Azure Functions が Application Insights に統合されると、関数アプリの監視をより適切に行うことができます。 Azure Monitor の機能である Application Insights は、アプリがログに書き込む情報など、関数アプリによって生成されたデータを収集する拡張可能なアプリケーション パフォーマンス管理 (APM) サービスです。 Application Insights との統合は、通常、関数アプリが作成されるときに有効になります。 アプリにインストルメンテーション キーが設定されていない場合は、まず Application Insights との統合を有効にする必要があります。
Application Insights はカスタム構成なしで使用できます。 ただし、既定の構成ではデータ量が多くなる可能性があります。 Visual Studio Azure サブスクリプションを使っている場合、Application Insights のデータ上限に達する可能性があります。 Application Insights のコストについては、「Application Insights の課金」をご覧ください。 詳細については、「テレメトリの量が多いソリューション」を参照してください。
この記事では、関数から Application Insights に送信するデータを構成し、カスタマイズする方法を説明します。 host.json ファイルでは、一般的なログ構成を設定できます。 既定では、これらの設定によって、コードによって出力されるカスタム ログも制御されます。 ただし、ログをより詳細に制御できるオプションを優先して、この動作を無効にできる場合があります。 詳細については、「カスタム アプリケーション ログ」を参照してください。
注
特別に構成されたアプリケーション設定を使用して、特定の環境の host.json ファイル内の特定の設定を表すことができます。 そうすることで、プロジェクト内の host.json ファイルを再発行することなく、host.json 設定を効果的に変更できます。 詳細については、「host.json 値をオーバーライドする」を参照してください。
カスタム アプリケーション ログ
既定では、書き込まれたカスタム アプリケーション ログは Functions ホストに送信され、Worker カテゴリの下で Application Insights に送信されます。 一部の言語スタックでは、代わりにログを Application Insights に直接送信できるため、書き込んだログの出力方法を完全に制御できます。 この場合、ログ パイプラインは worker -> Functions host -> Application Insights から worker -> Application Insights に変更されます。
次の表は、各スタックで使用できる構成オプションをまとめたものです。
| 言語スタック | カスタム ログを構成する場所 |
|---|---|
| .NET (インプロセス モデル) | host.json |
| .NET (分離モデル) | 既定値 (カスタム ログを Functions ホストに送信): host.jsonログを Application Insights に直接送信するには、HostBuilder で Application Insights を構成するに関する記事を参照してください |
| Node.js | host.json |
| Python(プログラミング言語) | host.json |
| ジャワ | 既定値 (カスタム ログを Functions ホストに送信): host.jsonログを Application Insights に直接送信するには、Application Insights Java エージェントの構成に関する記事を参照してください |
| PowerShell | host.json |
カスタム アプリケーション ログが直接送信されるように構成すると、ホストはログを出力しなくなり、host.json はログの動作を制御しなくなります。 同様に、各スタックによって公開されるオプションはカスタム ログにのみ適用され、この記事で説明されている他のランタイム ログの動作は変更されません。 この場合、すべてのログの動作を制御するには、両方の構成を変更する必要がある場合があります。
カテゴリを構成する
Azure Functions のロガーでは、すべてのログにカテゴリがあります。 カテゴリは、ランタイム コードや関数コードのどの部分にログが記述されているかを示します。 バージョン 1.x とそれ以降のバージョンとでは、カテゴリが異なります。
カテゴリ名は、他の .NET フレームワークとは異なる方法で関数に割り当てられます。 たとえば、ASP.NET で ILogger<T> を使用する場合、カテゴリはジェネリック型の名前になります。 C# 関数も ILogger<T> を使用しますが、ジェネリック型名をカテゴリとして設定する代わりに、ランタイムはソースに基づいてカテゴリを割り当てます。 次に例を示します。
- 関数の実行に関連するエントリには、
Function.<FUNCTION_NAME>カテゴリが割り当てられます。 -
logger.LogInformation()の呼び出し時など、関数内のユーザー コードによって作成されたエントリには、Function.<FUNCTION_NAME>.Userカテゴリが割り当てられます。
次の表では、ランタイムが作成するログの主なカテゴリについて説明します。
| カテゴリ | テーブル | 説明 |
|---|---|---|
Function |
痕跡 | すべての関数の実行について、Function started および completed のログが含まれます。 正常に実行された場合、これらのログは Information レベルとなります。 例外は Error レベルでログされます。 また、キュー メッセージがWarningに送信されたといったような場合には、ランタイムによって レベルのログも作成されます。 |
Function.<YOUR_FUNCTION_NAME> |
依存 関係 | 一部のサービスについては、依存関係データが自動的に収集されます。 正常に実行された場合、これらのログは Information レベルとなります。 詳しくは、「依存関係」をご覧ください。 例外は Error レベルでログされます。 また、キュー メッセージがWarningに送信されたといったような場合には、ランタイムによって レベルのログも作成されます。 |
Function.<YOUR_FUNCTION_NAME> |
customMetrics customEvents |
C# および JavaScript SDK を使用すると、カスタム メトリックを収集し、カスタム イベントをログに記録することができます。 詳細については、「カスタム利用統計情報」を参照してください。 |
Function.<YOUR_FUNCTION_NAME> |
痕跡 | 特定の関数の実行について、Function started および completed のログが含まれます。 正常に実行された場合、これらのログは Information レベルとなります。 例外は Error レベルでログされます。 また、キュー メッセージがWarningに送信されたといったような場合には、ランタイムによって レベルのログも作成されます。 |
Function.<YOUR_FUNCTION_NAME>.User |
痕跡 | ユーザーが生成したログ。任意のログ レベルとすることができます。 関数からのログへの書き込みの詳細については、「ログへの書き込み」を参照してください。 |
Host.Aggregator |
customMetrics | これらのランタイム生成ログには、構成可能な期間の関数呼び出しの回数と平均回数が記録されます。 既定の期間は、30 秒か 1,000 回のどちらか早い方です。 例としては、実行回数、成功率、時間などがあります。 これらすべてのログは Information レベルで書き込まれます。
Warning 以上でフィルター処理すると、このデータは表示されません。 |
Host.Results |
リクエスト | これらのランタイム生成ログから、関数の成功または失敗を確認できます。 これらすべてのログは Information レベルで書き込まれます。
Warning 以上でフィルター処理すると、このデータは表示されません。 |
Microsoft |
痕跡 | ホストによって起動される .NET ランタイム コンポーネントを反映する完全修飾ログ カテゴリ。 |
Worker |
痕跡 | .NET 以外の言語用の言語ワーカー プロセスによって生成されるログ。 言語ワーカー ログは、Microsoft.* などの Microsoft.Azure.WebJobs.Script.Workers.Rpc.RpcFunctionInvocationDispatcher カテゴリで記録される場合もあります。 これらのログは、Information レベルで書き込まれます。 |
注
.NET クラス ライブラリ関数の場合、これらのカテゴリでは、ILogger ではなく ILogger<T> を使用していることが想定されています。 詳細については、Functions ILogger のドキュメントを参照してください。
テーブル列に、Application Insights のどのテーブルにログが書き込まれるかが示されます。
ログ レベルを構成する
"ログ レベル" がすべてのログに割り当てられます。 値は、相対的な重要度を示す整数です。
| LogLevel | コード | 説明 |
|---|---|---|
| トレース | 0 | 最も詳細なメッセージを含むログ。 これらのメッセージには、機密性の高いアプリケーション データが含まれる場合があります。 これらのメッセージは既定で無効になっているため、運用環境では有効にしないでください。 |
| デバッグ | 1 | 開発時に対話型調査に使用されるログ。 これらのログには、主にデバッグに役立つ情報が含まれており、長期的な値は含まれていません。 |
| 情報 | 2 | アプリケーションの一般的なフローを追跡するログ。 これらのログには長期的な値を含める必要があります。 |
| 警告 | 3 | アプリケーション フロー内の異常なイベントまたは予期しないイベントを強調するが、それ以外ではアプリケーションの実行を停止することはないログ。 |
| エラー | 4 | エラーが発生したために現在の実行フローが停止したことを強調するログ。 これらのエラーは、アプリケーション全体の障害ではなく、現在のアクティビティの失敗を示している必要があります。 |
| 危うい | 5 | 回復不可能なアプリケーションまたはシステムのクラッシュや、早急に対処する必要がある重大な障害について説明するログ。 |
| なし | 6 | 指定したカテゴリのログ記録を無効にします。 |
host.json ファイルの構成により、関数アプリから Application Insights に送信されるログの量が決まります。
カテゴリごとに、送信する最小のログ レベルを指定します。 host.json の設定は、Functions ランタイムのバージョンによって異なります。
以下の例では、次の規則に基づいてログを定義します。
- 既定のログ レベルは、予期しないカテゴリに対する
Warningを防ぐために、 に設定されています。 -
Host.AggregatorとHost.Resultsは低いレベルに設定されています。 ログ レベルの設定が高すぎる (特にInformationより高い) と、メトリックとパフォーマンス データが失われる可能性があります。 - 関数の実行のログ記録が
Informationに設定されています。 必要に応じて、ローカル開発でこの設定を またはDebugにTraceできます。
{
"logging": {
"fileLoggingMode": "debugOnly",
"logLevel": {
"default": "Warning",
"Host.Aggregator": "Trace",
"Host.Results": "Information",
"Function": "Information"
}
}
}
host.json に、同じ文字列で始まる複数のログが含まれている場合は、より明確に定義されたログが先に一致します。 ランタイムで、Host.Aggregator を除き、Error レベルのすべてのものをログする次の例について考えてみます。
{
"logging": {
"fileLoggingMode": "debugOnly",
"logLevel": {
"default": "Information",
"Host": "Error",
"Function": "Error",
"Host.Aggregator": "Information"
}
}
}
None というログ レベル設定を使用すれば、カテゴリのログが書き込まれないようにすることができます。
注意事項
Azure Functions は、Application Insights にテレメトリ イベントを格納することで、Application Insights と統合されます。 カテゴリ ログ レベルを Information とは異なる値に設定すると、テレメトリがこれらのテーブルに流れなくなり、[Application Insights] と関数の [監視] タブで関連データを表示できなくなります。
たとえば、前のサンプルでは次のようになります。
-
Host.ResultsカテゴリがErrorログ レベルに設定されている場合、Azure ではrequestsテーブルに失敗した関数の実行に関するホスト実行テレメトリ イベントのみが収集され、[Application Insights] と関数の [監視] の両方のタブで、成功した実行のホスト実行の詳細が表示されなくなります。 -
FunctionカテゴリをErrorログ レベルに設定すると、すべての関数のdependencies、customMetrics、customEventsに関連する関数テレメトリ データの収集が停止され、Application Insights にこのデータが表示されなくなります。 Azure では、tracesレベルでログされたErrorのみが収集されます。
どちらの場合も、Azure は [Application Insights] と関数の [監視] タブでエラーと例外のデータを収集し続けます。 詳細については、「テレメトリの量が多いソリューション」を参照してください。
アグリゲーターを構成する
前のセクションで述べたように、ランタイムでは期間内の関数実行についてデータが集計されます。 既定の期間は、30 秒か 1,000 回実行のどちらか早い方です。 host.json ファイル内でこの設定を構成できます。 次に例を示します。
{
"aggregator": {
"batchSize": 1000,
"flushTimeout": "00:00:30"
}
}
サンプリングを構成する
Application Insights には、負荷がピークのときに、完了した実行に関してテレメトリ データが生成されすぎないようにするサンプリング機能があります。 Application Insights では、受信実行の割合が指定されたしきい値を超えると、受信した実行の一部がランダムに無視され始めます。 1 秒あたりの最大実行数の既定の設定は 20 (バージョン 1.x では 5) です。 host.json でサンプリングを構成できます。 次に例を示します。
{
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"maxTelemetryItemsPerSecond" : 20,
"excludedTypes": "Request;Exception"
}
}
}
}
特定の種類のテレメトリをサンプリングから除外することができます。 この例では、Request および Exception 型のデータがサンプリングから除外されます。 これにより、"すべての" 関数実行 (要求) と例外が確実にログされる一方で、他の種類のテレメトリはサンプリング対象のままとなります。
プロジェクトで Application Insights SDK への依存関係を使用して手動でテレメトリ追跡を行う場合、サンプリング構成が関数アプリのサンプリング構成と異なると、異常な動作が発生する可能性があります。 このような場合は、関数アプリと同じサンプリング構成を使用します。 詳細については、「Application Insights におけるサンプリング」を参照してください。
SQL クエリ コレクションを有効にする
Application Insights は、HTTP 要求、データベース呼び出し、および複数のバインディングの依存関係に関するデータを自動的に収集します。 詳しくは、「依存関係」をご覧ください。 SQL 呼び出しの場合、サーバーとデータベースの名前は常に収集されて保存されますが、SQL クエリ テキストは既定では収集されません。
dependencyTrackingOptions.enableSqlCommandTextInstrumentation を使用して、host.json ファイルで (少なくとも) 次の設定を行うことで、SQL クエリのテキスト ログを有効にすることができます。
"logging": {
"applicationInsights": {
"enableDependencyTracking": true,
"dependencyTrackingOptions": {
"enableSqlCommandTextInstrumentation": true
}
}
}
詳しくは、「詳細な SQL 追跡で完全な SQL クエリを取得する」を参照してください。
スケール コントローラーのログを構成する
この機能はプレビュー段階にあります。
Azure Functions スケール コントローラーから Application Insights または BLOB ストレージにログを出力させることで、関数アプリに対してスケール コントローラーが行っている決定をより詳しく把握することができます。
この機能を有効にするには、関数アプリの設定に SCALE_CONTROLLER_LOGGING_ENABLED という名前のアプリケーション設定を追加します。 次の設定値は、<DESTINATION>:<VERBOSITY> の形式である必要があります。 詳細については、後の表を参照してください。
| プロパティ | 説明 |
|---|---|
<DESTINATION> |
ログの送信先。 有効な値は AppInsights と Blob です。AppInsights を使用する場合は、関数アプリで Application Insights が有効になっていることを確認してください。宛先を Blob に設定すると、azure-functions-scale-controller アプリケーション設定で設定されている既定のストレージ アカウントの AzureWebJobsStorage という名前の BLOB コンテナーにログが作成されます。 |
<VERBOSITY> |
ログ記録のレベルを指定します。 サポートされている値は、None、Warning、および Verbose です。Verbose に設定すると、スケール コントローラーは、すべてのワーカー数の変更の理由と、それらの決定の要因となるトリガーに関する情報をログに記録します。 詳細ログには、トリガー警告と、スケール コントローラーの実行前と実行後にトリガーによって使用されたハッシュが含まれます。 |
ヒント
スケール コントローラーのログを有効にしたままにすると、関数アプリの監視にかかる可能性のあるコストに影響することに注意してください。 スケール コントローラーの動作を理解するのに十分なデータを収集するまでログ記録を有効にし、その後は無効にすることを検討してください。
たとえば、次の Azure CLI コマンドを実行すると、スケール コントローラーから Application Insights への詳細ログ記録が有効になります。
az functionapp config appsettings set --name <FUNCTION_APP_NAME> \
--resource-group <RESOURCE_GROUP_NAME> \
--settings SCALE_CONTROLLER_LOGGING_ENABLED=AppInsights:Verbose
この例では、<FUNCTION_APP_NAME> と <RESOURCE_GROUP_NAME> を実際の関数アプリの名前とリソース グループ名でそれぞれ置き換えます。
次の Azure CLI コマンドでは、詳細度が None に設定されているため、ログ記録が無効になります。
az functionapp config appsettings set --name <FUNCTION_APP_NAME> \
--resource-group <RESOURCE_GROUP_NAME> \
--settings SCALE_CONTROLLER_LOGGING_ENABLED=AppInsights:None
また、次の Azure CLI コマンドを使用して SCALE_CONTROLLER_LOGGING_ENABLED 設定を削除することで、ログ記録を無効にすることもできます。
az functionapp config appsettings delete --name <FUNCTION_APP_NAME> \
--resource-group <RESOURCE_GROUP_NAME> \
--setting-names SCALE_CONTROLLER_LOGGING_ENABLED
スケール コントローラーのログを有効にすると、スケール コントローラーのログに対してクエリを実行できるようになります。
Application Insights との統合を有効にする
関数アプリが Application Insights にデータを送信するには、次のアプリケーション設定のうち 1 つのみを使用して Application Insights リソースに接続する必要があります。
| 設定の名前 | 説明 |
|---|---|
APPLICATIONINSIGHTS_CONNECTION_STRING |
この設定は推奨されており、Application Insights インスタンスがソブリン クラウドで実行されている場合に必要です。 この接続文字列は、他の新機能をサポートしています。 |
APPINSIGHTS_INSTRUMENTATIONKEY |
従来の設定。Application Insights では非推奨となっており、接続文字列の設定が優先されます。 |
Azure portal で、または Azure Functions Core Tools または Visual Studio Code を使用してコマンド ラインから関数アプリを作成すると、Application Insights 統合が既定で有効になります。 Application Insights リソースは関数アプリと同じ名前を持ち、同じリージョンまたは最も近いリージョンのどちらかに作成されます。
Microsoft Entra 認証を要求する
APPLICATIONINSIGHTS_AUTHENTICATION_STRING 設定を使用することで、Microsoft Entra 認証で Application Insights への接続を有効にすることができます。 これにより、プロファイラーやスナップショット デバッガーを含むすべての Application Insights パイプライン、および Functions ホストと言語固有のエージェントからの一貫した認証エクスペリエンスが作成されます。
注
現在、ローカル開発に対する Microsoft Entra ID 認証のサポートはありません。
ソブリン クラウドでデータを取り込む場合、Application Insights SDK を使用する場合、Microsoft Entra ID 認証は使用できません。 OpenTelemetry ベースのデータ収集では、ソブリン クラウドを含むすべてのクラウド環境で Microsoft Entra ID 認証がサポートされます。
値には、システム割り当てマネージド ID の場合は Authorization=AAD、ユーザー割り当てマネージド ID の場合には ClientId=<YOUR_CLIENT_ID>;Authorization=AAD が含まれます。 マネージド ID が関数アプリで既に使用可能であり、Monitoring Metrics Publisher と同等のロールが割り当てられている必要があります。 詳細については、「Application Insights 用 Microsoft Entra 認証」を参照してください。
APPLICATIONINSIGHTS_CONNECTION_STRING 設定は必須です。
注
APPLICATIONINSIGHTS_AUTHENTICATION_STRING を使用して Microsoft Entra 認証を使って Application Insights に接続する場合は、Application Insights のローカル認証も無効にする必要があります。 この構成で、テレメトリがワークスペースに取り込まれるようにするには、Microsoft Entra 認証が必要です。
ポータルでの新しい関数アプリ
作成されている Application Insights リソースを確認するには、それを選択して [Application Insights] ウィンドウを展開します。 [新しいリソース名] を変更するか、またはデータを格納する Azure 地域内の別の [場所] を選択することができます。
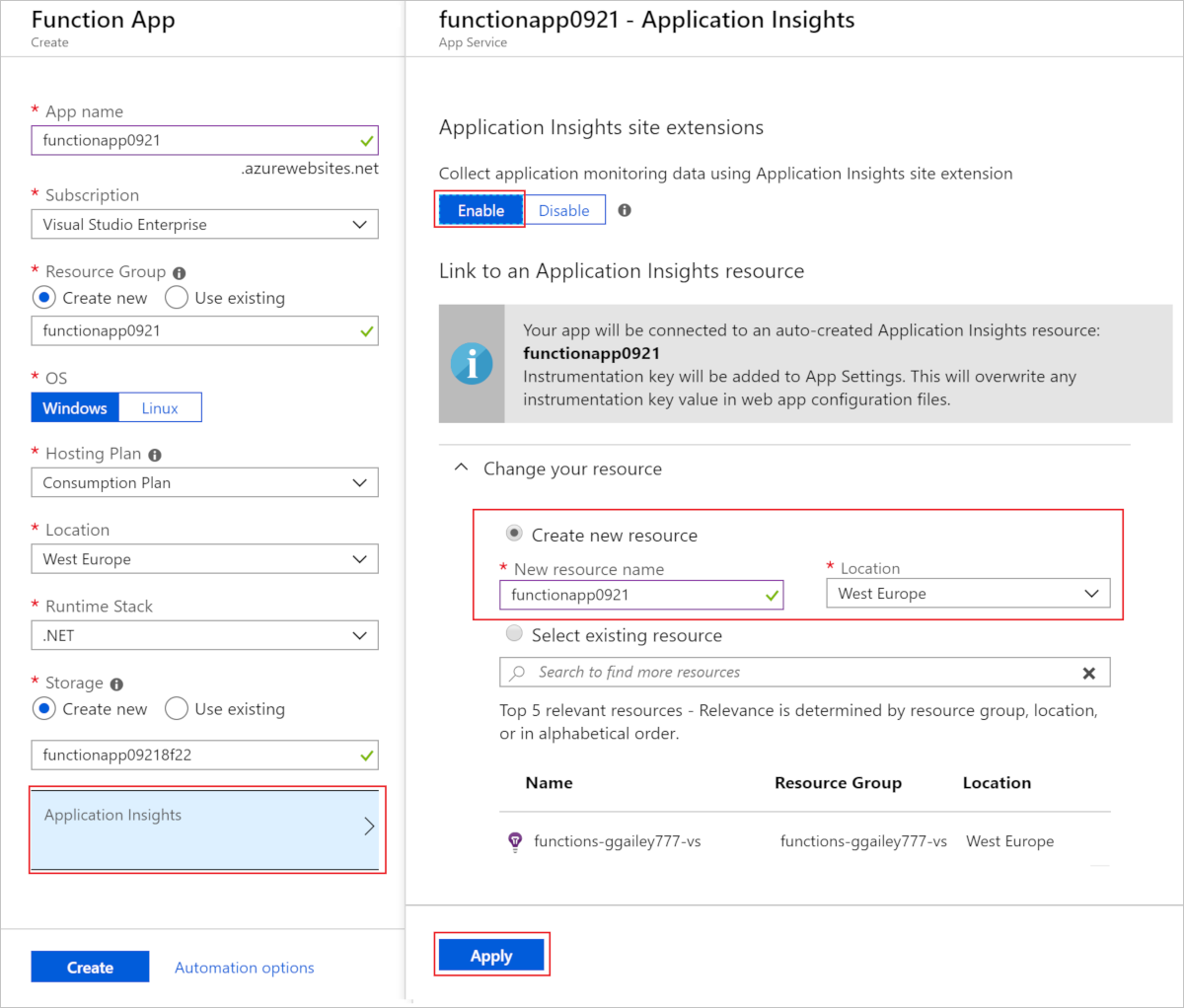
[作成] を選択すると、関数アプリと共に Application Insights リソースが作成され、アプリケーション設定の APPLICATIONINSIGHTS_CONNECTION_STRING が設定されます。 これで、すべて準備ができました。
既存の関数アプリに追加する
ご利用の関数アプリで Application Insights リソースが作成されていない場合は、次の手順を使用してリソースを作成します。 その後、関数アプリのアプリケーション設定として、そのリソースから接続文字列を追加できます。
Azure portal で、関数アプリを検索して選択してから、対象の関数アプリを選択します。
ウィンドウの上部にある [Application Insights が構成されていません] バナーを選択します。 このバナーが表示されない場合は、アプリで既に Application Insights が有効になっている可能性があります。
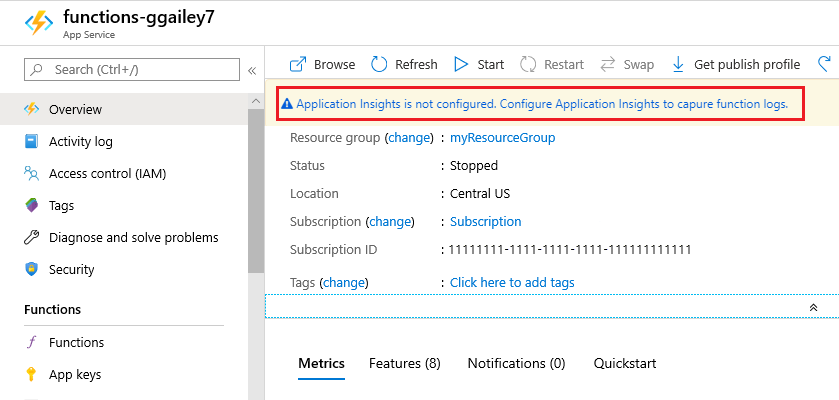
[リソースの変更] を展開し、下の表に指定されている設定を使用して、Application Insights リソースを作成します。
設定 提案された値 説明 新しいリソース名 一意のアプリ名 関数アプリと同じ名前を使用するのが最も簡単です。この名前は、サブスクリプション内で一意である必要があります。 場所 西ヨーロッパ 可能であれば、お使いの関数アプリと同じリージョン、または近隣のリージョンを使用してください。 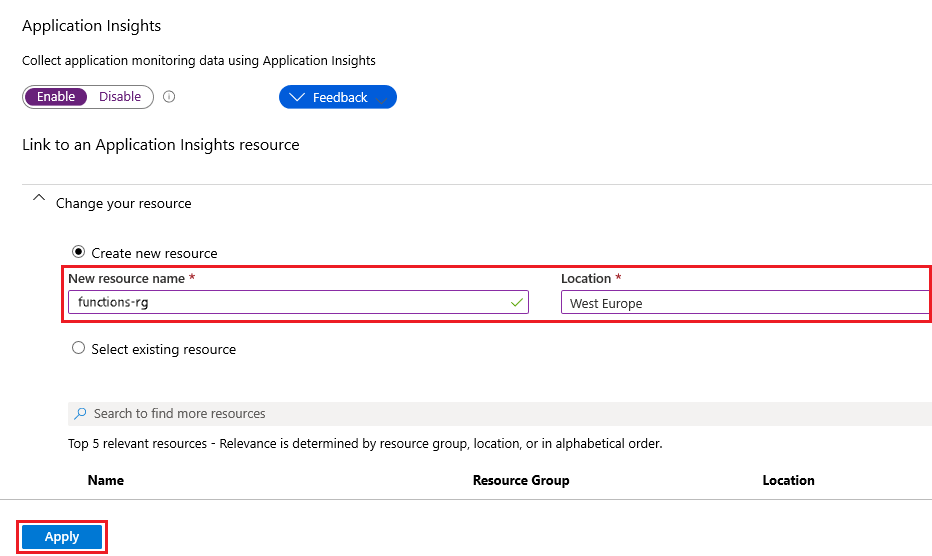
適用を選択します。
Application Insights リソースは、関数アプリと同じリソース グループおよびサブスクリプションに作成されます。 リソースが作成されたら、[Application Insights] ウィンドウを閉じます。
関数アプリで、[設定] を展開し、[環境変数] を選びます。 [アプリ設定] タブに、
APPLICATIONINSIGHTS_CONNECTION_STRINGというアプリ設定が表示される場合、Azure で実行されている関数アプリに対して Application Insights の統合が有効になっています。 この設定が存在しない場合は、Application Insights 接続文字列を値として使用して追加します。
注
以前の関数アプリでは、APPINSIGHTS_INSTRUMENTATIONKEY ではなく APPLICATIONINSIGHTS_CONNECTION_STRING が使用される場合があります。 可能な場合は、インストルメンテーション キーではなく接続文字列を使用するようにアプリを更新します。
組み込みログを無効にする
初期バージョンの関数では組み込みの監視を使用していましたが、これは推奨されなくなりました。 Application Insights を有効にする場合は、Azure Storage を使用する組み込みログを無効にします。 組み込みログは軽量のワークロードには便利ですが、高負荷の実稼働環境での使用には向きません。 実稼働環境の監視には、Application Insights をお勧めします。 運用環境で組み込みのログを使用すると、Azure Storage での調整が原因でログ レコードが不完全になる場合があります。
組み込みログを無効にするには、AzureWebJobsDashboard アプリ設定を削除します。 Azure portal でアプリ設定を削除する方法の詳細については、関数アプリの管理方法に関するページでアプリケーションの設定に関するセクションを参照してください。 アプリ設定を削除する前に、同じ関数アプリの既存の関数によって、Azure Storage のトリガーまたはバインドにその設定が使用されていないことを確認してください。
テレメトリの量が多いソリューション
関数アプリは、IoT ソリューション、迅速なイベント ドリブン ソリューション、高負荷の金融システム、統合システムなど、大量のテレメトリが生じる可能性のあるソリューションの必要不可欠な部分です。 この場合は、監視を維持しながらコストを削減するために、追加の構成を検討する必要があります。
生成されたテレメトリは、リアルタイム ダッシュボード、アラート、詳細な診断などで利用できます。 生成されたテレメトリがどのように利用されるかに応じて、生成されるデータの量を削減する戦略を定義する必要があります。 この戦略により、運用環境での関数アプリの監視、運用、診断を適切に行うことができます。 次のオプションを検討してください。
正しいテーブル プランを使用する: テーブル プラン は、テーブル内のデータを使用する頻度と実行する必要がある分析の種類を制御することで、データ コストを管理するのに役立ちます。 コストを削減するには、
Basicプランを選択します。Analyticsプランで使用できる機能はありません。サンプリングを使用する: 前述のように、サンプリングは、統計的に正しい分析を維持しながら、取り込まれるテレメトリ イベントの量を大幅に削減するのに役立ちます。 サンプリングを使用しても、大量のテレメトリを引き続き取得する可能性があります。 アダプティブ サンプリングによって提供されるオプションを調べます。 たとえば、
maxTelemetryItemsPerSecondを、監視のニーズによって生成される量のバランスを取る値に設定します。 テレメトリ サンプリングは、関数アプリを実行しているホストごとに適用されることに注意してください。既定のログ レベル: すべてのテレメトリ カテゴリの既定値として
WarningまたはErrorを使用します。 後で、関数を適切に監視および診断できるように、 レベルで設定するInformationを決めることができます。関数のテレメトリを調整する: 既定のログ レベルを
ErrorまたはWarningに設定すると、各関数からの詳細情報 (依存関係、カスタム メトリック、カスタム イベント、トレース) は収集されません。 運用環境の監視にとって重要な関数については、詳細な情報を収集できるように、Function.<YOUR_FUNCTION_NAME>カテゴリに明示的なエントリを定義して、Informationに設定します。 ユーザー生成ログがInformationレベルで収集されないようにするには、Function.<YOUR_FUNCTION_NAME>.UserカテゴリをErrorまたはWarningログ レベルに設定します。Host.Aggregator カテゴリ: 「カテゴリを構成する」で説明したように、このカテゴリを使用すると関数呼び出しの集計情報が提供されます。 このカテゴリの情報は Application Insights の
customMetricsテーブルに収集され、Azure portal の関数の [概要] タブに表示されます。 アグリゲーターの構成方法によっては、収集されたテレメトリに、flushTimeout設定によって決定される遅延が発生する可能性があることを考慮してください。 このカテゴリをInformationとは異なる値に設定すると、customMetricsテーブルでのデータ収集が停止され、関数の [概要] タブにメトリックが表示されなくなります。次のスクリーンショットは、関数の
Host.Aggregatorタブに表示されている テレメトリ データを示しています。![関数の [概要] タブに表示された Host.Aggregator テレメトリを示すスクリーンショット。](media/configure-monitoring/host-aggregator-function-overview.png)
次のスクリーンショットは、Application Insights の
Host.AggregatorテーブルのcustomMetricsテレメトリ データを示したものです。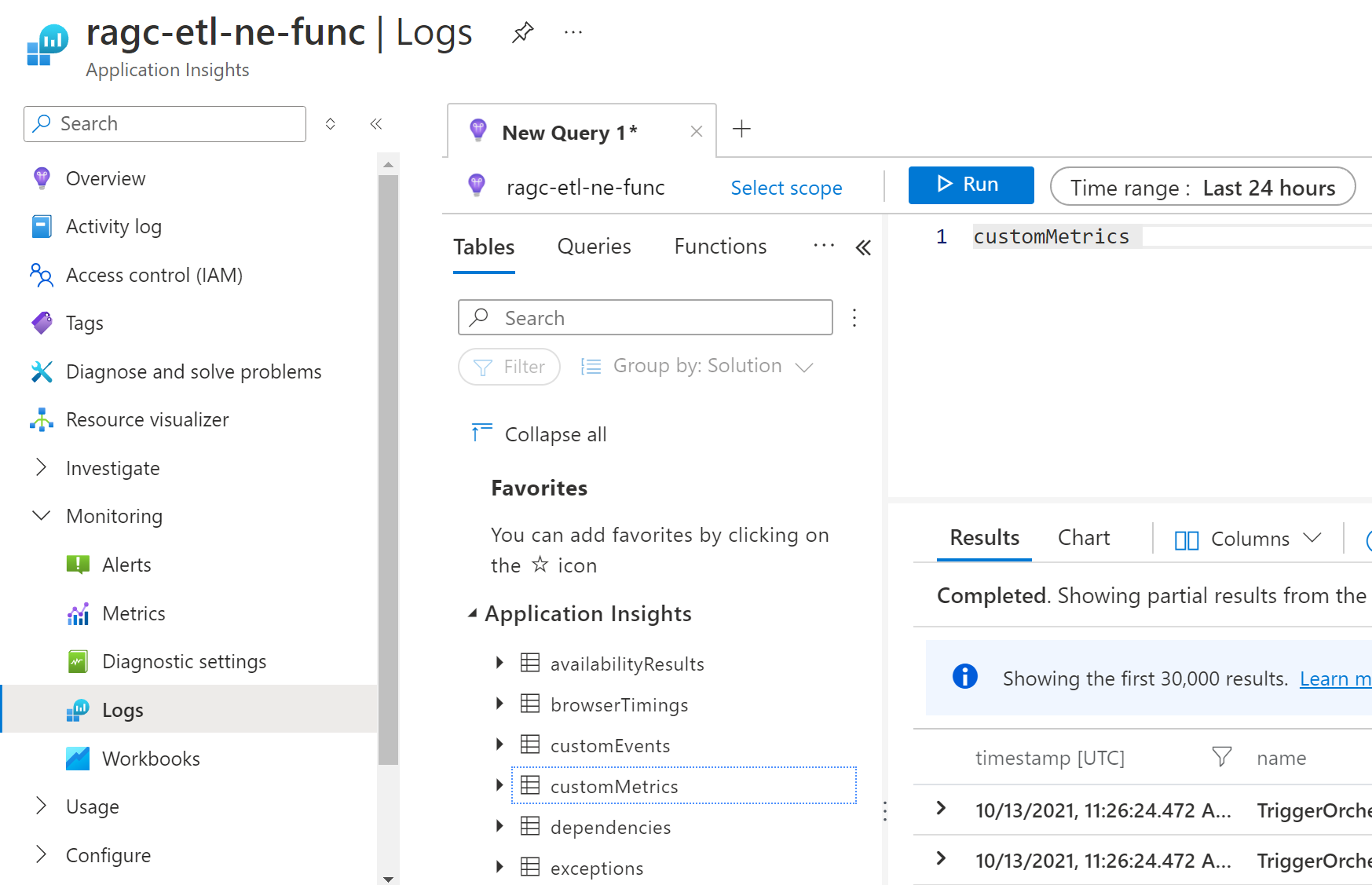
Host.Results カテゴリ: 「カテゴリを構成する」で説明されているように、このカテゴリでは、ランタイムによって生成された、関数呼び出しの成功または失敗を示すログが提供されます。 このカテゴリの情報は Application Insights の
requestsテーブルに収集され、関数の [監視] タブおよびさまざまな Application Insights ダッシュボード ([パフォーマンス]、[エラー] など) に表示されます。 このカテゴリをInformationとは異なる値に設定すると、定義されたログ レベル (またはそれ以上) で生成されたテレメトリのみが収集されます。 たとえば、これをerrorに設定すると、失敗した実行の要求データのみが追跡されます。次のスクリーンショットは、関数の
Host.Resultsタブに表示されている テレメトリ データを示しています。![関数の [監視] タブの Host.Results テレメトリを示すスクリーンショット。](media/configure-monitoring/host-results-function-monitor.png)
次のスクリーンショットは、Application Insights の [パフォーマンス] ダッシュボードに表示された
Host.Resultsテレメトリ データを示したものです。![Application Insights の [パフォーマンス] ダッシュボードの Host.Results テレメトリを示すスクリーンショット。](media/configure-monitoring/host-results-application-insights.png)
Host.Aggregator と Host.Results: どちらのカテゴリでも、関数の実行に関する適切な分析情報が提供されます。 必要に応じて、これらのカテゴリの一方から詳細情報を削除し、監視およびアラートにもう一方を使用できます。 サンプルを次に示します。
![関数の [概要] タブに表示された Host.Aggregator テレメトリを示すスクリーンショット。](media/configure-monitoring/host-aggregator-function-overview-big.png#lightbox)

![関数の [監視] タブの Host.Results テレメトリを示すスクリーンショット。](media/configure-monitoring/host-results-function-monitor-big.png#lightbox)
![Application Insights の [パフォーマンス] ダッシュボードの Host.Results テレメトリを示すスクリーンショット。](media/configure-monitoring/host-results-application-insights-big.png#lightbox)
{
"version": "2.0",
"logging": {
"logLevel": {
"default": "Warning",
"Function": "Error",
"Host.Aggregator": "Error",
"Host.Results": "Information",
"Function.Function1": "Information",
"Function.Function1.User": "Error"
},
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"maxTelemetryItemsPerSecond": 1,
"excludedTypes": "Exception"
}
}
}
}
この構成では次のようになります。
すべての関数およびテレメトリ カテゴリの既定値が
Warningに設定されます (Microsoft および worker のカテゴリを含む)。 そのため、既定では、ランタイムおよびカスタム ログによって生成されたすべてのエラーと警告が収集されます。Functionカテゴリのログ レベルはErrorに設定されているため、すべての関数について、既定では例外とエラー ログのみが収集されます。 依存関係、ユーザー生成のメトリック、ユーザー生成のイベントはスキップされます。Host.AggregatorカテゴリはErrorログ レベルに設定されているため、関数呼び出しからの集計情報はcustomMetricsApplication Insights テーブルに収集されず、実行数 (合計、成功、失敗) に関する情報は関数の概要ダッシュボードに表示されません。Host.Resultsカテゴリについては、すべてのホスト実行情報がrequestsApplication Insights テーブルに収集されます。 すべての呼び出し結果は、関数の [監視] ダッシュボードと [Application Insights] ダッシュボードに表示されます。Function1という関数のログ レベルをInformationに設定します。 したがって、この具象関数については、すべてのテレメトリ (依存関係、カスタム メトリック、カスタム イベント) が収集されます。 同じ関数について、Function1.Userカテゴリ (ユーザー生成のトレース) をErrorに設定して、カスタム エラー ログのみが収集されるようにします。注
関数ごとの構成は、Functions ランタイムの v1.x ではサポートされていません。
例外を除き、サンプリングは種類ごとに 1 秒あたり 1 つのテレメトリ項目を送信するように構成されます。 このサンプリングは、関数アプリを実行しているサーバー ホストごとに行われます。 そのため、インスタンスが 4 つある場合、この構成では種類ごとに 1 秒あたり 4 つのテレメトリ項目と、発生する可能性のあるすべての例外が出力されます。
注
要求レートや例外レートなどのメトリック カウントはサンプリング レートを補正するように調整され、メトリックス エクスプローラーにはほぼ正しい値が表示されます。
ヒント
さまざまな構成を試して、ログ、監視、アラートの要件が満たされることを確認してください。 また、予期しないエラーや誤動作が発生した場合に詳細な診断ができるようにします。
実行時の監視構成のオーバーライド
最後に、運用環境で特定のカテゴリのログ動作をすばやく変更する必要があり、host.json ファイルの変更のためだけに全体のデプロイを行いたくない場合があります。 そのような場合は、host.json の値をオーバーライドできます。
これらの値をアプリ設定レベルで構成する (そして、host.json の変更だけでの再デプロイを回避する) には、アプリケーション設定として同等の値を作成することにより、host.json の特定の値をオーバーライドする必要があります。 ランタイムによって AzureFunctionsJobHost__path__to__setting の形式のアプリケーション設定が検出されると、JSON の host.json にある同等の path.to.setting の設定がオーバーライドされます。 アプリケーション設定として表現される場合、JSON 階層を示すために使用されるドット (__) が 2 つのアンダースコア (.) に置き換えられます。 たとえば、次のアプリ設定を使用して、host.json の個々の関数ログ レベルを構成できます。
| host.json のパス | アプリ設定 |
|---|---|
| logging.logLevel.default | AzureFunctionsJobHost__logging__logLevel__default |
| logging.logLevel.Host.Aggregator | AzureFunctionsJobHost__logging__logLevel__Host.Aggregator |
| logging.logLevel.Function | AzureFunctionsJobHost__logging__logLevel__Function |
| logging.logLevel.Function.Function1 | AzureFunctionsJobHost__logging__logLevel__Function.Function1 |
| logging.logLevel.Function.Function1.User | AzureFunctionsJobHost__logging__logLevel__Function.Function1.User |
設定は、Azure portal 関数アプリの [構成] ペインで直接、または Azure CLI または PowerShell スクリプトを使用してオーバーライドできます。
az functionapp config appsettings set --name MyFunctionApp --resource-group MyResourceGroup --settings "AzureFunctionsJobHost__logging__logLevel__Host.Aggregator=Information"
注
アプリ設定を変更して host.json をオーバーライドすると、関数アプリが再起動されます。
Elastic Premium プランまたは Dedicated (App Service) プランで Linux 上で実行する場合、ピリオドを含むアプリ設定はサポートされません。 これらのホスティング環境では、引き続き host.json ファイルを使用する必要があります。
正常性チェックを使用して関数アプリを監視する
正常性チェック機能を使用して、Premium (Elastic Premium) プランと Dedicated (App Service) プランの関数アプリを監視できます。 正常性チェックは、従量課金プランのオプションではありません。 構成方法については、「正常性チェックを使用して App Service インスタンスを監視する」を参照してください。 関数アプリには、正常性チェックの Path パラメーターで構成されているのと同じエンドポイント上で HTTP 状態コード 200 で応答する HTTP トリガー関数が必要です。 また、その関数で追加のチェックを実行して、依存するサービスが到達可能で動作していることを確認することもできます。
関連するコンテンツ
監視の詳細については、以下を参照してください。