自動プロビジョニングは、Azure Data Explorer のクラスターを実行するために必要なリソースを迅速にデプロイして構成するためのプロセスです。 これは、DevOps または DataOps ワークフローの重要な部分です。 プロビジョニング プロセスでは、手動でクラスターを構成する必要はありません。ユーザーの介入は不要であり、簡単に設定できます。
継続的インテグレーションと継続的デリバリー (CI/CD) パイプラインの一部として、自動プロビジョニングを使用して、構成済みのクラスターをデータと共にデプロイすることができます。 これを行う主な利点には、次の機能があります。
- 複数の環境を定義して維持します。
- ソース管理でデプロイを追跡します。
- 以前のバージョンへのロールバックが容易になります。
- 専用のテスト環境をプロビジョニングすることで、テストの自動化を容易にします。
この記事では、インフラストラクチャ、スキーマ エンティティ、データ インジェストなど、Azure Data Explorer 環境のプロビジョニングを自動化するためのさまざまなメカニズムの概要について説明します。 また、プロビジョニング プロセスを自動化するために使用されるさまざまなツールと手法への参照も提供します。

インフラストラクチャのデプロイ
インフラストラクチャのデプロイは、クラスター、データベース、データ接続などの Azure リソースのデプロイに関連します。 インフラストラクチャのデプロイには、次のようないくつかの異なる種類があります。
ARM テンプレートと Terraform スクリプトは、Azure Data Explorer インフラストラクチャをデプロイするための 2 つの主な宣言型の方法です。
ARM テンプレートのデプロイ
ARM テンプレートは、デプロイのインフラストラクチャと構成を定義する JSON または Bicep のファイルです。 テンプレートはクラスター、データベース、データ接続、およびその他の多くのインフラストラクチャ コンポーネントをデプロイするために使用できます。 「Azure Resource Manager テンプレートを使用して Azure Data Explorer クラスターとデータベースを作成する」を参照してください。
ARM テンプレートを使用して コマンド スクリプトをデプロイすることもできます。これは、データベース スキーマを作成したり、ポリシーを定義したりするのに役立ちます。 詳細については、「Kusto 照会言語スクリプトを使用してデータベースを構成する」を参照してください。
さらに多くのテンプレートの例については、「Azure クイックスタート テンプレート」のサイトを参照してください。
Terraform デプロイ
Terraform は、オープンソースのコードとしてのインフラストラクチャ ソフトウェア ツールです。 これには、クラウド サービスを管理するための一貫した CLI ワークフローが用意されています。 Terraform はクラウド API を宣言的な構成ファイルに体系化します。
Terraform には、ARM テンプレートと同じ機能が用意されています。 Terraform はクラスター、データベース、データ接続、およびその他のインフラストラクチャ コンポーネントをデプロイするために使用できます。
Terraform を使用して コマンドスクリプトをデプロイすることもできます。これは、データベース スキーマを作成したり、ポリシーを定義したりするのに役立ちます。
強制的なデプロイ
インフラストラクチャは、次のサポートされているいずれかのプラットフォームを使用して強制的にデプロイすることもできます。
スキーマ エンティティのデプロイ
スキーマ エンティティのプロビジョニングは、テーブル、関数、ポリシー、アクセス許可のデプロイに関連します。 管理コマンドで構成されるスクリプトを実行して、エンティティを作成または更新。
スキーマ エンティティのデプロイは、次の方法を使用して自動化できます。
- ARM テンプレート
- Terraform スクリプト
- Kusto CLI
- SDK
- ツール
- Kusto の同期. この対話型開発者ツールを使用して、データベース スキーマまたは管理コマンド スクリプトを抽出します。 その後、抽出されたコンテンツ コマンド スクリプトは、自動デプロイに使用できます。
- デルタ Kusto: CI/CD パイプラインでこのツールを起動します。 データベース スキーマや管理コマンド スクリプトなどの 2 つのソースを比較し、デルタ管理コマンド スクリプトを計算できます。 その後、抽出されたコンテンツ コマンド スクリプトは、自動デプロイに使用できます。
- Azure Data Explorer の Azure DevOps タスク。
データを取り込む
場合によっては、クラスターにデータを取り込む必要があります。 たとえば、データを取り込み、テストを実行したり、環境を再作成したりできます。 次の方法を使用してデータを取り込むことができます。
- SDK
- LightIngest CLI ツール
- Azure Data Factory パイプラインをトリガーする
CI/CD パイプラインを使用したデプロイの例
次の例では、Azure DevOps CI/CD パイプラインを使用します。これによりインフラストラクチャ、スキーマ エンティティ、データのデプロイを自動化するツールが実行されます。 これは、特定のツールセットを使用するパイプラインの一例ですが、他のツールや手順を使用することもできます。 たとえば、運用環境では、データを取り込まないパイプラインを作成することができます。 また、作成したクラスターで自動テストを実行するなど、パイプラインに追加の手順を追加することもできます。
ここでは、次のツールを使用します。
| デプロイの種類 | ツール | タスク |
|---|---|---|
| インフラストラクチャ | ARM テンプレート | クラスターとデータベースを作成する |
| スキーマ エンティティ | Kusto CLI | データベースのテーブルを作成する |
| データ | LightIngest | 1 つのテーブルにデータを取り込む |

パイプラインを作成するには、次の手順に従います。
手順 1: サービス接続を作成する
Azure Resource Manager 型のサービス接続を定義します。 クラスターをデプロイするサブスクリプションとリソースグループへの接続をポイントします。 Azure サービス プリンシパルが作成され、それを使用して ARM テンプレートをデプロイします。 同じプリンシパルを使用して、スキーマ エンティティをデプロイし、データを取り込むことができます。 Kusto CLI および LightIngest ツールに資格情報を明示的に渡す必要があります。
手順 2: パイプラインを作成する
クラスターのデプロイ、スキーマ エンティティの作成、データの取り込みに使用するパイプライン (deploy-environ) を定義します。
パイプラインを使用する前に、次のシークレット変数を作成する必要があります。
| 変数名 | 説明 |
|---|---|
clusterName |
Azure Data Explorer クラスターの名前。 |
serviceConnection |
ARM テンプレートのデプロイに使用される Azure DevOps 接続の名前。 |
appId |
クラスターとの対話に使用されるサービス プリンシパルのクライアント ID。 |
appSecret |
サービス プリンシパルのシークレット。 |
appTenantId |
サービス プリンシパルのテナント ID。 |
location |
クラスターをデプロイする Azure リージョン。 たとえば、eastus のようにします。 |
resources:
- repo: self
stages:
- stage: deploy_cluster
displayName: Deploy cluster
variables: []
clusterName: specifyClusterName
serviceConnection: specifyServiceConnection
appId: specifyAppId
appSecret: specifyAppSecret
appTenantId: specifyAppTenantId
location: specifyLocation
jobs:
- job: e2e_deploy
pool:
vmImage: windows-latest
variables: []
steps:
- bash: |
nuget install Microsoft.Azure.Kusto.Tools -Version 5.3.1
# Rename the folder (including the most recent version)
mv Microsoft.Azure.Kusto.Tools.* kusto.tools
displayName: Download required Kusto.Tools Nuget package
- task: AzureResourceManagerTemplateDeployment@3
displayName: Deploy Infrastructure
inputs:
deploymentScope: 'Resource Group'
# subscriptionId and resourceGroupName are specified in the serviceConnection
azureResourceManagerConnection: $(serviceConnection)
action: 'Create Or Update Resource Group'
location: $(location)
templateLocation: 'Linked artifact'
csmFile: deploy-infra.json
overrideParameters: "-clusterName $(clusterName)"
deploymentMode: 'Incremental'
- bash: |
# Define connection string to cluster's database, including service principal's credentials
connectionString="https://$(clusterName).$(location).kusto.windows.net/myDatabase;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
# Execute a KQL script against the database
kusto.tools/tools/Kusto.Cli $connectionString -script:MyDatabase.kql
displayName: Create Schema Entities
- bash: |
connectionString="https://ingest-$(CLUSTERNAME).$(location).kusto.windows.net/;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
kusto.tools/tools/LightIngest $connectionString -table:Customer -sourcePath:customers.csv -db:myDatabase -format:csv -ignoreFirst:true
displayName: Ingest Data
手順 3: クラスターをデプロイする ARM テンプレートを作成する
クラスターをサブスクリプションとリソース グループにデプロイするために使用する ARM テンプレート (deploy-infra.json) を定義します。
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"clusterName": {
"type": "string",
"minLength": 5
}
},
"variables": {
},
"resources": [
{
"name": "[parameters('clusterName')]",
"type": "Microsoft.Kusto/clusters",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"sku": {
"name": "Dev(No SLA)_Standard_E2a_v4",
"tier": "Basic",
"capacity": 1
},
"resources": [
{
"name": "myDatabase",
"type": "databases",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Kusto/clusters', parameters('clusterName'))]"
],
"kind": "ReadWrite",
"properties": {
"softDeletePeriodInDays": 365,
"hotCachePeriodInDays": 31
}
}
]
}
]
}
手順 4: スキーマ エンティティを作成するための KQL スクリプトを作成する
データベースにテーブルを作成するために使用する KQL スクリプト (MyDatabase.kql) を定義します。
.create table Customer(CustomerName:string, CustomerAddress:string)
// Set the ingestion batching policy to trigger ingestion quickly
// This is to speedup reaction time for the sample
// Do not do this in production
.alter table Customer policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
.create table CustomerLogs(CustomerName:string, Log:string)
手順 5: データを取り込むための KQL スクリプトを作成する
取り込む CSV データ ファイル (customer.csv) を作成します。
customerName,customerAddress
Contoso Ltd,Paris
Datum Corporation,Seattle
Fabrikam,NYC
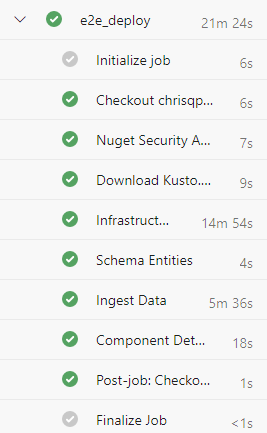
クラスターは、パイプラインで指定したサービス プリンシパルの資格情報を使用して作成します。 ユーザーにアクセス許可を付与するには、「Azure Data Explorer データベース アクセス許可の管理」の手順を使用します。
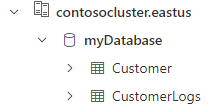
[カスタマー] テーブルに対してクエリを実行することで、デプロイを 確認できます。 CSV ファイルからインポートされた 3 つのレコードが表示されます。
関連するコンテンツ
- Azure Resource Manager テンプレートを使用してクラスターとデータベースを作成します。
- KQL スクリプトを使用してデータベースを構成します。