このガイドでは、カスタマイズされた AI アシスタントである Heelie を使って、対象者の共感を呼ぶ動的広告コンテンツを作成する方法を見ていきます。 Azure Cosmos DB for MongoDB 仮想コアを利用たベクトル類似性検索機能を使って、インベントリの説明をセマンティック的に分析し、広告トピックと照合します。 このプロセスは、OpenAI 埋め込みを使用してインベントリの説明に対するベクトルを生成することで実現され、セマンティックの深さが大幅に向上します。 その後、これらのベクトルは、Cosmos DB for MongoDB 仮想コア リソース内に格納されて、インデックスが付けられます。 広告のコンテンツを生成するときは、広告トピックをベクトル化して、最もよく一致するインベントリ項目を見つけます。 その後、検索拡張生成 (RAG) プロセスにより、上位の一致が OpenAI に送信されて、人を引きつける広告が作成されます。 アプリケーションのコードベース全体は、GitHub リポジトリで参照できます。
機能
- ベクトル類似性検索: Azure Cosmos DB for MongoDB 仮想コアの強力なベクトル類似性検索を使ってセマンティック検索機能を向上させ、広告の内容に基づいて関連するインベントリ項目が簡単に見つかるようにします。
- OpenAI 埋め込み: OpenAI の最先端の埋め込みを利用して、インベントリの説明に対するベクトルを生成します。 このアプローチを使うと、インベントリと広告コンテンツの間でいっそう微妙でセマンティックに富んだ一致を実現できます。
- コンテンツ生成: OpenAI の高度な言語モデルを採用し、魅力的でトレンド重視の広告を生成します。 この方法により、コンテンツが関連性を持つことだけでなく、対象者に魅力的であることも保証されます。
前提条件
- Azure OpenAI: Azure OpenAI リソースをセットアップします。 現在、このサービスへのアクセスは、申請によってのみ利用できます。 Azure OpenAI へのアクセスを申請するには、https://aka.ms/oai/access のフォームに入力してください。 アクセスできるようになったら、次の手順のようにします。
- Cosmos DB for MongoDB 仮想コア リソース: 最初に、こちらのクイック スタート ガイドに従って、Azure Cosmos DB for MongoDB 仮想コア リソースを無料で作成します。
- 接続の詳細をメモします。
numpy、openai、pymongo、python-dotenv、azure-core、azure-cosmos、tenacity、gradioなどのパッケージを含む Python 環境 (>= 3.9 バージョン)。- データ ファイルをダウンロードし、指定されたデータ フォルダーに保存します。
スクリプトの実行
AI で強化された広告の生成の核心部分に進む前に、環境を設定する必要があります。 このセットアップには、スクリプトの円滑な実行を保証するために必要なパッケージのインストールが含まれます。 すべてを準備するための詳細な手順のガイドを次に示します。
1.1 必要なパッケージをインストールする
まず、いくつかの Python パッケージをインストールする必要があります。 ターミナルを開いて、次のコマンドを実行します。
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 OpenAI と Azure クライアントを設定する
必要なパッケージをインストールした後、次のステップでは、スクリプト用に OpenAI と Azure のクライアントを設定します。これは、OpenAI API と Azure のサービスに対する要求を認証するために重要です。
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
ソリューションのアーキテクチャ
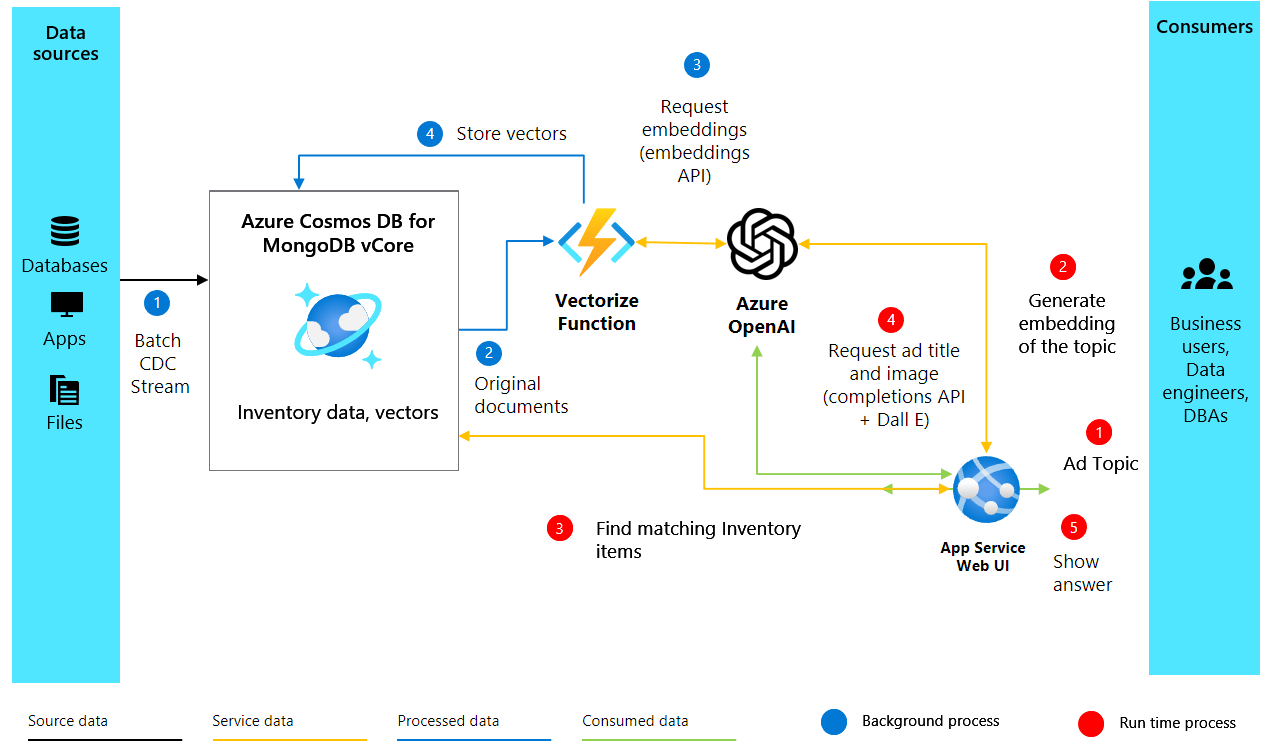
2. 埋め込みの作成と Cosmos DB の設定
環境と OpenAI クライアントを設定した後、AI で強化された広告生成プロジェクトの中核部分に移ります。 次のコードでは、製品のテキスト説明からベクトル埋め込みが作成されて、これらの埋め込みを格納および検索するように Azure Cosmos DB for MongoDB 仮想コアのデータベースが設定されます。
2.1 埋め込みを作成する
人を引きつける広告を生成するには、まずインベントリ内の項目を理解する必要があります。 これを行うため、項目の説明からベクトル埋め込みを作成します。これにより、そのセマンティックな意味を、コンピューターが理解して処理できる形式でキャプチャできます。 Azure OpenAI を使って項目の説明のベクトル埋め込みを作成する方法を次に示します。
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
この関数は、製品の説明のようなテキスト入力を受け取り、OpenAI API の client.embeddings.create メソッドを使って、そのテキストに対するベクトル埋め込みを生成します。 ここでは text-embedding-ada-002 モデルを使っていますが、要件に基づいて他のモデルを選択できます。 プロセスが成功した場合は、生成された埋め込みを出力します。そうでない場合は、エラー メッセージを出力して例外を処理します。
3. Cosmos DB for MongoDB 仮想コアに接続して設定する
埋め込みの準備ができたら、次のステップでは、ベクトル類似性検索をサポートするデータベースにそれを格納して、インデックスを付けます。 Azure Cosmos DB for MongoDB 仮想コアは、トランザクション データを格納し、ベクトル検索をすべて 1 か所で実行することを目的に構築されているため、このタスクに最適です。
3.1 接続を設定する
Cosmos DB に接続するには、pymongo ライブラリを使います。これにより、MongoDB を簡単に操作できます。 次のコード スニペットは、Cosmos DB for MongoDB 仮想コア インスタンスとの接続を確立します。
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
<USERNAME>、<PASSWORD>、<VCORE_CLUSTER_NAME> は、それぞれ実際の MongoDB ユーザー名、パスワード、仮想コア クラスター名に置き換えてください。
4. Cosmos DB でのデータベースとベクトル インデックスの設定
Azure Cosmos DB への接続を確立したら、次のステップでは、データベースとコレクションを設定してから、ベクトル インデックスを作成して効率的なベクトル類似性検索を有効にします。 これらの手順を見ていきましょう。
4.1 データベースとコレクションを設定する
最初に、Cosmos DB インスタンス内にデータベースとコレクションを作成します。 その方法を次に紹介します。
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2 ベクトル インデックスを作成する
コレクション内で効率的なベクトル類似性検索を実行するには、ベクトル インデックスを作成する必要があります。 Cosmos DB ではさまざまな種類のベクトル インデックスがサポートされています。ここでは、IVF と HNSW の 2 つについて説明します。
IVF
IVF は Inverted File Index (転置ファイル インデックス) の頭文字で、すべてのクラスター レベルで動作する既定のベクトル インデックス作成アルゴリズムです。 これは、クラスタリングを使ってデータセット内の類似ベクトルの検索を高速化する、近似最近傍 (ANN) アプローチです。 IVF インデックスを作成するには、次のコマンドを使います。
db.runCommand({
'createIndexes': 'COLLECTION_NAME',
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
重要
ベクトル プロパティごとに作成できるインデックスは 1 つだけです。 つまり、同じベクトル プロパティを指す複数のインデックスを作成することはできません。 インデックスの種類 (IVF から HNSW など) を変更する場合は、新しいインデックスを作成する前にまずインデックスを削除する必要があります。
HNSW
HNSW は階層ナビゲーション可能な小さい世界を表します。これは、クラスターとサブクラスターにベクトルを分割するグラフベースのデータ構造です。 HNSW を使用すると、より高い精度で高速の近似ニアレスト ネイバー検索を実行できます。 HNSW は近似 (ANN) 手法です。 以下に、設定の方法を説明します。
db.runCommand(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
Note
HNSW のインデックス付けは、M40 クラスター レベル以上でのみ使用できます。
5.データをコレクションに挿入する
次に、説明とそれに対応するベクトル埋め込みを含むインベントリ データを、新しく作成されたコレクションに挿入します。 データをコレクションに挿入するには、pymongo ライブラリによって提供される insert_many() メソッドを使います。 このメソッドを使うと、一度に複数のドキュメントをコレクションに挿入できます。 データは JSON ファイルに格納されています。それを読み込んでデータベースに挿入します。
GitHub リポジトリから shoes_with_vectors.json ファイルをダウンロードして、プロジェクト フォルダー内の data ディレクトリに格納します。
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6.Cosmos DB for MongoDB 仮想コアでのベクトル検索
データが正常にアップロードされたので、ベクトル検索の機能を適用し、クエリに基づいて最も関連性の高い項目を検索できるようになりました。 前に作成したベクトル インデックスを使うと、データセット内でセマンティック検索を実行できます。
6.1 ベクトル検索の実施
ベクトル検索を実行するため、クエリと返す結果の数を受け取る関数 vector_search を定義します。 この関数は、前に定義した generate_embeddings 関数を使ってクエリのベクトルを生成してから、Cosmos DB の $search 機能を使って、ベクトル埋め込みに基づいて最もよく一致する項目を検索します。
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 ベクトル検索クエリを実行する
最後に、特定のクエリを使ってベクトル検索関数を実行し、結果を処理してそれらを表示します。
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
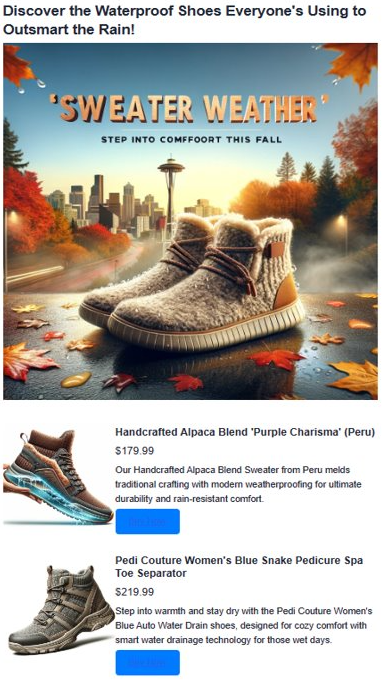
7.GPT-4 と DALL.E を使用して広告コンテンツを生成する
開発したすべてのコンポーネントを組み合わせて、人を引きつける広告を作成します。テキストには OpenAI の GPT-4 を使い、画像には DALL·E 3 を使います。 ベクトル検索結果と併せて、完全な広告を形成します。 また、魅力的な広告キャッチフレーズの作成を担当するインテリジェント アシスタントである Heelie も導入します。 今後提供されるコードを見ると、Heelie の動作と、強化された広告作成プロセスを確認できます。
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8.まとめ
広告の生成を対話形式にするため、簡単な Web UI を作成するための Python ライブラリである Gradio を使っています。 ユーザーが広告トピックを入力し、結果の広告を動的に生成して表示できるようにする UI を定義します。
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
出力