人工知能 (AI) と機械学習 (ML) を中心に構築されるマルチテナント ソリューションがますます増え続けています。 マルチテナント AI/ML ソリューションは、任意の数のテナントに同様の ML ベースの機能を提供するソリューションです。 テナントは通常、他のテナントのデータを表示または共有できませんが、場合によっては、テナントが他のテナントと同じモデルを使用することがあります。
マルチテナント AI/ML アーキテクチャでは、データとモデルの要件と、モデルのトレーニングとモデルからの推論の実行に必要なコンピューティング リソースを考慮する必要があります。 マルチテナント AI/ML モデルをどのようにデプロイ、分散、調整するかを検討し、ソリューションの正確さ、信頼性、スケーラビリティを確保することが重要です。
大規模な言語モデルと小規模言語モデルの両方を利用した生成 AI テクノロジが人気を集めるにつれて、機械学習の運用 (MLOps) と GenAIOps (LLMOps とも呼ばれる) の導入を通じて、運用環境でこれらのモデルを管理するための効果的な運用プラクティスと戦略を確立することが重要です。
主な考慮事項と要件
AI と ML を使用する場合は、 トレーニング と 推論の要件を個別に考慮することが重要です。 トレーニングの目的は、一連のデータに基づいた予測モデルを構築することです。 モデルを使用してアプリケーションで何かを予測するときに、推論を実行します。 これらのプロセスにはそれぞれ異なる要件があります。 マルチテナント ソリューションでは、 テナント モデル が各プロセスにどのように影響するかを検討する必要があります。 これらの要件を考慮することによって、ソリューションが正確な結果を提供し、負荷が高い状況で良好に動作し、コスト効率に優れ、将来の成長に合わせてスケーリングできるようにすることができます。
テナントの分離
テナントが他のテナントのデータまたはモデルへの未承認または不要なアクセスを取得していないことを確認します。 トレーニングに使用した生データと同様の感度でモデルを処理します。 テナントが、そのデータがモデルのトレーニングにどのように使用されるか、および他のテナントのデータでトレーニングされたモデルがワークロードの推論にどのように使用されるかを理解していることを確認します。
マルチテナント ソリューションで ML モデルを操作するには、テナント固有のモデル、共有モデル、およびチューニングされた共有モデルという 3 つの一般的な方法があります。
テナント固有のモデル
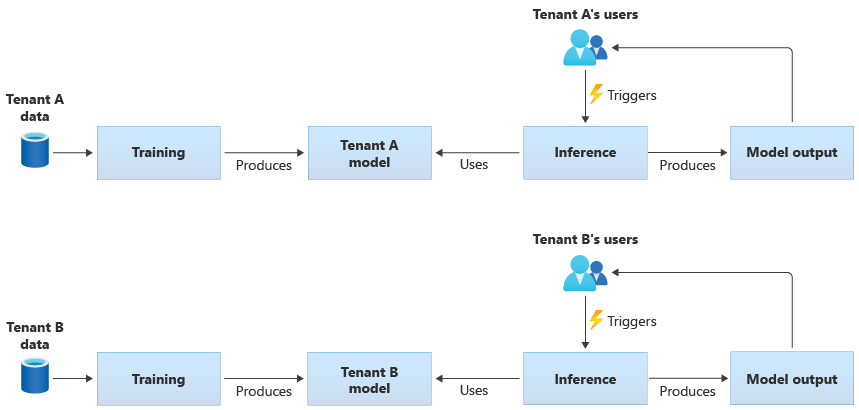
テナント固有のモデルは、1 つのテナントのデータのみでトレーニングされ、その 1 つのテナントに適用されます。 テナント固有のモデルは、テナントのデータの機密性が高い場合、または 1 つのテナントによって提供されるデータから学習する余地がほとんどなく、そのモデルを別のテナントに適用する場合に適しています。 次の図は、2 つのテナントのテナント固有モデルを使用してソリューションを構築する方法を示しています。
共有モデル
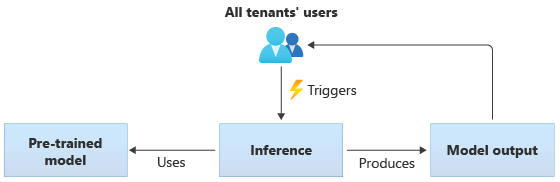
共有モデルを使用するソリューションでは、すべてのテナントが同じ共有モデルに基づいて推論を実行します。 共有モデルは、コミュニティ ソースから取得または手に入れた事前トレーニング済みのモデルである場合があります。 次の図は、すべてのテナントで 1 つの事前トレーニング済みモデルを使用して推論を行う方法を示しています。
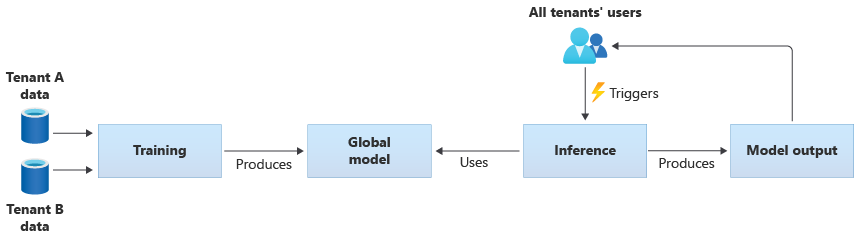
また、すべてのテナントが提供するデータからトレーニングすることで、独自の共有モデルを作成することもできます。 次の図は、すべてのテナントのデータでトレーニングされた単一の共有モデルを示しています。
重要
テナントのデータから共有モデルをトレーニングする場合は、テナントがそのデータの使用について理解し、それに同意していることを確認します。 テナントのデータから識別情報が削除されていることを確認します。
テナントが、別のテナントに適用されるモデルをトレーニングするために使用されているデータを拒否する場合は、どうするかを検討します。 たとえば、トレーニング データ セットから特定のテナントのデータを除外することはできますか。
チューニングされた共有モデル
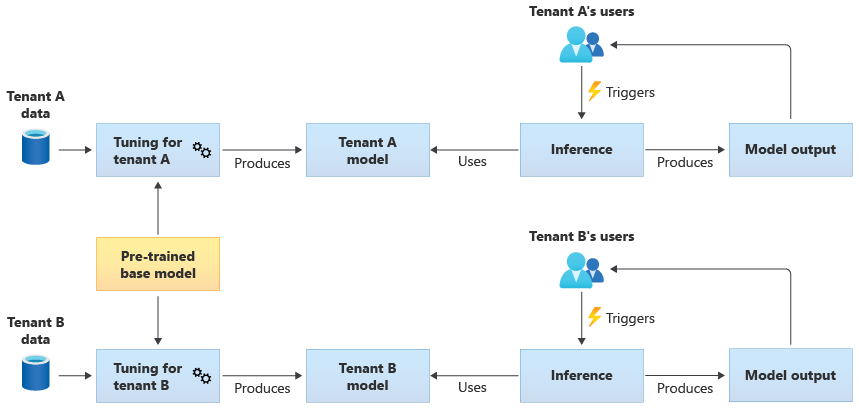
また、事前トレーニング済みの基本モデルを取得し、さらにモデルのチューニングを実行して、独自のデータに基づいて各テナントに適用できるようにすることもできます。 この方法を示す図を次に示します。
スケーラビリティ
ソリューションの拡張が AI および ML コンポーネントの使用にどのように影響するかを検討してください。 拡張とは、テナントの数、各テナントに格納されるデータの量、ユーザー数、ソリューションに対する要求の量の増加を指します。
訓練: モデルのトレーニングに必要なリソースに影響を与える要因はいくつかあります。 これらの要因には、トレーニングが必要なモデルの数、モデルのトレーニングに使用されるデータの量、モデルのトレーニングまたは再トレーニングの頻度などが含まれます。 テナント固有のモデルを作成すると、テナントの数が増えるにつれて、必要なコンピューティング リソースとストレージの量も増加する可能性があります。 共有モデルを作成し、すべてのテナントのデータに基づいてトレーニングを行うと、トレーニング用のリソースがテナントの数の増加と同じ速度でスケーリングされる可能性が低くなります。 ただし、トレーニング データ全体の量が増加すると、共有モデルとテナント固有のモデルの両方をトレーニングするために使用されるリソースに影響します。
推論: 推論に必要なリソースは、通常、推論のためにモデルにアクセスする要求の数に比例します。 テナントの数が増えるにつれて、要求の数も増加する可能性があります。
適切にスケーリングできる Azure サービスを使用することをお勧めします。 AI/ML ワークロードはコンテナーを使用する傾向があるため、Azure Kubernetes Service (AKS) と Azure Container Instances (ACI) は、AI/ML ワークロードの一般的な選択肢となる傾向があります。 AKS は、通常、高スケールを有効にし、必要に応じてコンピューティング リソースを動的にスケーリングする場合に適しています。 小さなワークロードの場合、ACI は、AKS ほど簡単にスケーリングできませんが、シンプルなコンピューティング プラットフォームとして構成できます。
パフォーマンス
トレーニングと推論の両方について、ソリューションの AI/ML コンポーネントのパフォーマンス要件を考慮してください。 必要に応じて測定および改善できるように、各プロセスの待機時間とパフォーマンスの要件を明確にすることが重要です。
訓練: トレーニングは多くの場合、バッチ プロセスとして実行されます。つまり、ワークロードの他の部分ほどパフォーマンスを重視しない可能性があります。 ただし、スケーリング時を含め、モデルのトレーニングを効率的に実行するために、十分なリソースをプロビジョニングする必要があります。
推論: 推論は待機時間に依存するプロセスであり、多くの場合、高速またはリアルタイムの応答が必要です。 リアルタイムで推論を実行する必要がない場合でも、ソリューションのパフォーマンスを監視し、適切なサービスを使用してワークロードを最適化するようにしてください。
AI と ML のワークロードには、Azure のハイパフォーマンス コンピューティング機能を使用することを検討してください。 Azure には、さまざまな種類の仮想マシンとその他のハードウェア インスタンスが用意されています。 CPU、 GPU、 FPGA、またはその他のハードウェアアクセラレータ環境を使用することでソリューションがメリットを得られるかどうかを検討します。 Azure では、NVIDIA Triton 推論サーバーを含む NVIDIA GPU によるリアルタイムの推論も提供します。 優先順位の低いコンピューティング要件については、 AKS スポット ノード プールの使用を検討してください。 マルチテナント ソリューションでのコンピューティング サービスの最適化の詳細については、マルチテナント ソリューション でのコンピューティングのアーキテクチャ アプローチに関するページを参照してください。
通常、モデルのトレーニングでは、データストアと多くのやり取りが必要になるため、データ戦略や、データ層で提供されるパフォーマンスを考慮することも重要です。 マルチテナントとデータ サービスの詳細については、 マルチテナント ソリューションでのストレージとデータのアーキテクチャ アプローチに関する記事を参照してください。
ソリューションのパフォーマンスをプロファイリングすることを検討してください。 たとえば、 Azure Machine Learning には、ソリューションの 開発とインストルメント化に使用できるプロファイリング機能が用意されています。
実装の複雑さ
AI と ML を使用するソリューションを構築する場合は、事前に構築されたコンポーネントを使用するか、カスタム コンポーネントを作成するかを選択できます。 2 つの重要な決定を行う必要があります。 1 つ目は、AI と ML に使用する プラットフォームまたはサービス です。 2 つ目は、事前トレーニング済みのモデルを使用するか、独自のカスタム モデルを作成するかということです。
プラットフォーム: AI と ML のワークロードに使用できる Azure サービスは多数あります。 たとえば、Foundry Models の Azure AI Services と Azure OpenAI には、事前構築済みモデルに対して推論を実行する API が用意されており、基になるリソースは Microsoft によって管理されます。 Azure AI Services を使用すると、新しいソリューションをすばやくデプロイできますが、トレーニングと推論の実行方法をあまり制御できないため、すべての種類のワークロードに適しているとは限りません。 これに対し、Azure Machine Learning は、独自の ML モデルを作成、トレーニング、および使用できるプラットフォームです。 Azure Machine Learning を使用すると制御が可能になり柔軟性が増しますが、設計と実装の複雑さが増します。 Microsoft の 機械学習の製品とテクノロジ を確認して、アプローチを選択する際に情報に基づいた意思決定を行います。
モデル: Azure AI Services などのサービスによって提供される完全なモデルを使用しない場合でも、事前トレーニング済みのモデルを使用して開発を高速化できます。 事前トレーニング済みモデルがニーズに正確に合わない場合は、 転移学習 または 微調整と呼ばれる手法を適用して、事前トレーニング済みモデルを拡張することを検討してください。 転移学習を使用すると、既存のモデルを拡張し、別のドメインに適用できます。 たとえば、マルチテナント ミュージック レコメンデーション サービスを構築している場合は、音楽に関するレコメンデーションの事前トレーニング済みモデルを構築し、転移学習を使用して特定のユーザーの音楽の好みに合わせてモデルをトレーニングすることを検討してください。
Azure AI Services や Azure OpenAI などの事前構築済みの ML プラットフォーム、または事前トレーニング済みのモデルを使用することで、初期の研究開発コストを大幅に削減できます。 事前に構築されたプラットフォームを使用することによって、数か月にもわたる調査期間が削減され、モデルのトレーニング、設計、および最適化を行うために、高度な技能を有するデータ サイエンティストを採用する必要がなくなります。
コスト最適化
一般的に、AI と ML のワークロードでは、モデルのトレーニングと推論に必要なコンピューティング リソースのコストが最も大きな割合を占めます。 マルチテナント ソリューションのコンピューティングのアーキテクチャ アプローチを確認して、要件に合わせてコンピューティング ワークロードのコストを最適化する方法を理解します。
AI と ML のコストを計画するときは、次の要件を考慮してください。
- トレーニング用のコンピューティング SKU を決定します。 たとえば、 Azure Machine Learning でこれを行う方法に関するガイダンスを参照してください。
- 推論用のコンピューティング SKU を決定します。 推論のコスト見積もりの例 については、Azure Machine Learning のガイダンスを参照してください。
- 使用率を観察します。 コンピューティング リソースの使用率を観察することによって、さまざまな SKU をデプロイして容量を減らしたり増やしたりするか、要件の変化に応じてコンピューティング リソースをスケーリングする必要があるかどうかを判断できます。 Azure Machine Learning Monitor を参照してください。
- コンピューティング クラスタリング環境を最適化します。 コンピューティング クラスターを使用する場合は、クラスターの使用率を監視するか、コンピューティング ノードをスケールダウンするように 自動スケールを 構成します。
- コンピューティング リソースを共有します。 コンピューティング リソースを複数のテナント間で共有することで、コンピューティング リソースのコストを最適化できるかどうかを検討します。
- 予算を検討してください。 予算が固定されているかどうかを理解し、それに応じて消費を監視します。 予算を 設定 して、過剰な支出を防ぎ、テナントの優先順位に基づいてクォータを割り当てることができます。
考慮すべきアプローチとパターン
Azure には、AI と ML のワークロードを有効にする一連のサービスが用意されています。 マルチテナント ソリューションで使用される一般的なアーキテクチャ アプローチには、事前構築済みの AI/ML ソリューションの使用、Azure Machine Learning を使用したカスタム AI/ML アーキテクチャの構築、Azure 分析プラットフォームの 1 つの使用などがあります。
事前構築済みの AI/ML サービスを使用する
可能であれば、事前構築済みの AI/ML サービスを使用してみることをお勧めします。 たとえば、組織が AI/ML に注目し始めていて、有用なサービスと迅速に統合したいと考えている場合があります。 または、カスタム ML モデルのトレーニングと開発を必要としない基本的な要件がある場合もあります。 事前構築済み ML サービスを使用すると、独自のモデルを構築してトレーニングすることなく、推論を使用できます。
Azure には、言語理解、音声認識、知識、ドキュメントとフォーム認識、コンピューター ビジョンなど、さまざまなドメインにわたって AI と ML テクノロジを提供するサービスがいくつか用意されています。 Azure の事前構築済みの AI/ML サービスには、 Azure AI サービス、 Foundry モデルの Azure OpenAI、 Azure AI Search、 Azure AI ドキュメント インテリジェンスが含まれます。 各サービスには、統合のためのシンプルなインターフェイスと、事前トレーニング済みモデルとテスト済みモデルのコレクションが用意されています。 管理サービスとして、サービス レベルアグリーメントを提供し、構成や継続的な管理をほとんど必要としません。 これらのサービスを使用するために独自のモデルを開発またはテストする必要はありません。
マネージド ML サービスの多くは、モデルのトレーニングやデータを必要としないので、通常、テナント データの分離に関する問題はありません。 ただし、マルチテナント ソリューションで AI Search を使用する場合は、 マルチテナント SaaS アプリケーションと Azure AI Search の設計パターンを確認してください。
ソリューション内のコンポーネントのスケール要件を検討します。 たとえば、1 秒あたりの要求の最大数は、Azure AI Services 内の API の多くでサポートされています。 テナント間で共有する 1 つの AI サービス リソースをデプロイする場合、テナントの数が増えるにつれて、 複数のリソースにスケーリングすることが必要になる場合があります。
注
一部のマネージド サービスでは、 Custom Vision サービス、 Face API、 ドキュメント インテリジェンス カスタム モデル、 カスタマイズと微調整をサポートするいくつかの OpenAI モデルなど、独自のデータを使用してトレーニングできます。 これらのサービスを使用する場合は、テナントのデータの 分離要件 を考慮することが重要です。
カスタム AI/ML アーキテクチャ
ソリューションにカスタム モデルが必要な場合、またはマネージド ML サービスの対象ではないドメインで作業している場合は、独自の AI/ML アーキテクチャの構築を検討してください。 Azure Machine Learning には、ML モデルのトレーニングとデプロイを調整するための一連の機能が用意されています。 Azure Machine Learning では、 PyTorch、 TensorFlow、 Scikit、 Keras など、多くのオープンソース機械学習ライブラリがサポートされています。 モデルのパフォーマンス メトリックを継続的に監視し、データ ドリフトを検出し、再トレーニングをトリガーしてモデルのパフォーマンスを向上させることができます。 ML モデルのライフサイクル全体を通じて、Azure Machine Learning は、すべての ML 成果物の追跡と連携機能を組み込んだ監査機能とガバナンスを有効にします。
マルチテナント ソリューションで作業する場合は、トレーニングと推論の両方の段階で テナントの分離要件 を考慮することが重要です。 また、モデルのトレーニングとデプロイのプロセスを決定する必要があります。 Azure Machine Learning にはモデルをトレーニングし、推論に使用する環境にそれをデプロイするパイプラインが用意されています。 マルチテナント コンテキストでは、モデルを共有コンピューティング リソースにデプロイするべきか、各テナントに専用のリソースを持つかどうかを検討します。 分離モデルとテナントデプロイ プロセスに基づいて、モデルデプロイ パイプラインを設計します。
オープンソース モデルを使用する場合は、転送学習またはチューニングを使用して、これらのモデルを再トレーニングすることが必要になる場合があります。 各テナントの異なるモデルとトレーニング データ、およびモデルのバージョンを管理する方法を検討します。
次の図は、 Azure Machine Learning を使用するアーキテクチャの例を示しています。 この例では、 テナント固有のモデル分離 アプローチを使用します。
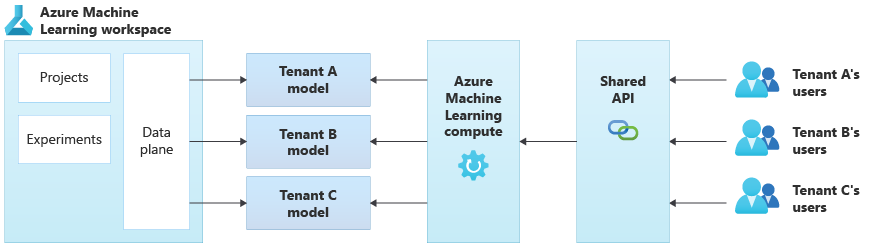
統合された AI/ML ソリューション
Azure には、さまざまな目的で使用できる強力な分析プラットフォームがいくつか提供されています。 これらのプラットフォームには、 Azure Synapse Analytics、 Databricks、 Apache Spark が含まれます。
ML 機能を非常に多くのテナントにスケーリングする必要がある場合、および大規模なコンピューティングとオーケストレーションが必要な場合は、これらのプラットフォームを AI/ML に対して使用することを検討できます。 また、データ分析や Microsoft Power BI によるレポート作成との統合など、ソリューションの他の部分のための幅広い分析プラットフォームが必要な場合には、これらのプラットフォームを AI/ML に対して使用することを検討することもできます。 分析と AI/ML のすべてのニーズを対象とする単一のプラットフォームをデプロイできます。 マルチテナント ソリューションにデータ プラットフォームを実装する場合は、マルチテナント ソリューション でのストレージとデータのアーキテクチャ アプローチを確認します。
ML 運用モデル
生成型 AI プラクティスを含む AI と機械学習を採用する場合は、それらを管理する際に組織の機能を継続的に改善して評価することが推奨されます。 MLOps と GenAIOps の導入により、組織内の AI と ML プラクティスの機能を継続的に拡張するためのフレームワークが客観的に提供されます。 詳細なガイダンスについては、 MLOps 成熟度モデル と LLMOps 成熟度モデル のドキュメントを確認してください。
回避すべきアンチパターン
- 分離要件の検討に失敗しました。 トレーニングと推論の両方で 、テナントのデータとモデルを分離する方法を慎重に検討することが重要です。 そうしないと、法的または契約上の要件に違反する可能性があります。 また、データが大幅に異なる場合は、複数のテナントのデータ間でトレーニングするモデルの正確性が低下する可能性があります。
- うるさい隣人。 トレーニングプロセスまたは推論プロセスが ノイズネイバーの問題の影響を受ける可能性があるかどうかを検討します。 たとえば、複数の大規模なテナントと 1 つの小規模なテナントがある場合は、大規模なテナントのモデル トレーニングによりすべてのコンピューティング リソースが誤って消費され、小規模なテナントが使用するものがなくなることがないようにします。 他のテナントのアクティビティに影響されるテナントのコンピューティング ワークロードのリスクを軽減するために、リソースのガバナンスと監視を使用する必要があります。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- ケビン・アシュリー |Azure 用 FastTrack のシニア カスタマー エンジニア
その他の共同作成者:
- ポール・ブルポ |プリンシパル カスタマー エンジニア、FastTrack for Azure
- ジョン・ダウンズ |プリンシパル ソフトウェア エンジニア
- ダニエル・スコット=レインズフォード |パートナー テクノロジストラテジスト
- アルセン・ウラジミルスキー |プリンシパル カスタマー エンジニア、FastTrack for Azure
- ヴィック・ペルダナ |ISV パートナー ソリューション アーキテクト
次のステップ
- マルチテナント ソリューション アプローチでのコンピューティングのアーキテクチャ アプローチを確認します。
- 複数のテナントをサポートする Azure Machine Learning パイプラインの設計の詳細については、「 マルチテナント方式の ML パイプラインのソリューション」を参照してください。