適用対象: ![]() MongoDB
MongoDB
この移行ガイドは、MongoDB から MongoDB 用 Azure Cosmos DB API へのデータベースの移行に関するシリーズの一部です。 重要な移行手順は、次に示すように、移行前、移行、および移行後です。
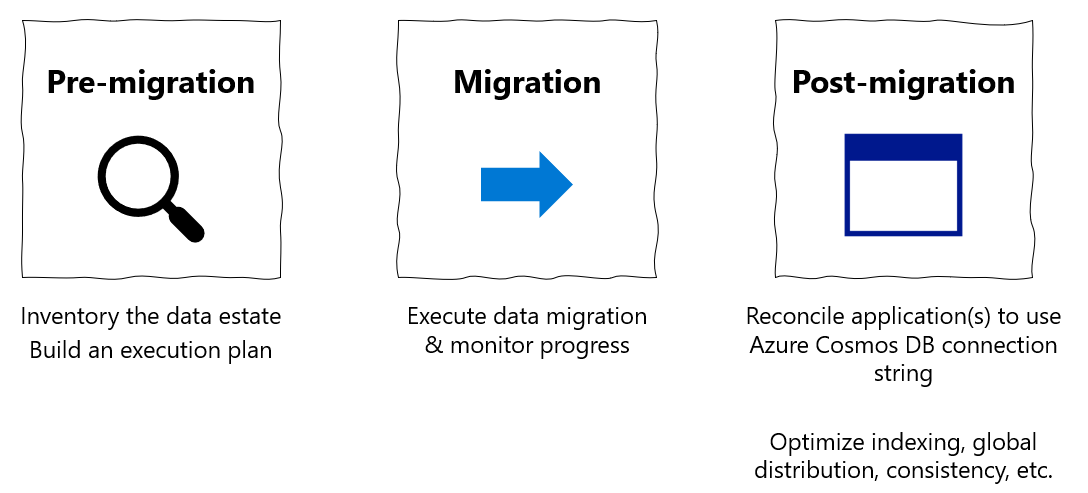
Azure Databricks を使用したデータ移行
Azure Databricks は、Apache Spark 用のサービスとしてのプラットフォーム (PaaS) オファリングです。 大規模なデータセットでオフライン移行を行う方法が提供されます。 Azure Databricks を使用して、MongoDB から Azure Cosmos DB for MongoDB へのデータベースのオフライン移行を行うことができます。
このチュートリアルでは、次の内容を学習します。
Azure Databricks クラスターのプロビジョニング
依存関係を追加する
Scala または Python ノートブックを作成して実行する
移行のパフォーマンスを最適化する
移行中に確認されることがあるレート制限エラーのトラブルシューティングを行う
前提条件
このチュートリアルを完了するには、以下を実行する必要があります。
- スループットの見積もりやシャード キーの選択など、移行前の手順を完了する。
- Azure Cosmos DB for MongoDB アカウントを作成します。
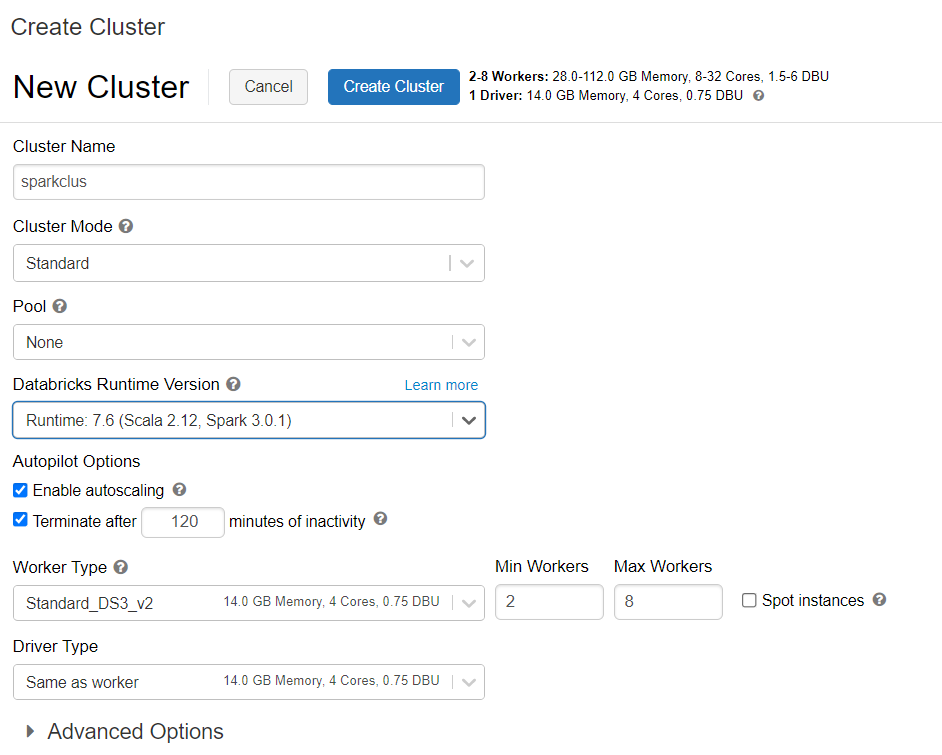
Azure Databricks クラスターのプロビジョニング
手順に従って、Azure Databricks クラスターをプロビジョニングできます。 Spark 3.0 をサポートする Databricks ランタイム バージョン 7.6 を選択することをお勧めします。
依存関係を追加する
Spark 用 MongoDB コネクタ ライブラリをクラスターに追加して、ネイティブの MongoDB と Azure Cosmos DB for MongoDB エンドポイントの両方に接続します。 ご利用のクラスターで、 [ライブラリ]>[新規インストール]>[Maven] の順に選択し、org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 という Maven 座標を追加します。
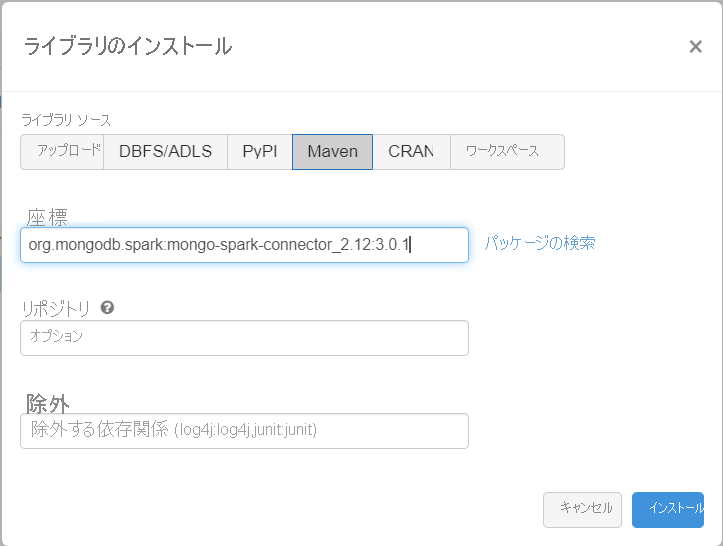
[インストール] を選択し、インストールが完了したらクラスターを再起動します。
Note
Spark 用 MongoDB コネクタ ライブラリがインストールされた後、必ず Databricks クラスターを再起動してください。
その後、移行用の Scala または Python ノートブックを作成できます。
移行用の Scala ノートブックを作成する
Databricks で Scala ノートブックを作成します。 次のコードを実行する前に、必ず変数に適切な値を入力してください。
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
移行用の Python ノートブックを作成する
Databricks で Python ノートブックを作成します。 次のコードを実行する前に、必ず変数に適切な値を入力してください。
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
移行のパフォーマンスを最適化する
移行のパフォーマンスは、これらの構成を使用して調整できます。
Spark クラスター内のワーカーとコアの数: ワーカーが多いということは、タスクを実行するためのコンピューティング シャードが多いことを意味します。
maxBatchSize: :
maxBatchSize値で、ターゲットの Azure Cosmos DB コレクションにデータが保存されるレートを制御します。 しかし、maxBatchSize がコレクション スループットに対して高すぎる場合、レート制限エラーが発生するおそれがあります。ワーカーの数と maxBatchSize を調整する必要があります。これは、Spark クラスター内のエグゼキュータの数、場合によっては書き込まれる各ドキュメントのサイズ (したがって RU コスト)、およびターゲット コレクションのスループットの制限によって異なります。
ヒント
maxBatchSize = コレクションのスループット / ( 1 つのドキュメントの RU コスト * Spark ワーカーの数 * ワーカーあたりの CPU コアの数 )
MongoDB Spark パーティショナーと partitionKey: 使用される既定のパーティショナーは MongoDefaultPartitioner で、既定の partitionKey は _id です。 パーティショナーは、入力構成プロパティ
spark.mongodb.input.partitionerに値MongoSamplePartitionerを割り当てることによって変更できます。 同様に、partitionKey は、適切なフィールド名を入力構成プロパティspark.mongodb.input.partitioner.partitionKeyに割り当てることによって変更できます。 適切な partitionKey は、データ スキュー (多数のレコードが同じシャード キー値に対して書き込まれること) を回避するのに役立つ場合があります。データ転送中にインデックスを無効にする: 大量のデータを移行する場合は、インデックスを無効にすることを検討してください。特に、ターゲット コレクションのワイルドカード インデックスです。 インデックスを使用すると、各ドキュメントの書き込みにかかる RU コストが増加します。 これらの RU を解放すると、データ転送速度の向上に役立つ場合があります。 データが移行されたら、インデックスを有効にすることができます。
トラブルシューティング
タイムアウト エラー (エラー コード 50)
Azure Cosmos DB for MongoDB データベースに対する操作について、50 エラー コードが表示される場合があります。 次のシナリオでは、タイムアウト エラーが発生するおそれがあります。
- データベースに割り当てられているスループットが低い: 確実にターゲット コレクションに十分なスループットが割り当てられるようにしてください。
- 大規模なデータ ボリュームでの過度のデータ スキュー。 特定のテーブルに移行するデータが大量にあるが、データに大きなスキューがある場合、テーブルに複数の要求ユニットがプロビジョニングされている場合でも、レート制限が発生することがあります。 要求ユニットが物理パーティション間で均等に分割され、大量のデータ スキューによって単一のシャードに対して要求のボトルネックが発生するおそれがあります。 データ スキューは、同じシャード キー値に対して多数のレコードがあることを意味します。
レート制限 (エラー コード 16500)
Azure Cosmos DB for MongoDB データベースに対する操作について、16500 エラー コードが表示される場合があります。 これらはレート制限のエラーであり、古いアカウント、またはサーバー側の再試行機能が無効になっているアカウントで確認される場合があります。
- サーバー側の再試行を有効にする: サーバー側の再試行 (SSR) 機能を有効にし、サーバーでレート制限のある操作が自動的に再試行されるようにします。
移行後の最適化
データを移行した後、Azure Cosmos DB に接続してデータを管理することができます。 また、インデックス作成ポリシーの最適化、既定の整合性レベルの更新、Azure Cosmos DB アカウントのグローバル分散の構成など、移行後の他の手順に従うこともできます。 詳細については、「移行後の最適化」を参照してください。
その他のリソース
- Azure Cosmos DB への移行のための容量計画を実行しようとしていますか?
- 既存のデータベース クラスター内の仮想コアとサーバーの数のみがわかっている場合は、仮想コア数または仮想 CPU 数を使用した要求ユニットの見積もりに関するページを参照してください
- 現在のデータベース ワークロードに対する通常の要求レートがわかっている場合は、Azure Cosmos DB Capacity Planner を使用した要求ユニットの見積もりに関するページを参照してください