マルチデバイスの会話 を使用すると、複数のクライアント間で音声やテキストによる会話を簡単に作成し、その間で送信されるメッセージを調整することができます。
Note
マルチデバイスの会話アクセスは、プレビュー機能です。
マルチデバイスの会話では、次のことができます。
- 複数のクライアントを同じ会話に接続し、その間で送受信されるメッセージを管理します。
- 各クライアントからの音声の文字起こしを簡単に行い、その文字起こしを他のユーザーに送信します (翻訳も可能です)。
- クライアント間でテキスト メッセージを簡単に送信します (翻訳も可能です)。
多くのデバイスで動作する機能やソリューションを構築することができます。 各デバイスは、他のどのデバイスにでも個別にメッセージを送信することができます (音声の文字起こしまたはインスタント メッセージのどちらか)。
会議の文字起こしがマルチチャンネルのマイク配列を備えた 1 台のデバイスで動作するのに対して、マルチデバイスの会話は、それぞれ 1 つのマイクを備えた複数のデバイスのシナリオに適しています。
重要
マルチデバイスの会話では、クライアント間での音声ファイルの送信がサポートされていません。文字起こしと翻訳のみがサポートされています。
主要な機能
- リアルタイムの文字起こし: すべてのユーザーが会話のトランスクリプトを受信するので、テキストをリアルタイムでフォローしたり、後で読むために保存したりできます。
- リアルタイムの翻訳: テキスト翻訳のサポート言語が 70 を超えており、ユーザーは会話を希望の言語に翻訳することができます。
- 読みやすいトランスクリプト: 句読点や文の区切り記号により、文字起こしや翻訳が理解しやすくなります。
- 音声またはテキストの入力: 各ユーザーは、参加者が選択した言語で有効になっている言語サポート機能に応じてお使いのデバイスに音声入力または入力できます。 言語のサポートに関する記事をご覧ください。
- メッセージ リレー: マルチデバイスの会話サービスは、1 つのクライアントによって送信されたメッセージを、他のすべてのクライアントにそれぞれで選択されている言語で配信します。
- メッセージ ID: ユーザーが会話で受信するすべてのメッセージに、そのメッセージを送信したユーザーのニックネームでタグが付けられます。
ユース ケース
軽量な会話
会話の作成と参加は簡単です。 1 人のユーザーが "ホスト" になり、会話を作成すると、ランダムな 5 文字の会話コードと QR コードが生成されます。 他のすべてのユーザーは、会話コードを入力するか、QR コードをスキャンすることで、会話に参加できます。
ユーザーは会話コードを使用して参加するので、連絡先情報を共有する必要がなく、会話を即座に、簡単に作成できます。
インクルーシブな会議
リアルタイムの文字起こしと翻訳により、異なる言語を話す人や聴覚に障碍のある方でも、会話に参加することができます。 各ユーザーは、希望の言語を話したり、インスタント メッセージを送信したりして、会話に積極的に参加することもできます。
プレゼンテーション
画面上と対象ユーザーの所有デバイスの両方に、プレゼンテーションと講義のキャプションを提供することができます。 対象ユーザーが会話コードを使用して参加すると、自分のデバイスに希望の言語でトランスクリプトを表示できます。
しくみ
すべてのクライアントが会話の作成または参加に Speech SDK を使用します。 Speech SDK は、会話の有効期間を管理するマルチデバイスの会話サービスと交信します。 会話には、参加者の一覧、各クライアントで選択されている言語、送信されたメッセージが含まれます。
各クライアントは、音声またはインスタント メッセージを送信できます。 サービスは音声認識を使用して音声をテキストに変換し、インスタント メッセージとしてそのまま送信します。 クライアントで別の言語が選ばれている場合、サービスはすべてのメッセージを各クライアントの指定言語に翻訳します。
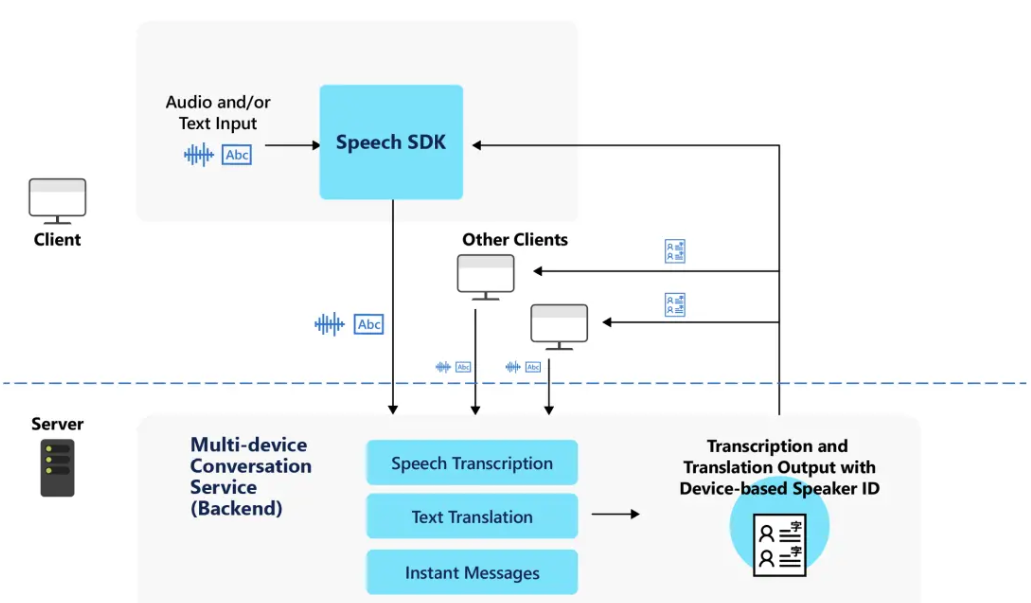
会話、ホスト、参加者の概要
会話は、1 人のユーザーによって開始され、他のユーザーが参加しているセッションです。 すべてのクライアントは、5 文字の会話コードを使用して、会話に接続します。
それぞれの会話では、次のものを含むメタデータが作成されます。
- 会話が開始および終了したときのタイムスタンプ
- 会話内のすべての参加者の一覧。各ユーザーが選択したニックネームと、音声またはテキスト入力に使用する第 1 言語が含まれます。
会話には、2 種類のユーザーがいます。ホストと参加者です。
ホスト は、会話を開始したユーザーであり、その会話の管理者の役割を果たします。
- それぞれの会話のホストは 1 人のみです
- ホストは、会話の間、その会話に接続されている必要があります。 ホストが会話を終了すると、他のすべての参加者に対して会話が終了します。
- ホストは、会話を管理するために次のような管理も行います。
- 会話をロックする - それ以上参加者が参加できないようにします
- すべての参加者をミュートにする - 他の参加者が音声の文字起こしかインスタント メッセージかを問わず、メッセージを会話に送信できないようにします
- 個々の参加者をミュートにする
- すべての参加者のミュートを解除する
- 個々の参加者のミュートを解除する
参加者は、会話に参加するユーザーです。
- 参加者は、他の参加者の会話を終了することなく、いつでも同じ会話を終了したり再度参加したりできます。
- 参加者は会話をロックしたり、他のユーザーのミュートおよびミュート解除を行うことはできません
Note
それぞれの会話には、最大 100 人の参加者を含めることができ、そのうち 10 人と同時に話すことができます。
言語のサポート
各ユーザーは、会話に参加するときに第 1 言語を選ぶ必要があります。 選んだ言語を使って、ユーザーは、話したり、インスタント メッセージを送信したり、他のユーザーのメッセージを表示したりします。
言語には、音声変換とテキストのみの 2 種類があります。
ユーザーが第 1 言語として音声テキスト変換言語を選ぶと、会話で音声入力とテキスト入力の両方を使用できるようになります。
ユーザーがテキスト専用言語を選ぶと、会話ではテキスト入力を使用し、インスタント メッセージを送信することだけができます。 テキストのみの言語は、テキスト翻訳ではサポートされているが、音声変換ではサポートされていない言語です。 使用可能な言語は、言語のサポートに関するページで確認できます。
各参加者は、第 1 言語とは別に、会話を翻訳するための言語をさらに指定することもできます。
次の表は、選んだ第 1 言語に基づいて、ユーザーがマルチデバイスの会話でできることをまとめたものです。
| ユーザーが会話で実行できる操作 | 音声テキスト変換 | テキストのみ |
|---|---|---|
| 音声入力の使用 | ✔️ | ❌ |
| インスタント メッセージの送信 | ✔️ | ✔️ |
| 会話の翻訳 | ✔️ | ✔️ |
注意
使用可能な音声変換とテキスト翻訳の言語のリストは、サポートされる言語に関する記事を参照してください。