マルチテナント システムでは、テナント間でリソースが共有されます。 テナントは同じ共有リソースを使用するため、1 つのテナントのアクティビティが他のテナントのシステムの使用に悪影響を与えるおそれがあります。
問題の説明
複数の顧客またはテナントによって共有されるサービスを構築する場合は、"マルチテナント" になるようにビルドすることができます。 マルチテナント システムの利点は、リソースをプールしてテナント間で共有できることです。 これにより多くの場合、コストが削減され、効率が向上します。 ただし、システムで使用可能なリソースのうちの過度な量が 1 つのテナントで使用されると、システム全体のパフォーマンスが低下する可能性があります。 別のテナントのアクティビティによって 1 つのテナントのパフォーマンスが低下する場合に、"うるさい隣人" の問題が発生します。
2 つのテナントがあるマルチテナント システムの例を考えてみましょう。 テナント A の使用パターンとテナント B の使用パターンは一致しています。これは、ピーク時のリソースの合計使用量が、システムの容量を上回ることを意味します。
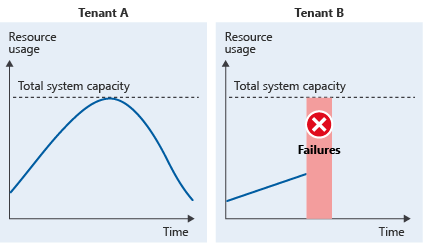
多くの場合は、最初に到着したテナントの要求が優先されます。 そして、もう一方のテナントでうるさい隣人の問題が発生します。 あるいは、両方のテナントでパフォーマンスが低下する場合があります。
また、うるさい隣人の問題は、個々のテナントが比較的少量のシステム容量を消費していても、多くのテナントの全体的なリソース使用量によって全体的な使用量がピークになる場合にも発生します。
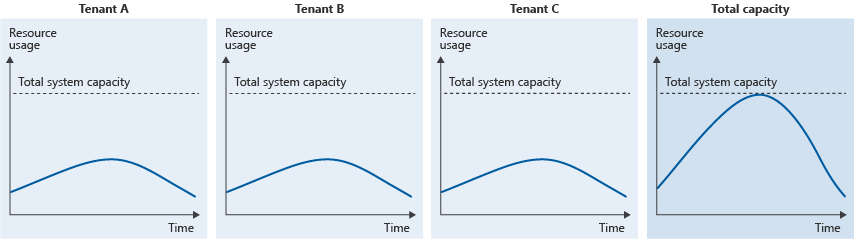
これは、複数のテナントですべての使用パターンが類似している場合や、システムの全体的な負荷に対して十分な容量をプロビジョニングしていない場合に発生する可能性があります。
問題の解決方法
うるさい隣人の問題はマルチテナントシステムの本質的なリスクであり、うるさい隣人の影響を受ける可能性を完全に排除することはできません。 ただし、クライアントとサービス プロバイダーの両方で、うるさい隣人の問題が発生する可能性を低減したり、発生したときの影響を軽減したりするために実行できる手順がいくつかあります。
クライアントが実行できる操作
- サービスへの不要な要求を減らすために、アプリケーションが確実にサービス調整を処理するようにします。 アプリケーションが一時的なエラー応答を受信した要求を再試行するための適切なプラクティスに従っていることを確認します。
- 予約容量を購入します (使用可能な場合)。 たとえば、Azure Cosmos DB を使う場合は予約済みのスループットを購入し、ExpressRoute を使う場合は、パフォーマンスの影響を受けやすい環境に対して個別の回線をプロビジョニングします。
- サービスのシングルテナント インスタンスに移行するか、より強力な分離が保証されたサービス レベルに移行します。 たとえば、Service Bus を使用する場合は、Premium レベルに移行します。Azure Cache for Redis を使用する場合は、Standard または Premium レベルのキャッシュをプロビジョニングします。
サービス プロバイダーが実行できる操作
- システムのリソース使用量を監視してください。 全体的なリソースの使用状況と、各テナントが使用するリソースの両方を監視してください。 リソース使用量の急増を検出するアラートを構成します。可能な場合は、スケールアップまたはスケールアウトすることで、既知の問題を自動的に軽減するように自動化を構成します。
- リソース ガバナンスを適用してください。 単一のテナントがシステムに過剰な負荷をかけ、他のテナントが使用できる容量を減らさないようにするポリシーを適用することを検討してください。 このステップは、調整パターンまたはレート制限パターンを通じたクォータ適用の形式になる場合があります。
- より多くのインフラストラクチャをプロビジョニングしてください。 このプロセスには、ソリューション コンポーネントの一部をアップグレードすることによってスケールアップが必要になる場合があります。また、シャーディング パターンに従う場合は追加のシャードを、デプロイ スタンプ パターンに従う場合はスタンプをプロビジョニングすることによってスケールアウトが必要になる場合もあります。
- テナントで事前にプロビジョニングされた容量または予約容量を購入できるようにしてください。 この容量により、ソリューションがワークロードを適切に処理できるようになり、テナントの確実性が向上します。
- テナントのリソース使用量をスムーズにしてください。 たとえば、次のようなアプローチがあります。
- ソリューションの複数のインスタンスをホスティングする場合は、インスタンスまたはスタンプ間でテナントを再分散することを検討します。 たとえば、予測可能な類似する使用パターンを持つテナントを複数のスタンプにわたって配置することで、使用量のピークを平坦化することを検討してください。
- 時間に依存しないバックグラウンド プロセスやリソースを集中的に使用するワークロードがないかどうかを検討します。 これらのワークロードをオフピーク時間に非同期的に実行して、ピーク時のリソース容量を時間的制約のあるワークロード用に確保することができます。
- ダウンストリーム サービスで、うるさい隣人の問題を軽減するためのコントロールを提供するかどうかを確認します。 たとえば、Kubernetes を使用する場合は、ポッドの制限を使用することを検討します。Service Fabric を使用する場合は、組み込みのガバナンス機能を使用することを検討してください。
- テナントが行うことができる操作を制限してください。 たとえば、返すことができる最大レコード数やクエリの時間制限を指定するなどして、非常に大きなデータベース クエリを実行する操作をテナントが実行できないようにします。 このアクションにより、テナントが他のテナントに悪影響を与える可能性のあるアクションを実行するリスクが軽減されます。
- サービスの品質 (QoS) システムを提供してください。 QoS を適用する場合は、一部のプロセスまたはワークロードの優先順位をその他よりも高くします。 QoS を設計とアーキテクチャに組み込むことで、リソースに負荷がかかっているときに優先度の高い操作が優先されるようにすることができます。
考慮事項
ほとんどの場合、個々のテナントは、うるさい隣人の問題を引き起こすことを意図していません。 個々のテナントは、そのワークロードが他のテナントに対してうるさい隣人の問題を引き起こしていることを認識さえしていない場合があります。 ただし、一部のテナントが共有コンポーネントの脆弱性を悪用して、個別に、または分散型サービス拒否 (DDoS) 攻撃を実行することで、サービスを攻撃するおそれもあります。
原因にかかわらず、これらの問題をリソース ガバナンスの問題として扱い、使用量クォータ、調整、ガバナンス コントロールを適用して問題を軽減することが重要です。
注意
適用する調整、またはサービスの使用量クォータについて、必ずクライアントに通知するようにしてください。 失敗した要求が適切に処理されること、また適用される制限やクォータによって驚かれないことが重要です。
問題の検出方法
クライアントの観点から見ると、うるさい隣人の問題は、通常、サーバー要求の失敗、または完了するまでに長い時間がかかる要求として現れます。 特に、同じ要求がある時には成功し、ランダムに失敗するように見える場合は、うるさい隣人の問題が発生していることがあります。 クライアント アプリケーションは、サービスに対する要求の成功率とパフォーマンスを追跡するためにテレメトリを記録する必要があります。また、アプリケーションでは、比較のためにベースライン パフォーマンス メトリックも記録する必要があります。
サービスの観点から見ると、うるさい隣人の問題はいくつかの形で現れる可能性があります。
- リソース使用量の急増。 重要なのは、通常のベースライン リソース使用量を明確に把握し、リソース使用量の急増を検出するために監視とアラートを構成することです。 サービスのパフォーマンスや可用性に影響する可能性のあるすべてのリソースを考慮してください。 これらのリソースには、サーバーの CPU とメモリの使用量、ディスク IO、データベースの使用状況、ネットワーク トラフィックなどのメトリック、および管理サービスによって公開されるメトリック (要求の数や、Azure Cosmos DB 要求ユニットなどの合成および抽象のパフォーマンス メトリックなど) が含まれます。
- テナントの操作を実行するときのエラー。 特に、テナントがシステムのリソースの大部分を使用していない場合に発生するエラーを探します。 このようなパターンは、そのテナントが、うるさい隣人の問題の被害にあっていることを示している場合があります。 テナントごとのリソース消費量を追跡することを検討してください。 たとえば、Azure Cosmos DB を使用している場合は、各テナントの要求ユニットの使用量を集計できるように、各要求に使用される要求ユニットをログに記録し、テナントの識別子をディメンションとしてテレメトリに追加することを検討してください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- John Downs | FastTrack for Azure のプリンシパル カスタマー エンジニア
その他の共同作成者:
- Chad Kittel | プリンシパル ソフトウェア エンジニア
- Paolo Salvator | FastTrack for Azure のプリンシパル カスタマー エンジニア
- Daniel Scott-Raynsford |パートナー テクノロジ ストラテジスト
- Arsen Vladimirskiy | FastTrack for Azure のプリンシパル カスタマー エンジニア
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。