カスタム音声はテキスト読み上げ機能であり、アプリケーション用に独自のカスタマイズされた合成音声を作成できます。 カスタム音声を使用すると、人間の音声サンプルを微調整データとして提供することで、ブランドやキャラクターに対して非常に自然に聞こえる音声を構築できます。
初期設定のままで、音声合成はサポートされている言語ごとに標準音声を使って使用できます。 一意の音声が必要ない場合、標準音声はほとんどのテキスト読み上げシナリオで適切に機能します。
カスタム音声は、ニューラル テキスト読み上げテクノロジと多言語のマルチスピーカーユニバーサル モデルに基づいています。 豊富な話し方の合成音声や、調整可能なクロス言語を作成できます。 カスタム音声の現実的で自然な音声は、ブランドを表し、マシンを擬人化し、ユーザーがアプリケーションと対話できるようにします。 カスタム音声で サポートされている言語を 参照してください。
しくみ
カスタム音声を作成するには、 Speech Studio を 使用して、録音されたオーディオと対応するスクリプトをアップロードし、モデルをトレーニングし、音声をカスタム エンドポイントにデプロイします。
優れたカスタム音声を作成するには、音声の設計とデータの準備から、音声モデルのシステムへのデプロイまで、各ステップで慎重な品質管理が必要です。
Speech Studio で作業を開始する前に、いくつかの考慮事項を次に示します。
- 簡潔なペルソナ ドキュメントを使用して、ブランドを表す音声のペルソナを設計します。 このドキュメントは、音声の特徴や音声の背後にある特性などの要素を定義します。 これは、スクリプトの定義、音声タレントの選択、トレーニング、音声チューニングなど、カスタム音声モデルを作成するプロセスをガイドするのに役立ちます。
- 音声のユーザー シナリオを表す、レコーディング スクリプトを選択します。 たとえば、カスタマー サービス ボットを作成する場合、ボットの会話フレーズをレコーディング スクリプトとして使用できます。 陳述文、質問文、感嘆文など、さまざまな種類の文をスクリプトに含めます。
Speech Studio でカスタム音声を作成する手順の概要を次に示します。
- データ、音声モデル、テスト、エンドポイントを含むプロジェクトを作成します。 プロジェクトは、国やリージョン、および言語ごとに作成されます。 複数の音声を作成する場合は、音声ごとにプロジェクトを作成することをお勧めします。
- ボイス タレントを設定します。 プロの音声を微調整する前に、ボイス タレントの同意に関する声明の記録を送信する必要があります。 ボイス タレント ステートメントは、音声タレントが、プロの音声微調整のための音声データの使用に同意するステートメントを読み上げるための記録です。
- 適切な形式でデータの微調整を準備します。 高い SN 比 (信号対雑音比) を実現するため、プロフェッショナル品質の録音スタジオでオーディオ録音をキャプチャすることをお勧めします。 音声モデルの品質は、微調整データに大きく依存します。 一定の音量、話す速度、ピッチ、さらには話の表現方法における一貫性も必要です。
- 音声モデルをトレーニングします。 カスタム音声を作成するには、少なくとも 300 個の発話を選択します。 アップロードすると、一連のデータ品質チェックが自動的に実行されます。 高品質な音声モデルを作成するには、すべてのエラーを修正してからもう一度送信する必要があります。
- 音声をテストします。 アプリのさまざまなユース ケースをカバーする音声モデルのテスト スクリプトを準備します。 トレーニング データセットの内部および外部のスクリプトを使用することをお勧めします。そうすることで、さまざまなコンテンツに対して幅広く品質をテストできます。
- 音声モデルをアプリにデプロイして使用します。
標準音声を使用するのと同様に、カスタム音声を設定し、調整して使用できます。 リアルタイムでテキストを音声に変換したり、テキスト入力を使用してオーディオ コンテンツをオフラインで生成したりできます。 REST API、Speech SDK、または Speech Studio を使用します。
ヒント
アプリケーションでカスタム音声を使用する方法については、 GitHub の Speech SDK リポジトリ のコード サンプルを参照してください。
トレーニング済みの音声モデルのスタイルと特性は、トレーニングに採用したボイス タレントのスタイルと録音品質によって異なってきます。 とはいえ、音声モデルに対して API を呼び出して合成音声を生成するときに、SSML (音声合成マークアップ言語) を使用していくつかの調整を行うことができます。 SSML は、テキストを音声に変換するテキスト読み上げサービスとの通信に使用されるマークアップ言語です。 実施できる調整には、ピッチ、速さ、イントネーションの変更や発音の修正が含まれます。 複数のスタイルで音声モデルが構築されている場合は、SSML を使用してスタイルを切り替えることもできます。
コンポーネント シーケンス
カスタム音声は、テキスト アナライザー、ニューラル音響モデル、ニューラル ボコーダーの 3 つの主要なコンポーネントで構成されます。 テキストから自然な合成音声を生成するために、まずテキストがテキスト アナライザーに入力されます。これにより、音素シーケンスの形式で出力が提供されます。 "音素" は、特定の言語で、ある単語を別の単語と区別するための基本的なサウンド単位です。 音素のシーケンスは、テキストで提供された単語の発音を定義します。
次に、音素シーケンスは、ニューラル音響モデルに投入され、音声信号を定義する音響の特徴が予測されます。 音響の特徴には、音色、話し方、速度、イントネーション、強勢パターンなどがあります。 最後に、ニューラル ボコーダーが音響特徴を可聴波に変換すると、合成音声が生成されます。
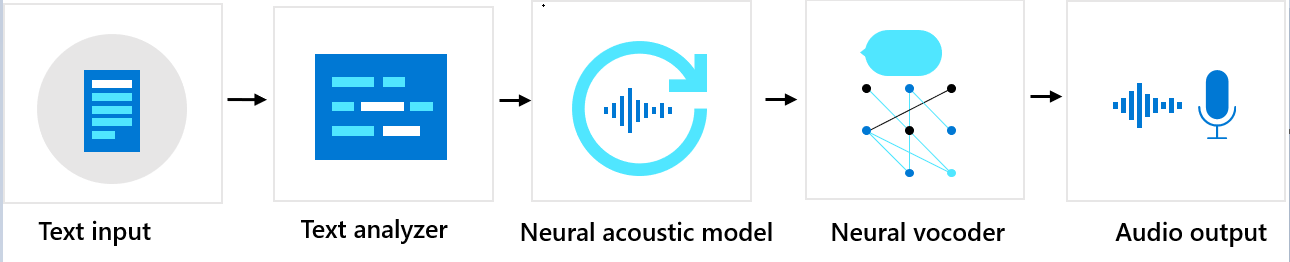
ニューラル テキスト読み上げ音声モデルは、人間の声の録音サンプルに基づき、ディープ ニューラル ネットワークを使用してトレーニングされています。 詳細については、こちらの Microsoft ブログ記事をご覧ください。 ニューラル ボコーダーのトレーニング方法の詳細については、こちらの Microsoft ブログ記事をご覧ください。
責任ある AI
AI システムには、テクノロジだけでなく、それを使用する人、それによって影響を受ける人、それがデプロイされる環境も含まれます。 「透過性のためのメモ」を読み、システムでの責任ある AI の使用とデプロイについて確認してください。
- カスタム音声の透明性に関するメモとユース ケース
- カスタム音声を使用するための特性と制限事項
- カスタム音声への制限付きアクセス
- 合成音声テクノロジの責任あるデプロイのためのガイドライン
- ボイス タレントに関する開示
- 開示設計のガイドライン
- 設計パターンの開示
- テキスト読み上げ統合の倫理規定
- カスタム音声のデータ、プライバシー、セキュリティ