冗長性による可用性 - Azure SQL データベース
適用対象: ![]() Azure SQL データベース
Azure SQL データベース
この記事では、ローカル冗長による可用性とゾーン冗長による高可用性を実現する Azure SQL データベース のアーキテクチャについて説明します。
概要
SQL Database は、適用可能なすべてのパッチが適用された Windows オペレーティング システム上の SQL Server データベース エンジンの最新の安定バージョンで実行されます。 SQL Database は、パッチの適用、バックアップ、Windows と SQL エンジンのアップグレードなどの重要なサービス タスク、基になるハードウェア、ソフトウェア、またはネットワークのエラーなどの計画外のイベントを、自動的に処理します。 アプリに再試行ロジックを導入していると、SQL Database のデータベースまたはエラスティック プールにパッチが適用されたとき、またはフェールオーバーしたときに、ダウンタイムの影響を受けません。 SQL Database は、クリティカルな状況であっても迅速な復旧が可能であるため、データが常に使用可能であることが保証されます。 ほとんどのユーザーは、アップグレードが継続的に実行されていることに気付きません。
既定では、Azure SQL データベース はローカル冗長性によって可用性を実現し、次の期間中にデータベースを使用できるようにします。
- 顧客が開始した管理操作で発生する短いダウンタイム
- サービス メンテナンス操作
- 次に関する問題:
- サービスを稼働するマシンが実行されているラック
- SQL データベース エンジンをホストする物理マシン
- SQL データベース エンジンに関するその他の問題
- その他の、発生する可能性がある計画外のローカル障害
既定の可用性ソリューションは、コミットされたデータが障害によって失われないこと、メンテナンス操作がワークロードに影響を及ぼさないこと、また、データベースがソフトウェア アーキテクチャでの単一障害点にならないことを保証するように設計されています。
ただし、ゾーン全体の障害発生時にデータへの影響を最小限に抑えるために、ゾーン冗長を有効にすると、高可用性を実現できます。 ゾーン冗長がない場合、フェールオーバーは同じデータ センター内でローカルに実行されるため、障害が解決されるまでデータベースが使用できなくなる可能性があります。アクティブ geo レプリケーションによる geo フェールオーバーフェールオーバー、フェールオーバー グループ、geo 冗長バックアップの geo リストアなどの、ディザスター リカバリー ソリューションを使用しなければ復元できません。 詳細については、「ビジネス継続性の概要」を確認してください。
可用性アーキテクチャ モデルには、次の 3 つがあります。
- コンピューティングとストレージの分離に基づくリモート ストレージ モデル。 リモート ストレージ層の可用性と信頼性に依存します。 このアーキテクチャでは、メンテナンス作業中に一定のパフォーマンス低下を許容できる予算重視のビジネス アプリケーションを対象とします。
- データベース エンジン プロセスのクラスターに基づくローカル ストレージ モデル。 利用可能なデータベース エンジン ノードのクォーラムが常にあることに依存しています。 このアーキテクチャでは、高い IO パフォーマンス、高いトランザクション レートを備えたミッション クリティカルなアプリケーションを対象とし、メンテナンス作業中のワークロードに対するパフォーマンスの影響を最小限に抑えることを保証します。
- 計算ノード、ページ サーバー、ログ サービス、永続ストレージなど、高可用性コンポーネントの分散システムを使う Hyperscale モデル。 Hyperscale データベースをサポートする各コンポーネントは、それぞれ障害に対して独自の冗長性と回復性を備えています。 計算ノード、ページ サーバー、ログ サーバーは Azure Service Fabric 上で実行されます。これにより、各コンポーネントの正常性が制御され、必要に応じて使用できる正常なノードへのフェールオーバーが行われます。 永続ストレージは、高可用性と冗長性の機能を備えた Azure Storage を使います。 詳細については、Hyperscale のアーキテクチャに関する記事を参照してください。
3 つの可用性モデルのそれぞれで、SQL Database はローカル冗長とゾーン冗長のオプションをサポートしています。 ローカル冗長は、データセンター内部の回復性を提供します。一方、ゾーン冗長は、リージョン内の可用性ゾーンの停止から保護することによって、回復性をさらに向上します。
次の表は、サービス レベルに基づく可用性オプションを示しています。
| サービス レベル | 高可用性モデル | ローカル冗長可用性 | ゾーン冗長可用性 |
|---|---|---|---|
| General Purpose (仮想コア) | リモート ストレージ | はい | はい |
| Business Critical (仮想コア) | ローカル ストレージ | はい | はい |
| Hyperscale (仮想コア) | Hyperscale | はい | はい |
| Basic (DTU) | リモート ストレージ | はい | いいえ |
| Standard (DTU) | リモート ストレージ | はい | いいえ |
| Premium (DTU) | ローカル ストレージ | はい | はい |
異なるサービス レベルの特定の SLA に関する詳細については、「Azure SQL データベース の SLA」を確認してください。
ローカル冗長性による可用性
ローカル冗長可用性は、データベースをローカル冗長ストレージ (LRS) に格納することに基づいています。これにより、プライマリ リージョンの 1 つのデータセンター内でデータが 3 回コピーされ、小規模なネットワークや電源障害などのローカル障害が発生した場合にデータが保護されます。 LRS は、コストが最も安い冗長オプションであり、他のオプションと比較して持続性は最も低くなります。 火災や洪水などの大規模な災害がリージョン内で発生した場合、LRS を使っているストレージ アカウントのすべてのレプリカが失われたり、回復不能になる可能性があります。 そのため、ローカル冗長可用性オプションを使用するときにデータをさらに保護するには、データベースのバックアップに回復性の高いストレージ オプションを使用することを検討してください。 これは Hyperscale データベースには適用されません。その同じストレージがデータ ファイルとバックアップの両方に使われます。
ローカル冗長可用性は、すべてのサービス レベルのすべてのデータベースと、データ損失の量がゼロであることを示す回復ポイントの目標 (RPO) で使用できます。
Basic、Standard、General Purpose のサービス レベル
DTU ベースの購入モデルの Basic と Standard サービス レベルおよび、仮想コアベースの購入モデルの General Purpose サービス レベルでは、サーバーレス コンピューティングにもプロビジョン済みコンピューティングにもリモート記憶域の可用性モデルを使用します。 次の図は、計算レイヤーとストレージ レイヤーが分離されている4 つの異なるノードを示しています。
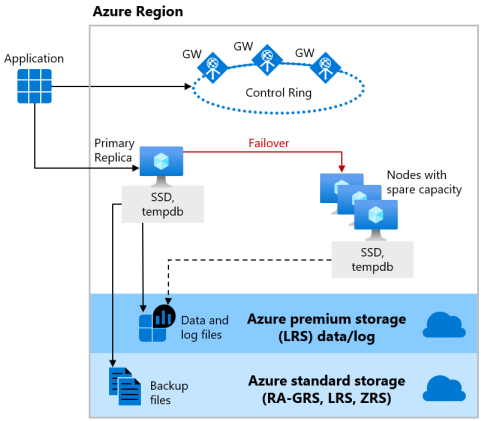
リモート ストレージの可用性モデルには、2 つのレイヤーが含まれます。
- ステートレス計算レイヤー。データベース エンジン プロセスが実行され、一時的なデータとキャッシュ データ (アタッチされた SSD 上の
tempdbとmodelデータベース、およびメモリ内のプラン キャッシュ、バッファー プール、列ストア プールなど) のみが含まれています。 このステートレス ノードは、データベース エンジンの初期化、ノードの正常性の制御、必要に応じた他のノードへのフェールオーバーの実行を行う Azure Service Fabric によって操作されます。 - ステートフル データ レイヤー。データベース ファイル (
.mdfおよび.ldf) は Azure Blob Storage に保存されています。 Azure Blob Storage には、データの可用性と冗長性の機能が組み込まれています。 データベース エンジン プロセスがクラッシュした場合でも、ログ ファイル内のすべてのレコードまたはデータ ファイル内のすべてのページが保持されることが保証されます。
データベース エンジンまたはオペレーティング システムがアップグレードされるとき、または障害が検出されたとき、Azure Service Fabric は常に、ステートレス データベース エンジン プロセスを十分な空き容量がある別のステートレス計算ノードに移動します。 Azure Blob Storage 内のデータは移動による影響を受けず、データとログ ファイルは、新しく初期化されたデータベース エンジン プロセスにアタッチされます。 このプロセスにより高い可用性が保証されますが、新しいデータベース エンジン プロセスはコールド キャッシュを使って起動されるため、負荷の高いワークロードでは移行の間にパフォーマンスが低下する可能性があります。
Premium と Business Critical のサービス レベル
DTU ベースの購入モデル の Premium サービス レベルと 仮想コアベースの購入モデル の Business Critical サービス レベルでは、ローカル記憶域の可用性モデルを使用することで、コンピューティング リソース (データベース エンジン プロセス) とストレージ (ローカルにアタッチされた SSD) を単一ノードに統合します。 高可用性は、コンピューティングとストレージの両方を追加のノードにレプリケートすることで実現されます。
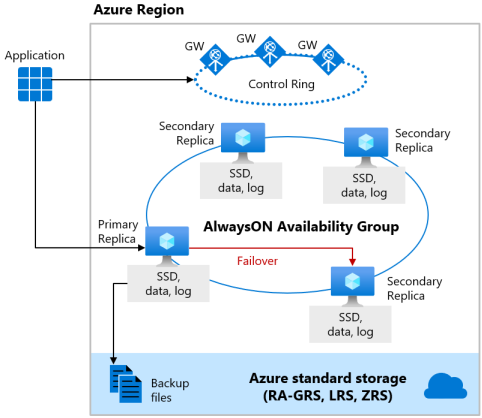
基になるデータベース ファイル (.mdf/.ldf) は、非常に低い待機時間の IO をワークロードに提供するために、アタッチされている SSD ストレージ上に配置されています。 高可用性は、SQL Server Always On 可用性グループと同様のテクノロジを使用して実装されます。 クラスターには、読み取り/書き込みの顧客ワークロードにアクセス可能な単一のプライマリ レプリカと、データのコピーを格納する最大 3 つのセカンダリ レプリカ (計算とストレージ) が含まれます。 プライマリ レプリカは、常に変更を順番にセカンダリ レプリカにプッシュし、各トランザクションをコミットする前に、十分な数のセカンダリ レプリカにデータが保持されるようにします。 このプロセスにより、何らかの理由でプライマリ レプリカまたは読み取り可能なセカンダリ レプリカがクラッシュした場合に、フェールオーバー先となる完全に同期されたノードが常に存在することが保証されます。 フェールオーバーは、Azure Service Fabric によって開始されます。 セカンダリ レプリカが新しいプライマリ レプリカになると、クォーラムを維持するのに十分な数のレプリカがクラスターに確実にあるよう、別のセカンダリ レプリカが作成されます。 フェールオーバーが完了すると、Azure SQL の接続は、新しいプライマリ レプリカまたは読み取り可能なセカンダリ レプリカに自動的にリダイレクトされます。
その他の利点として、ローカル ストレージ可用性モデルは、読み取り専用の Azure SQL 接続をセカンダリ レプリカの 1 つにリダイレクトする機能を備えています。 この機能は、読み取りスケールアウトと呼ばれます。追加料金なしで 100% の追加のコンピューティング容量を提供し、分析ワークロードなどの読み取り専用の操作をプライマリ レプリカからオフロードします。
ハイパースケール サービス レベル
Hyperscale サービス レベルのアーキテクチャについては、「分散機能アーキテクチャ」を参照してください。

Hyperscale の可用性モデルには、次の 4 つのレイヤーが含まれます。
- ステートレス計算レイヤー。データベース エンジン プロセスを実行しており、一時的なデータとキャッシュ データのみ (カバーしない RBPEX キャッシュ、
tempdb、アタッチされた SSD 上のmodelデータベースなど、メモリ内のプラン キャッシュ、バッファー プール、列ストア プールなど) が含まれています。 このステートレス レイヤーには、プライマリ計算レプリカと、必要に応じて、フェールオーバー ターゲットとして機能できる多くのセカンダリ計算レプリカが含まれています。 - ページ サーバーによって形成されるステートレス ストレージ レイヤー。 このレイヤーは、計算レプリカで実行されているデータベース エンジン プロセス用の分散ストレージ エンジンです。 各ページ サーバーには、アタッチされた SSD 上のカバーする RBPEX キャッシュ、メモリにキャッシュされたデータ ページなど、一時的なデータとキャッシュされたデータのみが含まれます。 各ページ サーバーでは、負荷分散、冗長性、高可用性を提供するためのアクティブ/アクティブ構成にペアのページ サーバーがあります。
- ステートフルなトランザクション ログのストレージ レイヤー。ログ サービス プロセス、トランザクション ログのランディング ゾーン、およびトランザクション ログの長期保存を実行する計算ノードによって形成されます。 ランディング ゾーンと長期保存では Azure Storage を使用します。これにより、トランザクション ログの可用性と冗長性が提供され、コミットされたトランザクションのデータの持続性が確保されます。
- ステートフルなデータ ストレージ レイヤー。Azure Storage に格納され、ページ サーバーによって更新される、データベース ファイル (.mdf/.ndf) が含まれます。 このレイヤーでは、Azure Storage のデータの可用性と冗長性の機能を使用します。 これにより、Hyperscale アーキテクチャの他のレイヤーのプロセスがクラッシュした場合や、計算ノードで障害が発生した場合でも、データ ファイル内のすべてのページが保持されることが保証されます。
すべての Hyperscale レイヤー内の計算ノードは、Azure Service Fabric で実行されます。これにより、各ノードの正常性が制御され、必要に応じて使用できる正常なノードへのフェールオーバーが行われます。
Hyperscale の高可用性の詳細については、「ハイパースケールでのデータベースの高可用性」を参照してください。
ゾーン冗長による高可用性
ゾーン冗長可用性により、プライマリ リージョンの 3 つの Azure 可用性ゾーンにデータが分散されます。 各可用性ゾーンは、独立した電源、冷却装置、ネットワークを備えた独立した物理的な場所です。
ゾーン冗長可用性は、仮想コアベースの購入モデルでは Business Critical、General Purpose、Hyperscale サービス レベルで使用可能で、DTU ベースの購入モデルでは Premium サービス レベルでのみ使用可能です。Basic と Standard サービス レベルではゾーン冗長がサポートされません。
サービス レベルごとにゾーン冗長の実装は違いますが、すべての実装で、フェールオーバー時にコミットされたデータが失われることはなく、回復ポイントの目標 (RPO) が保証されます。
汎用のサービス階層
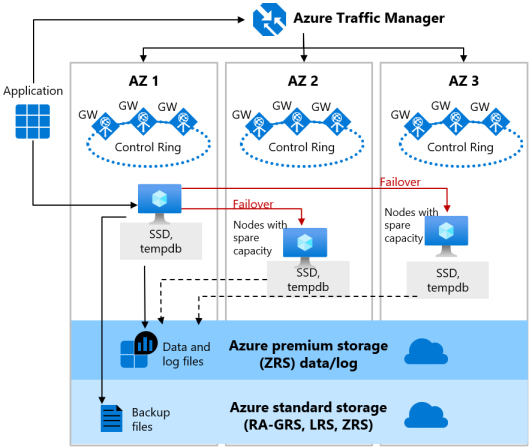
General Purpose サービス レベルのゾーン冗長構成は、仮想コア購入モデルのデータベースのサーバーレスおよびプロビジョニングのコンピューティングの両方に提供されます。 この構成では、Azure Availability Zones を利用して、Azure リージョン内の複数の物理的な場所にデータベースをレプリケートします。 ゾーン冗長を選択することで、アプリケーション ロジックを変更することなく、データセンターの壊滅的な障害などの大規模な障害に対する回復性を、新規および既存のサーバーレスおよびプロビジョニング済みの汎用単一データベースやエラスティック プールに持たせることができます。
General Purpose レベル向けのゾーン冗長構成には、次の 2 つの層があります。
- ステートフル データ レイヤー。データベース ファイル (.mdf/.ldf) は ZRS (ゾーン冗長ストレージ) に保存されています。 ZRS を使用すると、データとログのファイルは、物理的に分離された 3 つの Azure 可用性ゾーン間で同期的にコピーされます。
- ステートレス計算レイヤー。sqlservr.exe プロセスを実行しており、一時的なデータとキャッシュ データのみ (
tempdb、アタッチされた SSD 上のmodelデータベース、およびメモリ内のプラン キャッシュ、バッファー プール、列ストア プールなど) が含まれています。 このステートレス ノードは、sqlservr.exe の初期化、ノードの正常性の制御、および他のノードへのフェールオーバーを必要に応じて実行する Azure Service Fabric によって操作されます。 ゾーン冗長のサーバーレスおよびプロビジョニング済み General Purpose データベースの場合、予備の容量があるノードをフェールオーバーのために他の Availability Zones ですぐに使用できます。
ゾーン冗長による General Purpose サービス レベル向けの高可用性アーキテクチャを、次の図に示します。
General Purpose データベースをゾーン冗長で構成する場合は、次の点を考慮してください。
- General Purpose レベルのゾーン冗長構成は、次のリージョンでのみ一般提供されます。
- (アフリカ) 南アフリカ北部
- (アジア太平洋) オーストラリア東部
- (アジア太平洋) 東アジア
- (アジア太平洋) 東日本
- (アジア太平洋) 韓国中部
- (アジア太平洋) 東南アジア
- (アジア太平洋) インド中部
- (アジア太平洋) 中国北部 3
- (アジア太平洋) アラブ首長国連邦北部
- (ヨーロッパ) フランス中部
- (ヨーロッパ) ドイツ中西部
- (ヨーロッパ) イタリア北部
- (ヨーロッパ) 北ヨーロッパ
- (ヨーロッパ) ノルウェー東部
- (ヨーロッパ) ポーランド中部
- (ヨーロッパ) 西ヨーロッパ
- (ヨーロッパ) 英国南部
- (ヨーロッパ) スイス北部
- (ヨーロッパ) スウェーデン中部
- (中東) イスラエル中部
- (中東) カタール中部
- (北米) カナダ中部
- (北米) 米国東部
- (北米)米国東部 2
- (北米) 米国中南部
- (北米)米国西部 2
- (北米) 米国西部 3
- (南アメリカ) ブラジル南部
- ゾーン冗長可用性の場合、既定以外のメンテナンス期間を選択することは、現在、一部のリージョンでのみ可能です。
- ゾーン冗長構成は、標準シリーズ (Gen5) ハードウェアが選ばれている場合にのみ SQL Database で利用できます。
- ゾーン冗長は、DTU 購入モデルの Basic と Standard のサービス レベルでは使用できません。
Premium と Business Critical のサービス レベル
Premium または Business Critical サービス レベルでゾーン冗長が有効になっている場合、レプリカは同じリージョン内の異なる可用性ゾーンに配置されます。 単一障害点をなくすため、制御リングも複数のゾーンで 3 つのゲートウェイ リング (GW) として複製できます。 特定のゲートウェイ リングへのルーティングは Azure Traffic Manager によって制御されます。 Premium または Business Critical サービス レベルのゾーン冗長構成では、既存のレプリカを使用して異なる可用性ゾーンに配置されるため、追加料金なしで有効にすることができます。 ゾーン冗長構成を選ぶことで、アプリケーション ロジックにまったく変更を加えずに、データセンターの壊滅的な障害などの極めて大規模な障害に対して、Premium または Business Critical のデータベースとエラスティック プールが回復性を備えることができます。 また、既存の Premium または Business Critical のデータベースまたはエラスティック プールをゾーン冗長構成に変換することもできます。
ゾーン冗長による高可用性アーキテクチャを、次の図に示します。

Premium または Business Critical データベースをゾーン冗長で構成する場合は、次の点を考慮してください。
- ゾーン冗長データベースがサポートされているリージョンの最新情報については、「リージョン別のサービスのサポート」を参照してください。
- ゾーン冗長可用性の場合、既定以外のメンテナンス期間を選択することは、現在、一部のリージョンでのみ可能です。
ハイパースケール サービス レベル
Hyperscale サービス レベルのデータベースに対してゾーン冗長を構成することができます。 詳細については、「ゾーン冗長 Hyperscale データベースを作成する」を参照してください。
この構成を有効にすると、すべての Hyperscale レイヤーににおける Availability Zones 間のレプリケーションを通じて、ゾーン レベルの回復性が確保されます。 ゾーン冗長を選択することにより、アプリケーション ロジックを変更することなく、データセンターの壊滅的な障害など、大規模な障害に対する Hyperscale データベースの回復性を高めることができます。 Availability Zones を持つすべての Azure リージョンは、ゾーン冗長 Hyperscale データベースをサポートします。
ゾーン冗長可用性は、Hyperscale スタンドアロン データベースおよび Hyperscale エラスティック プールの両方でサポートされています。 詳細については、「Hyperscale エラスティック プール」を参照してください。
次の図は、ゾーン冗長 Hyperscale データベースの基礎となるアーキテクチャを示しています。

次の制限が適用されます。
ゾーン冗長構成は、データベースの作成時にのみ指定できます。 この設定は、リソースがプロビジョニングされた後は変更できません。 データベースのコピー、ポイントインタイム リストア、または geo レプリカの作成を使用して、既存の Hyperscale データベースのゾーン冗長構成を更新します。 これらのアップデート オプションのいずれかを使用する際に、ターゲット データベースがソースとは異なるリージョンにある場合、またはターゲット データベースのバックアップ ストレージの冗長性がソース データベースと異なる場合、コピー操作はデータ操作のサイズになります。
現在、Azure portal を使用してデータベースを Hyperscale に移行する場合、ゾーン冗長を指定するオプションはありません。 ただし、既存のデータベースを別の Azure SQL Database サービス レベルから Hyperscale に移行する場合は、Azure PowerShell、Azure CLI、または REST API を使用してゾーン冗長を指定できます。 Azure CLI の例は次のとおりです。
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant trueHyperscale のゾーン冗長構成を有効にするには、少なくとも 1 つの高可用性コンピューティング レプリカとゾーン冗長または geo ゾーン冗長のバックアップ ストレージの使用が必要です。
データベースのゾーン冗長可用性
Azure SQL Database でのサーバーは、データベースのコレクションの中央管理ポイントとして機能する論理コンストラクトです。 サーバー レベルでは、ログイン、認証方法、ファイアウォール規則、監査規則、脅威検出ポリシー、フェールオーバー グループを管理できます。 ログインやファイアウォール規則など、これらの機能の一部に関連するデータは、master データベースに格納されます。 同様に、一部の DMV (sys.resource_stats など) のデータも、master データベースに格納されます。
ゾーン冗長構成のデータベースが論理サーバーに作成されると、サーバーに関連付けられている master データベースも自動的にゾーン冗長になります。 これにより、ゾーンの障害が発生しても、ログインやファイアウォール規則などの master データベースに依存する機能は引き続き使用できるため、データベースを使用するアプリケーションは影響を受けなくなります。 master データベースをゾーン冗長にするのは非同期プロセスであり、バックグラウンドで完了するまでに時間がかかります。
サーバー上のどのデータベースもゾーン冗長でない場合、または空のサーバーを作成する場合は、サーバーに関連付けられている master データベースはゾーン冗長ではありません。
Azure PowerShell、Azure CLI、または REST API を使って、master データベースの ZoneRedundant プロパティを確認できます。
次のコマンド例を使って、master データベースの "ZoneRedundant" プロパティの値を確認します。
Get-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "myServerName" -DatabaseName "master"
アプリケーションの障害回復性のテスト
高可用性は、データベース アプリケーションに対して透過的に機能する SQL Database プラットフォームの基礎となる部分です。 しかし、計画済みまたは計画外のイベント時に開始された自動フェールオーバー操作がアプリケーションに与える影響をテストしてから、運用環境にデプロイする必要があると Microsoft は認識しています。 特別な API を呼び出してデータベースまたはエラスティック プールを再起動することにより、手動でフェールオーバーをトリガーできます。 ゾーン冗長のサーバーレスまたはプロビジョニング済み General Purpose データベースまたはエラスティック プールの場合、API 呼び出しによって、クライアント接続が、古いプライマリの可用性ゾーンとは異なる可用性ゾーン内の新しいプライマリにリダイレクトされます。 そのため、フェールオーバーが既存のデータベース セッションにどのように影響するかをテストするだけでなく、ネットワーク待機時間の変化によってエンドツーエンドのパフォーマンスを変化させるかどうかを確認することもできます。 再起動操作が影響を及ぼし、その多くがプラットフォームに負荷をかける可能性があるため、各データベースまたはエラスティック プールに対しては、15 分ごとに 1 つのフェールオーバー呼び出しのみが許可されます。
Azure SQL Database の高可用性とディザスター リカバリーの詳細については、HA と DR のチェックリストに関する記事を参照してください。
フェールオーバーは、PowerShell、REST API または Azure CLI を使用して開始できます。
| デプロイの種類 | PowerShell | REST API | Azure CLI |
|---|---|---|---|
| データベース | Invoke-AzSqlDatabaseFailover | データベース フェールオーバー | Azure CLI から REST API 呼び出しを起動するため、az rest が使用される場合があります |
| エラスティック プール | Invoke-AzSqlElasticPoolFailover | エラスティック プールのフェールオーバー | Azure CLI から REST API 呼び出しを起動するため、az rest が使用される場合があります |
重要
フェールオーバー コマンドは、ハイパースケール データベースの読み取り可能なセカンダリ レプリカでは使用できません。
まとめ
Azure SQL Database の特徴は、Azure プラットフォームと緊密に統合される、組み込みの高可用性ソリューションです。 障害の検出と復旧に Service Fabric を、データ保護に Azure Blob ストレージを、フォールト トレランスを高めるために Availability Zones を活用しています。 さらに、SQL Database は、データの同期とフェールオーバーのために、SQL Server の Always On 可用性グループ テクノロジを使っています。 これらのテクノロジを組み合わせることで、アプリケーションは混合ストレージ モデルを最大限に活用し、最も要求の厳しい SLA に対応できます。
関連するコンテンツ
詳細については、次を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示