人工知能により、今日の小売業が変革される可能性があります。 小売業者は AI に支えられたカスタマー エクスペリエンス アーキテクチャを開発するようになると考えてよいでしょう。 AI で強化されたプラットフォームでは、ハイパー パーソナル化による収益の増加が期待されます。 デジタル コマースは、顧客の期待、嗜好、行動を高め続けています。 リアルタイム エンゲージメント、関連性のあるレコメンデーション、ハイパー パーソナル化などのニーズは、ボタンのクリックによるスピードと利便性の向上を促しています。 自然音声や視覚などを通じてアプリケーションのインテリジェンスを実現します。 このインテリジェンスにより、小売業において、顧客の従来の買物の方法を覆し、価値を増大させる改善が可能になります。
このドキュメントでは、 画像検索 の AI の概念について説明し、その実装に関する重要な考慮事項を示します。 ワークフローの例を示し、各段階を関連する Azure テクノロジにマップします。 この概念は、顧客がモバイル デバイスで撮影した画像やインターネット上にある画像を利用できることに基づいています。 エクスペリエンスの意図に応じて、関連する項目や類似する項目の検索を実行します。 そのため、画像検索では、テキスト入力ではなく、複数のメタデータ ポイントを含む画像を使用することで速度が向上し、適切なすべての項目をすばやく見つけ出すことができます。
画像検索エンジン
画像検索エンジンは、画像を入力として使用して情報を取得しますが、それだけではなく、多くの場合、出力としても使用します。
画像検索エンジンは小売業界で普及が進んでいますが、これには次のような十分な理由があります。
- 2017 年に発行された Emarketer のレポートによると、インターネット ユーザーの約 75% が、購入前に製品の写真やビデオを検索しています。
- Slyce (画像検索会社) の 2015 年のレポートによると、コンシューマーの 74% が、テキスト検索は非効率的であると思っています。
そのため、 Markets & Marketsの調査によると、画像認識市場は 2019 年までに 250 億ドル以上の規模になると予想されます。
このテクノロジは、主要 e コマース ブランドで既に採用されています。これらのブランドは、このテクノロジの開発にも大きく貢献しています。 最も有名と思われる早期導入者は次のとおりです。
- アプリで Image Search および "Find It on eBay" ツールを提供する eBay (現時点ではモバイル エクスペリエンスのみ)。
- 画像検索ツールのレンズ (Lens) を提供する Pinterest。
- Bing Visual Search を提供する Microsoft。
採用と適応
画像検索から利益を得るために膨大な処理能力は不要です。 画像カタログを所有する企業は、Azure サービスに組み込まれた Microsoft の AI の専門知識を活用できます。
Bing Visual Search API を使用すると、画像からコンテキスト情報を抽出し、たとえば、家財道具、ファッション、数種類の製品などを識別できます。
この API では、独自のカタログ、関連するショッピング ソースの製品、関連検索から、見た目が似ている画像を返すこともできます。 興味深いものの、自社がこれらのソースの 1 つでない場合、これはあまり役に立ちません。
Bing には次の機能も用意されています。
- 画像に含まれるオブジェクトや概念を探索できるタグ。
- 画像内の関心領域 (衣類、家具など) を示す境界ボックス。
その情報を取得して、検索空間を会社の製品カタログに限定し、関心領域の対象となるカテゴリのオブジェクトなどに限定することで、時間を大幅に短縮できます。
独自の画像検索の実装
画像検索を実装するときに考慮すべき重要な要素がいくつかあります。
- 画像の取り込みとフィルター処理
- 保存と取得の手法
- 特徴付け、エンコード、または "ハッシュ"
- 類似性測度または距離とランク付け
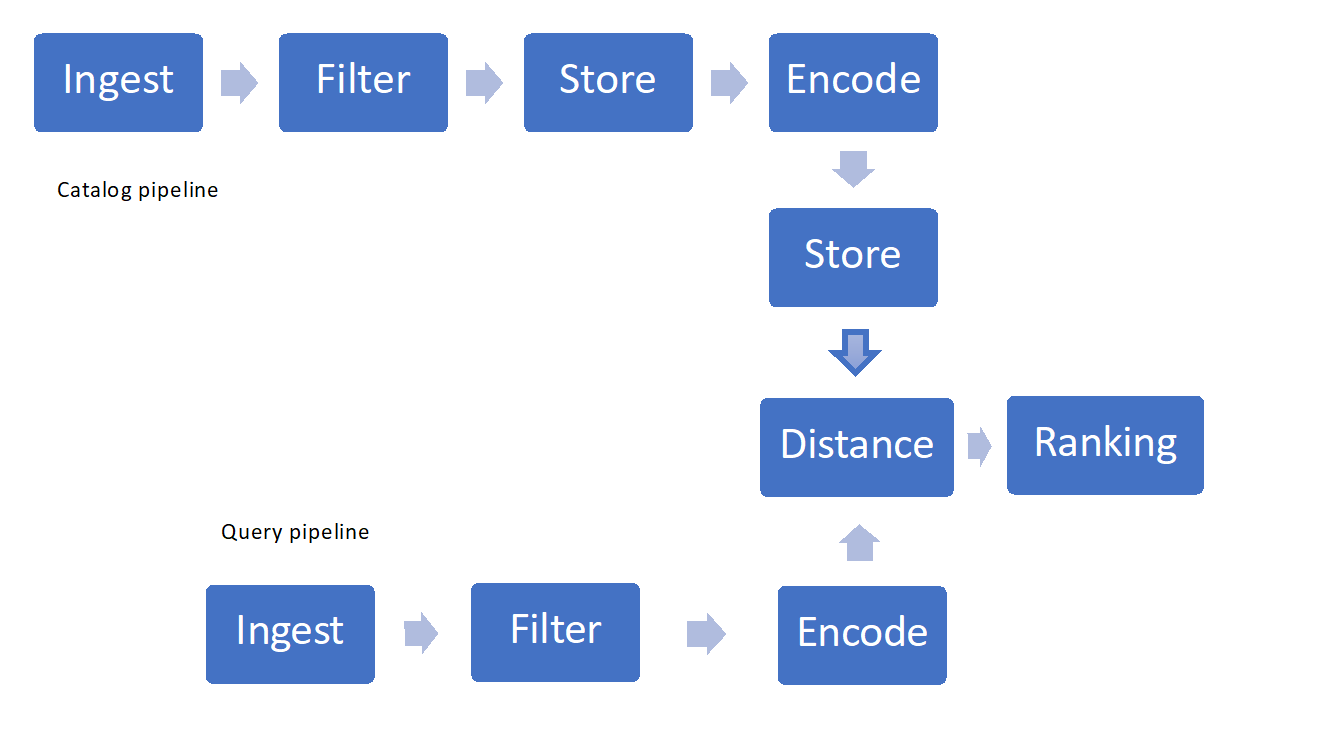
図 1: 画像検索パイプラインの例
画像の調達
画像カタログを所有していない場合、Fashion MNIST や Deep Fashion などの公開されているデータセットでアルゴリズムをトレーニングすることが必要な場合があります。 これらのデータセットには複数の製品カテゴリが含まれており、画像分類および検索アルゴリズムのベンチマークに一般に使用されます。

図 2: DeepFashion データセットの例
画像のフィルター処理
前述のようなベンチマーク データセットのほとんどは、既に前処理されています。
独自のベンチマークを構築する場合、少なくとも、画像をすべて同じサイズにすることが望まれます。ほとんどの場合、サイズはモデルのトレーニングの対象となった入力によって決まります。
多くの場合、画像の明度を正規化することも推奨されます。 検索の詳細レベルによっては、色も冗長情報になる可能性があるため、黒と白に減らすと処理時間が短縮されます。
最後に、画像データセットは、それが表すさまざまなクラス間でバランスを取る必要があります。
画像データベース
データ レイヤーは、アーキテクチャの特に繊細なコンポーネントです。 データ レイヤーには以下が含まれます。
- 画像
- 画像に関するメタデータ (サイズ、タグ、製品 SKU、説明)
- 機械学習モデルによって生成されたデータ (画像あたり 4096 要素の数値ベクトルなど)
さまざまなソースから画像を取得したり、最適なパフォーマンスを確保するために複数の機械学習モデルを使用したりすると、データの構造が変わります。 そのため、半構造化データを処理することができ、固定スキーマのないテクノロジまたは組み合わせを選択することが重要です。
また、最小数の有用なデータ ポイント (画像識別子またはキー、製品 SKU、説明、タグ フィールドなど) が必要になる場合もあります。
Azure Cosmos DB は、その上に構築されたアプリケーションに必要な柔軟性とさまざまなアクセス メカニズムを提供します (これは、カタログ検索に役立ちます)。 ただし、最適な価格/パフォーマンス比を実現するには注意が必要です。 Azure Cosmos DB ではドキュメントの添付ファイルを保存できますが、アカウントごとに上限があり、コストのかかる問題になる可能性があります。 実際の画像ファイルは BLOB に保存し、それらへのリンクをデータベースに挿入するのが一般的です。 Azure Cosmos DB の場合、これは、その画像に関連付けられたカタログ プロパティ (SKU、タグなど) を含むドキュメントと、(Azure Blob ストレージや OneDrive などにある) 画像ファイルの URL を含む添付ファイルを作成することを意味します。
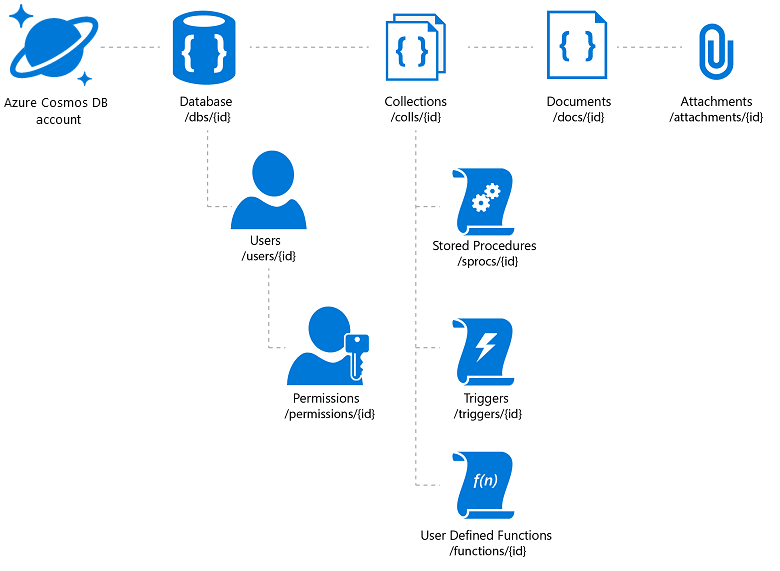
"図 3: Azure Cosmos DB 階層型リソース モデル"
Azure Cosmos DB のグローバル配布を利用する場合、ドキュメントと添付ファイルはレプリケートされますが、リンクされたファイルはレプリケートされません。 これらのファイルには、コンテンツ配信ネットワークを使用することを検討してください。
適用可能な他のテクノロジとして、Azure SQL Database (固定スキーマを許容できる場合) と BLOB の組み合わせ、または Azure Table と BLOB の組み合わせ (安価で高速の保存と取得を実現する場合) があります。
特徴抽出 & エンコード
エンコード プロセスでは、データベース内の画像から顕著な特徴を抽出し、数千の成分を持つことができる疎な "特徴" ベクトル (多数のゼロを持つベクトル) に各特徴をマップします。 このベクトルは、画像を特徴付けるエッジや形状などの特徴の数値表現です。 これはコードに似ています。
通常、特徴抽出手法では "転移学習メカニズム" を使用します。 これは、事前トレーニングされたニューラル ネットワークを選択し、それを使って各画像を実行して、生成された特徴ベクトルを画像データベースに保存するときに発生します。 このようにして、誰かがトレーニングしたネットワークから学習を "転移" します。 Microsoft は、事前トレーニングされたネットワークをいくつか開発し、公開しています。これらのネットワークは、画像認識タスク (ResNet50など) に広く使用されています。
ニューラル ネットワークによって特徴ベクトルの長さと疎の度合いが異なるため、メモリとストレージの要件が異なります。
また、ネットワークによって適用できるカテゴリがそれぞれ異なる場合があるため、画像検索の実装では、実際にはさまざまなサイズの特徴ベクトルが生成されます。
事前トレーニングされたニューラル ネットワークは比較的使いやすいですが、独自の画像カタログでトレーニングされたカスタム モデルほど効率的ではない可能性があります。 これらの事前トレーニングされたネットワークは、通常、特定の画像コレクションの検索ではなく、ベンチマーク データセットの分類用に設計されています。
これらを変更して再トレーニングして、カテゴリ予測と密な (つまり、疎ではなく小さい) ベクトルの両方を生成することができます。これは、検索スペースを制限し、メモリとストレージの要件を軽減するのに非常に役立ちます。 バイナリ ベクトルを使用できます。多くの場合、これは "セマンティック ハッシュ" (ドキュメントのエンコードと取得の手法から派生した用語) と呼ばれます。 バイナリ表現により、後続の計算が簡素化されます。
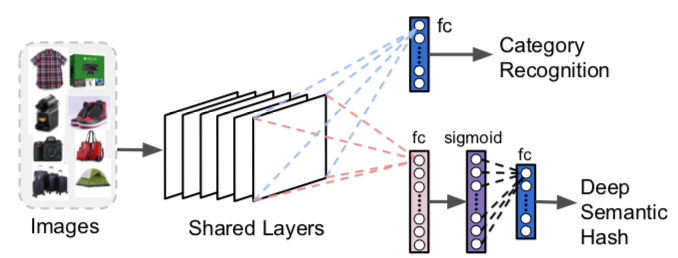
図 4: 画像検索のための ResNet の変更 - F. Yang 他 (2017 年)
事前トレーニングされたモデルを選択するか、独自のモデルを開発するかに関係なく、モデル自体の特徴付けやトレーニングを実行する場所を決定する必要があります。
Azure には、複数のオプション (VM、Azure Batch、 Batch AI、Databricks クラスター) が用意されています。 ただし、どの場合も、GPU を使用することによって、最適な価格/パフォーマンス比が得られます。
最近、Microsoft はわずかな GPU コストで高速計算を実現する FPGA の提供も発表しました (Project Brainwave)。 ただし、このドキュメントの執筆時点では、このオファリングは特定のネットワーク アーキテクチャに限定されているので、パフォーマンスを綿密に評価する必要があります。
類似性測度または距離
画像を特徴ベクトル空間内で表現する場合、類似性の検出は、そのような空間内にあるポイント間の距離測度の定義の問題になります。 距離が定義されたら、類似画像のクラスターを計算したり、類似性マトリックスを定義したりできます。 選択した距離メトリックによって、結果が異なる場合があります。 理解しやすいものとして、実数ベクトルに対する最も一般的なユークリッド距離測度があります。これは距離の大きさを取得します。 ただし、計算の観点から言うと、やや非効率的です。
コサイン 距離は、その大きさではなく、ベクトルの向きを取得するためによく使用されます。
バイナリ表現に対する ハミング 距離などの代替手段では、ある程度の正確さが損なわれる代わりに、効率と速度が得られます。
ベクトルのサイズと距離測度の組み合わせによって、検索の計算負荷とメモリ負荷がどのくらいになるかが決まります。
検索 & ランク付け
類似性が定義されたら、入力として渡されたものに最も近い N 個の項目を取得し、識別子のリストを返す効率的な方法を考案する必要があります。 これは "画像ランク付け" とも呼ばれます。 大規模なデータセットでは、すべての距離の計算に膨大な時間がかかるため、近似最近傍アルゴリズムを使用します。 これらのアルゴリズムのオープン ソース ライブラリがいくつか存在するので、ゼロからコーディングする必要はありません。
最後に、メモリと計算の要件によって、トレーニングされたモデルの展開テクノロジと高可用性が決まります。 通常、検索空間はパーティション分割され、ランク付けアルゴリズムの複数のインスタンスが並列実行されます。 スケーラビリティと可用性を実現する 1 つのオプションとして、 Azure Kubernetes クラスターがあります。 その場合、ランク付けモデルを複数のコンテナー (各検索空間のパーティションを処理) および複数のノード (高可用性の確保) に展開することをお勧めします。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- Giovanni Marchetti | Manager, Azure Solution Architects
- Mariya Zorotovich | カスタマー エクスペリエンス、HLS & エマージング テクノロジー担当責任者
その他の共同作成者:
- Scott Seely 氏 | ソフトウェア アーキテクト
次のステップ
画像検索の実装は複雑である必要はありません。 Bing を使用することも、Azure サービスを使用して独自に構築することもでき、Microsoft の AI 研究と AI ツールからメリットが得られます。
開発
- カスタマイズされたサービスの作成を開始するには、 Bing Visual Search API の概要をご覧ください。
- 最初のリクエストを作成するには、クイックスタートを参照してください: C# | Java | Node.js | Python
- Visual Search API リファレンスを理解します。
バックグラウンド
- ディープ ラーニングによる画像のセグメント化: 画像をバックグラウンドから分離するプロセスについて説明する Microsoft の論文
- Visual Search at eBay (eBay での画像検索): コーネル大学による研究
- Visual Discovery at Pinterest (Pinterest での画像検索): コーネル大学による研究
- Semantic Hashing (セマンティック ハッシュ): トロント大学による研究