翻訳など、より深い AI エンリッチメントを作成できます。
前提条件
Azure AI 検索、Basic 価格レベル以上。
Microsoft 365 クラウド サービスの SharePoint (OneDrive はサポートされているデータ ソースではありません)。
ドキュメント ライブラリ内のファイル。
サポートされるドキュメントの形式
SharePoint Online インデクサーは、次の形式のドキュメントからテキストを抽出できます。
- CSV (CSV BLOB のインデックス作成に関する記事を参照)
- EML
- EPUB
- GZ
- HTML
- JSON (JSON BLOB のインデックス作成に関する記事を参照)
- KML (地理的表現の XML)
- Microsoft Office 形式: DOCX/DOC/DOCM、XLSX/XLS/XLSM、PPTX/PPT/PPTM、MSG (Outlook 電子メール)、XML (2003 と 2006 両方の WORD XML)
- オープン ドキュメント形式: ODT、ODS、ODP
- プレーンテキスト ファイル (「プレーン テキストのインデックス作成」も参照)
- RTF
- XML
- 郵便番号
制限と考慮事項
この機能の制限は次のとおりです。
インデクサーは、ドキュメント ライブラリでサポートされているドキュメント形式のコンテンツにインデックスを作成できます。 SharePoint リスト、ASPX サイト コンテンツ、および OneNote ノートブック ファイルに対するインデクサーのサポートはありません。 さらに、特定のサイトからのサブサイトの再帰的なインデックス作成はサポートされていません。
増分インデックス作成での制限:
SharePoint フォルダーの名前を変更すると、増分インデックス作成が中断されます。 名前が変更されたフォルダーは、新しいコンテンツとして扱われます。
SharePoint ファイル システムメタデータを更新する Microsoft 365 プロセスは、コンテンツに他の変更がない場合でも、増分インデックス作成をトリガーできます。 インデクサーと AI エンリッチメントを使用する前に、必ずセットアップをテストし、ドキュメント処理の数を理解してください。
セキュリティの制限事項:
プライベート エンドポイントはサポートされません。
Microsoft Entra ID 条件付きアクセス用に構成されたドキュメント ライブラリまたはコンテンツはサポートされません。
ユーザー暗号化ファイル、Information Rights Management (IRM) で保護されたファイル、パスワードを含む ZIP ファイル、または同様の暗号化されたコンテンツはサポートされていません。
ドキュメント レベルでユーザーごとのアクセスを決定する SharePoint の詳細な承認モデルはサポートされません。 インデクサーは、これらのアクセス許可をインデックスにプルしません。 コンテンツは、インデックスへの読み取りアクセス権を持つすべてのユーザーが利用できます。 ドキュメント レベルのアクセス許可が必要な場合は、 セキュリティ フィルターを使用して結果をトリミング し、ファイル レベルでアクセス許可をインデックス内のフィールドにコピーすることを自動化することを検討してください。
この機能を使用する場合の考慮事項を次に示します。
SharePoint データとチャットするためにカスタム Copilot または RAG (取得拡張生成) アプリケーションを作成する必要がある場合は、このプレビュー機能の代わりに Microsoft Copilot Studio を使用することをお勧めします。
運用環境で Azure AI Search を使用するカスタム SharePoint Online コンテンツ インデックス作成ソリューションが必要な場合は、Microsoft Copilot Studio を使用することをお勧めしますが、次の点を考慮してください。
SharePoint Webhook を使用してカスタム コネクタを作成し、Microsoft Graph API を呼び出してデータを Azure BLOB コンテナーにエクスポートした後、増分インデックス作成に Azure BLOB インデクサーを使用します。
一般公開時に Azure Logic AppsSharePoint コネクタ と Azure AI Search コネクタ を使用して独自の Azure Logic Apps ワークフローを作成する。 Azure portal ウィザードによって生成されたワークフローを出発点として使用し、Azure Logic Apps デザイナーでカスタマイズして、必要な変換手順を含めることができます。 Azure AI Search ウィザード を使用して SharePoint Online データのインデックスを作成するときに作成される Azure Logic App ワークフローは、 従量課金ワークフローです。 運用環境のワークロードを設定する場合は、 標準のロジック アプリ ワークフロー に切り替えて、その追加のエンタープライズ機能を利用してください。
選択した方法に関係なく、SharePoint フックを使用してカスタム コネクタを構築するか、Azure Logic Apps ワークフローを作成するかに関係なく、確実に堅牢なセキュリティ対策を実装してください。 これらの対策には、共有プライベート リンクの構成、ファイアウォールの設定、ソースからのユーザーアクセス許可の保持、クエリ時のアクセス許可の優先などが含まれます。 また、パイプラインの監査と監視も定期的に行う必要があります。
SharePoint Online インデクサーを構成する
SharePoint Online インデクサーを設定するには、プレビュー REST API を使用します。 このセクションでは、手順について説明します。
手順 1 (省略可能): システム割り当てマネージド ID を有効にする
システム割り当てマネージド ID を有効にして、検索サービスがプロビジョニングされているテナントを自動的に検出します。
SharePoint サイトが検索サービスと同じテナントにある場合は、この手順を実行します。 SharePoint サイトが別のテナントにある場合は、この手順をスキップします。 ID はインデックス作成には使用されず、テナントの検出のみに使用されます。 接続文字列にテナント ID を含める場合は、この手順をスキップすることもできます。
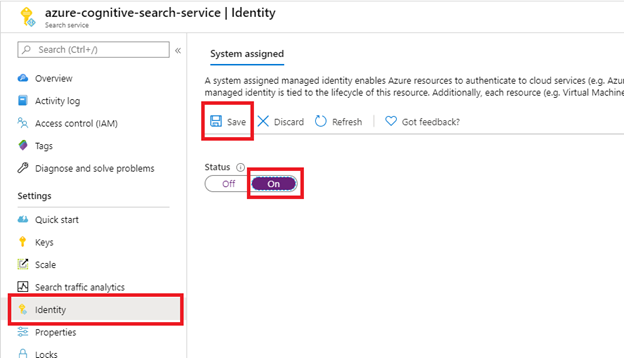
[保存] を選択した後に、検索サービスに割り当てられたオブジェクト ID が取得されます。
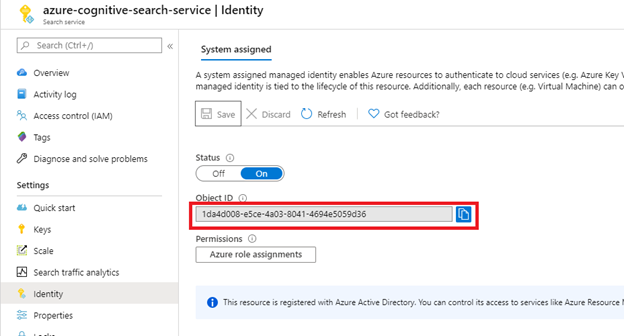
手順 2: インデクサーに必要なアクセス許可を決定する
SharePoint Online インデクサーは、委任されたアクセス許可とアプリケーションのアクセス許可の両方をサポートします。 シナリオに基づいて、使用するアクセス許可を選択します。
アプリベースのアクセス許可をおすすめします。 委任されたアクセス許可に関連する既知の問題については、制限事項を参照してください。
アプリケーションのアクセス許可 (推奨)。インデクサーは、すべてのサイトとファイルにアクセスできる SharePoint テナントの ID で実行されます。 インデクサーには、クライアント シークレットが必要です。 また、インデクサーは、任意のコンテンツにインデックスを作成する前に、テナント管理者の承認を必要とします。
委任されたアクセス許可。インデクサーは、要求を送信したユーザーまたはアプリケーションの ID で実行されます。 データ アクセスは、呼び出し元がアクセスできるサイトおよびファイルに制限されます。 デリゲートされたアクセス許可をサポートするため、インデクサーにはユーザーの代わりにサインインするためのデバイス コード プロンプトが必要です。 ユーザーによって委任されたアクセス許可では、この認証の種類の実装に使用された最新のセキュリティ ライブラリごとに、75 分ごとにトークンの有効期限が適用されます。 これは調整できるビヘイビアーではありません。 有効期限が切れたトークンには、「インデクサーの実行 (プレビュー)」を使用して手動でインデックスを作成する必要があります。 このため、代わりにアプリベースのアクセス許可を使用する必要があります。
手順 3: Microsoft Entra アプリケーション登録を作成する
SharePoint Online インデクサーは、認証に Microsoft Entra アプリケーションを使用します。 Azure AI Search と同じテナントにアプリケーション登録を作成します。
Azure portal にサインインします。
Microsoft Entra ID を検索または移動し、[追加>App 登録] を選択します。
[+ 新規登録] を選択します。
- ご自分のアプリの名前を指定します。
- [シングル テナント] を選択します。
- URI 指定手順をスキップします。 リダイレクト URI は必要ありません。
- [登録] を選択します。
ナビゲーション ウィンドウの [ 管理] で、[ API のアクセス許可] を選択し、[ アクセス許可を追加]、[ Microsoft Graph] の順に選択します。
インデクサーがアプリケーション API のアクセス許可を使用している場合は、[アプリケーションのアクセス許可] を選択し、次のように追加します。
- Application - Files.Read.All
- Application - Sites.Read.All

アプリケーションのアクセス許可を使用すると、インデクサーはサービス コンテキスト内の SharePoint サイトにアクセスします。 そのため、インデクサーを実行すると、SharePoint テナントのすべてのコンテンツにアクセスできるようになります。そのためには、テナント管理者の承認が必要です。 クライアント シークレットは、認証にも必要です。 クライアント シークレットの設定については、この記事の後半で説明します。
インデクサーが委任された API のアクセス許可を使用している場合は、[委任されたアクセス許可] を選択し、次を追加します。
- 委任済み - Files.Read.All
- 委任済み - Sites.Read.All
- 委任済み - User.Read
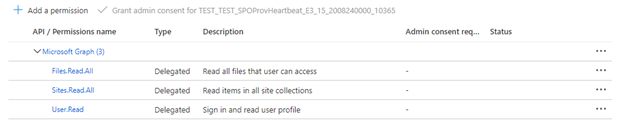
委任されたアクセス許可により、検索クライアントは、現在のユーザーのセキュリティ ID で SharePoint に接続できます。
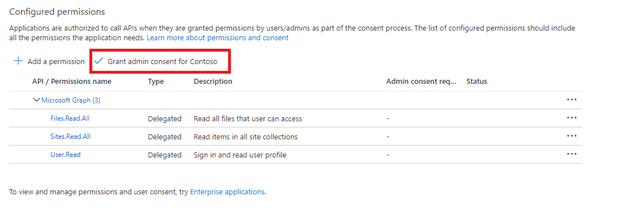
管理者の同意を与えます。
アプリケーション API のアクセス許可を使用する場合は、テナント管理者の同意が必要です。 一部のテナントはロックダウンされていて、委任された API アクセス許可にも、そのテナント管理者の同意必要です。 これらの条件のいずれかに該当する場合は、インデクサーを作成する前に、この Microsoft Entra アプリケーションに対してテナント管理者が同意する必要があります。
認証 タブを選択します。
[Allow public client flows]\(パブリック クライアント フローを許可する\) を [はい] に設定してから、[保存] を選択します。
[+ プラットフォームを追加]、[モバイル アプリケーションとデスクトップ アプリケーション] の順に選択し、
https://login.microsoftonline.com/common/oauth2/nativeclientのチェック ボックスをオンにしてから、[構成] を選択します。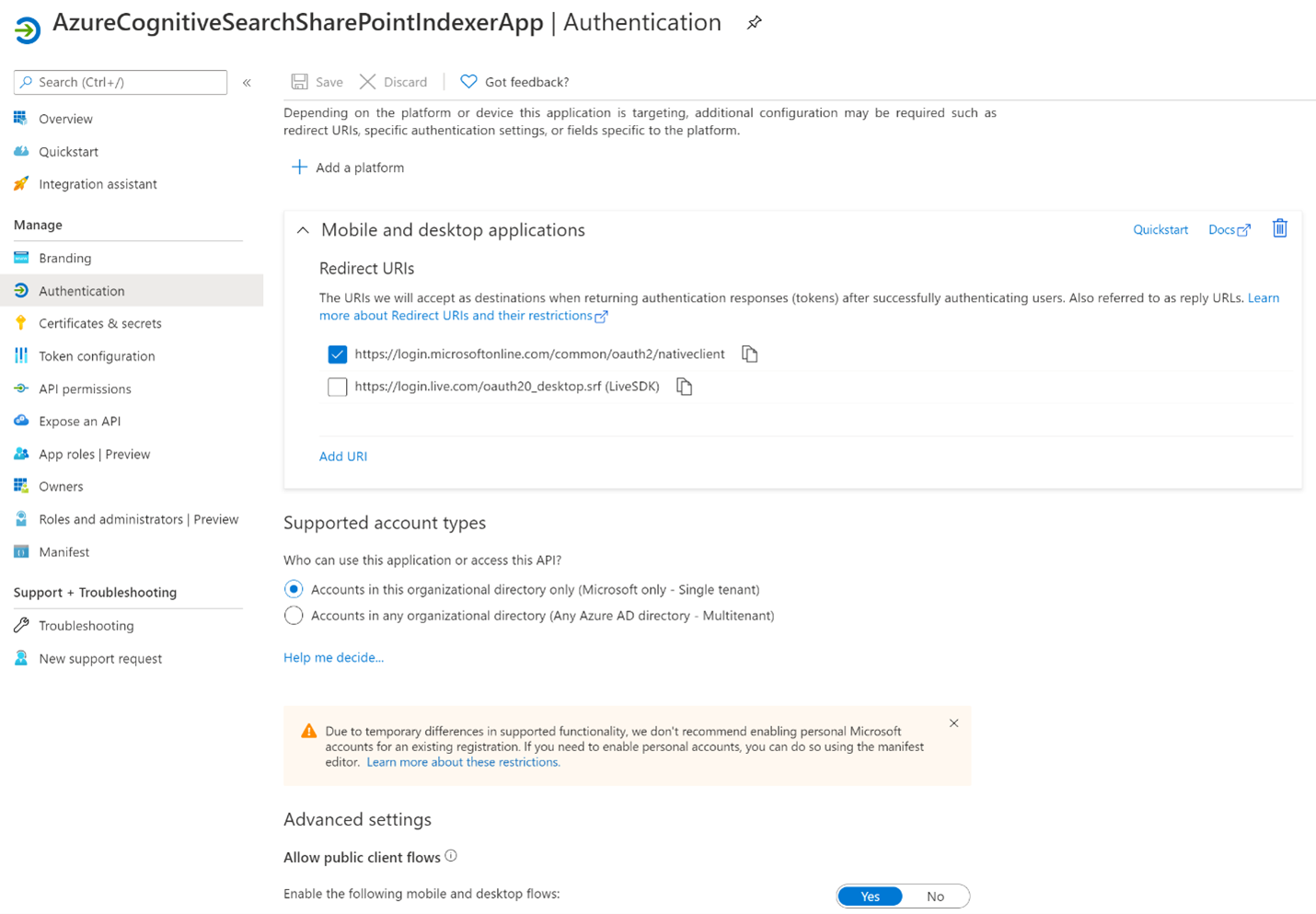
(アプリケーション API のアクセス許可のみ) アプリケーションのアクセス許可を使用して Microsoft Entra アプリケーションに対して認証するには、インデクサーにクライアント シークレットが必要です。
左側のメニューから [証明書とシークレット] を選択し、[クライアント シークレット]、[新しいクライアント シークレット] の順にクリックします。

ポップアップ表示されたメニューで、新しいクライアント シークレットの説明を入力します。 必要に応じて有効期限を調整します。 有効期限が切れた場合、シークレットを再作成する必要があり、インデクサーを新しいシークレットで更新する必要があります。
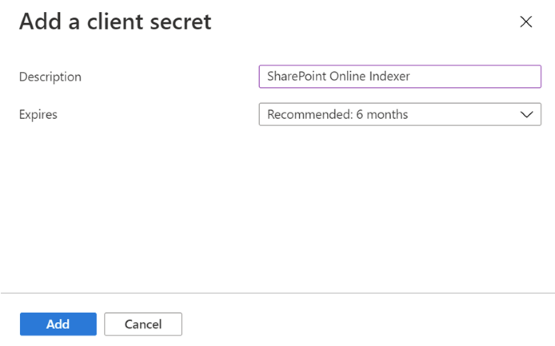
新しいクライアント シークレットが [シークレット] の一覧に表示されます。 ページから移動すると、シークレットは表示されなくなります。そのため、[コピー] ボタンを使用してコピーし、安全な場所に保存してください。

手順 4: データ ソースを作成する
このセクション以降、残りの手順ではプレビュー REST API を使用します。 最新のプレビュー API をお勧めします。
データ ソースでは、インデックスを作成するデータ、資格情報、およびデータの変更 (新しい行、変更された行、削除された行) を効率よく識別するためのポリシーを指定します。 データ ソースは、同じ Search サービス内の複数のインデクサーで使用できます。
SharePoint のインデックスを作成する場合は、次の必須プロパティがデータ ソースに必要です。
- name は、Search サービス内のデータ ソースの一意の名前です。
- type は "sharepoint" である必要があります。 この値は、大文字と小文字が区別されます。
- credentials には、SharePoint エンドポイントと Microsoft Entra アプリケーション (クライアント) ID を指定します。 SharePoint エンドポイントの例は、
https://microsoft.sharepoint.com/teams/MySharePointSiteです。 エンドポイントを取得するには、ご自分の SharePoint サイトのホーム ページに移動し、ブラウザーから URL をコピーします。 - container には、インデックスを作成するドキュメント ライブラリを指定します。 プロパティは、どのドキュメントにインデックスを付けるかを制御します。
データ ソースを作成するには、データ ソースの作成 (プレビュー) を呼び出します。
POST https://[service name].search.windows.net/datasources?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
接続文字列の形式
接続文字列の形式は、インデクサーが委任された API のアクセス許可を使用しているか、アプリケーション API のアクセス許可を使用しているかに基づいて変化します。
委任された API のアクセス許可の接続文字列の形式
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]アプリケーション API のアクセス許可の接続文字列の形式
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
注
SharePoint サイトが検索サービスと同じテナント内にあり、システム割り当てマネージド ID が有効になっている場合は、TenantId を接続文字列に含める必要はありません。 SharePoint サイトが検索サービスとは異なるテナント内にある場合は、TenantId を含める必要があります。
手順 5: インデックスを作成する
インデックスでは、検索に使用する、ドキュメント内のフィールド、属性、およびその他の構成要素を指定します。
インデックスを作成するには、インデックスの作成 (プレビュー) を呼び出します。
POST https://[service name].search.windows.net/indexes?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
重要
SharePoint Online インデクサーによって設定されたインデックスのキーフィールドとして metadata_spo_site_library_item_id のみを使用できます。 キー フィールドがデータ ソースに存在しない場合、metadata_spo_site_library_item_id は自動的にキー フィールドにマップされます。
手順 6: インデクサーを作成する
インデクサーはデータ ソースをターゲットの検索インデックスに接続し、データ更新を自動化するスケジュールを提供します。 インデックスとデータ ソースを作成した後、インデクサーを作成できます。
委任されたアクセス許可を使っている場合は、このステップの間に、SharePoint サイトにアクセスできる組織の資格情報を使ってサインインするよう求められます。 可能であれば、新しい組織ユーザー アカウントを作成し、その新しいユーザーに、インデクサーに必要なアクセス許可を付与することをお勧めします。
インデクサーを作成するには、いくつかの手順があります。
インデクサーの作成 (プレビュー) 要求を送信します。
POST https://[service name].search.windows.net/indexers?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }アプリケーションのアクセス許可を使っている場合は、インデックスのクエリを始める前に、最初の実行が完了するのを待つ必要があります。 このステップで説明する次の手順は、委任されたアクセス許可に特に関連するものであり、アプリケーションのアクセス許可には適用されません。
初めてインデクサーを作成する場合、インデクサーの作成 (プレビュー) 要求は次の手順を完了するまで待機します。 [インデクサー状態の取得] を呼び出してリンクを取得し、新しいデバイス コードを入力する必要があります。
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key]10 分以内にインデクサー状態の取得を実行しないと、コードの有効期限が切れ、データ ソースを再作成する必要があります。
インデクサーの状態の取得応答からデバイス ログイン コードをコピーします。 デバイスのログインは、"errorMessage" にあります。
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }エラー メッセージに含まれているコードを指定します。
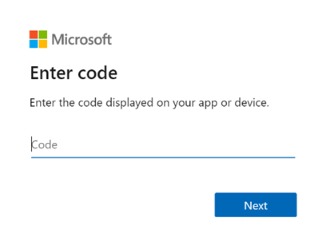
SharePoint Online インデクサーは、サインインしているユーザーとして SharePoint コンテンツにアクセスします。 この手順でログインするユーザーは、そのサインインしているユーザーになります。 そのため、インデックスを作成するドキュメント ライブラリ内のドキュメントにアクセスできないユーザー アカウントを使用してサインインした場合、インデクサーはそのドキュメントにアクセスできません。
可能であれば、新しいユーザー アカウントを作成し、その新しいユーザーに、インデクサーに必要なアクセス許可を付与することをお勧めします。
要求されているアクセス許可を承認します。
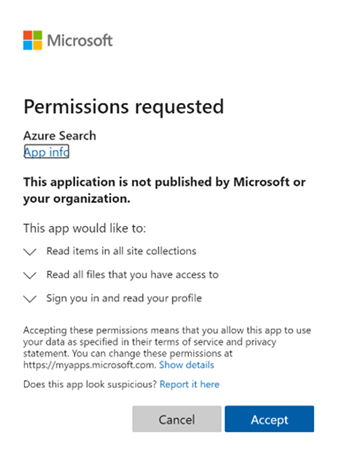
インデクサーの作成 (プレビュー) の最初の要求は、上記で提供されたすべてのアクセス許可が正しく、かつ 10 分の時間枠内であれば完了します。
注
Microsoft Entra アプリケーションに管理者の承認が必要であり、ログイン前に承認されていない場合は、次の画面が表示されることがあります。 続行するには、管理者の承認が必要です。
手順 7: インデクサーの状態を確認する
インデクサーが作成された後、インデクサー状態の取得を呼び出すことができます。
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
データ ソースの更新
データ ソース オブジェクトに対する更新がない場合、ユーザーの介入なしにスケジュールに基づいてインデクサーを実行します。
ただし、デバイス コードの有効期限が切れている間にデータ ソース オブジェクトを変更する場合は、インデクサーを実行するためにもう一度サインインする必要があります。 たとえば、データ ソース クエリを変更した場合は、https://microsoft.com/devicelogin を使用してもう一度サインインし、新しいデバイス コードを取得します。
期限切れのデバイス コードを想定して、データ ソースを更新する手順を次に示します。
インデクサーの実行 (プレビュー) を呼び出し、インデクサーの実行を手動で開始します。
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key]インデクサーの状態を確認します。
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key]https://microsoft.com/deviceloginにアクセスするように求めるエラーが発生した場合は、ページを開き、新しいコードをコピーします。コードをダイアログ ボックスに貼り付けます。
もう一度手動でインデクサーを実行し、インデクサーの状態を確認します。 今度はインデクサーの実行が正常に開始されるはずです。
ドキュメント メタデータのインデックス作成
ドキュメント メタデータ ("dataToExtract": "contentAndMetadata") のインデックスを作成する場合は、次のメタデータを使用して、インデックスを作成できます。
| 識別子 | 型 | 説明 |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | サイトのドキュメント ライブラリ内にある項目を一意に識別する、サイト ID、ライブラリ ID、および項目 ID を組み合わせたキー。 |
| metadata_spo_site_id | Edm.String | SharePoint サイトの ID。 |
| metadata_spo_library_id | Edm.String | ドキュメント ライブラリの ID。 |
| metadata_spo_item_id | Edm.String(エドム・ストリング) | ライブラリ内にある (ドキュメント) 項目の ID。 |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | 項目の最終変更日時 (UTC)。 |
| metadata_spo_item_name | Edm.String | 項目の名前。 |
| metadata_spo_item_size | Edm.Int64 | 項目のサイズ (バイト単位)。 |
| metadata_spo_item_content_type | Edm.String | 項目のコンテンツ タイプ。 |
| metadata_spo_item_extension | Edm.String | 項目の拡張子。 |
| metadata_spo_item_weburi | Edm.String | 項目の URI。 |
| metadata_spo_item_path | Edm.String | 親パスと項目名の組み合わせ。 |
SharePoint Online インデクサーでは、各ドキュメントの種類に固有のメタデータもサポートされています。 詳細については、Azure AI Search で使用されるコンテンツ メタデータのプロパティに関するページを参照してください。
注
カスタム メタデータのインデックスを作成するには、データ ソースのクエリ パラメーターに "additionalColumns" を指定する必要があります。
ファイルの種類で含めるか除外する
インデクサー定義の "parameters" セクションに包含と除外の条件を設定して、どのファイルのインデックスを作成するかを制御できます。
特定のファイル拡張子を含めるには、"indexedFileNameExtensions" をファイル拡張子 (先頭のドットを含む) のコンマ区切りリストに設定します。 特定のファイル拡張子を除外するには、"excludedFileNameExtensions" をスキップする拡張子に設定します。 同じファイル拡張子が両方のリストにある場合、それはインデックス作成から除外されます。
PUT /indexers/[indexer name]?api-version=2025-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
インデックスを作成するドキュメントの制御
1 つの SharePoint Online インデクサーで、1 つ以上のドキュメント ライブラリにあるコンテンツのインデックスを作成できます。 データ ソース定義の "container" パラメーターを使用して、インデックスの作成元になるサイトとドキュメント ライブラリを指定します。
データ ソースの "container" セクションには、"name" と "query" という 2 つのプロパティがあります。
名前
"name" プロパティは必須で、次の値のいずれかである必要があります。
| 値 | 説明 |
|---|---|
| デフォルトサイトライブラリー | サイトの既定のドキュメント ライブラリにあるすべてのコンテンツのインデックスを作成します。 |
| allSiteLibraries | サイト内のすべてのドキュメント ライブラリにあるすべてのコンテンツのインデックスを作成します。 サブサイトのドキュメント ライブラリはスコープ外です。サブサイトのコンテンツが必要な場合は、"useQuery" を選択して "includeLibrariesInSite" を指定します。 |
| useQuery | "query" で定義されているコンテンツのインデックスのみを作成します。 |
クエリ
データ ソースの "query" パラメーターは、キーワードと値のペアで構成されます。 使用できるキーワードを以下に示します。 値は、サイトの URL またはドキュメント ライブラリの URL のいずれかです。
注
特定のキーワードの値を取得するには、含めたり除外したりするドキュメント ライブラリに移動し、ブラウザーから URI をコピーすることをお勧めします。 これは、クエリのキーワードと共に使用する値を取得する最も簡単な方法です。
| キーワード | 値の説明と例 |
|---|---|
| 無効 | null 値または空の場合は、コンテナー名に応じて、既定のドキュメント ライブラリまたはすべてのドキュメント ライブラリのいずれかのインデックスを作成します。 例: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| サイトにライブラリを含める | 接続文字列に含まれる指定されたサイトで、すべてのライブラリにあるコンテンツのインデックスを作成します。 値は、サイトまたはサブサイトの URI である必要があります。 例 1: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } 例 2 (少数のサブサイトのみを含む): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | このライブラリにあるすべてのコンテンツのインデックスを作成します。 値は、ライブラリへの完全修飾パスであり、ブラウザーからコピーできます。 例 1 (完全修飾パス): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } 例 2 (ブラウザーからコピーした URI): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | このライブラリにあるコンテンツのインデックスを作成しません。 値は、ライブラリへの完全修飾パスであり、ブラウザーからコピーできます。 例 1 (完全修飾パス): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } 例 2 (ブラウザーからコピーした URI): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | ドキュメント ライブラリにある列にインデックスを作成します。 値は、インデックスを作成する対象の列名のコンマ区切りのリストです。 列名に含まれるセミコロンとコンマは、二重円記号を使用してエスケープします。 例 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } 例 2 (二重円記号を使用したエスケープ文字): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
エラーを処理する
既定では、SharePoint Online インデクサーは、サポートされていないコンテンツ タイプ (画像など) のドキュメントを検出するとすぐに停止します。 excludedFileNameExtensions パラメーターを使用して特定のコンテンツの種類をスキップできます。 ただし、存在する可能性のあるすべてのコンテンツ タイプが事前にわからないままドキュメントのインデックスを作成する必要がある場合もあります。 サポートされていないコンテンツ タイプが検出されたときにインデックス作成を続行するには、failOnUnsupportedContentType 構成パラメーターを false に設定します。
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
一部のドキュメントについては、Azure AI Search でコンテンツ タイプを判別できないことや、他ではサポートされているコンテンツ タイプのドキュメントを処理できないことがあります。 この障害モードを無視するには、failOnUnprocessableDocument 構成パラメーターを false に設定します。
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Azure AI Search では、インデックスを作成するドキュメントのサイズが制限されています。 これらの制限は、「Azure AI Search のサービス制限」に記載されています。 サイズが大きいドキュメントは、既定ではエラーとして扱われます。 ただし、indexStorageMetadataOnlyForOversizedDocuments 構成パラメーターを true に設定した場合、サイズが大きいドキュメントのストレージ メタデータのインデックスも作成することができます。
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
ドキュメントの解析中またはインデックスへのドキュメントの追加中、処理のどこかの時点でエラーが発生した場合に、インデックス作成を続行することもできます。 特定数のエラーを無視するには、構成パラメーター maxFailedItems と maxFailedItemsPerBatch を望ましい値に設定します。 次に例を示します。
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
SharePoint サイト上のファイルで暗号化が有効になっている場合は、次のようなエラー メッセージが表示されることがあります。
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
エラー メッセージには、SharePoint サイト ID、ドライブ ID、ドライブ項目 ID も次のパターンで含まれます: <sharepoint site id> :: <drive id> :: <drive item id>。 この情報を使用して、SharePoint 側で障害が発生している項目を識別できます。 その後、ユーザーは項目から暗号化を削除して問題を解決できます。