Important
99.999% 可用性サービス レベル アグリーメント (SLA)、インスタント 自動スケール、および複数のリージョン間の自動フェールオーバーを使用した 大規模 なシナリオ向けのデータベース ソリューションをお探しですか? [c0]NoSQL 用に Azure Cosmos DB を検討してください。[c0]
オンライン分析処理 (OLAP) グラフを実装するか、既存の Apache Gremlin アプリケーションを移行しますか? Microsoft Fabric で Graph を検討してください。
この記事では、グラフ データ モデルの使用に関する推奨事項を示します。 これらのベスト プラクティスは、データの進化に合わせてグラフ データベース システムのスケーラビリティとパフォーマンスを確保するために不可欠です。 効率的なデータ モデルは、大規模なグラフで特に重要です。
Requirements
このガイドに記載されているプロセスは、次の前提条件に基づいています。
- 問題空間内のエンティティが特定されている。 これらのエンティティは各要求に対して "アトミックに" 使用されます。 つまり、このデータベース システムは複数のクエリ要求で 1 つのエンティティのデータを取得するようには設計されていません。
- このデータベース システムの "読み取りと書き込みの要件" を理解している。 これらの要件は、グラフ データ モデルに必要な最適化の指針となります。
- Apache のプロパティ グラフ標準の原則はよく理解されています。
グラフ データベースが必要になる場合
データ ドメイン内のエンティティとリレーションシップが次のいずれかの特性を備えている場合に、グラフ データベース ソリューションを最適に使用できます。
- エンティティが、わかりやすいリレーションシップにより緊密に接続されている。 このシナリオのメリットは、リレーションシップがストレージ内に保持されることです。
- 循環リレーションシップまたは自己参照エンティティがある。 このパターンは、リレーショナルまたはドキュメント データベースを使用する場合に課題となることがよくあります。
- エンティティ間に動的に発展するリレーションシップがある。 このパターンは、多数のレベルがある階層またはツリー構造のデータに特に適用されます。
- エンティティ間に多対多のリレーションシップがある。
- エンティティとリレーションシップの両方に書き込みと読み取りの要件がある。
上記の条件を満たしている場合、グラフ データベースのアプローチが "クエリの複雑さ"、"データ モデルのスケーラビリティ"、および "クエリ パフォーマンス" の面でメリットをもたらす可能性があります。
次の手順では、分析とトランザクション目的のどちらでグラフを使用するかを確認します。 グラフが高負荷な計算やデータ処理のワークロードに使用される場合は、Cosmos DB Spark コネクタや GraphX ライブラリについて検討する価値があります。
グラフ オブジェクトを使用する方法
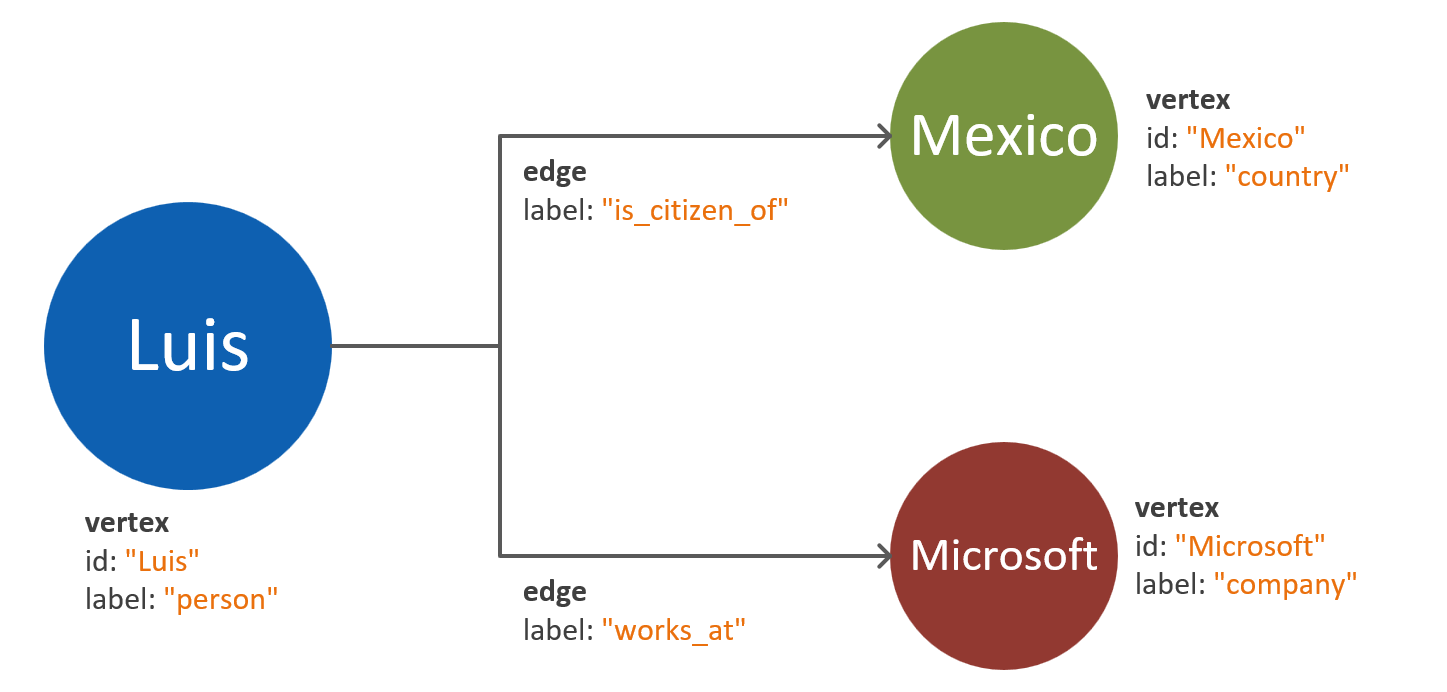
Apache のプロパティ グラフ標準では、頂点とエッジの 2 種類のオブジェクトが定義されています。
グラフ オブジェクトのプロパティのベスト プラクティスを以下に示します。
| Object | 財産 | タイプ | メモ |
|---|---|---|---|
| 頂点 | ID | String | パーティションごとに一意に適用されます。 挿入時に値が指定されていない場合は、自動生成された GUID が格納されます。 |
| 頂点 | ラベル | String | このプロパティは、頂点が表すエンティティの種類を定義するために使用されます。 値が指定されないと、既定値の vertex が使用されます。 |
| 頂点 | プロパティ | 文字列、ブール値、数値 | 各頂点にキーと値のペアとして格納される個々のプロパティの一覧。 |
| 頂点 | パーティション キー | 文字列、ブール値、数値 | このプロパティでは、頂点とその外向きエッジを格納する場所を定義します。 グラフのパーティション分割の詳細をご覧ください。 |
| エッジ | ID | String | パーティションごとに一意に適用されます。 既定で自動生成されます。 通常、エッジは ID を使用して一意に取得する必要はありません。 |
| エッジ | ラベル | String | このプロパティは、2 つの頂点のリレーションシップの種類を定義するために使用されます。 |
| エッジ | プロパティ | 文字列、ブール値、数値 | 各エッジにキーと値のペアとして格納される個々のプロパティの一覧。 |
注
エッジにはパーティション キー値が必要ありません。その値はそのソースとなる頂点に基づいて自動的に割り当てられるためです。 詳細については、「Azure Cosmos DB でのパーティション分割されたグラフの使用」を参照してください。
エンティティとリレーションシップのモデリングのガイドライン
以下のガイドラインは、Azure Cosmos DB for Apache Gremlin グラフ データベースのデータ モデリングにアプローチする際に役立ちます。 これらのガイドラインでは、データ ドメインとそのクエリの既存の定義があることを前提としています。
注
以下の手順は、推奨事項として示されています。 最終的なモデルを評価およびテストしてから、運用環境に対応できると見なす必要があります。 さらに、これらの推奨事項は、Azure Cosmos DB の Gremlin API の実装に固有です。
頂点とプロパティのモデル化
グラフ データ モデルの最初の手順では、識別されたすべてのエンティティを Vertex オブジェクトにマップします。 すべてのエンティティと頂点の 1 対 1 のマッピングは、最初の手順であり、変更されることがあります。
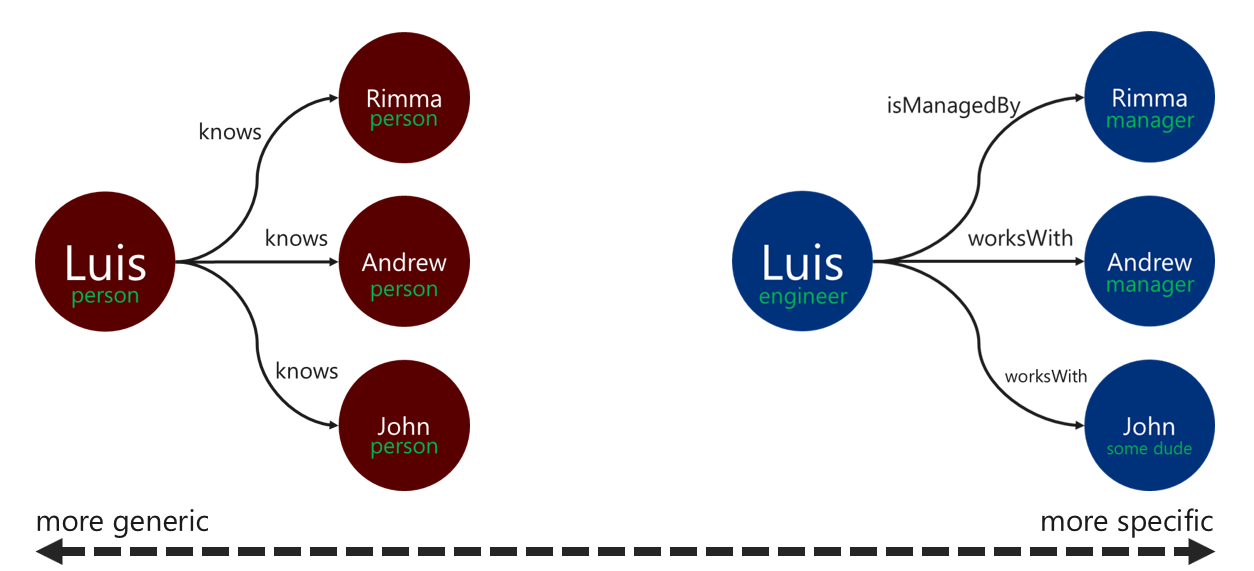
よくある落とし穴の 1 つとして、1 つのエンティティのプロパティを別々の頂点としてマップすることがあります。 同じエンティティを 2 つの異なる方法で表現する次の例について考えてみましょう。
頂点ベースのプロパティ: このアプローチでは、エンティティは 3 つの個別の頂点と 2 つのエッジを使用して、そのプロパティを記述します。 このアプローチにより、冗長性が軽減される可能性はありますが、モデルの複雑さが増します。 モデルの複雑さが増すと、待ち時間、クエリの複雑さ、および計算コストが増加する場合があります。 このモデルでは、パーティション分割で問題が発生する可能性もあります。
プロパティの埋め込み頂点: このアプローチでは、キーと値のペアの一覧を利用して、頂点内でエンティティのすべてのプロパティを表します。 このアプローチでは、モデルの複雑さが軽減され、クエリがシンプルになり、トラバーサルのコスト効率が高くなります。

注
上記の図では、エンティティのプロパティを分割する 2 つの方法を比較する簡略化されたグラフ モデルを示しています。
プロパティが埋め込まれた頂点パターンは、一般に、パフォーマンスとスケーラビリティの高いアプローチを提供します。 新しいグラフ データ モデルに対する既定のアプローチは、このパターンになる傾向があります。
ただし、プロパティの参照がメリットをもたらすことがあるシナリオもあります。 たとえば、参照されるプロパティが頻繁に更新される場合です。 個々の頂点を使用して、繰り返し変更されるプロパティを表すことで、更新に必要な書き込み操作の量が最小限に抑えられます。
エッジの方向によるリレーションシップのモデル
頂点をモデル化した後、それらのリレーションシップを示すためにエッジを追加できます。 評価する必要がある最初の側面は、リレーションシップの方向です。
エッジには既定の方向があり、 out() または outE() 関数を使用する場合はトラバーサルが続きます。 この自然な方向は、すべての頂点がその発信エッジと共に格納されるため、効率的な操作になります。
in()関数を使用してエッジの逆方向を走査すると、常にパーティション間クエリが実行されます。 詳しくは、グラフのパーティション分割に関する記事をご覧ください。
in()関数を使用して頻繁に走査する必要がある場合は、両方向にエッジを追加します。
エッジの方向を指定するには、.to() Gremlin ステップに .from() または .addE() 述語を使用します。 または、Gremlin API 用 bulk executor ライブラリを使用します。
注
エッジには既定で方向があります。
リレーションシップのラベル
わかりやすいリレーションシップ ラベルを使用すると、エッジ解決操作の効率を向上させることができます。 このパターンを次の方法で適用できます。
- 非ジェネリック用語を使用してリレーションシップにラベルを付けます。
- リレーションシップ名を使用して、ソースの頂点のラベルとターゲットの頂点のラベルを関連付ける。
トラバーサーがエッジのフィルター処理に使用するラベルを具体的にするほど良くなります。 この決定は、クエリのコストにも大きな影響を与える可能性があります。
executionProfileの手順を使用して、いつでもクエリ コストを評価できます。