Important
Azure Cosmos DB for PostgreSQL は、新しいプロジェクトではサポートされなくなりました。 このサービスは、新しいプロジェクトには使用しないでください。 代わりに、次の 2 つのサービスのいずれかを使用します。
Azure Cosmos DB for NoSQL は、99.999% 可用性サービス レベル アグリーメント (SLA)、インスタント 自動スケール、および複数のリージョン間の自動フェールオーバーを使用する 大規模 なシナリオ向けに設計された分散データベース ソリューションに使用します。
オープンソースの Citus 拡張機能を使用して、シャード化された PostgreSQL 用の Azure Database For PostgreSQL のエラスティック クラスター機能 を使用します。
各テーブルのディストリビューション列を選択することは、モデリングに関する決定事項の中でも最も重要なものの 1 つです。 Azure Cosmos DB for PostgreSQL では、行のディストリビューション列の値に基づいて、行をシャードに格納します。
適切な選択では、同じ物理ノード上の関連データがまとめてグループ化され、クエリが高速になり、すべての SQL 機能のサポートが追加されます。 不適切な選択を行うと、システムの動作が遅くなります。
一般的なヒント
ここでは、分散テーブルに最適なディストリビューション列を選択するための 4 つの基準について説明します。
アプリケーション ワークロードの中心的な部分である列を選択する。
この列は、データをパーティション分割するための "心臓部"、"中心的な部分"、"自然なディメンション" と考えることができます。
例 :
- IoT ワークロードの
device_id - 証券を追跡する金融アプリの
security_id - ユーザー分析の
user_id - マルチテナント SaaS アプリケーションの
tenant_id
- IoT ワークロードの
カーディナリティが適切で、統計分布が均等な列を選択する。
この列には、多くの値が含まれており、すべてのシャード間で完全かつ均等に分布している必要があります。
例 :
- 1000 を超えるカーディナリティ
- 行の大部分に同じ値がある列 (データ スキュー) は選択しない
- SaaS ワークロードでは、1 つのテナントが残りのテナントよりも大幅に大きくなると、データ スキューが発生する可能性があります。 このような状況では、そのテナントを処理する専用シャードを作成するために、テナントの分離を使用できます。
既存のクエリを活用できる列を選択する。
(ほとんどのクエリが数ミリ秒しかかからない) トランザクションまたは運用ワークロードの場合、少なくとも 80% のクエリの
WHERE句でフィルターとして示される列を選択します。 たとえば、device_idのSELECT * FROM events WHERE device_id=1列などです。(ほとんどのクエリが 1 から 2 秒かかる) 分析ワークロードの場合、ワーカー ノード間でクエリを並列化できる列を選択します。 たとえば、GROUP BY 句で頻繁に使用される列や、一度に複数の値が照会される列などです。
複数の大規模テーブルの大部分に存在する列を選択する。
50 GB を超えるテーブルは分散させる必要があります。 これらすべてに対して同じディストリビューション列を選択すると、ワーカー ノードにその列のデータを併置できます。 併置により、JOIN とロールアップを効率的に実行でき、また外部キーを効率的に適用できます。
その他の (小規模な) テーブルは、ローカルまたは参照テーブルにすることができます。 小規模なテーブルと分散テーブルを結合 (JOIN) する必要がある場合、そのテーブルは参照テーブルにします。
ユース ケースの例
ディストリビューション列を選択するための一般的な基準について説明しました。 次に、これらが一般的なユース ケースにどのように適用されるかについて説明します。
マルチテナント アプリ
マルチテナント アーキテクチャでは、階層型データベース モデリングフォームを使用して、クラスター内のノードにクエリを分散します。 データ階層の最上位は "テナント ID" と呼ばれ、各テーブルの列に格納する必要があります。
Azure Cosmos DB for PostgreSQL は、クエリを検査してどのテナント ID が関係しているかを確認し、一致するテーブル シャードを見つけます。 クエリはシャードを含む単一のワーカー ノードにルーティングされます。 同じノード上にあるすべての関連データに対してクエリを実行することは、コロケーションと呼ばれます。
次の図は、マルチテナント データ モデルのコロケーションを示します。 これには Accounts と Campaigns という 2 つのテーブルがあり、それぞれ account_id で分散されます。 網掛けのボックスはシャードを表します。 緑色のシャードは 1 つのワーカー ノードにまとめて格納され、青色のシャードは別のワーカー ノードに格納されます。 両方のテーブルを同じ account_id に制限すると、Accounts と Campaigns 間の結合クエリですべての必要なデータが 1 つのノードにまとめられる点に注目してください。
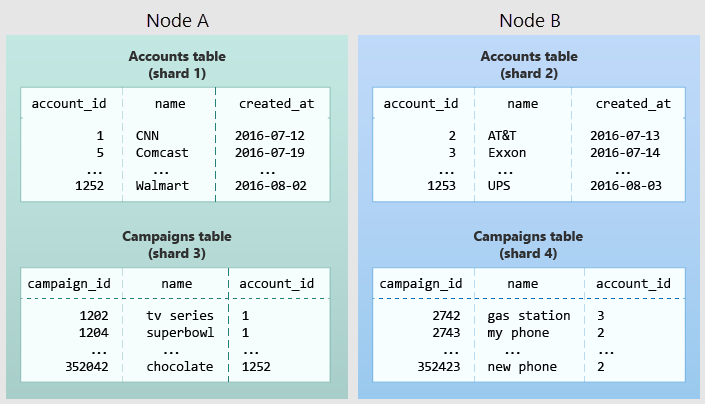
この設計を自分のスキーマに適用するには、アプリケーションのテナントを構成する要素を特定します。 一般的なインスタンスには、会社、アカウント、組織、または顧客が含まれます。 列名は company_id や customer_id のようになります。 各クエリを調べて、関連するすべてのテーブルをテナント ID が同じ行に制限する追加の WHERE 句があればうまくいくかどうかを自問してください。 マルチテナント モデルのクエリはテナントにスコープされています。 たとえば、売上や在庫に対するクエリは特定の店舗内にスコープされています。
ベスト プラクティス
- 共通の tenant_id 列でテーブルを分散させます。 たとえば、テナントが会社である SaaS アプリケーションでは、tenant_id はおそらく company_id になります。
- 小さなクロステナント テーブルを参照テーブルに変換します。 複数のテナントが小さな情報テーブルを共有する場合は、それを参照テーブルとして配布します。
- すべてのアプリケーション クエリのフィルター処理を tenant_id で制限します。 各クエリでは、一度に 1 つのテナントの情報を要求するようにします。
このような種類のアプリケーションを構築する方法の例については、マルチテナント チュートリアルに関する記事を参照してください。
リアルタイム アプリ
マルチテナント アーキテクチャは階層構造を導入し、データ コロケーションを使用してテナントごとにクエリをルーティングします。 対照的に、リアルタイム アーキテクチャは、高度な並列処理を実現するために、データの特定の分散プロパティに依存しています。
ここでは、リアルタイム モデルのディストリビューション列の用語として "エンティティ ID" を使用します。 一般的なエンティティは、ユーザー、ホスト、またはデバイスです。
通常、リアルタイム クエリには、日付またはカテゴリでグループ化された数値の集計が必要です。 Azure Cosmos DB for PostgreSQL では、部分的な結果を得るためにこれらのクエリが各シャードに送信され、コーディネーター ノード上で最終的な答えがまとめられます。 可能な限り多数のノードが参加し、過度な量の作業を行う必要があるノードが 1 つもない場合に、最も高速にクエリが実行されます。
ベスト プラクティス
- カーディナリティの高い列をディストリビューション列として選択します。 比較として、"New"、"Paid"、"Shipped" の値を持つ、order テーブルの Status フィールドは、ディストリビューション列には適していません。 データを保持できるシャードの数とそれを処理できるノードの数が制限されるため、これらの値はごくわずかと想定されます。 さらに、カーディナリティの高い列の中で、group-by 句や結合キーとして頻繁に使用される列を選択することをお勧めします。
- 均等な分散の列を選択します。 特定の共通値に偏った列についてテーブルを分散させると、テーブル内のデータは特定のシャードに蓄積される傾向があります。 このようなシャードを保持しているノードは、他のノードよりも多くの作業を実行することになります。
- 共通の列についてファクト テーブルとディメンション テーブルを分散させます。 ファクト テーブルが持つことができる分散キーは 1 つのみです。 別のキーで結合するテーブルは、ファクト テーブルと併置されません。 結合する頻度と結合する行のサイズに基づいて、併置するディメンションを 1 つ選択します。
- 一部のディメンション テーブルを参照テーブルに変更します。 ディメンション テーブルをファクト テーブルと併置できない場合は、ディメンション テーブルのコピーを参照テーブルの形式ですべてのノードに分散させることで、クエリのパフォーマンスを向上することができます。
このような種類のアプリケーションを構築する方法の例については、リアルタイム ダッシュボードのチュートリアルに関する記事を参照してください。
時系列データ
時系列ワークロードでは、アプリケーションは古い情報をアーカイブしながら最新の情報を照会します。
Azure Cosmos DB for PostgreSQL で時系列情報をモデル化する際に最も一般的な誤りは、タイムスタンプ自体をディストリビューション列として使用することです。 時間に基づくハッシュ分散は、時間の範囲をシャードにまとめるのではなく、見かけ上ランダムに時間を異なるシャードに分散させます。 時間に関係するクエリは、通常、時間の範囲 (たとえば最新のデータ) を参照します。 このようなハッシュ分散はネットワークのオーバーヘッドにつながります。
ベスト プラクティス
- ディストリビューション列としてタイムスタンプを選択しないでください。 別の分散列を選択します。 マルチテナント アプリでは、テナント ID を使用します。また、リアルタイム アプリではエンティティ ID を使用します。
- 代わりに PostgreSQL のテーブル パーティションを使用します。 時系列データの大きなテーブルを、それぞれ時間の範囲が異なる複数の継承テーブルに分割するには、テーブルのパーティション分割を使用します。 Postgres でパーティション分割されたテーブルを 分散すると、継承テーブルのシャードが作成されます。