データベース アーキテクチャの設計
この記事では、Azure アーキテクチャ センターで説明した Azure データベース ソリューションの概要を示します。
Apache®、Apache Cassandra®、および Hadoop のロゴは、Apache Software Foundation の米国およびその他の国における登録商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
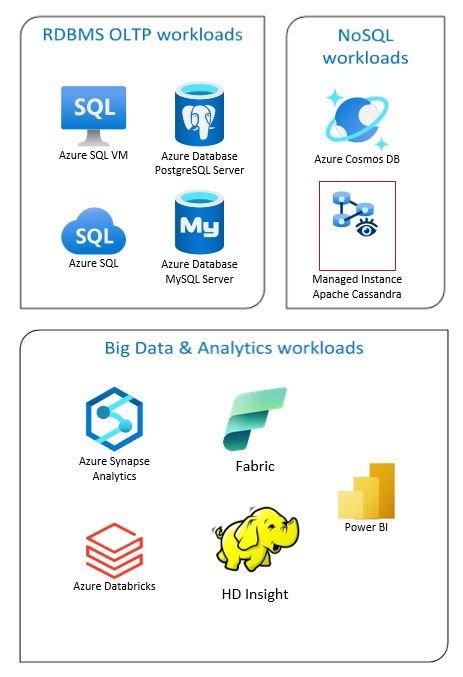
Azure Databaseソリューションには、従来のリレーショナルデータベース管理システム(RDBMSとOLTP)、ビッグデータおよび分析ワークロード(OLAP を含む)、NoSQLワークロードが含まれます。
RDBMS のワークロードには、オンライン トランザクション処理 (OLTP) とオンライン分析処理 (OLAP) が含まれます。 組織内の複数のソースから得られるデータは、データ ウェアハウスに統合できます。 ETL (抽出、変換、ロード)、または ELT (抽出、ロード、変換) プロセスを使用して、ソース データを移動および変換できます。 RDBMSデータベースの詳細については、「Azureのリレーショナルデータベースの探索」を参照してください。
ビッグ データ アーキテクチャは、大規模なデータや複雑なデータのインジェスト、処理、分析を処理するように設計されています。 ビッグデータソリューションは通常、大量のリレーショナルデータと非リレーショナルデータ(従来のRDBMSシステムは保存に適していない)を含みます。 これらは通常、データレイク、デルタレイク、およびレイクハウスのようなソリューションを含みます。 アナリティクスアーキテクチャ設計の詳細を参照してください。
NoSQLデータベースは、非リレーショナル、NoSQL DB あるいは非 SQL とも呼ばれ、急速に変化する膨大な量の非構造化データを処理できるという事実を強調しています。 NoSQL データベースは、(SQL) データベースのようにデータをテーブル、行、列に保存しません。 No SQL DB データベースの詳細については、「NoSQL データ」と「NoSQL データベースとは?」を参照してください。
この記事では、Azure データベースについて学習するためのリソースを示します。 ニーズに合わせたアーキテクチャを実装する方法と、ソリューションの設計時に考慮すべきベスト プラクティスについて概要を説明します。
データベースのニーズに対応するために利用できる多くのアーキテクチャを用意しています。 また、基礎となるソリューションのアイデアも用意しています。これには、必要になるすべてのコンポーネントへのリンクが含まれています。
Azure のデータベースについて学習する
ソリューションのアーキテクチャについて考えるときは、適切なデータストアを選択することが重要です。 Azure のデータベースを初めて使用する場合は、Microsoft Learn から始めることをお勧めします。 この無料のオンライン プラットフォームは、実践的な学習のためのビデオとチュートリアルを提供します。 Microsoft Learn には、開発者やデータ アナリストなどの仕事の役割に基づいたラーニング パスが用意されています。
Azureのさまざまなデータベースとその使用方法の一般的な説明から始めることができます。 また、Azure データ モジュールと「Azure でのデータ ストレージ手法を選択する」を参照することもできます。 これらの記事は、Azure データ ソリューションでの選択肢を理解し、特定のシナリオで一部のソリューションが推奨される理由を確認するのに役立ちます。
役立ちそうな学習モジュールはこちらです。
- Azure への移行を設計する
- Azure SQL Database のデプロイ
- Azure のデータベースおよび分析サービスについて調べる
- Azure SQL Database のセキュリティ保護
- Azure Cosmos DB
- Azure Database for PostgreSQL
- Azure Database for MySQL
- Azure VM での SQL Server
運用へのパス
リレーショナル データの処理に役立つオプションを見つけるために、次のリソースについて検討してください。
- 複数のソースからデータを収集するためのリソース、およびデータパイプライン内でのデータ変換の方法と適用方法については、Azureのアナリティクスを参照してください。
- 大規模なビジネス データベースを編成して複雑な分析をサポートする OLAP については、「オンライン分析処理」を参照してください。
- ビジネス インタラクションが発生したときに記録する OLTP システムについては、「オンライン トランザクション処理」を参照してください。
非リレーショナル データベースでは、行と列の表形式のスキーマを使用しません。 詳細については、「非リレーショナル データと NoSQL」を参照してください。
大量のデータをネイティブな未加工の形式で保持するデータ レイクについては、「データ レイク」を参照してください。
ビッグ データ アーキテクチャは、従来のデータベース システムには多すぎる、または複雑すぎるデータのインジェスト、処理、分析を処理できます。 詳細については、「ビッグ データ アーキテクチャ」と「分析」を参照してください。
ハイブリッド クラウドとは、パブリック クラウドとオンプレミスのデータセンターを組み合わせた IT 環境のことです。 詳細については、Azure Arc と Azure データベース 組み合わせることを検討してください。
Azure Cosmos DB は、最新のアプリ開発に対応するフル マネージドの NoSQL データベース サービスです。 詳細については、「Azure Cosmos DB リソース モデル」を参照してください。
Azure との間のデータ転送のオプションについては、「Azure との間でのデータの転送」を参照してください。
ベスト プラクティス
ソリューションの設計時には、これらのベスト プラクティスを確認してください。
| ベスト プラクティス | 説明 |
|---|---|
| Azure Cosmos DB を使用した Transactional Outbox パターン | 信頼性の高いメッセージングと確実なイベントの配信のために、Transactional Outbox パターンを使用する方法について説明します。 |
| Azure Cosmos DB を使用してデータをグローバルに分散させる | 待機時間の短縮と高可用性を実現するために、一部のアプリケーションは、そのユーザーの近くにあるデータ センターにデプロイする必要があります。 |
| Azure Cosmos DB のセキュリティ | セキュリティのベスト プラクティスは、データベース侵害の防止、検出、および対応に役立ちます。 |
| Azure Cosmos DB のポイントインタイム リストアを使用した継続的バックアップ | Azure Cosmos DB のポイントインタイム リストア機能について説明します。 |
| Azure Cosmos DB を使用して高可用性を実現する | Azure Cosmos DB には、高可用性を実現するための機能と構成のオプションが複数用意されています。 |
| Azure SQL Database と SQL Managed Instance の高可用性 | データベースは、アーキテクチャの単一障害点にならないようにする必要があります。 |
テクノロジの選択
Azure データベースに使用するテクノロジには、多数のオプションがあります。 次に示す記事は、目的のニーズに最適なテクノロジを選択する際に役立ちます。
- データストアの選択
- Azure で使用する分析データ ストアの選択
- Azure でのデータ分析とテクノロジの選択
- Azure でのバッチ処理テクノロジの選択
- Azure でのビッグ データ ストレージ テクノロジの選択
- Azure でのデータ パイプライン オーケストレーション テクノロジの選択
- Azure で検索データ ストアを選択する
- Azure でのストリーム処理テクノロジの選択
データベースを最新の状態に維持する
「Azure の更新情報」を参照して、Azure Databases テクノロジを最新の状態に維持してください。
関連リソース
- Azure でのデータ管理と分析のための Adatum Corporation のシナリオ
- Azure でのデータ管理と分析のための Lamna Healthcare シナリオ
- SQL Server インスタンスの管理を最適化する
- Azure でのデータ管理と分析のための Relecloud シナリオ
同様のデータベース製品
アマゾン ウェブ サービス (AWS) または Google Cloud についての知識がある場合は、次の比較を参照してください。