Azure の SQL データ同期とは
適用対象: ![]() Azure SQL データベース
Azure SQL データベース
重要
SQL データ同期 は、2027 年 9 月 30 日に廃止される予定です。 代替のデータ レプリケーション/同期ソリューションへの移行を検討してください。
SQL データ同期は、Azure SQL Database 上に構築されているサービスであり、選択したデータをオンプレミスおよびクラウドの複数のデータベース間で双方向に同期させることができます。
SQL データ同期は、Azure SQL Managed Instance または Azure Synapse Analytics をサポートしていません。
概要
データ同期は、同期グループの概念に基づいています。 同期グループは、同期するデータベースのグループです。
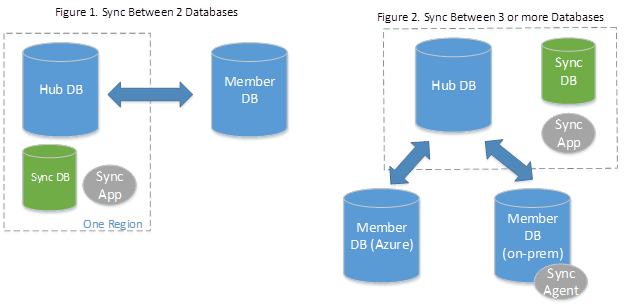
データ同期は、データを同期するために、ハブとスポークのトポロジを使用します。 同期グループ内のいずれかのデータベースを、ハブ データベースとして定義します。 他のデータベースは、メンバー データベースです。 同期は、ハブと個々のメンバー間でのみ発生します。
- ハブ データベースは、Azure SQL Database にする必要があります。
- メンバー データベースにできるのは、Azure SQL Database 内のデータベースか、SQL Server のインスタンス内のデータベースです。
- 同期メタデータ データベースには、データ同期のメタデータとログが含まれています。同期メタデータ データベースは、ハブ データベースと同じリージョンにある Azure SQL Database である必要があります。 同期メタデータ データベースは、お客様が作成し、所有します。 同期メタデータ データベースは、リージョンおよびサブスクリプションごとに 1 つだけ作成できます。 同期グループまたは同期エージェントが存在する間は、同期メタデータ データベースを削除したり、名前を変更したりすることはできません。 Microsoft では、同期メタデータ データベースとして使用する新しい空のデータベースを作成することをお勧めしています。 データ同期は、このデータベースにテーブルを作成し、頻繁に発生するワークロードを実行します。
Note
オンプレミスのデータベースをメンバー データベースとして使用している場合は、ローカル同期エージェントをインストールして構成する必要があります。
同期グループには、次のプロパティがあります。
- 同期スキーマは、どのデータが同期されるかについて説明します。
- 同期の方向は、双方向にするか、一方向だけのフローにすることができます。 つまり、同期の方向は、" [Hub to Member](ハブからメンバーへ) " または " [Member to Hub](メンバーからハブへ) "、あるいはその両方にすることができます。
- 同期間隔は、同期が発生する頻度を示します。
- 競合解決ポリシーは、グループ レベルのポリシーであり、 [ハブ側に合わせる] と [Member wins](メンバー側に合わせる) のどちらかにすることができます。
使用する場合
データ同期は、Azure SQL Database または SQL Server の複数のデータベースにわたってデータを更新し続ける必要がある場合に便利です。 以下に、データ同期の主なユース ケースを示します。
- ハイブリッド データ同期: データ同期を使って、SQL Server および Azure SQL Database のデータベース間でデータの同期を維持し、ハイブリッド アプリケーションを実現できます。 この機能は、クラウドに移行して一部のアプリケーションを Azure に配置することを検討している顧客にとって魅力的な場合があります。
- 分散アプリケーション: 多くの場合、ワークロードが異なるのであればデータベースも分離しておくと便利です。 たとえば、大規模な運用データベースがあり、このデータに対するレポートまたは分析ワークロードを実行する必要がある場合は、この追加のワークロード用に 2 つ目のデータベースを用意すると便利です。 そうすることで、運用ワークロードのパフォーマンスへの影響を最低限にすることができます。 データ同期を使えば、この 2 つのデータベースの同期を維持することができます。
- グローバル分散アプリケーション: 多くの企業は、複数のリージョン、さらには複数の国/リージョンにわたって展開しています。 ネットワーク待ち時間を最小限にするには、データは最寄りのリージョンに配置するのが一番です。 データ同期では、世界中のリージョンのデータベースを簡単に同期させることができます。
データ同期は、次のシナリオに適したソリューションではありません。
| シナリオ | 推奨されるソリューション例 |
|---|---|
| ディザスター リカバリー | Azure SQL Database の自動バックアップ |
| 読み取りスケール | 読み取り専用レプリカを使用して読み取り専用クエリ ワークロードをオフロードする |
| ETL (OLTP から OLAP へ) | Azure Data Factory または SQL Server Integration Services |
| SQL Server から Azure SQL Database への移行。 ただし、移行の完了後に SQL データ同期を使用して、ソースとターゲットの同期を確実に維持することができます。 | Azure Database Migration Service |
しくみ
- データ変更の追跡: データ同期では、挿入、更新、および削除の 3 種類のトリガーを使用して変更を追跡します。 変更はユーザー データベースのサイド テーブルに記録されます。 既定では BULK INSERT はトリガーを起動しません。 FIRE_TRIGGERS が指定されていない場合は、INSERT トリガーは実行しません。 データ同期がこれらの INSERT を追跡できるように、FIRE_TRIGGERS オプションを追加します。
- データの同期: データ同期は、ハブとスポークのモデルで設計されています。 ハブは、各メンバーと個別に同期されます。 ハブの変更がメンバーにダウンロードされ、次にメンバーの変更がハブにアップロードされます。
- 競合の解決: データ同期には、競合を解決するために、 [ハブ側に合わせる] と [Member wins] (メンバー側に合わせる) という 2 つのオプションが用意されています。
- [ハブ側に合わせる] を選択すると、ハブでの変更が常にメンバーでの変更を上書きします。
- [Member wins](メンバー側に合わせる) を選択すると、メンバーでの変更がハブでの変更を上書きします。 複数のメンバーがある場合、最終的な値は、どのメンバーが最初に同期されるかによって異なります。
トランザクション レプリケーションとの比較
| データ同期 | トランザクション レプリケーション | |
|---|---|---|
| 長所 | - アクティブ/アクティブのサポート - オンプレミスと Azure SQL Database 間で双方向 |
- 待ち時間の短縮 - トランザクションの整合性 - 移行後に既存トポロジの再利用 \- Azure SQL Managed Instance のサポート |
| 短所 | - トランザクションの整合性なし - パフォーマンスへの影響が大きい |
- Azure SQL データベースからは発行できません - 高いメンテナンス コスト |
データ同期用のプライベート リンク
Note
SQL データ同期のプライベート リンクは、Azure Private Link とは異なります。
新しいプライベート リンク機能を使用すると、サービス マネージド プライベート エンドポイントを選択して、データの同期処理中に同期サービスとメンバー/ハブ データベースの間にセキュリティで保護された接続を確立できます。 サービス マネージド プライベート エンドポイントは、特定の仮想ネットワークおよびサブネット内のプライベート IP アドレスです。 データ同期では、サービス マネージド プライベート エンドポイントが Microsoft によって作成され、特定の同期操作でデータ同期サービスによって排他的に使用されます。
プライベート リンクを設定する前に、この機能の一般的な要件を確認してください。

Note
同期グループのデプロイ中に Azure portal の [プライベート エンドポイント接続] ページで、または PowerShell を使用して、サービス マネージド プライベート エンドポイントを手動で承認する必要があります。
はじめに
Azure portal でのデータ同期の設定
- チュートリアル:Azure SQL Database と SQL Server のデータベース間の SQL データ同期を設定する
- Data Sync Agent - SQL データ同期の Data Sync Agent
PowerShell を使用したデータ同期の設定
- PowerShell を使用して Azure SQL Database の複数データベース間でデータを同期する
- PowerShell を使用して SQL Database と SQL Server の間でデータの同期
REST API を使用したデータ同期の設定
データ同期のベスト プラクティスの確認
何か問題が起きた場合
一貫性とパフォーマンス
最終的な一貫性
データ同期はトリガー ベースであるため、トランザクションの一貫性は保証されません。 Microsoft では、最終的にはすべての変更が行われることと、データ同期でデータ損失が発生しないことを保証しています。
パフォーマンスへの影響
データ同期では、挿入、更新、および削除の 3 種類のトリガーを使用して変更を追跡します。 これにより、ユーザー データベース内に変更追跡のためのサイド テーブルが作成されます。 これらの変更追跡アクティビティは、データベースのワークロードに影響します。 サービス層を評価し、必要な場合はアップグレードします。
同期グループの作成、更新、削除中のプロビジョニングとプロビジョニング解除は、データベースのパフォーマンスにも影響を与える場合があります。
要件と制限事項
一般的な要件
- 各テーブルには主キーが必要です。 どの行の主キーも値を変更しないでください。 主キーの値を変更する必要がある場合は、行を削除し、新しい主キー値で作成し直してください。
重要
既存の主キーの値を変更すると、次の動作不良が生じます。
- 同期の問題がレポートされなくても、ハブとメンバーとの間でデータの損失が生じる可能性があります。
- 同期に失敗する可能性があります。主キーの変更で、追跡しているテーブルに、同期元からの存在しない行が含まれることが原因です。
同期のメンバーとハブの両方に対してスナップショット分離を有効にする必要があります。 詳しくは、「SQL Server でのスナップショット分離」をご覧ください。
データ同期でプライベート リンクを使用するには、メンバーとハブの両方のデータベースが、同じ種類のクラウド (パブリック クラウドまたは政府のクラウド) で、Azure (同じリージョンまたは異なるリージョン) でホストされている必要があります。 また、プライベート リンクを使用するには、ハブ サーバーとメンバー サーバーをホストするサブスクリプションに対して、
Microsoft.Networkリソース プロバイダーを登録する必要があります。 最後に、同期構成中、Azure portal の [プライベート エンドポイント接続] セクション内で、または PowerShell を使用して、データ同期用にプライベート リンクを手動で承認する必要があります。 プライベート リンクを承認する方法の詳細については、「チュートリアル: Azure SQL テータベースと SQL Server のデータベース間に SQL データ同期の設定」を参照してください。 サービス マネージド プライベート エンドポイントを承認すると、同期サービスとメンバー/ハブ データベース間のすべての通信がプライベート リンクを介して行われます。 既存の同期グループを更新して、この機能を有効にすることができます。
一般的な制限事項
- テーブルに、主キー以外の ID 列を設けることはできません。
- 主キーには、次のデータ型を含めることはできません: sql_variant、binary、varbinary、image、xml。
- サポートされている精度は秒単位のみのため、次のデータ型を主キーとして使用するときは注意してください: time、datetime、datetime2、datetimeoffset。
- オブジェクト (データベース、テーブル、および列) の名前には、印刷可能な文字のピリオド (
.)、左角かっこ ([)、または右角かっこ (]) を使用できません。 - テーブル名に印刷可能文字を含めることはできません:
! " # $ % ' ( ) * + -またはスペース。 - Microsoft Entra (旧 Azure Active Directory) 認証はサポートされていません。
- 名前が同じでスキーマが異なるテーブル (たとえば
dbo.customersとsales.customers) がある場合は、一方のテーブルのみを同期に追加できます。 - ユーザー定義データ型の列はサポートされていません。
- 異なるサブスクリプション間でのサーバーの移動はサポートされていません。
- 2 つの主キーでケースだけが違っている (例:
Fooとfoo) 場合、データ同期ではこのシナリオがサポートされません。 - テーブルの切り捨ては、データ同期でサポートされている操作ではありません (変更は追跡されません)。
- Azure SQL Hyperscale データベースをハブまたは同期メタデータ データベースとして使用する機能はサポートされていません。 ただし、Hyperscale データベースは、データ同期トポロジ内のメンバー データベースになることができます。
- メモリ最適化テーブルはサポートされません。
- スキーマ変更は自動的にはレプリケートされません。 カスタム ソリューションを作成して、スキーマ変更のレプリケーションを自動化できます。
- データ同期では、次の 2 つのインデックス プロパティのみがサポートされています: Unique、Clustered/Non-Clustered。
IGNORE_DUP_KEYまたはWHEREフィルター述語など、インデックスのその他のプロパティはサポートされておらず、ソース インデックスにこれらのプロパティが設定されていても、同期先インデックスはこれらのプロパティなしでプロビジョニングされます。 - さらに、Azure Elastic ジョブ データベースを SQL データ同期メタデータ データベースとして使用することはできません。その逆も同様です。
- SQL データ同期はレジャー データベースではサポートされていません。
サポートされていないデータ型
- FileStream
- SQL/CLR UDT
- XMLSchemaCollection (XML サポート)
- Cursor、RowVersion、Timestamp、Hierarchyid
サポートされていない列の種類
データ同期では、読み取り専用の列またはシステムで生成された列は同期できません。 次に例を示します。
- 計算列。
- テンポラル テーブル用にシステムで生成された列。
サービスとデータベースの数量に関する制限
| Dimensions | 制限 | 回避策 |
|---|---|---|
| データベースが属することができる同期グループの最大数。 | 5 | |
| 1 つの同期グループ内のエンドポイントの最大数 | 30 | |
| 1 つの同期グループ内のオンプレミス エンドポイントの最大数。 | 5 | 複数の同期グループを作成する |
| データベース、テーブル、スキーマ、および列名の文字数 | 名前 1 件あたり 50 文字 | |
| 同期グループ内のテーブル数 | 500 | 複数の同期グループを作成する |
| 同期グループ内のテーブルの列数 | 1000 | |
| テーブルでのデータ行のサイズ | 24 Mb |
Note
同期グループが 1 つのみの場合、1 つの同期グループに最大 30 個のエンドポイントを持つことができます。 同期グループが 2 つ以上ある場合は、すべての同期グループでのエンドポイントの合計数が最大 30 個に制限されます。 データベースが複数の同期グループに属している場合、それは 1 つではなく、複数のエンドポイントとしてカウントされます。
ネットワークの要件
注意
同期プライベート リンクを使用する場合、これらのネットワーク要件は適用されません。
同期グループが確立されるときに、データ同期サービスはハブ データベースに接続する必要があります。 同期グループを確立する場合、Azure SQL サーバーの Firewalls and virtual networks 設定は次のように構成されている必要があります。
- [Deny public network access](パブリック ネットワーク アクセスの拒否) は、"オフ" に設定する必要があります。
- [Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] は、"はい" に設定する必要があります。または、[IP addresses used by Data Sync service](データ同期サービスによって使用される IP アドレス) に IP 規則を作成する必要があります。
同期グループが作成され、プロビジョニングされたら、これらの設定を無効にできます。 同期エージェントは、ハブ データベースに直接接続します。また、サーバーのファイアウォール IP 規則またはプライベート エンドポイントを使用して、エージェントがハブ サーバーにアクセスできるよう許可します。
Note
同期グループのスキーマ設定を変更する場合は、ハブ データベースを再プロビジョニングできるように、データ同期サービスがサーバーに再度アクセスすることを許可する必要があります。
リージョンのデータ所在地
同じリージョン内のデータを同期する場合、SQL データ同期では、サービス インスタンスがデプロイされているリージョン外部での顧客データの格納または処理は行われません。 異なるリージョン間でデータを同期すると、SQL データ同期は顧客データをペアになっているリージョンにレプリケートします。
SQL データ同期に関する FAQ
SQL データ同期サービスのコストはどのくらいですか?
SQL データ同期サービスそのものに対しては課金されません。 ただし、SQL データベース インスタンスへの、またはインスタンスからのデータ移動には、データ転送の料金がかかります。 詳細については、データ転送の料金に関するページを参照してください。
データ同期はどのリージョンでサポートされていますか?
SQL データ同期はすべてのリージョンでご利用いただけます。
SQL Database アカウントは必要ですか?
はい。 ハブ データベースをホストするには、SQL Database アカウントが必要です。
データ同期を使用して、SQL Server データベースのみの間で同期できますか?
直接無効にすることはできません。 しかし、Azure でハブ データベースを作成し、オンプレミス データベースを同期グループに追加することで、SQL Server データベース間で間接的に同期できます。
データ同期を構成して、異なるサブスクリプションに属している Azure SQL Database のデータベース間で同期できますか?
はい。 サブスクリプションが異なるテナントに属している場合でも、異なるサブスクリプションによって所有されているリソース グループに属するデータベース間で同期を構成できます。
- サブスクリプションが同じテナントに属していて、すべてのサブスクリプションへのアクセス許可がある場合、Azure portal 上で同期グループを構成できます。
- それ以外の場合、PowerShell を使用して、同期メンバーを追加する必要があります。
データ同期を設定して、異なるクラウド (Azure パブリック クラウドおよび 21Vianet による Azure など) に属している SQL Database のデータベース間で同期できますか?
はい。 異なるクラウドに属しているデータベース間で同期を設定できます。 異なるサブスクリプションに属している同期メンバーを追加する場合は、PowerShell を使用する必要があります。
データ同期を使用して、実稼働データベースから空のデータベースにデータをシードし、同期することはできますか?
はい。 元のデータベースからスクリプトを作成することで、新しいデータベース内にスキーマを手動で作成します。 スキーマを作成した後で、同期グループにテーブルを追加し、データをコピーして同期を維持します。
データベースをバックアップおよび復元するには、SQL データ同期を使う必要がありますか?
SQL データ同期を使ってデータのバックアップを作成することはお勧めできません。 SQL データ同期の同期はバージョン管理されていないため、バックアップして特定の時点に復元することはできません。 さらに、SQL データ同期を使用すると、ストアド プロシージャなどの他の SQL オブジェクトがバックアップされないため、復元操作に相当する処理を迅速に行うことはできません。
推奨される 1 つのバックアップ方法については、「トランザクション上一貫性のある Azure SQL データベースにあるデータベースのコピーの作成」を参照してください。
データ同期によって、暗号化されたテーブルと列を同期できますか?
- データベースが [Always Encrypted (常に暗号化)] を使用する場合、暗号化されていないテーブルおよび列のみを同期できます。 データ同期はデータを暗号化解除できないため、暗号化された列を同期することはできません。
- 列が列レベルの暗号化 (CLE) を使用している場合、行サイズが 24 Mb の最大サイズより小さい場合に限り、列を同期できます。 データ同期は、鍵によって暗号化された列 (CLE) を通常のバイナリ データとして処理します。 他の同期メンバーのデータを暗号化解除するには、同じ証明書を持っている必要があります。
SQL データ同期では照合順序はサポートされていますか?
はい。 SQL データ同期は、次のシナリオで照合順序の設定をサポートします。
- 選んだ同期スキーマ テーブルがハブまたはメンバー データベースにまだない場合、同期グループを展開すると、サービスは空の展開先データベースで選ばれている照合順序の設定を使って、対応するテーブルと列を自動的に作成します。
- 同期対象のテーブルがハブとメンバー データベースの両方に既に存在する場合は、SQL データ同期で同期グループを正常に展開するには、ハブとメンバー データベースで主キー列の照合順序が同じである必要があります。 主キー列以外の列に対して照合順序の制限はありません。
SQL データ同期ではフェデレーションはサポートされていますか?
フェデレーション ルート データベースは、SQL データ同期サービスで制限なしに使うことができます。 現在のバージョンの SQL データ同期には、フェデレーション データベースのエンドポイントを追加できません。
データ同期を使用して、Dynamics 365 からエクスポートされたデータを、独自データベースの持ち込み (BYOD) 機能によって同期することはできますか?
管理者は、Dynamics 365 の独自データベースの持ち込み機能を使用して、データ エンティティをアプリケーションから自分の Microsoft Azure SQL Database にエクスポートできます。 増分プッシュを使用してデータをエクスポートし (完全プッシュはサポートされていません)、かつ [ターゲット データベースのトリガーを有効にする] を [はい] に設定している場合、データ同期を使用してこのデータを他のデータベースに同期することができます。
ディザスター リカバリーをサポートするためにフェールオーバー グループに Microsoft SQL データ同期を作成する操作方法はどのようなものですか?
- フェールオーバー リージョンのデータ同期操作がプライマリ リージョンと同等にするために、フェールオーバー後、プライマリ リージョンと同じ設定を使用してフェールオーバー リージョンに同期グループを手動で再作成する必要があります。
関連するコンテンツ
同期されたデータベースのスキーマの更新
同期グループ内のデータベースのスキーマを更新する必要がある場合、 スキーマ変更は自動的にはレプリケートされません。 いくつかのソリューションについては、次の記事を参照してください。
監視とトラブルシューティング
SQL データ同期が想定どおりに行われているかどうかを確認したい場合に、 アクティビティを監視して問題のトラブルシューティングを行うには、次の記事を参照してください。
- Azure Monitor ログによる SQL データ同期の監視
- Troubleshoot issues with Azure SQL Data Sync (Azure SQL データ同期に関する問題のトラブルシューティング)
Azure SQL Database の詳細
Azure SQL Database の詳細については、以下の記事を参照してください。