このチュートリアルでは、Azure Batch ワークロードを実行する Azure Data Factory パイプラインの作成と実行について説明します。 Python スクリプトは Batch ノードで実行され、Azure Blob Storage コンテナーからコンマ区切り値 (CSV) の入力を取得し、データを操作し、出力を別のストレージ コンテナーに書き込みます。 Batch Explorer を使用して Batch プールとノードを作成し、Azure Storage Explorer を使用してストレージ コンテナーとファイルを操作します。
このチュートリアルでは、以下の内容を学習します。
- Batch Explorer を使用して Batch プールとノードを作成する。
- Storage Explorer を使用してストレージ コンテナーを作成し、入力ファイルをアップロードする。
- 入力データを操作して出力を生成する Python スクリプトを開発する。
- Batch ワークロードを実行する Data Factory パイプラインを作成する。
- Batch Explorer を使用して、出力ログ ファイルを確認する。
前提条件
- アクティブなサブスクリプションが含まれる Azure アカウント。 アカウントがない場合は、無料アカウントを作成してください。
- Batch アカウントおよびリンクされた Azure Storage アカウント。 アカウントを作成するには、Azure CLI | Azure portal | Bicep | ARM テンプレート | Terraform のいずれかを使用します。
- Data Factory インスタンス。 データ ファクトリを作成するには、「データ ファクトリを作成する」の手順に従います。
- Batch Explorer をダウンロードしてインストールする。
- Storage Explorer をダウンロードしてインストールする。
-
Python 3.8 以降。
pipを使用して azure-storage-blob パッケージがインストールされていること。 - GitHub からダウンロードした iris.csv 入力データセット。
Batch Explorer を使用して Batch プールとノードを作成する
Batch Explorer を使用して、ワークロードを実行するコンピューティング ノードのプールを作成します。
ご自分の Azure 資格情報を使用して、Batch Explorer にサインインします。
Batch アカウントを選択します。
左側のサイドバーで [プール] を選択し、+ アイコンを選択してプールを追加します。
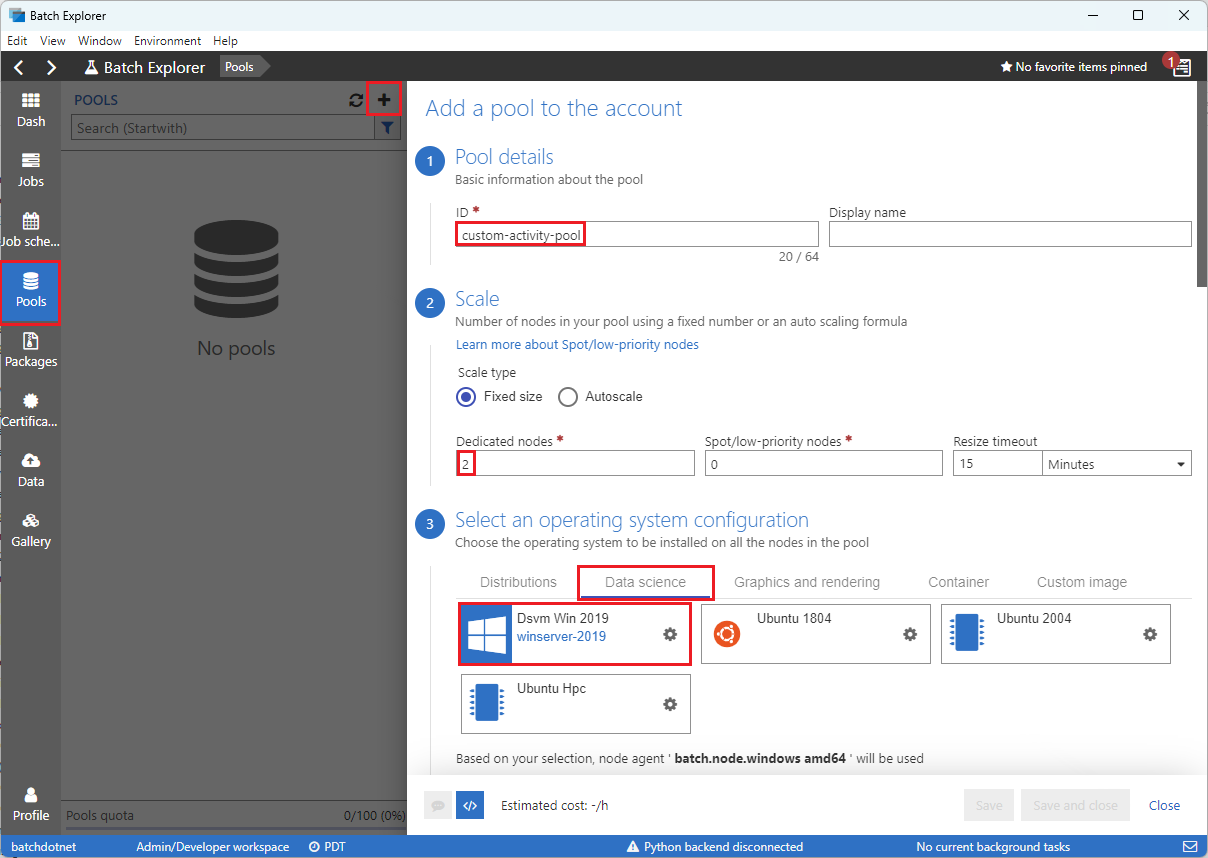
[Add a pool to the account] (アカウントにプールを追加する) フォームに次のように入力します。
- ID の下に「custom-activity-pool」と入力します。
- [Dedicated nodes] (専用ノード) に「2」と入力します。
- [Select an operating system configuration] (オペレーティング システム構成の選択) で、[Data science] (データ サイエンス) タブを選択し、[Dsvm Win 2019] を選択します。
- [Choose a virtual machine size] (仮想マシンのサイズの選択) で、[Standard_F2s_v2] を選択します。
-
[Start Task] (開始タスク) で、[Add a start task] (開始タスクの追加) を選択します。
開始タスクの画面の [コマンド ライン] に「
cmd /c "pip install azure-storage-blob pandas"」と入力し、[選択] を選びます。 このコマンドは、各ノードの起動時にazure-storage-blobパッケージをインストールします。
[保存して閉じる] を選びます。

Storage Explorer を使用して BLOB コンテナーを作成する
Storage Explorer を使用して、入力ファイルと出力ファイルを格納する BLOB コンテナーを作成し、入力ファイルをアップロードします。
- ご自分の Azure 資格情報を使用して、Storage Explorer にサインインします。
- 左側のサイドバーで、Batch アカウントにリンクされているストレージ アカウントを見つけて展開します。
- [BLOB コンテナー] を右クリックし、[BLOB コンテナーの作成] を選択するか、サイドバーの下部にある [アクション] から [BLOB コンテナーの作成] を選択します。
- 入力フィールドに「input」と入力します。
- output という名前の別の BLOB コンテナーを作成します。
- input コンテナーを選択し、右側のウィンドウで [アップロード]>[ファイルのアップロード] を選択します。
- [ファイルのアップロード] 画面の [選択したファイル] で、エントリ フィールドの横にある省略記号 [...] を選択します。
- ダウンロードした iris.csv ファイルの場所を参照し、[開く] を選択してから、[アップロード] を選びます。

Python スクリプトを開発する
次の Python スクリプトは、Storage Explorer の input コンテナーから iris.csv データセット ファイルを読み込み、データを操作し、結果を output コンテナーに保存します。
このスクリプトでは、Batch アカウントにリンクされている Azure Storage アカウントの接続文字列を使用する必要があります。 接続文字列を取得するには、次のようにします。
- Azure portal で、Batch アカウントにリンクされているストレージ アカウントの名前を検索して選択します。
- ストレージ アカウントのページで、左側のナビゲーションの [セキュリティとネットワーク] の下にある [アクセス キー] を選択します。
- [キー 1] の [接続文字列] の横にある [表示] を選択し、[コピー] アイコンを選択して接続文字列をコピーします。
接続文字列を次のスクリプトに貼り付け、<storage-account-connection-string> プレースホルダーを置き換えます。 スクリプトを main.py という名前のファイルとして保存します。
重要
運用環境で使用する場合は、アプリ ソースでアカウント キーを公開することはお勧めしません。 資格情報へのアクセスを制限し、コード内で変数または構成ファイルを使用して参照する必要があります。 Batch アカウントとストレージ アカウントのキーを Azure Key Vault に格納することをお勧めします。
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Azure Blob Storage の操作の詳細については、「Azure Blob Storage のドキュメント」」を参照してください。
スクリプトをローカルで実行して、機能をテストおよび検証します。
python main.py
スクリプトにより、Species = setosa を持つデータ レコードのみを含む iris_setosa.csv という名前の出力ファイルが生成されます。 正しく動作することを確認したら、main.py スクリプト ファイルを Storage Explorer の input コンテナーにアップロードします。
Data Factory パイプラインを設定する
Python スクリプトを使用する Data Factory パイプラインを作成して検証します。
アカウント情報の取得
この Data Factory パイプラインでは、Batch アカウントとストレージ アカウントの名前、アカウント キーの値、Batch アカウントのエンドポイントが使用されます。 この情報を Azure portal から取得するには、次のようにします。
Azure の検索バーで、Batch アカウント名を検索して選択します。
Batch アカウント ページで、左側のナビゲーションから [キー] を選択します。
[キー] ページで、次の値をコピーします。
- バッチアカウント
- アカウントエンドポイント
- プライマリ アクセス キー
- Storage account name (ストレージ アカウント名)
- Key1
パイプラインを作成して実行する
Azure Data Factory Studio がまだ実行されていない場合は、Azure portal の [Data Factory] ページで [Studio の起動] を選択します。
Data Factory Studio で、左側のナビゲーションにある [作成] の鉛筆アイコンを選択します。
[ファクトリのリソース] で、+ アイコンを選択し、[パイプライン] を選択します。
右側の [プロパティ] ペインで、パイプラインの名前を「Run Python」に変更します。
![[パイプラインの追加] を選択た後の Data Factory Studio のスクリーンショット。](media/run-python-batch-azure-data-factory/create-pipeline.png)
[アクティビティ] ペインで [Batch サービス] を展開し、パイプライン デザイナー画面に [カスタム] アクティビティをドラッグします。
デザイナー キャンバスの下の [全般] タブで、[名前] に 「testPipeline」と入力します。
![パイプライン タスクを作成するための [全般] タブのスクリーンショット。](media/run-python-batch-azure-data-factory/create-custom-task.png)
[Azure Batch] タブを選んでから、[新規] を選びます。
[新しいリンク サービス] フォームに次のように入力します。
- 名前: リンク サービスの名前 (AzureBatch1 など) を入力します。
- アクセス キー: Batch アカウントからコピーしたプライマリ アクセス キーを入力します。
- アカウント名: Batch アカウント名を入力します。
-
Batch URL: Batch アカウントからコピーしたアカウント エンドポイントを入力します (
https://batchdotnet.eastus.batch.azure.comなど)。 - プール名: Batch Explorer で作成したプール custom-activity-pool を入力します。
- ストレージ アカウントのリンク サービス名: [新規] を選択します。 次の画面で、リンクされたストレージ サービスの [名前] として AzureBlobStorage1 などを入力し、Azure サブスクリプションとリンクされたストレージ アカウントを選択し、[作成] を選びます。
Batch の [新しいリンク サービス] 画面の下部にある [接続のテスト] を選択します。 検証が成功したら、[作成] を選択します
![Batch ジョブの [新しいリンク サービス] 画面のスクリーンショット。](media/run-python-batch-azure-data-factory/integrate-pipeline-with-azure-batch.png)
[設定] タブを選択し、次の設定を入力または選択します。
-
コマンド: 「
cmd /C python main.py」と入力します。 - リソースのリンク サービス: 作成したリンクされたストレージ サービス (AzureBlobStorage1 など) を選択し、接続をテストして成功することを確認します。
- フォルダー パス: フォルダー アイコンを選択し、input コンテナーを選択して [OK] を選択します。 このフォルダーのファイルは、Python スクリプトが実行される前に、コンテナーからプール ノードにダウンロードされます。
![Batch ジョブの [設定] タブのスクリーンショット。](media/run-python-batch-azure-data-factory/create-custom-task-py-script-command.png)
-
コマンド: 「
パイプライン ツール バーの [検証] を選択してパイプラインを検証します。
[デバッグ] を選択してパイプラインをテストし、正しく動作することを確認します。
[すべて発行] を選択して、パイプラインを公開します。
[トリガーの追加] を選択し、[Trigger now] (今すぐトリガー) を選択してパイプラインを実行するか、[New/Edit] (新規/編集) を選択してスケジュールします。
![Data Factory の [検証]、[デバッグ]、[すべて発行]、[トリガーの追加] の選択のスクリーンショット。](media/run-python-batch-azure-data-factory/create-custom-task-py-success-run.png)
![[パイプラインの追加] を選択た後の Data Factory Studio のスクリーンショット。](media/run-python-batch-azure-data-factory/create-pipeline.png#lightbox)
Batch Explorer を使用してログ ファイルを表示する
パイプラインを実行すると警告またはエラーが発生する場合は、Batch Explorer を使用して、stdout.txt と stderr.txt の出力ファイルで詳細を確認できます。
- Batch Explorer で、左側のサイドバーから [ジョブ] を選択します。
- adfv2-custom-activity-pool ジョブを選択します。
- 失敗の終了コードがあるタスクを選びます。
- stdout.txt と stderr.txt ファイルを表示し、問題を調査して診断します。
リソースをクリーンアップする
Batch アカウント、ジョブ、タスクは無料ですが、コンピューティング ノードはジョブを実行していない場合でも料金が発生します。 ノード プールは、必要な場合にのみ割り当て、終了したら削除することをお勧めします。 プールを削除すると、ノード上のすべてのタスク出力とノード自体が削除されます。
入力ファイルと出力ファイルはストレージ アカウントに残り、料金が発生する可能性があります。 ファイルが不要になったら、ファイルまたはコンテナーを削除できます。 Batch アカウントまたはリンクされたストレージ アカウントが不要になった場合は、削除できます。
次のステップ
このチュートリアルでは、Batch Explorer、Storage Explorer、および Data Factory で Python スクリプトを使用して Batch ワークロードを実行する方法について説明しました。 Data Factory の詳細については、「Azure Data Factory とは何ですか」を参照してください。