適用対象: Azure Data Factory
Azure Data Factory Azure Synapse Analytics
Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
ビッグ データの世界では、未整理の生データは、多くの場合、リレーショナル、非リレーショナル、その他のストレージ システム内に格納されます。 ただし、生データ自体には、アナリストや、データ サイエンティスト、管理職意思決定者に有用な分析を提供するのに必要となる正しいコンテキストや意味はありません。
ビッグ データには、これらの膨大な量の生データをアクションにつながるビジネス分析へと精製するプロセスを統合および運用化できるサービスが必要です。 Azure Data Factoryは、これらの複雑なハイブリッド抽出-変換-読み込み (ETL)、抽出-読み込み変換 (ELT)、およびデータ統合プロジェクト用に構築されたマネージド クラウド サービスです。
Azure Data Factoryの機能
データ圧縮: データ Copy activity中に、データを圧縮し、圧縮されたデータをターゲット データ ソースに書き込む可能性があります。 この機能は、データ コピーでの帯域幅の使用を最適化するのに役立ちます。
さまざまなデータ ソースに対する広範な接続のサポート: Azure Data Factoryでは、さまざまなデータ ソースに接続するための広範な接続サポートが提供されます。 これは、さまざまなデータ ソースからデータをプルまたは書き込む場合に便利です。
カスタム イベント トリガー: Azure Data Factoryを使用すると、カスタム イベント トリガーを使用してデータ処理を自動化できます。 この機能を使用すると、特定のイベントが発生したときに特定のアクションを自動的に実行できます。
データのプレビューと検証: データコピー活動中に、データをプレビューおよび検証するためのツールが提供されます。 この機能は、データが正しくコピーされ、ターゲット データ ソースに正しく書き込まれることを確認するのに役立ちます。
カスタマイズ可能なデータ フロー: Azure Data Factoryを使用すると、カスタマイズ可能なデータ フローを作成できます。 この機能を使用すると、データ処理用のカスタム アクションまたはステップを追加できます。
統合セキュリティ: Azure Data Factoryは、データフローへのアクセスを制御するためのEntra ID統合やロールベースのアクセス制御などの統合されたセキュリティ機能を提供します。 この機能により、データ処理のセキュリティが強化され、データが保護されます。
使用シナリオ
たとえば、クラウド内のゲームで生成される、数ペタバイト規模のゲーム ログを収集するゲーム会社があるとします。 その会社がこれらのログを分析して顧客の好みや内訳、利用行動などについての洞察を得たいと考えているとしましょう。 また同社は、アップセルやクロス セルの商機の見極め、魅力的な新機能の開発、ビジネスの成長の後押し、カスタマー エクスペリエンスの向上にも興味があります。
これらのログを分析するには、顧客情報やゲーム情報、マーケティング キャンペーン情報など、オンプレミスのデータ ストアにある参照データを使用する必要があります。 この会社は、オンプレミスのデータ ストアにあるこれらのデータを、クラウドのデータ ストアにある追加のログ データと統合して活用しようと考えています。
分析情報を抽出するには、クラウド内の Spark クラスター (Azure HDInsight) を使用して結合されたデータを処理し、変換されたデータをクラウド データ ウェアハウス (Azure Synapse Analytics など) に発行して、その上に簡単にレポートを作成したいと考えています。 このワークフローを自動化し、日単位のスケジュールに従って監視、管理することが目標となります。 それを実行するタイミングは、BLOB ストア コンテナーにファイルが到着したときとします。
Azure Data Factoryは、このようなデータ シナリオを解決するプラットフォームです。 クラウドベースの ETL およびデータ統合サービスを通じて、データの移動と変換を大規模に制御するデータ ドリブンのワークフローを作成できます。 Azure Data Factoryを使用すると、さまざまなデータ ストアからデータを取り込むことができるデータドリブン ワークフロー (パイプラインと呼ばれます) を作成およびスケジュールできます。 データ フローを使用するか、Azure HDInsight Hadoop、Azure Databricks、Azure SQL Databaseなどのコンピューティング サービスを使用して、データを視覚的に変換する複雑な ETL プロセスを構築できます。
さらに、変換されたデータをビジネス インテリジェンス (BI) アプリケーションが使用するAzure Synapse Analyticsなどのデータ ストアに発行できます。 最終的には、Azure Data Factoryを通じて、生データを意味のあるデータ ストアとデータ レイクに編成して、ビジネス上の意思決定を向上させることができます。
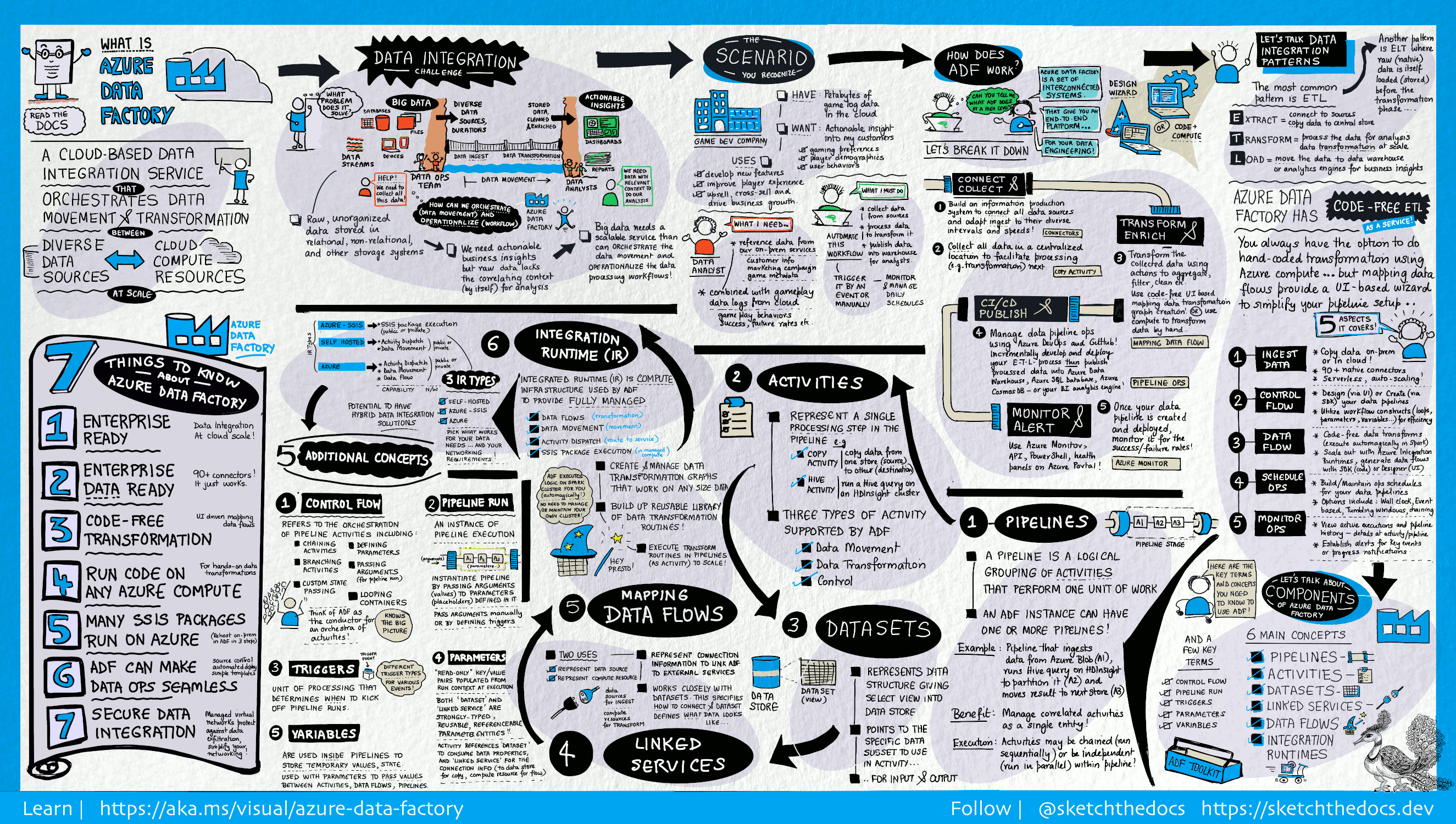
それはどのように機能しますか?
Data Factory には、包括的なエンド ツー エンドのプラットフォームをデータ エンジニアに提供する、相互接続された一連のシステムが含まれています。

このビジュアル ガイドは、完全な Data Factory アーキテクチャの詳しい概要を示しています。

詳細を表示するには、前の画像を選択して拡大するか、高解像度画像 を参照してください。 このビジュアル ガイドの開発とドキュメント プロジェクトのスケッチについては、こちらをご覧ください。
{kind=link}
接続と収集
企業は、さまざまな種類のデータをさまざまなソースで管理しています。ソースには、オンプレミスのソースやクラウド内のソース、構造化されたもの、構造化されていないもの、半構造化されたものなどがあり、そのデータの受信間隔も速度もまちまちです。
情報生成システム構築の最初のステップは、サービスとしてのソフトウェア (SaaS) サービス、データベース、ファイル共有、FTP Web サービスなど、必要なすべてのデータ ソースと処理の機能に接続することです。 データを必要に応じて中央集約型の場所へ移動し、その後の処理に備えます。
Data Factory を使用していない企業では、カスタムのデータ移動コンポーネントを構築するか、これらのデータ ソースと処理を統合するカスタム サービスを作成しなければなりません。 このようなシステムの統合と保守は高コストで、容易ではありません。 そのうえ、エンタープライズ クラスの監視やアラートが欠け、フル マネージドのサービスが提供できるような制御機能を用意できないことも少なくありません。
Data Factory を使用すれば、データ パイプラインのコピー アクティビティで、オンプレミスとクラウドの両方のソース データ ストアからクラウド内の一元化されたデータ ストアにデータを移動し、詳しく分析することができます。 たとえば、Azure Data Lake Storageでデータを収集し、後で Azure Data Lake Analytics コンピューティング サービスを使用してデータを変換できます。 また、Azure Blob Storage でデータを収集し、後で Azure HDInsight Hadoop クラスターを使用して変換することもできます。
変換と強化
クラウド上の一元的なデータ ストアにデータが集まったら、ADF マッピング データ フローを使用して、その収集されたデータを処理または変換します。 データ エンジニアは、Spark クラスターや Spark プログラミングの知識がなくても、データ フローを使用して、Spark 上で実行されるデータ変換グラフを作成、維持することができます。
手動で変換をコーディングする場合、ADF では、HDInsight Hadoop、Spark、Data Lake Analytics、Machine Learningなどのコンピューティング サービスで変換を実行するための外部アクティビティがサポートされます。
CI/CD と公開
Data Factory は、Azure DevOpsとGitHubを使用して、データ パイプラインの CI/CD を完全にサポートします。 ETL プロセスの開発とデリバリを段階的に進めたうえで、完成した製品を公開することが可能です。 生データをビジネスに適した利用可能な形態に精製したら、Azure Data Warehouse、Azure SQL Database、Azure Cosmos DB、またはビジネスユーザーがビジネスインテリジェンスツールを通じてアクセス可能な任意の分析エンジンへデータを読み込みます。
モニター
データ統合パイプラインを正常に構築してデプロイし、変換したデータからビジネス価値を生み出せるようになったなら、スケジュール化したアクティビティとパイプラインを監視して、成功率と失敗率を確認することができます。 Azure Data Factoryには、Azure ポータルの Azure Monitor、API、PowerShell、Azure Monitor ログ、正常性パネルを使用したパイプライン監視のサポートが組み込まれています。
トップレベルの概念
Azure サブスクリプションには、1 つ以上のAzure Data Factory インスタンス (またはデータ ファクトリ) が含まれます。 Azure Data Factoryは、次の主要なコンポーネントで構成されます。
- Pipelines
- アクティビティ
- データセット
- リンクされたサービス
- データ フロー
- 統合ランタイム
これらのコンポーネントの連携によって実現するプラットフォームを基盤として、データ移動とデータ変換のステップを含んだデータ主導型のワークフローを作成することができます。
パイプライン
データ ファクトリには、1 つまたは複数のパイプラインを設定できます。 パイプラインは、1 つの作業単位を実行するための複数のアクティビティから成る論理的なグループです。 パイプライン内のアクティビティがまとまって 1 つのタスクを実行します。 たとえば、パイプラインには、Azure BLOB からデータを取り込み、HDInsight クラスターで Hive クエリを実行してデータをパーティション分割するアクティビティのグループを含めることができます。
パイプラインのメリットは、アクティビティを個別にではなく、セットとして管理できることです。 パイプライン内のアクティビティは、連鎖して順次処理することも、独立して並行処理することもできます。
データ フローのマッピング
あらゆるサイズのデータの変換に使用できるデータ変換ロジックのグラフを作成して管理します。 再利用可能なデータ変換ルーチンのライブラリを構築し、それらのプロセスを ADF パイプラインからスケールアウト方式で実行することができます。 Data Factory は、必要なときにスピンアップおよびスピンダウンする Spark クラスターでロジックを実行します。 クラスターを自分で維持、管理する必要はありません。
アクティビティ
アクティビティは、パイプライン内の処理ステップを表します。 たとえば、コピー アクティビティを使用して、データ ストア間でデータをコピーできます。 同様に、Hive アクティビティを使用して、Azure HDInsight クラスターで Hive クエリを実行し、データを変換または分析できます。 Data Factory では、データ移動アクティビティ、データ変換アクティビティ、制御アクティビティの 3 種類のアクティビティがサポートされています。
データセット
データセットは、データ ストア内のデータ構造を表しています。アクティビティ内でデータを入力または出力として使用したい場合は、そのデータをポイントまたは参照するだけで済みます。
リンクされたサービス
リンクされたサービスは、接続文字列によく似ており、Data Factory が外部リソースに接続するために必要な接続情報を定義します。 リンクされたサービスはデータ ソースへの接続を定義するもので、データセットはデータの構造を表すもの、と捉えることができます。 たとえば、Azure Storage にリンクされたサービスは、Azure Storage アカウントに接続するための接続文字列を指定します。 さらに、Azure BLOB データセットは、BLOB コンテナーと、データを含むフォルダーを指定します。
Data Factory ではリンクされたサービスは 2 つの目的に使用されます。
データストアを表すには、例えば、SQL Server データベース、Oracle データベース、ファイル共有、Azure BLOB ストレージアカウントなどですが、これに限定されません。 サポートされるデータ ストアの一覧については、「コピー アクティビティ」を参照してください。
アクティビティの実行をホストできる コンピューティング リソース を表すため。 たとえば、HDInsightHive アクティビティは HDInsight Hadoop クラスターで実行されます。 変換アクティビティとサポートされているコンピューティング環境の一覧については、「データの変換」を参照してください。
Integration Runtime
Data Factory で、アクティビティは、実行されるアクションを定義します。 リンクされたサービスは、ターゲットのデータ ストアやコンピューティング サービスを定義します。 統合ランタイムは、アクティビティとリンクされたサービスとを橋渡しします。 リンクされたサービスまたはアクティビティによって参照され、アクティビティが実行されたりディスパッチされたりするコンピューティング環境を提供します。 これにより、できるだけターゲットのデータ ストアやコンピューティング サービスに近いリージョンでアクティビティを実行して効率を最大化できる一方、セキュリティとコンプライアンスの必要も満たせます。
トリガー
トリガーは、パイプラインの実行をいつ開始する必要があるかを決定する処理単位を表します。 さまざまな種類のイベントに合わせて、さまざまな種類のトリガーがあります。
パイプライン実行
パイプライン実行は、パイプラインを実行するインスタンスです。 パイプライン実行は、通常、パイプラインで定義されたパラメーターに引数を渡してインスタンス化されます。 引数は、手動で渡すか、トリガー定義内で渡すことができます。
パラメーター
パラメーターは、読み取り専用の構成のキーと値のペアです。 パラメーターはパイプラインで定義されます。 定義済みパラメーターの引数は、実行時に、トリガーが作成した実行コンテキストか、手動で実行されるパイプラインから渡されます。 パイプライン内のアクティビティは、パラメーターの値を使用します。
データセットとは、厳密に型指定されたパラメーターと、再利用または参照可能なエンティティのことです。 アクティビティは、データセットを参照でき、データセットの定義で定義されたプロパティを使用できます。
リンクされたサービスも厳密に型指定されたパラメーターであり、これにはデータ ストアかコンピューティング環境への接続情報が入ります。 これは再利用可能または参照可能なエンティティでもあります。
制御フロー
制御フローは、パイプライン アクティビティのオーケストレーションです。これには、シーケンスに従うアクティビティの連鎖、分岐、パイプライン レベルでのパラメーターの定義、オンデマンドかトリガーからパイプラインが呼び出される際の引数の受け渡しが含まれます。 さらに、カスタム状態の受け渡しや、ループ コンテナー、つまり For-each 反復子も含まれます。
変数
変数は、パイプライン内で一時的な値を格納するときに使用できるほか、パラメーターと組み合わせて、パイプラインやデータ フローなどのアクティビティ間で値を受け渡しする際にも使用できます。
関連するコンテンツ
次のステップとして重要なドキュメントを次に示します。ぜひご覧ください。