この記事では、マイクロサービス アーキテクチャでデータを管理するための考慮事項について説明します。 各マイクロサービスは独自のデータを管理するため、データの整合性とデータの整合性は重要な課題となります。
2 つのサービスでデータ ストアを共有しないでください。 各サービスは独自のプライベート データ ストアを管理し、他のサービスは直接アクセスできません。 この規則により、サービス間の意図しない結合が防止されます。これは、サービスが同じ基になるデータ スキーマを共有する場合に発生します。 データ スキーマが変更された場合は、そのデータベースに依存するすべてのサービスで変更を調整する必要があります。 各サービスのデータ ストアを分離すると、変更の範囲が制限され、独立したデプロイの機敏性が維持されます。 各マイクロサービスには、一意のデータ モデル、クエリ、または読み取りと書き込みのパターンがある場合もあります。 共有データ ストアでは、各チームが特定のサービス用にデータ ストレージを最適化する機能が制限されます。
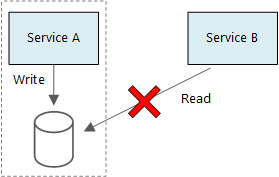
この図は、左側のセクションにサービス A とデータベースを示しています。 サービス A からデータベースへの書き込みポイントというラベルが付いた矢印。 サービス B は、右側のこのセクションの外側にあります。 読み取りのラベルが付いた矢印は、データベースを指します。 赤い X がこの矢印を横切ります。
このアプローチは、自然と ポリグロットの永続化につながります。つまり、1 つのアプリケーション内で複数のデータ ストレージ テクノロジを使用します。 1 つのサービスで、ドキュメント データベースの読み取り時スキーマ機能が必要になる場合があります。 別のサービスでは、リレーショナル データベース管理システム (RDBMS) が提供する参照整合性が必要な場合があります。 各チームは、そのサービスに最適なオプションを選択できます。
注
サービスは、同じ物理データベース サーバーを安全に共有できます。 サービスが同じスキーマを共有するか、同じデータベース テーブルのセットに対して読み取りと書き込みを行うと、問題が発生します。
課題
データを管理するための分散アプローチには、いくつかの課題があります。 まず、データ ストア間で冗長性が発生する可能性があります。 同じデータ項目が複数の場所に表示される場合があります。 たとえば、データはトランザクションの一部として格納され、分析、レポート、またはアーカイブのために他の場所に格納される場合があります。 データが重複またはパーティション分割されると、データの整合性と整合性に問題が発生する可能性があります。 データ リレーションシップが複数のサービスにまたがる場合、従来のデータ管理手法ではそれらのリレーションシップを適用できません。
従来のデータ モデリングは、 1 か所で 1 つのファクトのルールに従います。 すべてのエンティティは、スキーマに 1 回だけ表示されます。 他のエンティティが参照している可能性がありますが、複製することはできません。 従来のアプローチの主な利点は、更新プログラムが 1 か所で発生し、データの整合性の問題を防ぐことです。 マイクロサービス アーキテクチャでは、更新プログラムがサービス間でどのように伝達されるか、およびデータが厳密な整合性なしで複数の場所に表示される場合に最終的な整合性を管理する方法を考慮する必要があります。
データを管理する方法
すべてのケースに対して 1 つのアプローチは機能しません。 マイクロサービス アーキテクチャでデータを管理するには、次の一般的なガイドラインを検討してください。
各コンポーネントに必要な整合性レベルを定義し、可能な場合は最終的な整合性を優先します。 システム内で強力な整合性、原子性、一貫性、分離性、持続性 (ACID) トランザクションが必要な領域を特定します。 また、最終的な整合性が許容される領域を特定します。 詳細については、「 マイクロサービスに戦術的なドメイン駆動設計 (DDD) を使用する」を参照してください。
厳密な整合性が必要な場合は、単一の信頼できるソースを使用します。 1 つのサービスは、特定のエンティティの信頼のソースを表し、API を介して公開する場合があります。 他のサービスは、データの独自のコピーまたはデータのサブセットを保持する可能性があります。データのサブセットは、最終的にはプライマリ データと一致しますが、信頼できるソースとは見なされません。 たとえば、顧客注文サービスとレコメンデーション サービスがある e コマース システムでは、レコメンデーション サービスが注文サービスからのイベントをリッスンする場合があります。 ただし、顧客が払い戻しを要求した場合、注文サービスはレコメンデーション サービスではなく、完全なトランザクション履歴を持ちます。
トランザクション パターンを適用して、サービス間の一貫性を維持します。 Scheduler Agent Supervisor や補正トランザクションなどのパターンを使用して、複数のサービス間でデータの整合性を維持します。 複数のサービスの部分的な障害を回避するには、複数のサービスにまたがる作業単位の状態をキャプチャする追加のデータを格納する必要がある場合があります。 たとえば、マルチステップ トランザクションの進行中は、永続的なキューに作業項目を保持します。
サービスに必要なデータのみを格納します。 サービスには、ドメイン エンティティに関する情報のサブセットのみが必要な場合があります。 たとえば、出荷境界コンテキストでは、特定の配送に関連付けられている顧客を把握する必要があります。 ただし、顧客の請求先住所は必要ありません。これは、アカウントの有界コンテキストによってその情報が管理されるためです。 慎重なドメイン分析と DDD アプローチにより、この原則を適用できます。
サービスが一貫性があり、疎結合されているかどうかを検討します。 2 つのサービスが継続的に相互に情報を交換し、おしゃべりな API を作成する場合は、サービスの境界を再描画することが必要になる場合があります。 2 つのサービスをマージするか、機能をリファクタリングします。
イベント ドリブン アーキテクチャ スタイルを使用します。 このアーキテクチャ スタイルでは、パブリック モデルまたはエンティティへの変更が発生したときに、サービスによってイベントが発行されます。 他のサービスは、これらのイベントをサブスクライブできます。 たとえば、別のサービスでイベントを使用して、クエリに適したデータの具体化されたビューを作成できます。
イベントのスキーマを発行します。 イベントを所有するサービスでは、イベントのシリアル化と逆シリアル化を自動化するスキーマを発行する必要があります。 この方法では、パブリッシャーとサブスクライバーの間の緊密な結合を回避できます。 JSON スキーマ、または Protobuf や Avro などのフレームワークを検討してください。
イベントのボトルネックを大規模に削減します。 大規模なイベントは、システムのボトルネックになる可能性があります。 集計またはバッチ処理を使用して、総負荷を減らすことを検討してください。
例: ドローン配送アプリケーションのデータ ストアを選択する
このシリーズの前の記事では、ドローン配送サービスを実行中の例として説明します。 シナリオと対応するアーキテクチャの詳細については、「 マイクロサービス アーキテクチャの設計」を参照してください。
要約すると、このアプリケーションでは、ドローンによる配送をスケジュールするための複数のマイクロサービスを定義します。 ユーザーが新しい配信をスケジュールすると、クライアント要求には、配送に関する情報 (集荷場所や降車場所など)、およびパッケージに関する情報 (サイズや重量など) が含まれます。 この情報により、作業単位が定義されます。
さまざまなバックエンド サービスでは、要求内の情報のさまざまな部分が使用され、読み取りと書き込みのプロファイルが異なります。

配信サービス
配信サービスには、現在スケジュールされている、または進行中のすべての配信に関する情報が格納されます。 ドローンの発生するイベントを監視し、ドローンの進行中の配送の状態を追跡します。 また、配信状態が更新されたドメイン イベントも送信されます。
ユーザーは、パッケージを待っている間、配信の状態を頻繁に確認します。 そのため、配信サービスには、長期的なストレージよりもスループット (読み取りと書き込み) を重視するデータ ストアが必要です。 配信サービスでは、複雑なクエリや分析は行われません。 特定の配信の最新の状態のみが取得されます。 配信サービス チームは、高い読み取り/書き込みパフォーマンスのために Azure Managed Redis を選択しました。 Azure Managed Redis に格納されている情報は有効期間が短くなります。 配信が完了すると、配信履歴サービスがレコードのシステムになります。
配信履歴サービス
配信履歴サービスは、配信サービスからの配信状態イベントをリッスンします。 このデータは、長期的なストレージに格納されます。 この履歴データは、それぞれ異なるストレージ要件を持つ 2 つのシナリオをサポートしています。
最初のシナリオでは、ビジネスを最適化したり、サービス品質を向上させたりするために、データ分析用のデータを集計します。 配信履歴サービスでは、実際のデータ分析は行われません。 データの取り込みと格納のみが行われます。 このシナリオでは、ストレージを大規模なデータセットに対するデータ分析用に最適化し、スキーマ読み取り時のアプローチを使用してさまざまなデータ ソースに対応する必要があります。 Azure Data Lake Storage は、Hadoop 分散ファイル システム (HDFS) と互換性のある Apache Hadoop ファイル システムであるため、このシナリオに適しています。 また、データ分析シナリオのパフォーマンスに合わせて調整されます。
2 番目のシナリオでは、ユーザーは配信が完了した後に配信の履歴を検索できます。 Data Lake Storage では、このシナリオはサポートされていません。 最適なパフォーマンスを得られるように、Data Lake Storage の時系列データを日付でパーティション分割されたフォルダーに格納します。 ただし、この構造により、個々の ID ベースの参照が非効率的になります。 タイムスタンプもわからない限り、ID 検索ではコレクション全体をスキャンする必要があります。 この問題に対処するために、配信履歴サービスでは、迅速な検索のために Azure Cosmos DB に履歴データのサブセットも格納されます。 レコードは、Azure Cosmos DB に無期限に残る必要はありません。 月などの特定の期間の後に古い配送をアーカイブするには、一括処理を実行します。 データをアーカイブすると、Azure Cosmos DB のコストを削減し、Data Lake Storage からの履歴レポートに使用できるデータを保持できます。
詳細については、「 パフォーマンスを向上させるために Data Lake Storage を調整する」を参照してください。
パッケージサービス
パッケージ サービスには、すべてのパッケージに関する情報が格納されます。 パッケージ サービスのデータ ストアは、次の要件を満たしている必要があります。
- 長期ストレージ
- 大量のパッケージを処理するための高い書き込みスループット
- 複雑な結合や参照整合性制約のないパッケージ ID による単純なクエリ
パッケージ データはリレーショナルではないので、ドキュメント指向のデータベースが適切に機能します。 Azure DocumentDB では、シャード化されたコレクションを使用して高スループットを実現できます。 パッケージ サービス チームは、MongoDB、Express.js、AngularJS、Node.js (MEAN) スタックに精通しているため、 Azure DocumentDB の実装を選択します。 この選択により、既存の MongoDB エクスペリエンスを使用しながら、フル マネージドの高パフォーマンス Azure サービスの利点を得られます。