クォータを使用すると、サブスクリプション内のデプロイ全体で、レート制限の割り当てを柔軟に管理できます。 この記事では、Foundry モデルで Azure AI Foundry 仮想マシンと Azure OpenAI のクォータを管理するプロセスについて説明します。
Azure では、不正による予算超過を防ぎ、Azure の容量の制約を尊重するために制限とクォータを使用しています。 また、管理者のコスト管理にもお勧めです。 運用環境のワークロードに合わせてスケーリングするときは、これらの制限事項について考慮してください。
この記事では、以下について説明します。
- Azure リソースの既定の制限
- Azure AI Foundry ハブレベルのクォータの作成。
- クォータと制限の表示
- クォータと制限の引き上げ要求
クォータを使用すると、サブスクリプション内のデプロイ全体で、レート制限の割り当てを柔軟に管理できます。 この記事では、Foundry モデルで Azure OpenAI のクォータを管理するプロセスについて説明します。
Azure では、不正による予算超過を防ぎ、Azure の容量の制約を尊重するために制限とクォータを使用しています。 また、管理者のコスト管理にもお勧めです。 運用環境のワークロードに合わせてスケーリングするときは、これらの制限事項について考慮してください。
この記事では、以下について説明します。
- クォータと制限の表示
- クォータと制限の引き上げ要求
特別な考慮事項
クォータは、アカウント内の各サブスクリプションに適用されます。 複数のサブスクリプションがある場合は、サブスクリプションごとにクォータの引き上げを要求する必要があります。
クォータは、容量の保証ではなく、Azure リソースのクレジット制限です。 大規模な容量が必要な場合は、Azure サポートに連絡してクォータを引き上げてください。
注
Azure AI Foundry コンピューティングには、コア コンピューティング クォータとは別のクォータがあります。
既定の制限は、無料試用版、サーバーレス API のデプロイ、仮想マシン (VM) シリーズ (Dv2、F、G など) など、オファー カテゴリの種類によって異なります。
Azure AI Foundry クォータ
Azure AI Foundry ポータルの次の操作では、クォータが使用されます。
- コンピューティング インスタンスの作成。
- ベクトル インデックスのビルド。
- モデル カタログからのオープン モデルのデプロイ。
Azure AI Foundry コンピューティング
Azure AI Foundry コンピューティングには、サブスクリプションのリージョンごとに許可されるコアの数と一意のコンピューティング リソースの数の両方に対して、既定のクォータ制限があります。
- コア数のクォータは、各 VM ファミリと累積合計コアによって分割されます。
- リージョンあたりの一意のコンピューティング リソースの数に対するクォータは、マネージド コンピューティング リソースにのみ適用されるため、VM コア クォータとは別です
コンピューティングの上限を引き上げるには、Azure AI Foundry でクォータの引き上げを要求できます。
使用可能なリソースは次のとおりです。
- リージョンあたりの専用コアには、サブスクリプション プランの種類に応じて、24 から 300 の既定の制限があります。 サブスクリプションあたりの専用コアの数は VM ファミリごとに引き上げることができます。 NCv2、NCv3、ND シリーズなど、特殊な VM ファミリは、ゼロ コアの既定から開始されます。 GPU の既定のコア数も 0 です。
- リージョンあたりのコンピューティングの合計制限には、特定のサブスクリプション内のリージョンあたり 500 という既定の制限があります。 この制限は、リージョンあたり最大 2500 まで増やすことができます。 この制限は、コンピューティング インスタンスとマネージド オンライン エンドポイント デプロイの間で共有されます。 コンピューティング インスタンスは、クォータ目的で単一のノード クラスターと見なされます。 合計コンピューティング制限を引き上げるには、オンライン カスタマー サポート リクエストを開いてください。
合計コンピューティング制限を引き上げるためのサポート リクエストを開始する際には、次の情報を提供してください。
問題の種類で、[技術] を選択します。
クォータを増やしたいサブスクリプションを選択します。
サービスの種類として [Machine Learning] を選びます。
クォータを増やしたいリソースを選択します。
[概要] フィールドに「合計コンピューティング制限の引き上げ」と入力します。
問題の種類として [コンピューティング インスタンス] を選択し、問題のサブタイプとして [クォータ] を選択します。
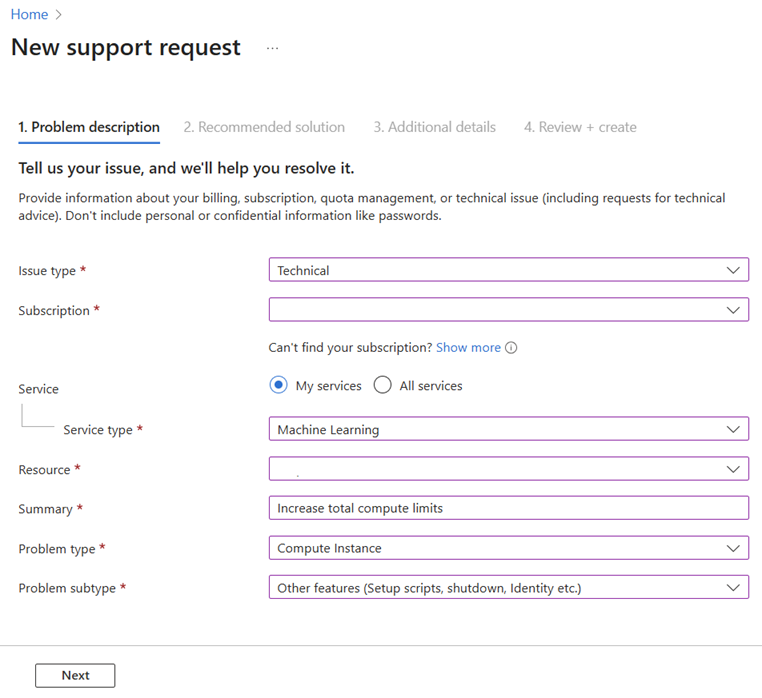
[次へ] を選択します。
[その他の詳細] ページで、サブスクリプション ID、リージョン、新しい制限 (500 から 2500 の間)、このリージョンの合計コンピューティング制限を引き上げるためのビジネス上の正当な理由を入力します。
[作成] を選択してサポート リクエスト チケットを送信します。

Azure AI Foundry の共有クォータ
Azure AI Foundry には、さまざまなリージョンのさまざまなユーザーが同時に使用できる共有クォータのプールが用意されています。 可用性に応じて、ユーザーは一次的に共有プールからクォータにアクセスし、限られた時間だけクォータを使用してテストを実行できます。 具体的な時間は、ユース ケースによって異なります。 クォータ プールから一時的にクォータを使用することで、短期的なクォータ増加のサポート チケットを提出したり、クォータ要求が承認されるまで待ってからワークロードを進める必要がなくなります。
共有クォータ プールの使用は、モデル カタログから Llama-2、Phi、Nemotron、Mistral、Dolly、Deci-DeciLM モデルの推論をテストするために使用できます。 共有クォータは、本番エンドポイントではなく、一時的なテスト エンドポイントを作成する場合にのみ使用する必要があります。 本番環境のエンドポイントの場合は、専用のクォータを要求する必要があります。 共有クォータの課金は使用量ベースです。
コンテナ事例
詳細については、「Container Instances の制限」を参照してください。
ストレージ
Azure Storage では、サブスクリプションおよびリージョンあたりのストレージ アカウント数が 250 に制限されています。 この制限には、Standard および Premium ストレージ アカウントの両方が含まれます。
Azure AI Foundry ポータルでクォータを表示して要求する
クォータを使用して、同じサブスクリプション内の複数のハブ ベースのプロジェクト間でコンピューティング ターゲットの割り当てとモデル クォータを管理します。
既定では、すべてのハブが VM ファミリのサブスクリプション レベル クォータと同じクォータを共有しています。 ただし、サブスクリプション内のハブでは、より詳細なコスト制御とガバナンスを実現するために、個々の VM ファミリに最大クォータを設定できます。 個々の VM ファミリのクォータを使用すると、容量を共有し、リソースの競合の問題を回避できます。
クォータを使用して、同じサブスクリプション内の複数の Foundry プロジェクト間のモデル クォータ割り当てを管理する
Azure AI Foundry ポータルで、左側のメニューの下部にある 管理センター を選択します。
左側のメニューから [クォータ] を選択します。
![[管理] セクションの [Model quota]\(モデル クォータ\) エントリと [VM quota]\(VM クォータ\) エントリのスクリーンショット。](../media/cost-management/quotas.png)
[クォータ] ビューから、選択した Azure リージョン内のモデルのクォータを確認できます。 クォータを要求するには、モデルを選択し、[ クォータの要求] を選択します。
![Azure AI Foundry ポータルの [モデル クォータ] ページのスクリーンショット。](../media/cost-management/model-quota.png)
- [Show all quota]\(すべてのクォータの表示\) トグルを使用して、すべてのクォータまたは現在割り当てられているクォータのみを表示します。
- [グループ化] ドロップダウンを使用して、[クォータの種類]、[Region & Model]\(リージョンとモデル\)、[クォータの種類]、[Model & Region]\(モデルとリージョン\)、または [なし] でリストをグループ化します。 [なし] でグループ化すると、モデル デプロイの一覧が表示されます。
- グループ化を展開して、特定のモデル デプロイに関する情報を表示します。 モデル デプロイを表示しているときに、[Quota allocation]\(クォータの割り当て\) 列で鉛筆アイコンを選択して、モデル デプロイのクォータ割り当てを編集します。
- ページの横にある [グラフ] を使用して、クォータの使用状況の詳細を表示します。 グラフは対話型です。グラフのセクションにカーソルを合わせると詳細情報が表示され、グラフを選択するとモデルの一覧がフィルター処理されます。 グラフの凡例を選択すると、グラフに表示されるデータがフィルター処理されます。
- [Azure OpenAI Provisioned]\(プロビジョニングされた Azure OpenAI\) リンクを使用して、プロビジョニングされたモデルに関する情報 (キャパシティ計算ツールなど) を表示します。
[VM クォータ] リンクを選択すると、選択した Azure リージョン内の仮想マシン ファミリのクォータと使用状況を表示できます。 クォータを要求するには、VM ファミリを選択し、[ クォータの要求] を選択します。
ヒント
VM クォータ リンクが表示されない場合は、管理センターを選択したときに Foundry プロジェクト プロジェクトを表示していました。 [すべてのリソース] リンクを使用し、[種類] に [親リソース: 名前 (ハブ)] が含まれているプロジェクトを選択し、左側のメニューから [クォータ] を選択します。
![Azure AI Foundry ポータルの [VM クォータ] ページのスクリーンショット。](../media/cost-management/vm-quota.png)
![[管理] セクションの [Model quota]\(モデル クォータ\) エントリと [VM quota]\(VM クォータ\) エントリのスクリーンショット。](../media/cost-management/quotas.png#lightbox)
![Azure AI Foundry ポータルの [モデル クォータ] ページのスクリーンショット。](../media/cost-management/model-quota.png#lightbox)
![Azure AI Foundry ポータルの [VM クォータ] ページのスクリーンショット。](../media/cost-management/vm-quota.png#lightbox)
Azure AI Foundry ポータルで、左側のメニューの下部にある 管理センター を選択します。
左側のメニューから [クォータ] を選択します。
[クォータ] ビューから、選択した Azure リージョン内のモデルのクォータを確認できます。 クォータを要求するには、モデルを選択し、[ クォータの要求] を選択します。
![Azure AI Foundry ポータルの Foundry プロジェクトの [モデル クォータ] ページのスクリーンショット。](../media/cost-management/project-model-quota.png)
- [Show all quota]\(すべてのクォータの表示\) トグルを使用して、すべてのクォータまたは現在割り当てられているクォータのみを表示します。
- [グループ化] ドロップダウンを使用して、[クォータの種類]、[Region & Model]\(リージョンとモデル\)、[クォータの種類]、[Model & Region]\(モデルとリージョン\)、または [なし] でリストをグループ化します。 [なし] でグループ化すると、モデル デプロイの一覧が表示されます。
- グループ化を展開して、特定のモデル デプロイに関する情報を表示します。 モデル デプロイを表示しているときに、[Quota allocation]\(クォータの割り当て\) 列で鉛筆アイコンを選択して、モデル デプロイのクォータ割り当てを編集します。
- ページの横にある [グラフ] を使用して、クォータの使用状況の詳細を表示します。 グラフは対話型です。グラフのセクションにカーソルを合わせると詳細情報が表示され、グラフを選択するとモデルの一覧がフィルター処理されます。 グラフの凡例を選択すると、グラフに表示されるデータがフィルター処理されます。
- [Azure OpenAI Provisioned]\(プロビジョニングされた Azure OpenAI\) リンクを使用して、プロビジョニングされたモデルに関する情報 (キャパシティ計算ツールなど) を表示します。
![Azure AI Foundry ポータルの Foundry プロジェクトの [モデル クォータ] ページのスクリーンショット。](../media/cost-management/project-model-quota.png#lightbox)